
Improve accuracy, speed, and memory usage by performing PCA transformation before outlier detection
This article continues a series related to applications of PCA (principle component analysis) for outlier detection, following Using PCA for Outlier Detection. That article described PCA itself, and introduced the two main ways we can use PCA for outlier detection: evaluating the reconstruction error, and running standard outlier detectors on the PCA-transformed space. It also gave an example of the first approach, using reconstruction error, which is straightforward to do using the PCA and KPCA detectors provided by PyOD.
This article covers the second approach, where we first transform the data space using PCA and then run standard outlier detection on this. As covered in the previous article, this can in some cases lower interpretability, but it does have some surprising benefits in terms of accuracy, execution time, and memory usage.
This article is also part of a larger series on outlier detection, so far covering FPOF, Counts Outlier Detector, Distance Metric Learning, Shared Nearest Neighbors, and Doping. This article also includes another excerpt from my book Outlier Detection in Python.
If you’re reasonably familiar with PCA itself (as it’s used for dimensionality reduction or visualization), you can probably skip the previous article if you wish, and dive straight into this one. I will, though, very quickly review the main idea.
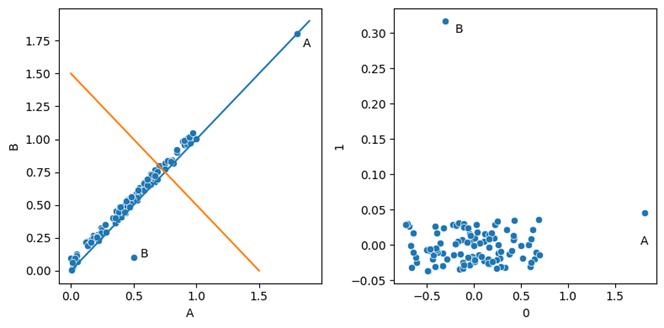
PCA is a means to transform data (viewing data records as points in high-dimensional space) from one set of coordinates to another. If we start with a dataset (as shown below in the left pane), with 100 records and two features, then we can view the data as 100 points in 2-dimensional space. With more realistic data, we would have many more records and many more dimensions, but the same idea holds. Using PCA, we move the data to a new set of coordinates, so effectively create a new set of features describing each record. As described in the previous article, this is done by identifying orthogonal lines through the data (shown in the left pane as the blue and orange lines) that fit the data well.
So, if we start with a dataset, such as is shown in the left pane below, we can apply PCA transformation to transform the data into something like is shown in the right pane. In the right pane, we show the two PCA components the data was mapped to. The components are simply named 0 and 1.
One thing to note about PCA components is that they are completely uncorrelated. This is a result of how they are constructed; they are based on lines, planes, or hyperplanes through the original data that are all strictly orthogonal to each other. We can see in the right pane, there is no relationship between component 0 and component 1.
This has strong implications for outlier detection; in particular it means that outliers tend to be transformed into extreme values in one or more of the components, and so are easier to detect. It also means that more sophisticated outlier tests (that test for unusual associations among the features) are not necessary, and simpler tests can be used.
Univariate and Multivariate outer detectors
Before looking closer at the benefits of PCA for for outlier detection, I’ll quickly go over two types of outlier detectors. There are many ways to classify outlier detection algorithms, but one useful way is to distinguish between what are called univariate from multivariate tests.
Univariate Tests
The term univariate refers to tests that just check one feature — tests that identify the rare or extreme values in that one feature. Examples are tests based on z-score, interquartile range (IQR), inter-decile range (IDR), median absolute deviation (MAD), histogram tests, KDE tests, and so on.
One histogram-based test provided by PyOD (PyOD is probably the most complete and useful tool for outlier detection on tabular data available in Python today) is HBOS (Histogram-based Outlier Score — described in my Medium article on Counts Outlier Detector, and in detail in Outlier Detection in Python).
As covered in Using PCA for Outlier Detection, another univariate test provided by PyOD is ECOD.
To describe univariate tests, we look at an example of outlier detection for a specific real-world dataset. The following table is a subset of the baseball dataset from OpenML (available with a public license), here showing just three rows and five columns (there are several more features in the full dataset). Each row represents one player, with statistics for each, including the number of seasons they played, number of games, and so on.
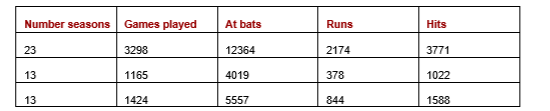
To identify unusual players, we can look for those records with unusual single values (for example, players that played in unusually many seasons, had unusually many At bats, and so on). These would be found with univariate tests.
For example, using z-score tests to find unusual records, we would actually perform a z-score test on each column, one at a time. We’d first check the Number seasons column (assessing how unusual each value in the column is relative to that column), then the Games played column and so on.
When checking, for example, the Number seasons column, using a z-score test, we would first determine the mean and standard deviation of the column. (Other tests may determine the median and interquartile range for the column, histogram bin counts, etc.).
We would then determine the absolute z-score for each value in the Number seasons column: the number of standard deviations each value is from the mean. The larger the z-score, the more unusual the value. Any values with an absolute z-score over about 4.0 or 5.0 can likely be considered anomalous, though this depends on the size of the data and the distribution.
We’d then repeat this for each other column. Once this is done, we have, for each row, a score for how unusual each value in the row is relative to their columns. So, each row would have a set of scores: one score for each value in that row.
We then need to determine an overall outlier score for each record. There are different ways to do this, and some nuances associated with each, but two simple methods are to take the average z-score of the values per row, or to take the maximum z-score per row.
Multivariate Tests
Multivariate tests consider multiple features at once. In fact, almost all multivariate outlier detectors consider all features at once.
The majority of outlier detectors (including Isolation Forest, Local Outlier Factor (LOF), KNN, and so on) are based on multivariate tests.
The advantage of these detectors is, we can look for records with unusual combinations of values. For example, some players may have a typical number of Runs and a typical number of At bats, but may have unusually many (or possibly unusually few) Runs given their number of At bats. These would be found with multivariate tests.
In the scatter plot above (considering the original data in the left pane), Point A is extreme in both dimensions, so could be detected by a univariate test. In fact, a univariate test on Feature A would likely flag Point A, and a univariate test on Feature B would likely as well, and so Point A, being anomalous in both features, would be scored highly using univariate tests.
Point B, though, is typical in both dimensions. Only the combination of values is unusual, and to detect this as an anomaly, we would require a multivariate test.
Normally, when performing outlier detection on tabular data, we’re looking for unusual rows, as opposed to unusual single values. And, unusual rows will include both those rows with unusual single values, as well as unusual combinations of values. So, both univariate and multivariate tests are typically useful. However, multivariate tests will catch both univariate and multivariate outliers (in the scatter plot, a multivariate test such as Isolation Forest, LOF, or KNN would generally catch both Point A and Point B), and so in practice, multivariate tests tend to be used more often.
Nevertheless, in outlier detection do we quite often limit analysis to univariate tests. Univariate tests are faster — often much faster (which can be very important in real-time environments, or environments where there are very large volumes of data to assess). Univariate tests also tend to be more interpretable.
And they don’t suffer from the curse of dimensionality. This is covered in Counts Outlier Detector, Shared Nearest Neighbors, and Outlier Detection in Python, but the general idea is that multivariate tests can break down when working with too many features. This is for a number of reasons, but an important one is that distance calculations (which many outlier detectors, including LOF and KNN, rely on) can become meaningless given enough dimensions. Often working with just 20 or more features, and very often with about 50 or more, outlier scores can become unreliable.
Univariate tests scale to higher dimensions much better than multivariate tests, as they do not rely on distance calculations between the rows.
And so, there are some major advantages to using univariate tests. But, also some major disadvantages: these miss outliers that relate to unusual combinations of values, and so can detect only a portion of the relevant outliers.
Univariate tests on PCA components
So, in most contexts, it’s useful (and more common) to run multivariate tests. But, they are slower, less interpretable, and more susceptible to the curse of dimensionality.
An interesting effect of PCA transformation is that univariate tests become much more practical. Once PCA transformation is done, there are no associations between the features, and so there is no concept of unusual combinations of values.
In the scatter plot above (right pane — after the PCA transformation), we can see that Points A and B can both be identified simply as extreme values. Point A is extreme in Component 0; Point B is extreme in Component 1.
Which means, we can perform outlier detection effectively using simple statistical tests, such as z-score, IQR, IDR or MAD tests, or using simple tools such as HBOS and ECOD.
Having said that, it’s also possible, after transforming the dataspace using PCA, to still use standard multivariate tests such as Isolation Forest, LOF, or any other standard tools. If these are the tools we most commonly use, there is a convenience to continuing to use them, and to simply first transform the data using PCA as a pre-processing step.
One advantage they provide over statistical methods (such as z-score, etc.) is that they automatically provide a single outlier score for each record. If we use z-score tests on each record, and the data has, say, 20 features and we convert this to 10 components (it’s possible to not use all components, as described below), then each record will have 10 outlier scores — one related to how unusual it is in each of the 10 components used. It’s then necessary to combine these scores into a single outlier score. As indicated above, there are simple ways to do this (including taking the mean, median, or maximum z-score for each value per row), but there are some complications doing this (as covered in Outlier Detection in Python). This is quite manageable, but having a detector provide a single score is convenient as well.
Example of outlier detection with PCA
We’ll now look at an example using PCA to help better identify outliers in a dataset. To make it easier to see how outlier detection works with PCA, for this example we’ll create two quite straightforward synthetic datasets. We’ll create both with 100,000 rows and 10 features. And we add some known outliers, somewhat similar to Points A and B in the scatter plot above.
We limit the datasets to ten features for simplicity, but as suggested above and in the previous article, there can be strong benefits to using PCA in high-dimensional space, and so (though it’s not covered in this example), more of an advantage to using PCA with, say, hundreds of features, than ten. The datasets used here, though, are reasonably easy to work with and to understand.
The first dataset, data_corr, is created to have strong associations (correlations) between the features. We update the last row to contain some large (but not exceptionally large) values. The main thing is that this row deviates from the normal patterns between the features.
We create another test dataset called data_extreme, which has no associations between the features. The last row of this is modified to contain extreme values in some features.
This allows us to test with two well-understood data distributions as well as well-understood outlier types (we have one outlier in data_corr that ignores the normal correlations between the features; and we have one outlier in data_extreme that has extreme values in some features).
This example uses several PyOD detectors, which requires first executing:
pip install pyod
The code then starts with creating the first test dataset:
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from pyod.models.ecod import ECOD
from pyod.models.iforest import IForest
from pyod.models.lof import LOF
from pyod.models.hbos import HBOS
from pyod.models.gmm import GMM
from pyod.models.abod import ABOD
import time
np.random.seed(0)
num_rows = 100_000
num_cols = 10
data_corr = pd.DataFrame({0: np.random.random(num_rows)})
for i in range(1, num_cols):
data_corr[i] = data_corr[i-1] + (np.random.random(num_rows) / 10.0)
copy_row = data_corr[0].argmax()
data_corr.loc[num_rows-1, 2] = data_corr.loc[copy_row, 2]
data_corr.loc[num_rows-1, 4] = data_corr.loc[copy_row, 4]
data_corr.loc[num_rows-1, 6] = data_corr.loc[copy_row, 6]
data_corr.loc[num_rows-1, 8] = data_corr.loc[copy_row, 8]
start_time = time.process_time()
pca = PCA(n_components=num_cols)
pca.fit(data_corr)
data_corr_pca = pd.DataFrame(pca.transform(data_corr),
columns=[x for x in range(num_cols)])
print("Time for PCA tranformation:", (time.process_time() - start_time))
We now have the first test dataset, data_corr. When creating this, we set each feature to be the sum of the previous features plus some randomness, so all features are well-correlated. The last row is deliberately set as an outlier. The values are large, though not outside of the existing data. The values in the known outlier, though, do not follow the normal patterns between the features.
We then calculate the PCA transformation of this.
We next do this for the other test dataset:
np.random.seed(0)
data_extreme = pd.DataFrame()
for i in range(num_cols):
data_extreme[i] = np.random.random(num_rows)
copy_row = data_extreme[0].argmax()
data_extreme.loc[num_rows-1, 2] = data_extreme[2].max() * 1.5
data_extreme.loc[num_rows-1, 4] = data_extreme[4].max() * 1.5
data_extreme.loc[num_rows-1, 6] = data_extreme[6].max() * 1.5
data_extreme.loc[num_rows-1, 8] = data_extreme[8].max() * 1.5
start_time = time.process_time()
pca = PCA(n_components=num_cols)
pca.fit(data_corr)
data_extreme_pca = pd.DataFrame(pca.transform(data_corr),
columns=[x for x in range(num_cols)])
print("Time for PCA tranformation:", (time.process_time() - start_time))
Here each feature is created independently, so there are no associations between the features. Each feature simply follows a uniform distribution. The last row is set as an outlier, having extreme values in features 2, 4, 6, and 8, so in four of the ten features.
We now have both test datasets. We next define a function that, given a dataset and a detector, will train the detector on the full dataset as well as predict on the same data (so will identify the outliers in a single dataset), timing both operations. For the ECOD (empirical cumulative distribution) detector, we add special handling to create a new instance so as not to maintain a memory from previous executions (this is not necessary with the other detectors):
def evaluate_detector(df, clf, model_type):
"""
params:
df: data to be assessed, in a pandas dataframe
clf: outlier detector
model_type: string indicating the type of the outlier detector
"""
global scores_df
if "ECOD" in model_type:
clf = ECOD()
start_time = time.process_time()
clf.fit(df)
time_for_fit = (time.process_time() - start_time)
start_time = time.process_time()
pred = clf.decision_function(df)
time_for_predict = (time.process_time() - start_time)
scores_df[f'{model_type} Scores'] = pred
scores_df[f'{model_type} Rank'] =
scores_df[f'{model_type} Scores'].rank(ascending=False)
print(f"{model_type:<20} Fit Time: {time_for_fit:.2f}")
print(f"{model_type:<20} Predict Time: {time_for_predict:.2f}")
The next function defined executes for each dataset, calling the previous method for each. Here we test four cases: using the original data, using the PCA-transformed data, using the first 3 components of the PCA-transformed data, and using the last 3 components. This will tell us how these four cases compare in terms of time and accuracy.
def evaluate_dataset_variations(df, df_pca, clf, model_name):
evaluate_detector(df, clf, model_name)
evaluate_detector(df_pca, clf, f'{model_name} (PCA)')
evaluate_detector(df_pca[[0, 1, 2]], clf, f'{model_name} (PCA - 1st 3)')
evaluate_detector(df_pca[[7, 8, 9]], clf, f'{model_name} (PCA - last 3)')
As described below, using just the last three components works well here in terms of accuracy, but in other cases, using the early components (or the middle components) can work well. This is included here as an example, but the remainder of the article will focus just on the option of using the last three components.
The final function defined is called for each dataset. It executes the previous function for each detector tested here. For this example, we use six detectors, each from PyOD (Isolation Forest, LOF, ECOD, HBOS, Gaussian Mixture Models (GMM), and Angle-based Outlier Detector (ABOD)):
def evaluate_dataset(df, df_pca):
clf = IForest()
evaluate_dataset_variations(df, df_pca, clf, 'IF')
clf = LOF(novelty=True)
evaluate_dataset_variations(df, df_pca, clf, 'LOF')
clf = ECOD()
evaluate_dataset_variations(df, df_pca, clf, 'ECOD')
clf = HBOS()
evaluate_dataset_variations(df, df_pca, clf, 'HBOS')
clf = GMM()
evaluate_dataset_variations(df, df_pca, clf, 'GMM')
clf = ABOD()
evaluate_dataset_variations(df, df_pca, clf, 'ABOD')
We finally call the evaluate_dataset() method for both test datasets and print out the top outliers (the known outliers are known to be in the last rows of the two test datasets):
# Test the first dataset
# scores_df stores the outlier scores given to each record by each detector
scores_df = data_corr.copy()
evaluate_dataset(data_corr, data_corr_pca)
rank_columns = [x for x in scores_df.columns if type(x) == str and 'Rank' in x]
print(scores_df[rank_columns].tail())
# Test the second dataset
scores_df = data_extreme.copy()
evaluate_dataset(data_extreme, data_extreme_pca)
rank_columns = [x for x in scores_df.columns if type(x) == str and 'Rank' in x]
print(scores_df[rank_columns].tail())
There are several interesting results. We look first at the fit times for the data_corr dataset, shown in table below (the fit and predict times for the other test set were similar, so not shown here). The tests were conducted on Google colab, with the times shown in seconds. We see that different detectors have quite different times. ABOD is significantly slower than the others, and HBOS considerably faster. The other univariate detector included here, ECOD, is also very fast.
The times to fit the PCA-transformed data are about the same as the original data, which makes sense given this data is the same size: we converted the 10 features to 10 components, which are equivalent, in terms of time, to process.
We also test using only the last three PCA components (components 7, 8, and 9), and the fit times are drastically reduced in some cases, particularly for local outlier factor (LOF). Compared to using all 10 original features (19.4s), or using all 10 PCA components (16.9s), using 3 components required only 1.4s. In all cases as well0, other than Isolation Forest, there is a notable drop in fit time.
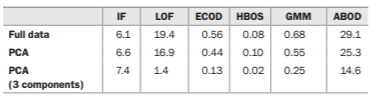
In the next table, we see the predict times for the data_corr dataset (the times for the other test set were similar here as well). Again, we see a very sizable drop in prediction times using just three components, especially for LOF. We also see again that the two univariate detectors, HBOS and ECOD were among the fastest, though GMM is as fast or faster in the case of prediction (though slightly slower in terms of fit time).
With Isolation Forest (IF), as we train the same number of trees regardless of the number of features, and pass all records to be evaluated through the same set of trees, the times are unaffected by the number of features. For all other detectors shown here, however, the number of features is very relevant: all others show a significant drop in predict time when using 3 components compared to all 10 original features or all 10 components.
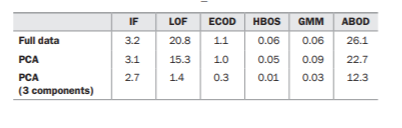
In terms of accuracy, all five detectors performed well on the two datasets most of the time, in terms of assigning the highest outlier score to the last row, which, for both test datasets, is the one known outlier. The results are shown in the next table. There are two rows, one for each dataset. For each, we show the rank assigned by each detector to the one known outlier. Ideally, all detectors would assign this rank 1 (the highest outlier score).
In most cases, the last row was, in fact, given the highest or nearly highest rank, with the exception of IF, ECOD, and HBOS on the first dataset. This is a good example where even strong detectors such as IF can occasionally do poorly even for clear outliers.

For the first dataset, ECOD and HBOS completely miss the outlier, but this is as expected, as it is an outlier based on a combination of values (it ignores the normal linear relationship among the features), which univariate tests are unable to detect. The second dataset’s outlier is based on extreme values, which both univariate and multivariate tests are typically able to detect reliably, and can do so here.
We see a drastic improvement in accuracy when using PCA for these datasets and these detectors, shown in the next table. This is not always the case, but it does hold true here. When the detectors execute on the PCA-transformed data, all 6 detectors rank the known outlier the highest on both datasets. When data is PCA-transformed, the components are all unassociated with each other; the outliers are the extreme values, which are much easier to identify.

Also interesting is that only the last three components are necessary to rank the known outliers as the top outliers, shown in the table here.
And, as we saw above, fit and predict times are substantially shorter in these cases. This is where we can achieve significant performance improvements using PCA: it’s often necessary to use only a small number of the components.
Using only a small set of components will also reduce memory requirements. This is not always an issue, but often when working with large datasets, this can be an important consideration.
This experiment covered two of the main types of outliers we can have with data: extreme values and values that deviate from a linear pattern, both of which are identifiable in the later components. In these cases, using the last three components worked well.
It can vary how many components to use, and which components are best to use, and some experimentation will be needed (likely best discovered using doped data). In some cases, it may be preferable (in terms of execution time, detecting the relevant outliers reliably, and reducing noise) to use the earlier components, in some cases the middle, and in some cases the later. As we can see in the scatter plot at the beginning of this article, different components can tend to highlight different types of outlier.
Improving the outlier detection system over time
Another useful benefit of working with PCA components is that it can make it easier to tune the outlier detection system over time. Often with outlier detection, the system is run not just once on a single dataset, but on an ongoing basis, so constantly assessing new data as it arrives (for example, new financial transactions, sensor readings, web site logs, network logs, etc.), and over time we gain a better sense of what outliers are most relevant to us, and which are being under- and over-reported.
As the outliers reported when working with PCA-transformed data all relate to a single component, we can see how many relevant and irrelevant outliers being reported are associated with each component. This can be particularly easy when using simple univariate tests on each component, like z-score, IQR, IDR, MAD-based tests, and similar tests.
Over time, we can learn to weight outliers associated with some components more highly and other components lower (depending on our tolerance for false positive and false negatives).
Visualization
Dimensionality reduction also has some advantages in that it can help visualize the outliers, particularly where we reduce the data to two or three dimensions. Though, as with the original features, even where there are more than three dimensions, we can view the PCA components one at a time in the form of histograms, or two at a time in scatter plots.
For example, inspecting the last two components of the first test dataset, data_corr (which contained unusual combinations of values) we can see the known outlier clearly, as shown below. However, it’s somewhat questionable how informative this is, as the components themselves are difficult to understand.

Conclusions
This article covered PCA, but there are other dimensionality reduction tools that can be similarly used, including t-SNE (as with PCA, this is provided in scikit-learn), UMAP, and auto-encoders (also covered in Outlier Detection in Python).
As well, using PCA, methods based on reconstruction error (measuring how well the values of a record can be approximated using only a subset of the components) can be very effective and is often worth investigating, as covered in the previous article in this series.
This article covered using standard outlier detectors (though, as demonstrated, this can more readily include simple univariate outlier detectors than is normally possible) for outlier detection, showing the benefits of first transforming the data using PCA.
How well this process will work depends on the data (for example, PCA relies on there being strong linear relationships between the features, and can breakdown if the data is heavily clustered) and the types of outliers you’re interested in finding. It’s usually necessary to use doping or other forms of testing to determine how well this works, and to tune the process — particularly determining which components are used. Where there are no constraints related to execution time or memory limits though, it can be a good starting point to simply use all components and weight them equally.
As well, in outlier detection, usually no single outlier detection process will reliably identify all the types of outliers you’re interested in (especially where you’re interested in finding all records that can be reasonably considered statistically unusual in one way or another), and so multiple outlier detection methods generally need to be used. Combining PCA-based outlier detection with other methods can cover a wider range of outliers than can be detected using just PCA-based methods, or just methods without PCA transformations.
But, where PCA-based methods work well, they can often provide more accurate detection, as the outliers are often better separated and easier to detect.
PCA-based methods can also execute more quickly (particularly where they’re sufficient and do not need to be combined with other methods), because: 1) simpler (and faster) detectors such as z-score, IQR, HBOS and ECOD can be used; and 2) fewer components may be used. The PCA transformations themselves are generally extremely fast, with times almost negligible compared to fitting or executing outlier detection.
Using PCA, at least where only a subset of the components are necessary, can also reduce memory requirements, which can be an issue when working with particularly large datasets.
All images by author
A Simple Example Using PCA for Outlier Detection was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Simple Example Using PCA for Outlier Detection
Go Here to Read this Fast! A Simple Example Using PCA for Outlier Detection