Understanding and coding how Gaussians are used within 3D Gaussian Splatting
Now on to gaussians! Everyone’s favorite distribution. If you are just joining us, we have covered how to take a 3D point and translate it to 2D given the location of the camera in part 1. For this article we will be moving onto dealing with the gaussian part of gaussian splatting. We will be using part_2.ipynb in our GitHub.
One slight change that we will make here is that we are going to use perspective projection that utilizes a different internal matrix than the one shown in the previous article. However, the two are equivalent when projecting a point to 2D and I find the first method introduced in part 1 far easier to understand, however we change our method in order to replicate, in python, as much of the author’s code as possible. Specifically our “internal” matrix will now be given by the OpenGL projection matrix shown here and the order of multiplication will now be points @ external.transpose() @ internal.
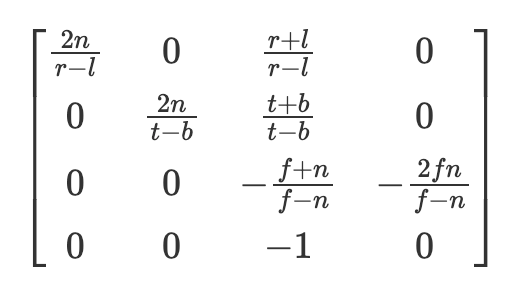
For those curious to know about this new internal matrix (otherwise feel free to skip this paragraph) r and l are the clipping planes of the right and left sides, essentially what points could be in view with regards to the width of the photo, and t and b are the top and bottom clipping planes. N is the near clipping plane (where points will be projected to) and f is the far clipping plane. For more information I have found scratchapixel’s chapters here to be quite informative (https://www.scratchapixel.com/lessons/3d-basic-rendering/perspective-and-orthographic-projection-matrix/opengl-perspective-projection-matrix.html). This also returns the points in normalized device coordinates (between -1 and 1) and which we then project to pixel coordinates. Digression aside the task remains the same, take the point in 3D and project onto a 2D image plane. However, in this part of the tutorial we are now using gaussians instead of a points.
def getIntinsicMatrix(
focal_x: torch.Tensor,
focal_y: torch.Tensor,
height: torch.Tensor,
width: torch.Tensor,
znear: torch.Tensor = torch.Tensor([100.0]),
zfar: torch.Tensor = torch.Tensor([0.001]),,
) -> torch.Tensor:
"""
Gets the internal perspective projection matrix
znear: near plane set by user
zfar: far plane set by user
fovX: field of view in x, calculated from the focal length
fovY: field of view in y, calculated from the focal length
"""
fovX = torch.Tensor([2 * math.atan(width / (2 * focal_x))])
fovY = torch.Tensor([2 * math.atan(height / (2 * focal_y))])
tanHalfFovY = math.tan((fovY / 2))
tanHalfFovX = math.tan((fovX / 2))
top = tanHalfFovY * znear
bottom = -top
right = tanHalfFovX * znear
left = -right
P = torch.zeros(4, 4)
z_sign = 1.0
P[0, 0] = 2.0 * znear / (right - left)
P[1, 1] = 2.0 * znear / (top - bottom)
P[0, 2] = (right + left) / (right - left)
P[1, 2] = (top + bottom) / (top - bottom)
P[3, 2] = z_sign
P[2, 2] = z_sign * zfar / (zfar - znear)
P[2, 3] = -(zfar * znear) / (zfar - znear)
return P
A 3D gaussian splat consists of x, y, and z coordinates as well as the associated covariance matrix. As noted by the authors: “An obvious approach would be to directly optimize the covariance matrix Σ to obtain 3D gaussians that represent the radiance field. However, covariance matrices have physical meaning only when they are positive semi-definite. For our optimization of all our parameters, we use gradient descent that cannot be easily constrained to produce such valid matrices, and update steps and gradients can very easily create invalid covariance matrices.”¹
Therefore, the authors use a decomposition of the covariance matrix that will always produce positive semi definite covariance matrices. In particular they use 3 “scale” parameters and 4 quaternions that are turned into a 3×3 rotation matrix (R). The covariance matrix is then given by
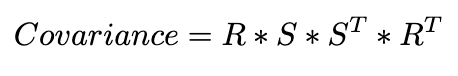
Note one must normalize the quaternion vector before converting to a rotation matrix in order to obtain a valid rotation matrix. Therefore in our implementation a gaussian point consists of the following parameters, coordinates (3×1 vector), quaternions (4×1 vector), scale (3×1 vector) and a final float value relating to the opacity (how transparent the splat is). Now all we need to do is optimize these 11 parameters to get our scene — simple right!
Well it turns out it is a little bit more complicated than that. If you remember from high school mathematics, the strength of a gaussian at a specific point is given by the equation:
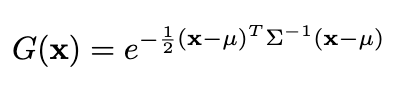
However, we care about the strength of 3D gaussians in 2D, ie. in the image plane. But you might say, we know how to project points to 2D! Despite that, we have not yet gone over projecting the covariance matrix to 2D and so we could not possibly find the inverse of the 2D covariance matrix if we have yet to find the 2D covariance matrix.
Now this is the fun part (depending on how you look at it). EWA Splatting, a paper reference by the 3D gaussian splatting authors, shows exactly how to project the 3D covariance matrix to 2D.² However, this assumes knowledge of a Jacobian affine transformation matrix, which we compute below. I find code most helpful when walking through a difficult concept and thus I have provided some below in order to exemplify how to go from a 3D covariance matrix to 2D.
def compute_2d_covariance(
points: torch.Tensor,
external_matrix: torch.Tensor,
covariance_3d: torch.Tensor,
tan_fovY: torch.Tensor,
tan_fovX: torch.Tensor,
focal_x: torch.Tensor,
focal_y: torch.Tensor,
) -> torch.Tensor:
"""
Compute the 2D covariance matrix for each gaussian
"""
points = torch.cat(
[points, torch.ones(points.shape[0], 1, device=points.device)], dim=1
)
points_transformed = (points @ external_matrix)[:, :3]
limx = 1.3 * tan_fovX
limy = 1.3 * tan_fovY
x = points_transformed[:, 0] / points_transformed[:, 2]
y = points_transformed[:, 1] / points_transformed[:, 2]
z = points_transformed[:, 2]
x = torch.clamp(x, -limx, limx) * z
y = torch.clamp(y, -limy, limy) * z
J = torch.zeros((points_transformed.shape[0], 3, 3), device=covariance_3d.device)
J[:, 0, 0] = focal_x / z
J[:, 0, 2] = -(focal_x * x) / (z**2)
J[:, 1, 1] = focal_y / z
J[:, 1, 2] = -(focal_y * y) / (z**2)
# transpose as originally set up for perspective projection
# so we now transform back
W = external_matrix[:3, :3].T
return (J @ W @ covariance_3d @ W.T @ J.transpose(1, 2))[:, :2, :2]
First off, tan_fovY and tan_fovX are the tangents of half the field of view angles. We use these values to clamp our projections, preventing any wild, off-screen projections from affecting our render. One can derive the jacobian from the transformation from 3D to 2D as given with our initial forward transform introduced in part 1, but I have saved you the trouble and show the expected derivation above. Lastly, if you remember we transposed our rotation matrix above in order to accommodate a reshuffling of terms and therefore we transpose back on the penultimate line before returning the final covariance calculation. As the EWA splatting paper notes, we can ignore the third row and column seeing as we only care about the 2D image plane. You might wonder, why couldn’t we do that from the start? Well, the covariance matrix parameters will vary depending on which angle you are viewing it from as in most cases it will not be a perfect sphere! Now that we’ve transformed to the correct viewpoint, the covariance z-axis info is useless and can be discarded.
Given that we have the 2D covariance matrix we are close to being able to calculate the impact each gaussian has on any random pixel in our image, we just need to find the inverted covariance matrix. Recall again from linear algebra that to find the inverse of a 2×2 matrix you only need to find the determinant and then do some reshuffling of terms. Here is some code to help guide you through that process as well.
def compute_inverted_covariance(covariance_2d: torch.Tensor) -> torch.Tensor:
"""
Compute the inverse covariance matrix
For a 2x2 matrix
given as
[[a, b],
[c, d]]
the determinant is ad - bc
To get the inverse matrix reshuffle the terms like so
and multiply by 1/determinant
[[d, -b],
[-c, a]] * (1 / determinant)
"""
determinant = (
covariance_2d[:, 0, 0] * covariance_2d[:, 1, 1]
- covariance_2d[:, 0, 1] * covariance_2d[:, 1, 0]
)
determinant = torch.clamp(determinant, min=1e-3)
inverse_covariance = torch.zeros_like(covariance_2d)
inverse_covariance[:, 0, 0] = covariance_2d[:, 1, 1] / determinant
inverse_covariance[:, 1, 1] = covariance_2d[:, 0, 0] / determinant
inverse_covariance[:, 0, 1] = -covariance_2d[:, 0, 1] / determinant
inverse_covariance[:, 1, 0] = -covariance_2d[:, 1, 0] / determinant
return inverse_covariance
And tada, now we can compute the pixel strength for every single pixel in an image. However, doing so is extremely slow and unnecessary. For example, we really don’t need to waste computing power figuring out how a splat at (0,0) affects a pixel at (1000, 1000), unless the covariance matrix is massive. Therefore, the authors make a choice to calculate what they call the “radius” of each splat. As seen in the code below we calculate the eigenvalues along each axis (remember, eigenvalues show variation). Then, we take the square root of the largest eigenvalue to get a standard deviation measure and multiply it by 3.0, which covers 99.7% of the distribution within 3 standard deviations. This radius helps us figure out the minimum and maximum x and y values that the splat touches. When rendering, we only compute the splat strength for pixels within these bounds, saving a ton of unnecessary calculations. Pretty smart, right?
def compute_extent_and_radius(covariance_2d: torch.Tensor):
mid = 0.5 * (covariance_2d[:, 0, 0] + covariance_2d[:, 1, 1])
det = covariance_2d[:, 0, 0] * covariance_2d[:, 1, 1] - covariance_2d[:, 0, 1] ** 2
intermediate_matrix = (mid * mid - det).view(-1, 1)
intermediate_matrix = torch.cat(
[intermediate_matrix, torch.ones_like(intermediate_matrix) * 0.1], dim=1
)
max_values = torch.max(intermediate_matrix, dim=1).values
lambda1 = mid + torch.sqrt(max_values)
lambda2 = mid - torch.sqrt(max_values)
# now we have the eigenvalues, we can calculate the max radius
max_radius = torch.ceil(3.0 * torch.sqrt(torch.max(lambda1, lambda2)))
return max_radius
All of these steps above give us our preprocessed scene that can then be used in our render step. As a recap we now have the points in 2D, colors associated with those points, covariance in 2D, inverse covariance in 2D, sorted depth order, the minimum x, minimum y, maximum x, maximum y values for each splat, and the associated opacity. With all of these components we can finally move onto rendering an image!
- Kerbl, Bernhard, et al. “3d gaussian splatting for real-time radiance field rendering.” ACM Transactions on Graphics 42.4 (2023): 1–14.
- Zwicker, Matthias, et al. “EWA splatting.” IEEE Transactions on Visualization and Computer Graphics 8.3 (2002): 223–238.
A Python Engineer’s Introduction to 3D Gaussian Splatting (Part 2) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Python Engineer’s Introduction to 3D Gaussian Splatting (Part 2)
Go Here to Read this Fast! A Python Engineer’s Introduction to 3D Gaussian Splatting (Part 2)