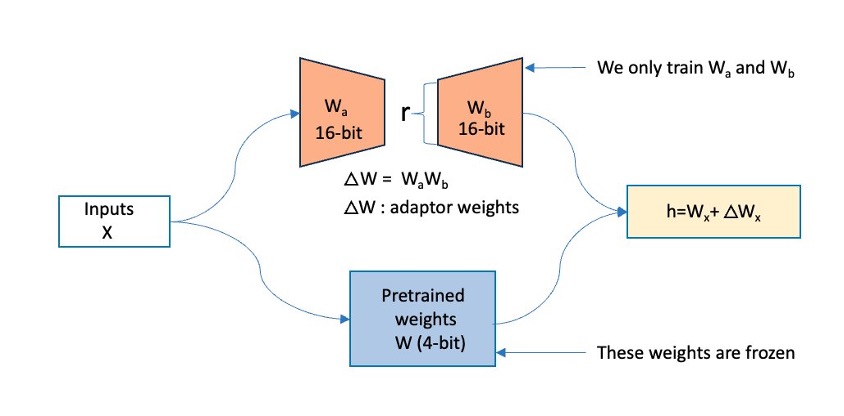
In this post, we demonstrate how you can address the challenges of model customization being complex, time-consuming, and often expensive by using fully managed environment with Amazon SageMaker Training jobs to fine-tune the Mixtral 8x7B model using PyTorch Fully Sharded Data Parallel (FSDP) and Quantized Low Rank Adaptation (QLoRA).
Originally appeared here:
Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA
Go Here to Read this Fast! Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA