

Exploring RAG techniques to improve retrieval accuracy
In Part 1, we dove into improving RAG (retrieval augmented generation) outcomes by re-writing queries before performing retrieval. This time we will learn about how re-ranking results from vector database retrievals helps performance.
While I highly recommend experimenting with promising proprietary options like Cohere’s Re-Rank 3, we’ll focus mainly on understanding what researchers have shared on the topic.
Re-Ranking, what’s the point?
First of all, why rerank at all? Results from vector databases return “similarity” scores based on the embeddings of the query and document. These scores can already be used to sort the results and since this is already a semantic similarity scoring of the document and query, why would we need another step?
There are a few reasons why we would take this approach:
- Document embeddings are “lossy”. Documents are compressed in vector format before seeing the query, which means the document vector is not tailored to the query vector. Re-ranking allows us to better understand the document’s meaning specific to the query.
- Two-stage systems have become standard in traditional search and recommender systems. They offer improvements in scalability, flexibility, and accuracy. Retrieval models are very fast, whereas ranking models are slow. By building a hybrid system, we can balance the speed and accuracy trade-offs between each stage.
- Re-ranking allows us to reduce the number of documents we stuff into the context window which a) reduces costs and b) reduces the chances of relevant data being “lost in the haystack”.
Traditional Methods of Re-Ranking
Informational retrieval is not a new field. Before LLMs employed RAG to improve generation, search engines used re-ranking methods to improve search results. Two popular methodologies are TF-IDF (term frequency–inverse document frequency) and BM25 (Best Match 25).
Karen Spärck Jones conceived of the concept of IDF (of TF-IDF), inverse document frequency, as a statistical interpretation of term-specificity in the 1970s. The general concept is that the specificity of a term can be quantified as an inverse function of the number of documents in which it occurs. A toy example is the frequency of terms in Shakespearean plays. Because the term “Romeo” only appears in one play, we believe it is more informative to the subject of the play than the word “sweet” because that term occurs in all plays.
BM25 or Okapi BM25 was developed by both Karen Spärck Jones and Stephen Robertson as an improvement to TF-IDF. BM25 is a “bag-of-words” retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of their proximity within the document. This method expands on TF-IDF in a few important ways:
- BM25 uses a saturation function where the importance of a term increases with frequency but with diminishing returns. (Side note: This was important for protecting accuracy when search engine optimization (SEO) became higher stakes. You can’t just spam your keyword with this improvement.)
- BM25 includes document length normalization to ensure that longer documents are not unfairly advantaged. (Another improvement to thwart would-be SEO gamers.)
Both of these methods can be used to re-rank results from vector databases before documents are used in the context of generation. This would be called “feature” based re-ranking.
Neural Re-Ranking Models
Something you should notice about the traditional methods is that they focus on exact term matches. These methods will struggle when documents use semantically similar but different terms. Neural re-ranking methods like SBERT (Sentence Transformers) seek to overcome this limitation.
SBERT is a fine-tuned BERT (Bidirectional Encoder Representations from Transformers) model with a siamese / triplet network architecture which greatly improves the computation efficiency and latency for calculating sentence similarity. Transformers like SBERT (Sentence-BERT) use the context in which terms are used, allowing the model to handle synonyms and words with multiple meanings.
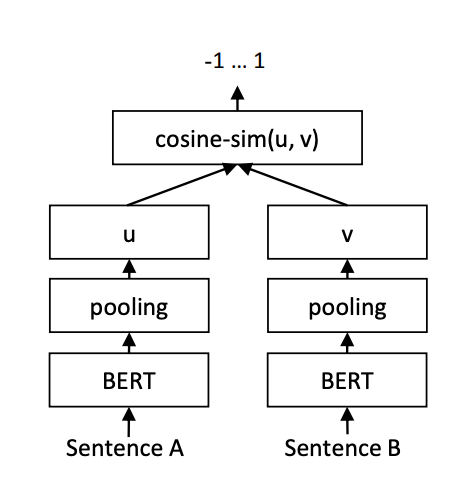
SBERT tends to perform better for semantic similarity ranking due to its specialization. However, using SBERT comes with the downside that you will need to manage the models locally versus calling an API, such as with OpenAI’s embedding models. Pick your poison wisely!
Cross-Encoder Re-Ranking
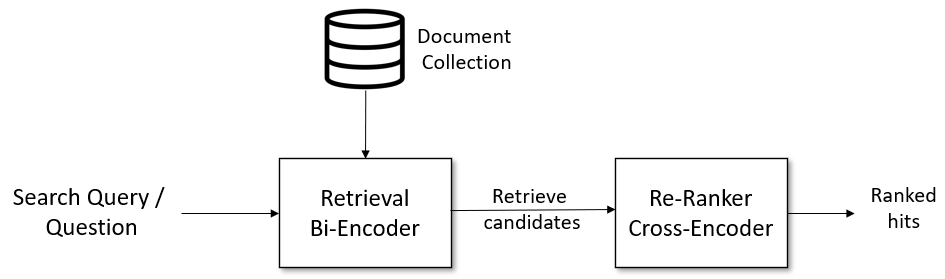
The top K results from a vector database search are the most similar document vectors compared to the query vector. Another way of describing this ranking method is to say it is a “bi-encoder” ranking. Vectors are calculated up front and approximate nearest neighbors algorithms (ANNs) select the most similar documents making this a highly efficient ranking method. But that efficiency comes at the expense of some accuracy.
In contrast, cross-encoders use a classification mechanism on data pairs to calculate similarity. This means you need a pair for each document and query. This approach can yield much more accurate results but it’s highly inefficient. That is why cross-encoders are best implemented through a hybrid approach where the number of documents is first pruned using a “bi-encoder” top K result before ranking with a cross-encoder. You can read more about using bi-encoders and cross-encoders together in the SBERT documentation.
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
Prompt-based Re-Ranking (PBR)
Until now, we have focused on using vectors or other numeric methods to rerank our RAG results. But does that mean we are underleveraging the LLM? Feeding the document and the query back to the LLM for scoring can be an effective way to score the document; there is approximately no information loss when you take this approach. If the LLM is prompted to return only a single token (the score), the latency incurred is often acceptable (although this is one of the more expensive approaches to scale). This is considered to be “zero-shot” re-ranking and research is still limited on this topic but we know it must be sensitive to the quality of the prompt.
Another version of (PBR) is the DSLR Framework (Document Refinement with Sentence-Level Re-ranking and Reconstruction). DSLR proposes an unsupervised method that decomposes retrieved documents into sentences, re-ranks them based on relevance, and reconstructs them into coherent passages before passing them to the LLM. This approach contrasts with traditional methods that rely on fixed-size passages, which may include redundant or irrelevant information. Pruning non-relevant sentences before generating a response can reduce hallucinations and improve overall accuracy. Below you can see an example of how DSLR refinement improves the LLMs response.

Graph-based Reranking
Sometimes the answer is not going to fit cleanly inside a single document chunk. Books and papers are written with the expectation that they’ll be read linearly or at least the reader will be able to easily refer back to earlier passages. For example, you could be asked to refer back to an earlier chapter on BM25 when reading about SBERT. In a basic RAG application, this would be impossible because your retrieved document would have no connections to the previous chapters.
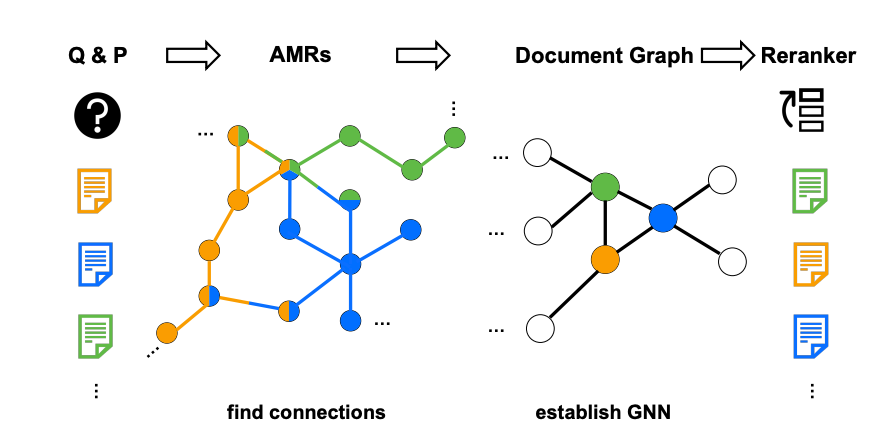
G-RAG, an approach proposed by researchers at Google and UCLA, hopes to alleviate this issue. G-RAG is a re-ranker that leverages graph neural networks (GNNs) to consider connections between retrieved documents. Documents are represented as nodes and edges are shared concepts between documents. These graphs are generated as Abstract Meaning Representation (AMR) Graphs which can be created with tools like https://github.com/goodbai-nlp/AMRBART (MIT License).
Experiments with Natural Question (NQ) and TriviaQA (TQA) datasets showed this approach made improvements to Mean Tied Reciprocal Ranking (MTRR) and Tied Mean Hits@10 (TMHits@10) over other state-of-the-art approaches.
Conclusion
I hope you’ve enjoyed this overview of techniques you can use to improve the performance of your RAG applications. I look forward to continued advancements in this field. I know there will be many considering the blistering pace of research at the moment.
Let me know in the comments section if you have favorite re-ranking methods not covered in this article.
Advanced Retrieval Techniques in a World of 2M Token Context Windows: Part 2 on Re-rankers was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Advanced Retrieval Techniques in a World of 2M Token Context Windows: Part 2 on Re-rankers