

The Azure Landing Zone for a Data Platform in the Cloud
Working with sensitive data or within a highly regulated environment requires safe and secure cloud infrastructure for data processing. The cloud might seem like an open environment on the internet and raise security concerns. When you start your journey with Azure and don’t have enough experience with the resource configuration it is easy to make design and implementation mistakes that can impact the security and flexibility of your new data platform. In this post, I’ll describe the most important aspects of designing a cloud adaptation framework for a data platform in Azure.
What is an Azure landing zone?
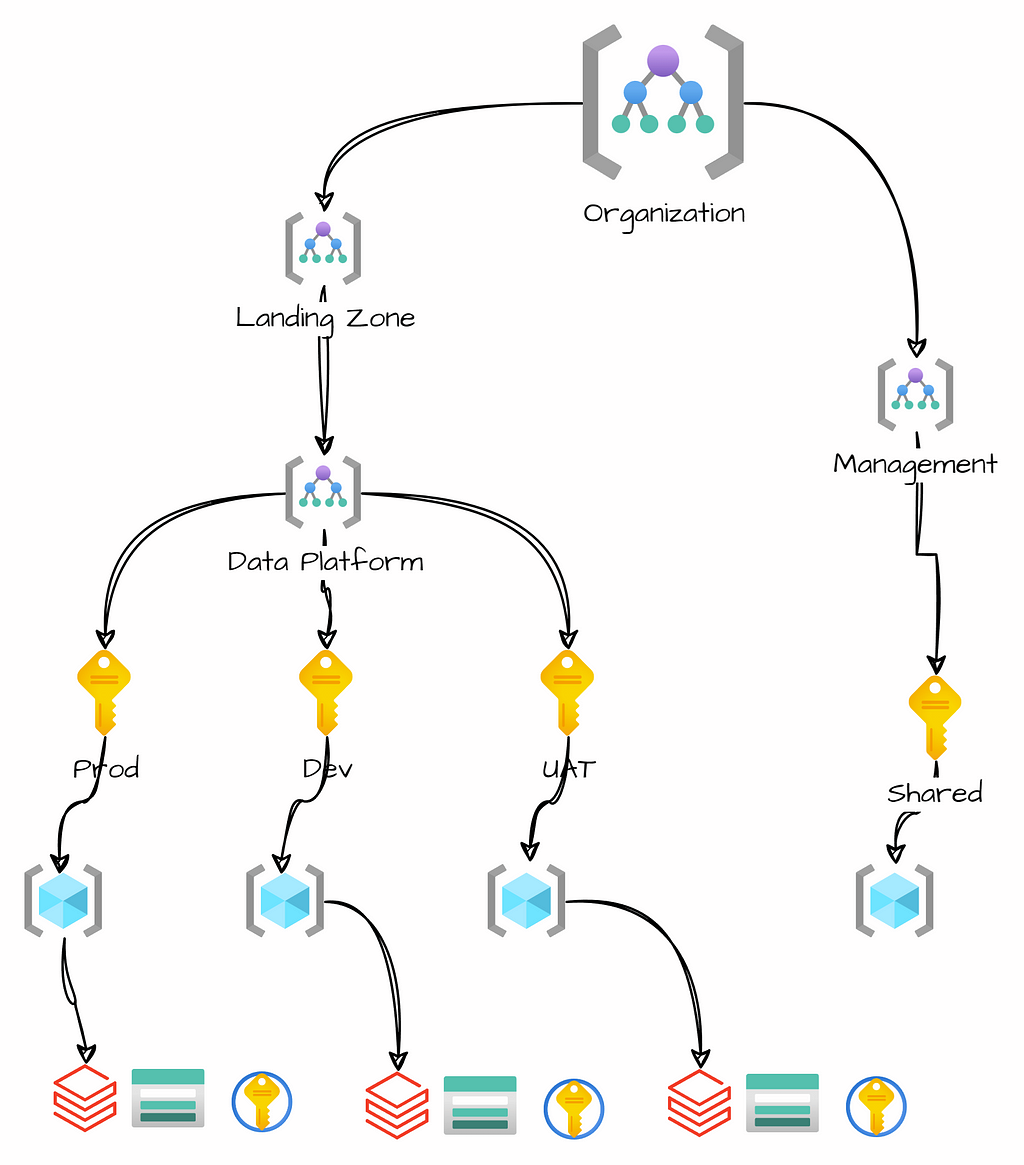
An Azure landing zone is the foundation for deploying resources in the public cloud. It contains essential elements for a robust platform. These elements include networking, identity and access management, security, governance, and compliance. By implementing a landing zone, organizations can streamline the configuration process of their infrastructure, ensuring the utilization of best practices and guidelines.
An Azure landing zone is an environment that follows key design principles to enable application migration, modernization, and development. In Azure, subscriptions are used to isolate and develop application and platform resources. These are categorized as follows:
- Application landing zones: Subscriptions dedicated to hosting application-specific resources.
- Platform landing zone: Subscriptions that contain shared services, such as identity, connectivity, and management resources provided for application landing zones.
These design principles help organizations operate successfully in a cloud environment and scale out a platform.
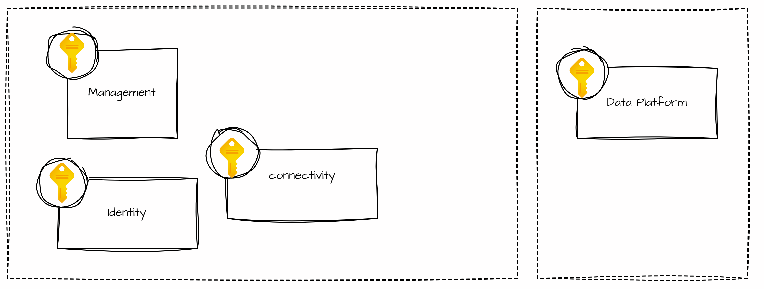
Implementing a Data Platform in Azure
A data platform implementation in Azure involves a high-level architecture design where resources are selected for data ingestion, transformation, serving, and exploration. The first step may require a landing zone design. If you need a secure platform that follows best practices, starting with a landing zone is crucial. It will help you organize the resources within subscriptions and resource groups, define the network topology, and ensure connectivity with on-premises environments via VPN, while also adhering to naming conventions and standards.
Architecture Design
Tailoring an architecture for a data platform requires a careful selection of resources. Azure provides native resources for data platforms such as Azure Synapse Analytics, Azure Databricks, Azure Data Factory, and Microsoft Fabric. The available services offer diverse ways of achieving similar objectives, allowing flexibility in your architecture selection.
For instance:
- Data Ingestion: Azure Data Factory or Synapse Pipelines.
- Data Processing: Azure Databricks or Apache Spark in Synapse.
- Data Analysis: Power BI or Databricks Dashboards.
We may use Apache Spark and Python or low-code drag-and-drop tools. Various combinations of these tools can help us create the most suitable architecture depending on our skills, use cases, and capabilities.
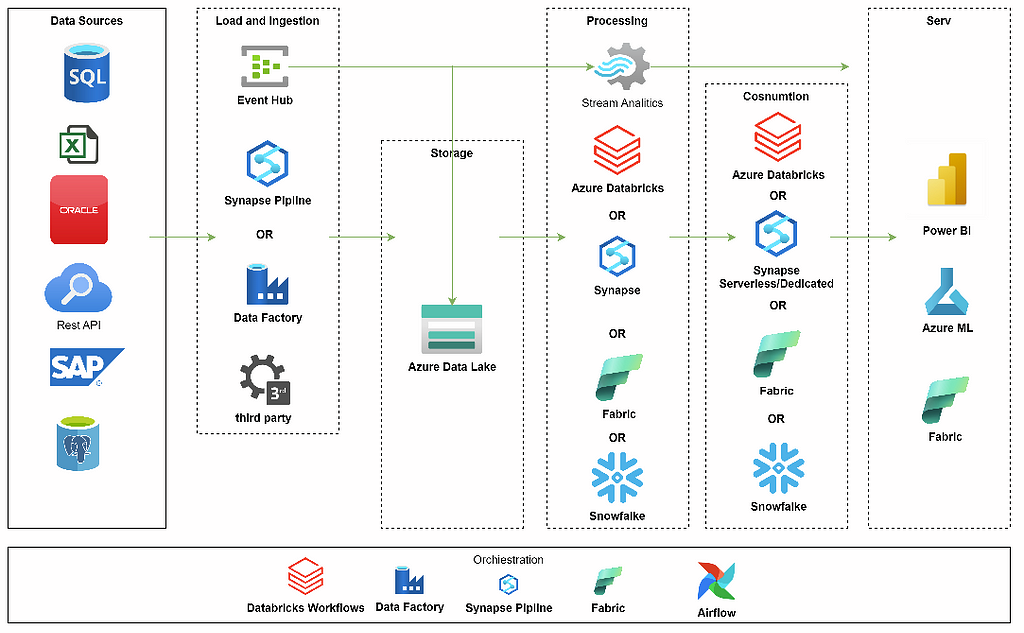
Azure also allows you to use other components such as Snowflake or create your composition using open-source software, Virtual Machines(VM), or Kubernetes Service(AKS). We can leverage VMs or AKS to configure services for data processing, exploration, orchestration, AI, or ML.
Typical Data Platform Structure
A typical Data Platform in Azure should comprise several key components:
1. Tools for data ingestion from sources into an Azure Storage Account. Azure offers services like Azure Data Factory, Azure Synapse Pipelines, or Microsoft Fabric. We can use these tools to collect data from sources.
2. Data Warehouse, Data Lake, or Data Lakehouse: Depending on your architecture preferences, we can select different services to store data and a business model.
- For Data Lake or Data Lakehouse, we can use Databricks or Fabric.
- For Data Warehouse we can select Azure Synapse, Snowflake, or MS Fabric Warehouse.
3. To orchestrate data processing in Azure we have Azure Data Factory, Azure Synapse Pipelines, Airflow, or Databricks Workflows.
4. Data transformation in Azure can be handled by various services.
- For Apache Spark: Databricks, Azure Synapse Spark Pool, and MS Fabric Notebooks,
- For SQL-based transformation we can use Spark SQL in Databricks, Azure Synapse, or MS Fabric, T-SQL in SQL Server, MS Fabric, or Synapse Dedicated Pool. Alternatively, Snowflake offers all SQL capabilities.
Subscriptions
An important aspect of platform design is planning the segmentation of subscriptions and resource groups based on business units and the software development lifecycle. It’s possible to use separate subscriptions for production and non-production environments. With this distinction, we can achieve a more flexible security model, separate policies for production and test environments, and avoid quota limitations.
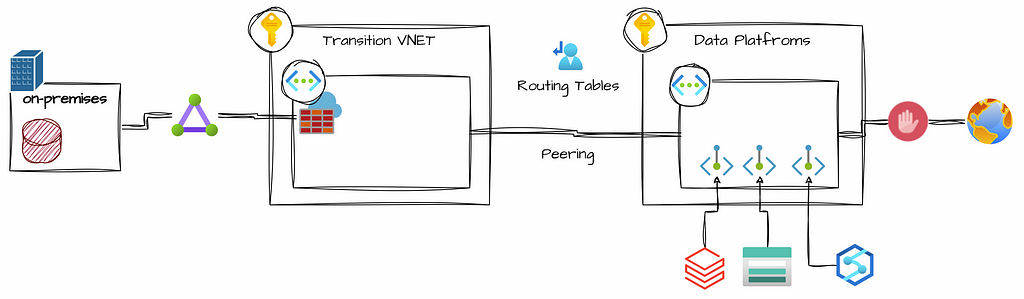
Networking
A virtual network is similar to a traditional network that operates in your data center. Azure Virtual Networks(VNet) provides a foundational layer of security for your platform, disabling public endpoints for resources will significantly reduce the risk of data leaks in the event of lost keys or passwords. Without public endpoints, data stored in Azure Storage Accounts is only accessible when connected to your VNet.
The connectivity with an on-premises network supports a direct connection between Azure resources and on-premises data sources. Depending on the type of connection, the communication traffic may go through an encrypted tunnel over the internet or a private connection.
To improve security within a Virtual Network, you can use Network Security Groups(NSGs) and Firewalls to manage inbound and outbound traffic rules. These rules allow you to filter traffic based on IP addresses, ports, and protocols. Moreover, Azure enables routing traffic between subnets, virtual and on-premise networks, and the Internet. Using custom Route Tables makes it possible to control where traffic is routed.
Naming Convention
A naming convention establishes a standardization for the names of platform resources, making them more self-descriptive and easier to manage. This standardization helps in navigating through different resources and filtering them in Azure Portal. A well-defined naming convention allows you to quickly identify a resource’s type, purpose, environment, and Azure region. This consistency can be beneficial in your CI/CD processes, as predictable names are easier to parametrize.
Considering the naming convention, you should account for the information you want to capture. The standard should be easy to follow, consistent, and practical. It’s worth including elements like the organization, business unit or project, resource type, environment, region, and instance number. You should also consider the scope of resources to ensure names are unique within their context. For certain resources, like storage accounts, names must be unique globally.
For example, a Databricks Workspace might be named using the following format:
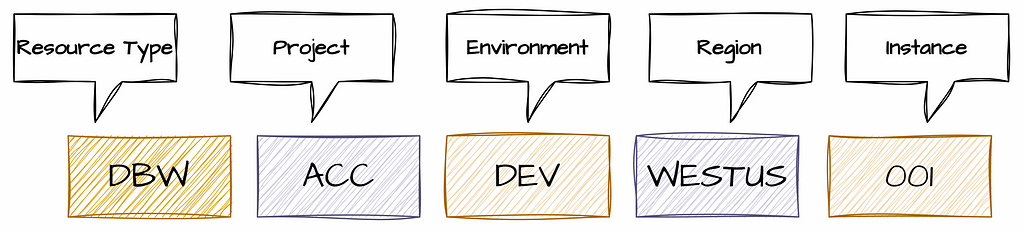
Example Abbreviations:
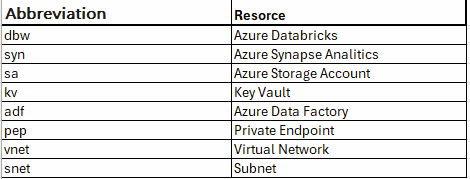
A comprehensive naming convention typically includes the following format:
- Resource Type: An abbreviation representing the type of resource.
- Project Name: A unique identifier for your project.
- Environment: The environment the resource supports (e.g., Development, QA, Production).
- Region: The geographic region or cloud provider where the resource is deployed.
- Instance: A number to differentiate between multiple instances of the same resource.
Infrastructure Implementation
Implementing infrastructure through the Azure Portal may appear straightforward, but it often involves numerous detailed steps for each resource. The highly secured infrastructure will require resource configuration, networking, private endpoints, DNS zones, etc. Resources like Azure Synapse or Databricks require additional internal configuration, such as setting up Unity Catalog, managing secret scopes, and configuring security settings (users, groups, etc.).
Once you finish with the test environment, you‘ll need to replicate the same configuration across QA, and production environments. This is where it’s easy to make mistakes. To minimize potential errors that could impact development quality, it‘s recommended to use an Infrastructure as a Code (IasC) approach for infrastructure development. IasC allows you to create cloud infrastructure as code in Terraform or Biceps, enabling you to deploy multiple environments with consistent configurations.
In my cloud projects, I use accelerators to quickly initiate new infrastructure setups. Microsoft also provides accelerators that can be used. Storing an infrastructure as a code in a repository offers additional benefits, such as version control, tracking changes, conducting code reviews, and integrating with DevOps pipelines to manage and promote changes across environments.
Summary
If your data platform doesn’t handle sensitive information and you don’t need a highly secured data platform, you can create a simpler setup with public internet access without Virtual Networks(VNet), VPNs, etc. However, in a highly regulated area, a completely different implementation plan is required. This plan will involve collaboration with various teams within your organization — such as DevOps, Platform, and Networking teams — or even external resources.
You’ll need to establish a secure network infrastructure, resources, and security. Only when the infrastructure is ready you can start activities tied to data processing development.
If you found this article insightful, I invite you to express your appreciation by clicking the ‘clap’ button or liking it on LinkedIn. Your support is greatly valued. For any questions or advice, feel free to contact me on LinkedIn.
Adapting the Azure Landing Zone for a Data Platform in the Cloud was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Adapting the Azure Landing Zone for a Data Platform in the Cloud
Go Here to Read this Fast! Adapting the Azure Landing Zone for a Data Platform in the Cloud