

Advanced Retrieval Techniques in a World of 2M Token Context Windows, Part 1
Exploring RAG techniques to improve retrieval accuracy
First of all, do we still care about RAG (Retrieval Augmented Generation)?
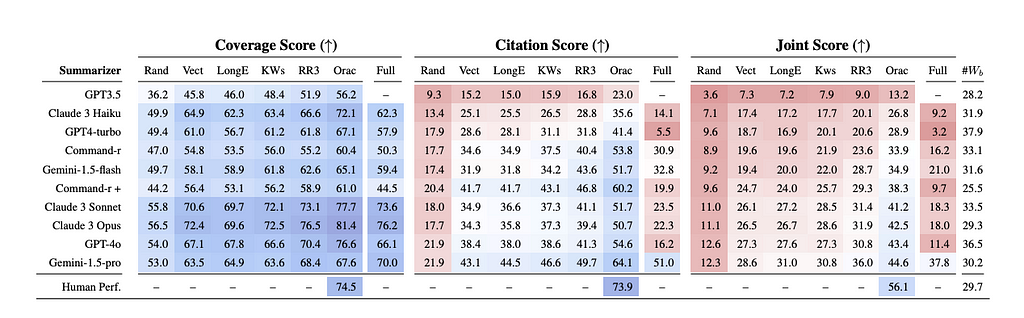
Gemini Pro can handle an astonishing 2M token context compared to the paltry 15k we were amazed by when GPT-3.5 landed. Does that mean we no longer care about retrieval or RAG systems? Based on Needle-in-a-Haystack benchmarks, the answer is that while the need is diminishing, especially for Gemini models, advanced retrieval techniques still significantly improve performance for most LLMs. Benchmarking results show that long context models perform well at surfacing specific insights. However, they struggle when a citation is required. That makes retrieval techniques especially important for use cases where citation quality is important (think law, journalism, and medical applications among others). These tend to be higher-value applications where lacking a citation makes the initial insight much less useful. Additionally, while the cost of long context models will likely decrease, augmenting shorter content window models with retrievers can be a cost-effective and lower latency path to serve the same use cases. It’s safe to say that RAG and retrieval will stick around a while longer but maybe you won’t get much bang for your buck implementing a naive RAG system.
So what are the retrieval techniques we should be implementing?
Advanced RAG covers a range of techniques but broadly they fall under the umbrella of pre-retrieval query rewriting and post-retrieval re-ranking. Let’s dive in and learn something about each of them.
Pre-Retrieval — Query Rewriting
Q: “What is the meaning of life?”
A: “42”
Question and answer asymmetry is a huge issue in RAG systems. A typical approach to simpler RAG systems is to compare the cosine similarity of the query and document embedding. This works when the question is nearly restated in the answer, “What’s Meghan’s favorite animal?”, “Meghan’s favorite animal is the giraffe.”, but we are rarely that lucky.
Here are a few techniques that can overcome this:
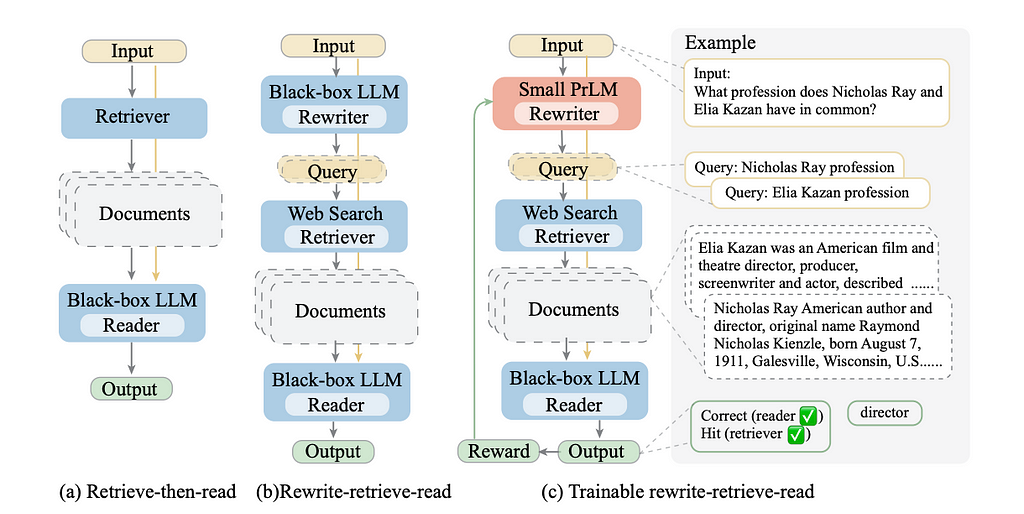
Rewrite-Retrieve-Read
The nomenclature “Rewrite-Retrieve-Read” originated from a paper from the Microsoft Azure team in 2023 (although given how intuitive the technique is it had been used for a while). In this study, an LLM would rewrite a user query into a search engine-optimized query before fetching relevant context to answer the question.
The key example was how this query, “What profession do Nicholas Ray and Elia Kazan have in common?” should be broken down into two queries, “Nicholas Ray profession” and “Elia Kazan profession”. This allows for better results because it’s unlikely that a single document would contain the answer to both questions. By splitting the query into two the retriever can more effectively retrieve relevant documents.
Rewriting can also help overcome issues that arise from “distracted prompting”. Or instances where the user query has mixed concepts in their prompt and taking an embedding directly would result in nonsense. For example, “Great, thanks for telling me who the Prime Minister of the UK is. Now tell me who the President of France is” would be rewritten like “current French president”. This can help make your application more robust to a wider range of users as some will think a lot about how to optimally word their prompts, while others might have different norms.
Query Expansion
In query expansion with LLMs, the initial query can be rewritten into multiple reworded questions or decomposed into subquestions. Ideally, by expanding the query into several options, the chances of lexical overlap increase between the initial query and the correct document in your storage component.
Query expansion is a concept that predates the widespread usage of LLMs. Pseudo Relevance Feedback (PRF) is a technique that inspired some LLM researchers. In PRF, the top-ranked documents from an initial search to identify and weight new query terms. With LLMs, we rely on the creative and generative capabilities of the model to find new query terms. This is beneficial because LLMs are not restricted to the initial set of documents and can generate expansion terms not covered by traditional methods.
Corpus-Steered Query Expansion (CSQE) is a method that marries the traditional PRF approach with the LLMs’ generative capabilities. The initially retrieved documents are fed back to the LLM to generate new query terms for the search. This technique can be especially performant for queries for which LLMs lacks subject knowledge.
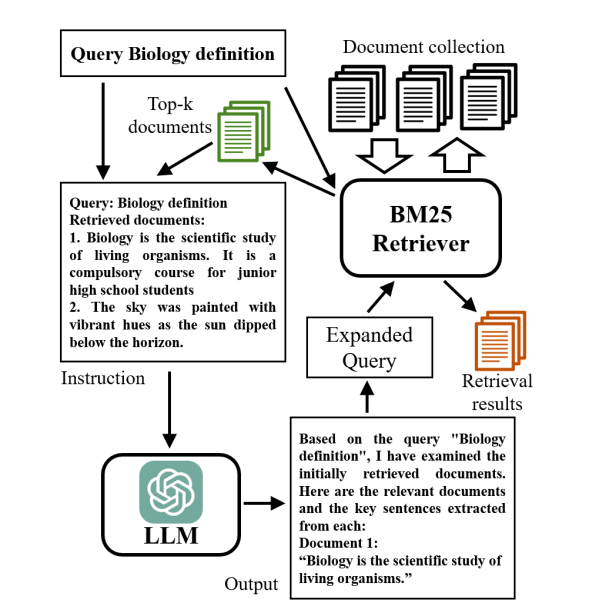
There are limitations to both LLM-based query expansion and its predecessors like PRF. The most glaring of which is the assumption that the LLM generated terms are relevant or that the top ranked results are relevant. God forbid I am trying to find information about the Australian journalist Harry Potter instead of the famous boy wizard. Both techniques would further pull my query away from the less popular query subject to the more popular one making edge case queries less effective.
Hypothetical Query Indexes
Another way to reduce the asymmetry between questions and documents is to index documents with a set of LLM-generated hypothetical questions. For a given document, the LLM can generate questions that could be answered by the document. Then during the retrieval step, the user’s query embedding is compared to the hypothetical question embeddings versus the document embeddings.
This means that we don’t need to embed the original document chunk, instead, we can assign the chunk a document ID and store that as metadata on the hypothetical question document. Generating a document ID means there is much less overhead when mapping many questions to one document.
The clear downside to this approach is your system will be limited by the creativity and volume of questions you store.
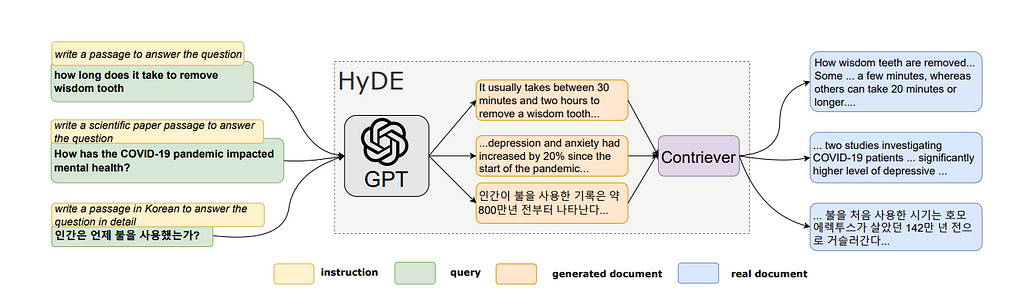
Hypothetical Document Embeddings — HyDE
HyDE is the opposite of Hypothetical Query Indexes. Instead of generating hypothetical questions, the LLM is asked to generate a hypothetical document that could answer the question, and the embedding of that generated document is used to search against the real documents. The real document is then used to generate the response. This method showed strong improvements over other contemporary retriever methods when it was first introduced in 2022.
We use this concept at Dune for our natural language to SQL product. By rewriting user prompts as a possible caption or title for a chart that would answer the question, we are better able to retrieve SQL queries that can serve as context for the LLM to write a new query.
Stay tuned for part 2 on reranking methods.
Advanced Retrieval Techniques in a World of 2M Token Context Windows Part 1 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Advanced Retrieval Techniques in a World of 2M Token Context Windows Part 1