

From LLaVA, Flamingo, to NVLM
Multi-modal LLM development has been advancing fast in recent years.
Although the commercial multi-modal models like GPT-4v, GPT-4o, Gemini, and Claude 3.5 Sonnet are the most eye-catching performers these days, the open-source models such as LLaVA, Llama 3-V, Qwen-VL have been steadily catching up in terms of performance on public benchmarks.
Just last month, Nvidia released their open-source multi-modal LLM family called NVLM. The family comprises three architectures: a) decoder-based, b) cross-attention-based, and c) hybrid. The decoder-based model takes both the image and text tokens to a pre-trained LLM, such as the LLaVA model. The cross-attention-based model uses the image token embeddings as the keys and values while using the text token embeddings as the queries; since the attention is calculated using different sources, it’s called “cross-attention” as in the original transformer decoder rather than the self-attention as in decoder-only models. The hybrid architecture is a unique design merging the decoder and cross-attention architecture for the benefit of multi-modal reasoning, fewer training parameters, and taking high-resolution input. The 72B decoder-based NVLM-D model achieved an impressive performance, beating state-of-the-art open-source and commercial models on tasks like natural image understanding and OCR.
In this article, I’m going to walk through the following things:
- the dynamic high-resolution (DHR) vision encoder, which all the NVLM models adopt
- the decoder-based model, NVLM-D, compared to LLaVA
- the gated cross-attention model, NVLM-X, compared to Flamingo
- the hybrid model, NVLM-H
In the end, I’ll show the NVLM-D 72B performance. Compared to state-of-the-art open-source and commercial models, the NVLM-D model shows stability over text-based tasks and superior performance on natural understanding and OCR tasks.
Dynamic High-Resolution-based Vision Encoder (DHR)
One of the prominent advantages of NVLM models is that they excel in processing OCR-related tasks, which require high-resolution image inputs. NVML adopts the dynamic high-resolution approach proposed in the InternVL 1.5 technical report to retain high resolution. The DHR approach first converts a high resolution image into a pre-defined aspect ratio size (also called dynamic aspect ratio matching), before splitting it into non-overlapping 448*448 tiles with an extra thumb-nail image, which can retain better global information.

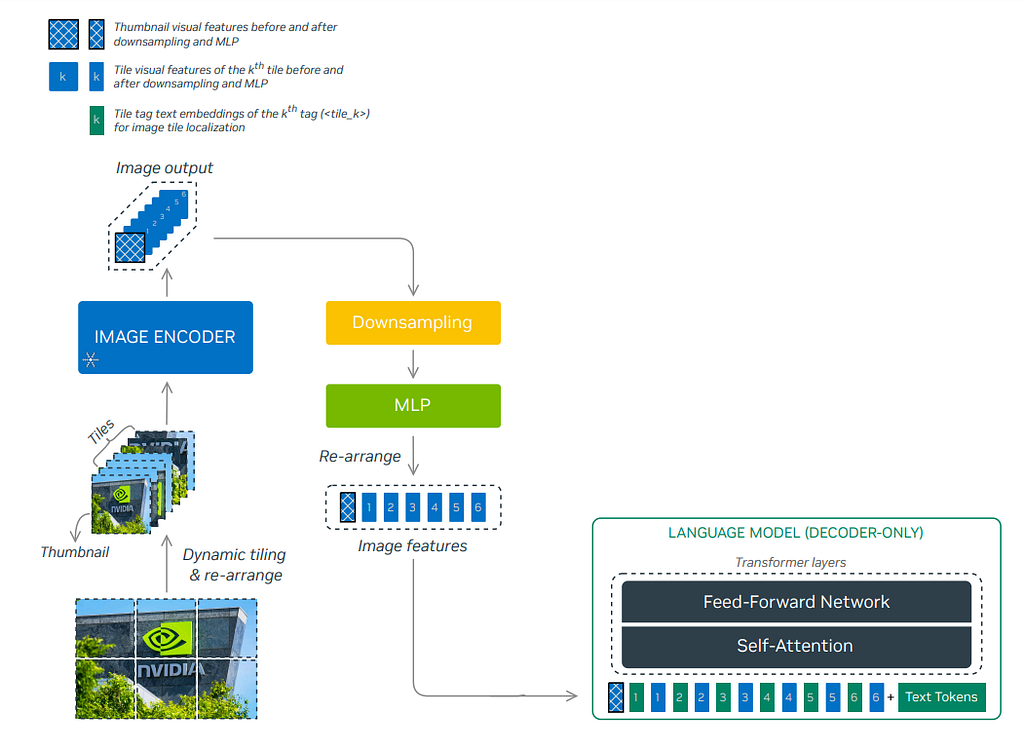
The image above shows a detailed explanation of the DHR pipeline. An input image is shown on the left, and a list of 6 different pre-defined aspect ratios is searched and matched to the original image shape. Then, the reshaped image is cropped into six non-overlapping tiles of 448*448, with an extra underresolution thumbnail image to capture global information. The sequence of n tiles (n=6+1=7 in this case) is passed into the ViT separately and converted into a sequence of length n with 1024 tokens (448/14*448/14=1024), each of embedding dimension d. To reduce the computational cost, a pixel reshuffle operation is employed to resize the 32*32 patch to 16*16, which reduces the final output token size to 256 with an increased embedding dimension of 4*d.
Decoder-only Models: NVLM-D vs LLaVA
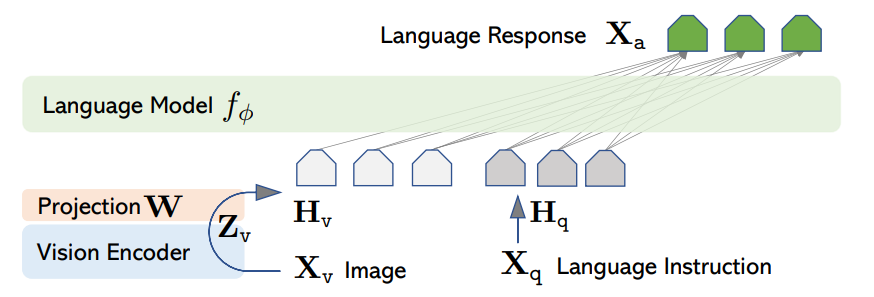
LLaVA is a well-known decoder-based Multi-modal LLM, which takes in the image X_v and uses a pre-trained CLIP encoder ViT-L/14 as vision encoder Z_v, with a trainable linear project layer W to convert into embedding tokens H_v, which can be digested together with other text tokens. The LLaVA architecture is shown below.
In contrast, the NVLM-D architecture takes in encoded tile sequence tokens using the DHR vision encoder and inserts tile tags in between before concatenating with the text tokens for the transformer layer ingestion. The architecture is shown below.
Cross-attention Models: NVLM-X vs Flamingo
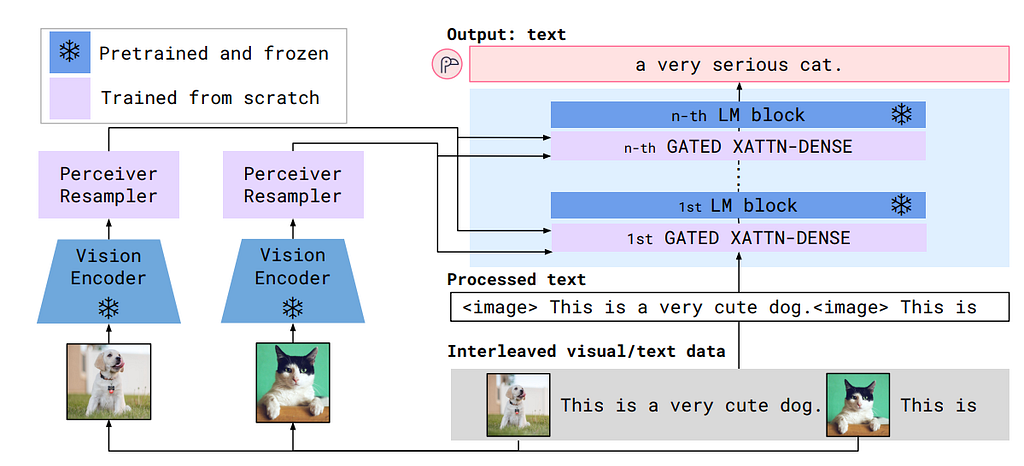
Comparing to LLaVA, the Flamingo model uses a more complicated cross-attention technique, which takes the vision embeddings as keys (K) and values (V), while the text embeddings as queries (Q). Moreover, the vision encoder is a CNN-based model with a Perceiver Resampler, which takes in a sequence of image(s) with temporal positional embedding to train learnable latent query vectors using cross attention. A more detailed discussion of the Perceiver Resampler can be found in my latest article here.
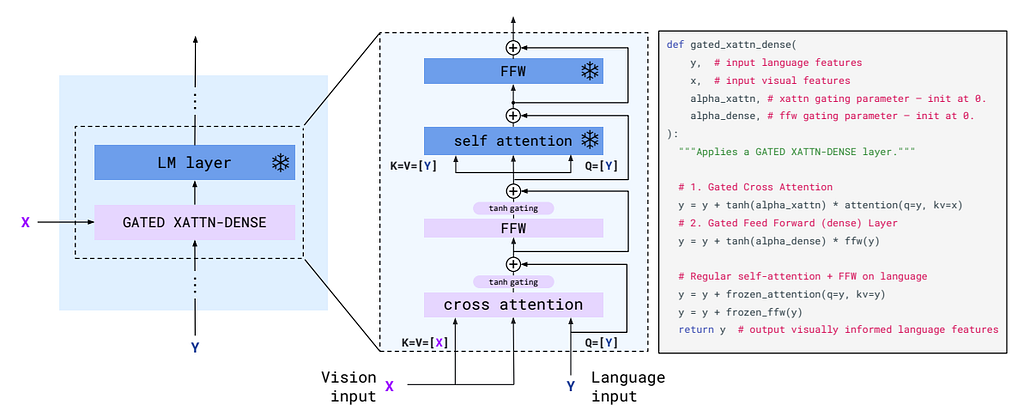
To fuse the vision embedding and text embedding, the Flamingo freezes the pre-trained LLM layers and further adds a trainable gated cross-attention layer in between, which is shown below. The gated attention uses a tanh gating with a learnable alpha parameter after the cross-attention layer and the subsequent linear layer. When the tanh gating is initialized as zero, the only information passed is through the skip connection, so the whole model will still be the original LLM to increase stability.
In comparison, the NVLM-X removes the Perceiver Resampler design for the benefit of OCR tasks to keep the more spatial relationship and only uses the DHR encoder output for the gated cross-attention. Unlike the decoder-based model, the NVLM-X concatenates the tile tags to the text tokens before sending them into the gated cross-attention. The whole architecture is shown below.
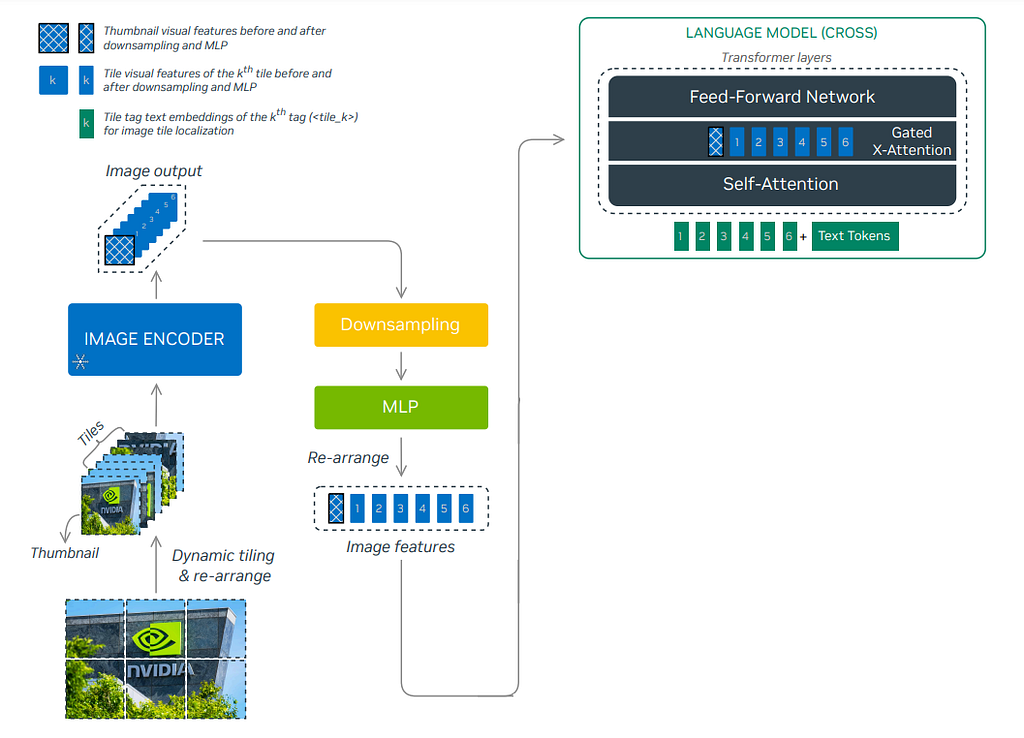
Hybrid Models: NVLM-H
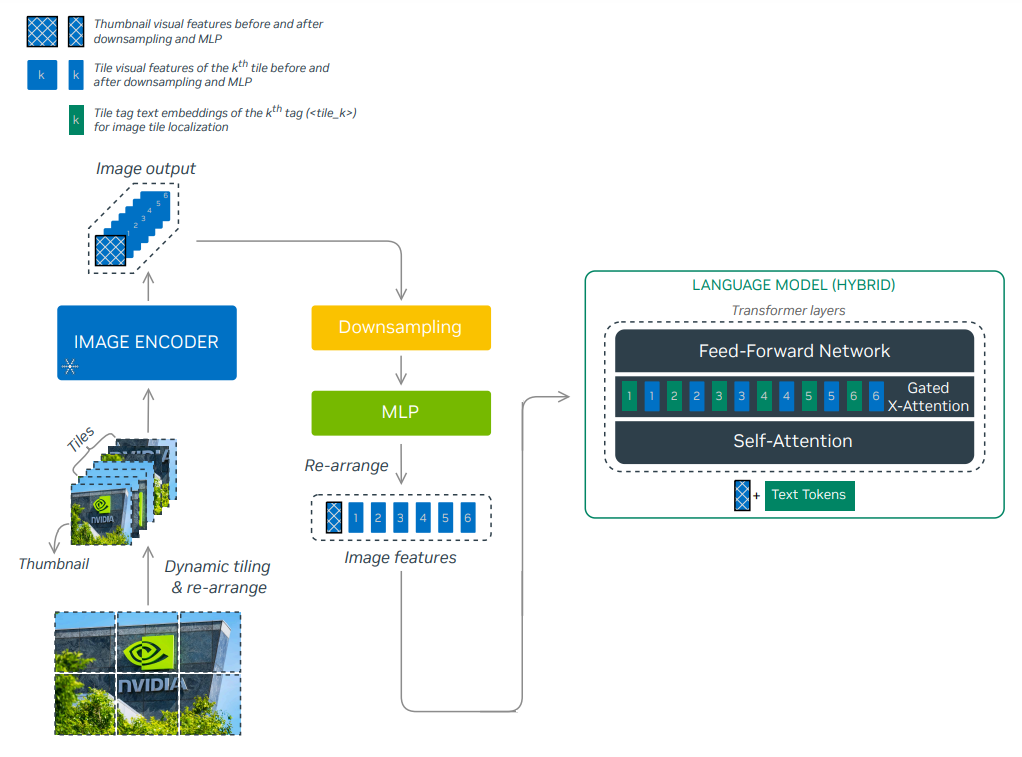
The hybrid model is a unique design by NVLM. The thumbnail image token is added to the text tokens as input to the self-attention layer, which preserves the benefit of multi-modal reasoning from the decoder-based model. The other image tiles and tile tags are passed into the gated cross-attention layer to capture finer image details while minimizing total model parameters. The detailed architecture is shown below.
Performance
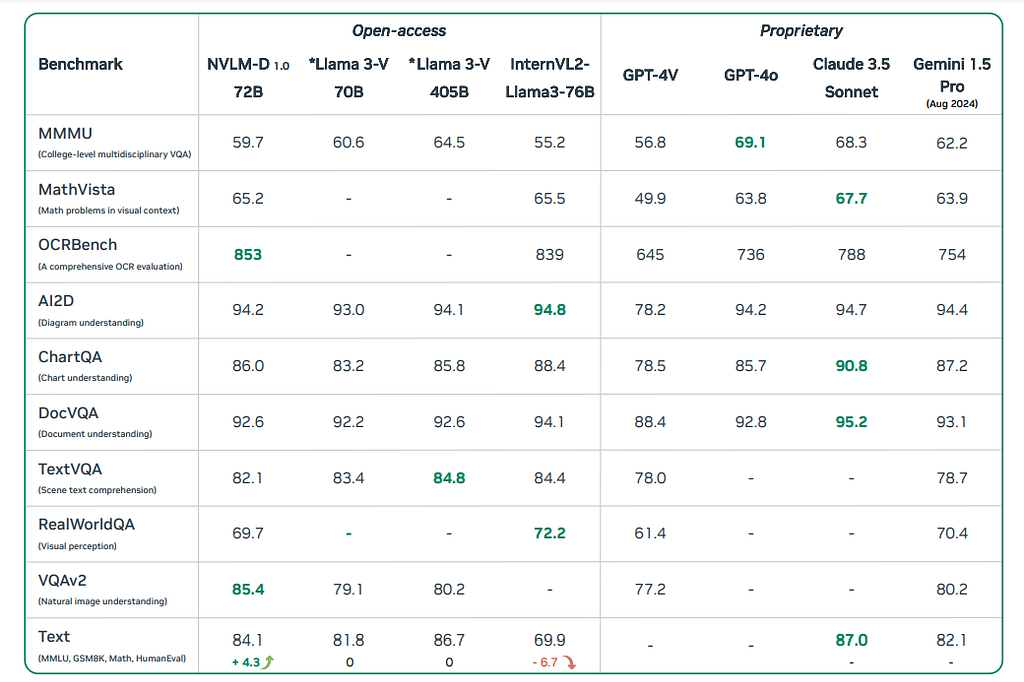
So, how’s the performance of NVLM compared to other state-of-the-art models? The paper lists benchmark performances comparing NVLM-D 72B to other open-source models like Llama-3 V and commercial models like GPT-4o. The NVLM-D achieved above-average performance on most benchmarks and excelled in the OCR and natural image understanding tasks due to the high-resolution image features and the model’s intrinsic multi-modal reasoning ability. Compared to Llama 3-V 70B and InternVL2-Llama3–76B, which have the equivalent amount of parameter numbers, the NVLM-D shows the advantage of having more consistent behaviours on the text-only tasks, the VQA task and the image understanding tasks. The detailed comparison is shown as follows.
It’s also interesting to note that, although the decoder-based model is very powerful, the training throughput (numbers of sampled trained per second) is much lower than the cross-attention-based model. The paper explains that the decoder-based model takes a much longer sequence length than the cross-attention-based model, which causes a much higher GPU consumption and lower throughput. The detailed training comparison is shown below:

References
- Dai et al., NVLM: Open Frontier-Class Multimodal LLMs. arXiv 2024.
- Chen et al., How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites. arXiv 2024.
- Liu et al., Visual Instruction Tuning. NeurIPS 2023.
- Bai et al., Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv 2023.
- Alayrac et al., Flamingo: a Visual Language Model for Few-Shot Learning. NeurIPS 2022.
A Walkthrough of Nvidia’s Latest Multi-Modal LLM Family was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Walkthrough of Nvidia’s Latest Multi-Modal LLM Family
Go Here to Read this Fast! A Walkthrough of Nvidia’s Latest Multi-Modal LLM Family