
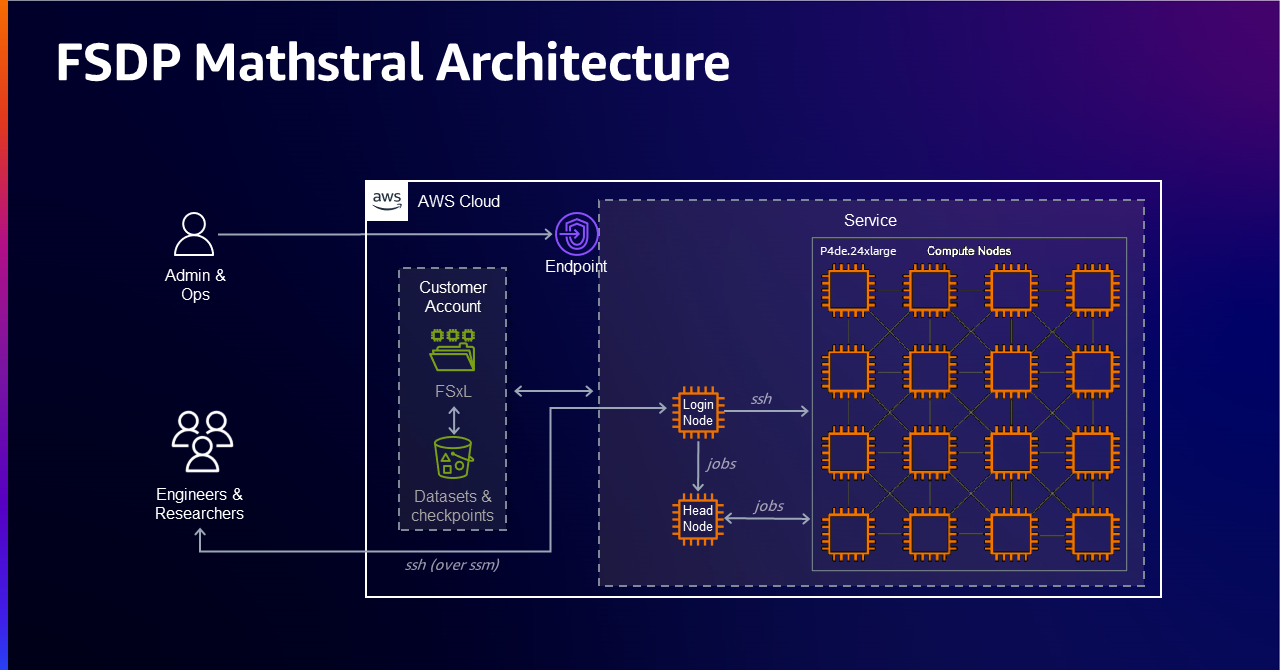
In this post, we present to you an in-depth guide to starting a continual pre-training job using PyTorch Fully Sharded Data Parallel (FSDP) for Mistral AI’s Mathstral model with SageMaker HyperPod.
Originally appeared here:
Accelerate pre-training of Mistral’s Mathstral model with highly resilient clusters on Amazon SageMaker HyperPod