On the potential benefits of creating model-specific GPU kernels and their application to optimizing the use of dynamically shaped tensors

This post continues a long series of posts on the topic of analyzing and optimizing the runtime performance of training AI/ML models. The post could easily have been titled “PyTorch Model Performance Analysis and Optimization — Part 7”, but due to the weight of the topic at hand, we decided that a dedicated post (or series of posts) was warranted. In our previous posts, we have spoken at length about the importance of analyzing and optimizing your AI/ML workloads and the potentially significant impact it can have on the speed and costs of AI/ML model development. We have advocated for having multiple tools and techniques for profiling and optimizing training performance and have demonstrated many of these in practice. In this post we will discuss one of the more advanced optimization techniques — one that sets apart the true rock stars from the simple amateurs — creating a custom PyTorch operator in C++ and CUDA.
Popular ML frameworks, such as PyTorch, TensorFlow, and JAX are typically built using SW components that are optimized for the underlying hardware that the AI/ML workload is run on, be it a CPU, a GPU, or an AI-specific ASIC such as a Google TPU. However, inevitably, you may find the performance of certain computation blocks that comprise your model to be unsatisfactory or in-optimal. Oftentimes, by tuning the low-level code blocks — often referred to as kernels — to the specific needs of the AI/ML model, can result in significant speed-ups to the runtime performance of model training and inference. Such speed-ups can be accomplished by implementing functionalities that were previously unsupported (e.g., an advanced attention block), fusing together individual operations (e.g., as in PyTorch’s tutorial on multiply-add fusion), and/or optimizing existing kernels based on the specific properties of the model at hand. Importantly, the ability to perform such customization depends on the support of both the AI HW and the ML framework. Although our focus on this post will be on NVIDIA GPUs and the PyTorch framework, it should be noted that other AI ASICs and ML frameworks enable similar capabilities for custom kernel customization. NVIDIA enables the development of custom kernels for its GPUs through its CUDA toolkit. And PyTorch includes dedicated APIs and tutorials for exposing this functionality and integrating it into the design of your model.
Our intention in this post is to draw attention to the power and potential of kernel customization and demonstrate its application to the unique challenge of training models with dynamically shaped tensors. Our intention is not — by any means — to replace the official documentation on developing custom operations. Furthermore, the examples we will share were chosen for demonstrative purposes, only. We have made no effort to optimize these or verify their robustness, durability, or accuracy. If, based on this post, you choose to invest in AI/ML optimization via custom CUDA kernel development, you should be sure to undergo the appropriate training.
Toy Model — The Challenge of Dynamically Shaped Tensors
The prevalence of tensors with dynamic shapes in AI models can pose unique and exciting challenges with regards to performance optimization. We have already seen one example of this in a previous post in which we demonstrated how the use of boolean masks can trigger a undesired CPU-GPU sync event and advocated against their use. Generally speaking, AI accelerators tend to prefer tensors with fixed shapes over ones with dynamic shapes. Not only does it simplify the management of memory resources, but it also enables greater opportunity for performance optimization (e.g., using torch.compile). The toy example that follows demonstrates this challenge.
Suppose we are tasked with creating a face detection model for a next-generation digital camera. To train, this model, we are provided with a dataset of one million 256x256 grayscale images and associated ground-truth bounding boxes for each image. Naturally, the number of faces in each image can vary greatly, with the vast majority of images containing five or fewer faces, and just a few containing dozens or even hundreds. The requirement from our model is to support all variations. Specifically, our model needs to support the detection of up to 256 faces in an image.
To address this challenge, we define the following naïve model that generates bounding boxes and an accompanying loss function. In particular, we naïvely truncate the model outputs based on the number of target boxes rather than perform some form of assignment algorithm for matching between the bounding box predictions and ground truth targets. We (somewhat arbitrarily) choose the Generalized Intersection Over Union (GIOU) loss. A real-world solution would likely be far more sophisticated (e.g., it would include a loss component that includes a penalizes for false positives).
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
conv_layers = []
for i in range(4):
conv_layers.append(nn.Conv2d(4 ** i, 4 ** (i + 1), 3,
padding='same'))
conv_layers.append(nn.MaxPool2d(2, 2))
conv_layers.append(nn.ReLU())
self.conv_layers = nn.Sequential(*conv_layers)
self.lin1 = nn.Linear(256 * 256, 256 * 64)
self.lin2 = nn.Linear(256 * 64, 256 * 4)
def forward(self, x):
x = self.conv_layers(x.float())
x = self.lin2(F.relu(self.lin1(x.view((-1, 256 * 256)))))
return x.view((-1, 256, 4))
def generalized_box_iou(boxes1, boxes2):
# loosly based on torchvision generalized_box_iou_loss code
epsilon = 1e-5
area1 = (boxes1[..., 2]-boxes1[..., 0])*(boxes1[..., 3]-boxes1[..., 1])
area2 = (boxes2[..., 2]-boxes2[..., 0])*(boxes2[..., 3]-boxes2[..., 1])
lt = torch.max(boxes1[..., :2], boxes2[..., :2])
rb = torch.min(boxes1[..., 2:], boxes2[..., 2:])
wh = rb - lt
inter = wh[..., 0] * wh[..., 1]
union = area1 + area2 - inter
iou = inter / union.clamp(epsilon)
lti = torch.min(boxes1[..., :2], boxes2[..., :2])
rbi = torch.max(boxes1[..., 2:], boxes2[..., 2:])
whi = rbi - lti
areai = (whi[..., 0] * whi[..., 1]).clamp(epsilon)
return iou - (areai - union) / areai
def loss_fn(pred, targets_list):
batch_size = len(targets_list)
total_boxes = 0
loss_sum = 0.
for i in range(batch_size):
targets = targets_list[i]
num_targets = targets.shape[0]
if num_targets > 0:
sample_preds = pred[i, :num_targets]
total_boxes += num_targets
loss_sum += generalized_box_iou(sample_preds, targets).sum()
return loss_sum / max(total_boxes, 1)
Due the varying number of faces per image, the loss is calculated separately for each individual sample rather than a single time (for the entire batch). In particular, the CPU will launch each of the GPU kernels associated with the loss function B times, where B is the chosen batch size. Depending on the size of the batch, this could entail a significant overhead, as we will see below.
In the following block we define a dataset that generates random images and associated bounding boxes. Since the number of faces varies per image, we require a custom collate function for grouping samples into batches:
from torch.utils.data import Dataset, DataLoader
import numpy as np
# A dataset with random images and gt boxes
class FakeDataset(Dataset):
def __init__(self):
super().__init__()
self.size = 256
self.img_size = [256, 256]
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randint(low=0, high=256,
size=[1]+self.img_size,
dtype=torch.uint8)
# set the distribution over the number of boxes to reflect the fact
# that the vast majority of images have fewer than 10 faces
n_boxes = np.clip(np.floor(np.abs(np.random.normal(0, 3)))
.astype(np.int32), 0, 255)
box_sizes = torch.randint(low=1, high=self.size, size=(n_boxes,2))
top_left = torch.randint(low=0, high=self.size-1, size=(n_boxes, 2))
bottom_right = torch.clamp(top_left + box_sizes, 0, self.size -1)
rand_boxes = torch.concat((top_left,bottom_right), dim = 1)
return rand_image, rand_boxes.to(torch.uint8)
def collate_fn(batch):
images = torch.stack([b[0] for b in batch],dim=0)
boxes = [b[1] for b in batch]
return images, boxes
train_loader = DataLoader(
dataset = FakeDataset(),
batch_size=1024,
pin_memory=True,
num_workers=16,
collate_fn=collate_fn
)
Typically, each training step starts with copying the training batch from the host (CPU) to the device (GPU). When our data samples are of fixed sized, they are copied in batches. However, one of the implications of the varying number of faces per image is that the bounding box targets of each sample is copied separately requiring many more individual copy operations.
def data_to_device(data, device):
if isinstance(data, (list, tuple)):
return type(data)(
data_to_device(val, device) for val in data
)
elif isinstance(data, torch.Tensor):
return data.to(device=device, non_blocking=True)
Lastly, we define our training/evaluation loop. For the purposes of our discussion, we have chosen to focus just on the forward pass of our training loop. Note the inclusion of a PyTorch profiler object and our use of explicit synchronization events (to facilitate performance evaluation of different portions of the forward pass).
device = torch.device("cuda:0")
model = torch.compile(Net()).to(device).train()
# forward portion of training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=5, warmup=5, active=10, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf/'),
profile_memory=True
) as prof:
for step, data in enumerate(train_loader):
with torch.profiler.record_function('copy data'):
images, boxes = data_to_device(data, device)
torch.cuda.synchronize(device)
with torch.profiler.record_function('forward'):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(images)
torch.cuda.synchronize(device)
with torch.profiler.record_function('calc loss'):
loss = loss_fn(outputs, boxes)
torch.cuda.synchronize(device)
prof.step()
if step > 30:
break
# filter and print profiler results
event_list = prof.key_averages()
for i in range(len(event_list) - 1, -1, -1):
if event_list[i].key not in ['forward', 'calc loss', 'copy data']:
del event_list[i]
print(event_list.table())
Performance Analysis
Running our script on a Google Cloud g2-standard-16 VM (with a single L4 GPU), a dedicated deep learning VM image, and PyTorch 2.4.0, generates the output below (which we trimmed for readability).
------------- ------------ ------------
Name CPU total CPU time avg
------------- ------------ ------------
copy data 288.164ms 28.816ms
forward 1.192s 119.221ms
calc loss 9.381s 938.067ms
------------- ------------ ------------
Self CPU time total: 4.018s
Self CUDA time total: 10.107s
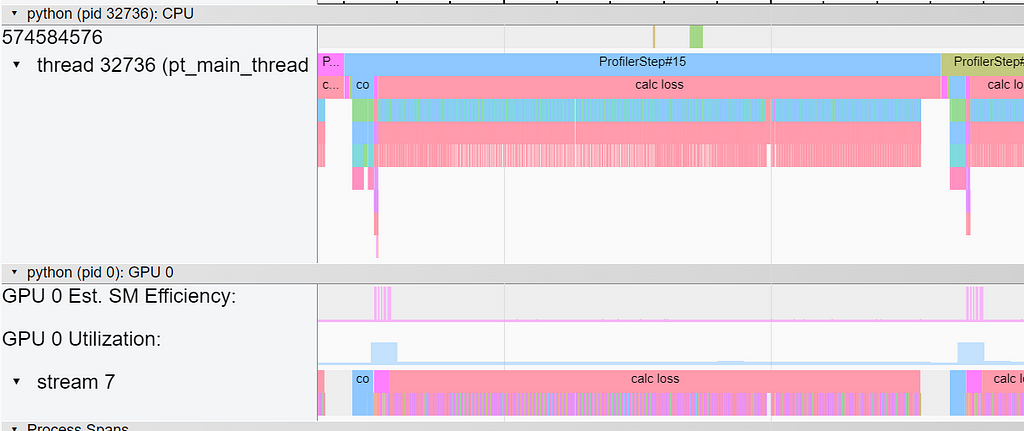
Despite the fact that the loss function contains far fewer operations, it completely dominates the overall step time. The overhead of the repeated invocations of the underlying GPU kernels (for each sample in the batch) is clearly evident in the Trace view in TensorBoard:
Optimization Through Concatenation
One way to reduce the number of calls to the loss function is to combine together all of the valid boxes each batch using concatenation, as shown in the following block.
def loss_with_concat(pred, targets_list):
bs = len(targets_list)
all_targets = torch.concat(targets_list, dim = 0)
num_boxes = [targets_list[i].shape[0] for i in range(bs)]
all_preds = torch.concat([pred[i,: num_boxes[i]] for i in range(bs)],
dim=0)
total_boxes = sum(num_boxes)
loss_sum = generalized_box_iou(all_targets, all_preds).sum()
return loss_sum/max(total_boxes, 1)
The results of this optimization are captured below.
------------- ------------ ------------
Name CPU total CPU time avg
------------- ------------ ------------
copy data 522.326ms 52.233ms
forward 1.187s 118.715ms
calc loss 254.047ms 25.405ms
------------- ------------ ------------
Self CPU time total: 396.674ms
Self CUDA time total: 1.871s
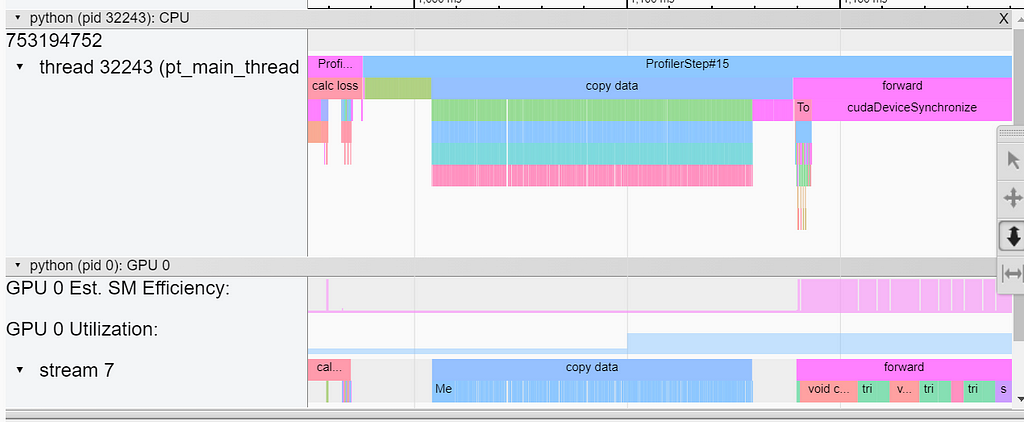
The concatenation optimization resulted in a 37X (!!) speed-up of the loss function. Note, however, that it did not address the overhead of the individual host-to-device copies of the sample ground-truth data. This overhead is captured in the screenshot below from TensorBoard’s Trace view:
Optimization Through Padding
A common approach to avoiding the use of dynamically shaped tensors is padding. In the following code block, we modify the collate function to pad (with zeros) the ground-truth bounding-boxes of each data sample to the maximum number of supported boxes, 256. (Note, that the padding could also have been performed in the Dataset class.)
def collate_with_padding(batch):
images = torch.stack([b[0] for b in batch],dim=0)
padded_boxes = []
for b in batch:
p = torch.nn.functional.pad(
b[1], (0, 0, 0, 256 - b[1].shape[0]), value = 0)
padded_boxes.append(p)
boxes = torch.stack(padded_boxes,dim=0)
return images, boxes
Padding the samples to fixed sized tensors enables us to copy the ground truth of the batch with a single call. It also allows us to compute the loss with a single invocation of the loss function. Note, that this method requires masking the resultant loss, as shown below, so that only the valid boxes are taken into consideration.
def loss_with_padding(pred, targets):
mask = (targets[...,3] > 0).to(pred.dtype)
total_boxes = mask.sum()
loss = generalized_box_iou(targets, pred)
masked_loss = loss*mask
loss_sum = masked_loss.sum()
return loss_sum/torch.clamp(total_boxes, 1)
The resultant runtime performance is captured below:
------------- ------------ ------------
Name CPU total CPU time avg
------------- ------------ ------------
copy data 57.125ms 5.713ms
forward 1.315s 131.503ms
calc loss 18.438ms 1.844ms
------------- ------------ ------------
Self CPU time total: 11.723ms
Self CUDA time total: 1.378s
Note the nearly 10X boost in the data copy and the additional 14X boost in the loss function performance. Keep in mind that padding may increase the use of the GPU memory. In our case, this increase is less than 1%.
While the runtime of our loss function has improved dramatically, we note that the vast majority of the calculations that are performed in the loss functions are immediately masked away. We can’t help but wonder whether there is a way to further improve the performance by avoiding these redundant operations. In the next section, we will explore the opportunities provided by using custom CUDA kernels.
Creating a Custom CUDA Kernel
Many tutorials will highlight the difficulty of creating CUDA kernels and the high entrance barrier. While mastering CUDA development and tuning kernels to maximize the utilization of the GPU could, indeed, require years of experience as well as an intimate understanding of the GPU architecture, we strongly believe that even a novice (but ambitious) CUDA enthusiast/ML developer can succeed at — and greatly benefit from — building custom CUDA kernels. In this section we will take PyTorch’s (relatively simple) example of a C++/CUDA extension for PyTorch and enhance it with a GIOU kernel. We will do this in two stages: First we will naïvely carry over all of the GIOU logic to C++/CUDA to assess the performance impact of kernel fusion. Then, we will take advantage of our new-found low-level control to add conditional logic and reduce unneeded arithmetic operations.
Developing CUDA kernels allows you to determine the core logic that is performed in each of the GPU threads and how these are distributed onto the underlying GPU streaming multiprocessors (SMs). Doing this in the most optimal manner requires an expert understanding of the GPU architecture including the different levels of GPU memory, memory bandwidth, the on-chip acceleration engines (e.g., TensorCores), the supported number of concurrent threads per SM and how they are scheduled, and much much more. What makes things even more complicated is that these properties can vary between GPU generations and flavors. See this blog for a very basic, but very easy, introduction to CUDA.
Step 1 — Kernel Fusion
Looking back at the Trace view of our last experiment, you may notice that the forward pass of our loss calculation includes roughly thirty independent arithmetic operations which of which translate to launching and running an independent CUDA kernel (as can be seen by simply counting the number of cudaLaunchKernel events). This can negatively impact performance in a number of ways. For example:
- Each kernel launch requires dedicated communication between the CPU and GPU — something we always try to minimize.
- Each kernel needs to wait for the previous kernel to be completed before running. Sometimes, this can’t be avoided, but in some cases, such as ours — where most of the operations are performed “per-pixel”, it can.
- The use of many independent kernels can have implications on how the GPU memory is used.
Optimization through kernel fusion attempts to reduce this overhead by combining these operations into a lower number of kernels so as to reduce the overhead of multiple kernels.
In the code block below, we define a kernel that performs our GIOU on a single bounding-box prediction-target pair. We use a 1-D grid to allocate thread blocks of size 256 each where each block corresponds one sample in the training batch and each thread corresponds to one bounding box in the sample. Thus, each thread — uniquely identified by a combination of the block and thread IDs — receives the predictions (boxes1) and targets(boxes2) and performs the GIOU calculation on the single bounding box determined by the IDs. As before, the “validity” of the bounding box is controlled by the value of the target boxes. In particular, the GIOU is explicitly zeroed wherever the corresponding box is invalid.
#include <torch/extension.h>
#include <cuda.h>
#include <cuda_runtime.h>
namespace extension_cpp {
__global__ void giou_kernel(const float* boxes1,
const float* boxes2,
float* giou,
bool* mask) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
bool valid = boxes2[4*idx+3] != 0;
mask[idx] = valid;
const float epsilon = 1e-5;
const float* box1 = &boxes1[idx * 4];
const float* box2 = &boxes2[idx * 4];
// Compute area of each box
float area1 = (box1[2] - box1[0]) * (box1[3] - box1[1]);
float area2 = (box2[2] - box2[0]) * (box2[3] - box2[1]);
// Compute the intersection
float left = max(box1[0], box2[0]);
float top = max(box1[1], box2[1]);
float right = min(box1[2], box2[2]);
float bottom = min(box1[3], box2[3]);
float inter_w = right - left;
float inter_h = bottom - top;
float inter_area = inter_w * inter_h;
// Compute the union area
float union_area = area1 + area2 - inter_area;
// IoU
float iou_val = inter_area / max(union_area, epsilon);
// Compute the smallest enclosing box
float enclose_left = min(box1[0], box2[0]);
float enclose_top = min(box1[1], box2[1]);
float enclose_right = max(box1[2], box2[2]);
float enclose_bottom = max(box1[3], box2[3]);
float enclose_w = enclose_right - enclose_left;
float enclose_h = enclose_bottom - enclose_top;
float enclose_area = enclose_w * enclose_h;
float result = iou_val - (enclose_area-union_area)/max(enclose_area, epsilon);
// Generalized IoU
giou[idx] = result * valid;
}
at::Tensor giou_loss_cuda(const at::Tensor& a, const at::Tensor& b) {
TORCH_CHECK(a.sizes() == b.sizes());
TORCH_CHECK(a.dtype() == at::kFloat);
TORCH_CHECK(b.dtype() == at::kFloat);
TORCH_INTERNAL_ASSERT(a.device().type() == at::DeviceType::CUDA);
TORCH_INTERNAL_ASSERT(b.device().type() == at::DeviceType::CUDA);
int bs = a.sizes()[0];
at::Tensor a_contig = a.contiguous();
at::Tensor b_contig = b.contiguous();
at::Tensor giou = torch::empty({a_contig.sizes()[0], a_contig.sizes()[1]},
a_contig.options());
at::Tensor mask = torch::empty({a_contig.sizes()[0], a_contig.sizes()[1]},
a_contig.options().dtype(at::kBool));
const float* a_ptr = a_contig.data_ptr<float>();
const float* b_ptr = b_contig.data_ptr<float>();
float* giou_ptr = giou.data_ptr<float>();
bool* mask_ptr = mask.data_ptr<bool>();
// Launch the kernel
// The number of blocks is set according to the batch size.
// Each block has 256 threads corresponding to the number of boxes per sample
giou_kernel<<<bs, 256>>>(a_ptr, b_ptr, giou_ptr, mask_ptr);
at::Tensor total_boxes = torch::clamp(mask.sum(), 1);
torch::Tensor loss_sum = giou.sum();
return loss_sum/total_boxes;
}
// Registers CUDA implementations for giou_loss
TORCH_LIBRARY_IMPL(extension_cpp, CUDA, m) {
m.impl("giou_loss", &giou_loss_cuda);
}
}
To complete the kernel creation, we need to add the appropriate C++ and Python operator definitions (see muladd.cpp and ops.py)
// Add the C++ definition
m.def(“giou_loss(Tensor a, Tensor b) -> Tensor”);
# define the Python operator
def giou_loss(a: Tensor, b: Tensor) -> Tensor:
return torch.ops.extension_cpp.giou_loss.default(a, b)
To compile our kernel run the installation script (pip install .) from the base directory.
The following block uses our newly defined GIOU CUDA kernel:
def loss_with_kernel(pred, targets):
pred = pred.to(torch.float32)
targets = targets.to(torch.float32)
import extension_cpp
return extension_cpp.ops.giou_loss(pred, targets)
Note the explicit casting to torch.float32. This is a rather expensive operation that could be easily avoided by enhancing our CUDA kernel support. We leave this as an exercise to the reader :).
The results of running our script with our custom kernel are displayed below.
------------- ------------ ------------
Name CPU total CPU time avg
------------- ------------ ------------
copy data 56.901ms 5.690ms
forward 1.327s 132.704ms
calc loss 6.287ms 628.743us
------------- ------------ ------------
Self CPU time total: 6.907ms
Self CUDA time total: 1.380s
Despite the naïveté of our kernel (and our inexperience at CUDA), we have boosted the loss function performance by an additional ~3X over our previous experiment (628 microseconds compare to 1.8 milliseconds). With some more. As noted above, this can be improved even further without much effort.
Step 2 — Conditional Execution
The thread-level control that CUDA provides us allows us to add a conditional statement that avoids computation on the invalid bounding boxes:
__global__ void giou_kernel(const float* boxes1,
const float* boxes2,
float* giou,
bool* mask) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
bool valid = boxes2[4*idx+3] != 0;
mask[idx] = valid;
if (valid)
{
const float* box1 = &boxes1[idx * 4];
const float* box2 = &boxes2[idx * 4];
giou[idx] = compute_giou(box1, box2);
}
else
{
giou[idx] = 0;
}
}
In the case of our kernel, the impact on runtime performance is negligible. The reason for this (presumably) is that our kernel is relatively small to the point that its runtime is negligible compared to the time require to load and instantiate it. The impact of our conditional execution might only become apparent for larger kernels. (The impact, as a function of the kernel size can be assessed by making our GIOU output dependent on a for loop that we run for a varying number of fixed steps. This, too, we leave as an exercise :).) It is also important to take into consideration how a conditional execution flows behave on CUDA’s SIMT architecture, particularly, the potential performance penalty when threads belonging to the same warp diverge.
------------- ------------ ------------
Name CPU total CPU time avg
------------- ------------ ------------
copy data 57.008ms 5.701ms
forward 1.318s 131.850ms
calc loss 6.234ms 623.426us
------------- ------------ ------------
Self CPU time total: 7.139ms
Self CUDA time total: 1.371s
Results and Next Steps
We summarize the results of our experiments in the table below.
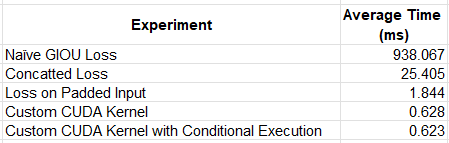
Importantly, our work is not done. Admittedly, we have taken some shortcuts in the example we have shared:
- In order to use our custom kernel for training, we would need to implement the backward pass. Typically, this can be a bit more complicated than the forward pass.
- We have fixed both the tensor types (to float32) and tensor shapes (to 256 boxes per sample). Ideally, a more robust solution is desired that supports varying input types and shapes.
- We limited our experiments to a single GPU type. In reality, we would want our implementation to support (and be tested on) multiple GPUs.
- We have completely neglected opportunities for kernel optimization — some of which may require greater CUDA expertise than we have demonstrated here.
Summary
In this post we demonstrated the potential of the use of a custom CUDA kernel on the runtime performance of AI/ML applications. We attempted, in particular, to utilize the low-level control enabled by CUDA to introduce a conditional flow to limit the number of redundant arithmetic operations in the case of dynamically shaped inputs. While the performance boost resulting from the fusion of multiple kernel operations was significant, we found the size of our kernel to be too small to benefit from the conditional execution flow.
Throughout many of our posts we have emphasized the importance of having multiple tools and techniques for optimizing ML and reducing its costs. Custom kernel development is one of the most powerful techniques at our disposal. However, for many AI/ML engineers, it is also one of the most intimidating techniques. We hope that we have succeeded in convincing you that this opportunity is within reach of any ML developer and that it does not require major specialization in CUDA.
In recent years, new frameworks have been introduced with the goal of making custom kernel development and optimization more accessible to AI/ML developers. One of the most popular of these frameworks is Triton. In our next post we will continue our exploration of the topic of custom kernel development by assessing the capabilities and potential impact of developing Triton kernels.
Accelerating AI/ML Model Training with Custom Operators was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Accelerating AI/ML Model Training with Custom Operators
Go Here to Read this Fast! Accelerating AI/ML Model Training with Custom Operators