

On Pixel Transformer and Ultra-long Sequence Distributed Transformer
Have you ever wondered why the Vision Transformer (ViT) uses 16*16 size patches as input tokens?
It all dates back to the earlier days of the Transformers. The original Transformer model was proposed in 2017 and only works with natural language data. When the BERT model was released in 2018, it could only handle a max token sequence of length 512. Later in 2020, when GPT-3 was released, it could handle a sequence of lengths 2048 and 4096 at 3.5. All these models showed amazing performance in handling sequence-to-sequence and text-generation tasks.
However, these sequences were too short for images when tokens were taken at the pixel level. For example, in Cifar-100, the image size is 32* 32 = 1024 pixels. In ImageNet, the image size is 224* 224 = 50176 pixels. The sequence length would be an immediate barrier if the transformer were directly applied to the pixel level.
The ViT paper was released in 2020. It proposed using patches rather than pixels as the input tokens. For an image of size 224* 224, using a patch size of 16* 16, the sequence length would be largely reduced to 196, which perfectly solved the issue.
However, the issue was only partially solved. For tasks requiring features of finer details, different approaches have to be utilized to get the pixel-level accuracy back. Segformer proposed to fuse features from hierarchical transformer encoders of different resolutions. SwinIR had to combine CNN with multiple levels of skip connection around the transformer module for fine-grained feature extraction. The Swin Transformer, a model for universal computer vision tasks, started with a patch size 4*4 in each local window and then gradually built toward the global 16*16 patch size to obtain both globality and granularity. Intrinsically, these efforts pointed to one fact — simply using the 16*16 size patch is insufficient.
The natural question is, can “pixel” be used as a direct token for transformers? The question further splits into two: 1. Is it possible to feed an ultralong sequence (e.g., 50k) to a transformer? 2. does feeding pixels as tokens provide more information than patches?
In this article, I will summarize two recent papers: 1. Pixel Transformer, a technical report released by Meta AI last week, comparing pixel-wise tokens and patch-wise tokens to transformer models from the perspective of reducing the inductive bias of locality on three different tasks: image classification, pre-training, and generation. 2. Ultra-long sequence distributed transformer: by distributing the query vector, the authors showed the possibility to scale an input sequence of length 50k on 3k GPUs.
Pixel Transformer (PiT) — from an inductive bias perspective
Meta AI released The technical report last week on arXiv: “An image is worth more than 16*16 patches”. Instead of proposing a novel method, the technical report answered a long-lasting question: Does it make sense to use pixels instead of patches as input tokens? If so, why?
The paper took the perspective of the Inductive Bias of Locality. According to K. Murphy’s well-known machine learning book, inductive bias is the “assumptions about the nature of the data distribution.” In the early “non-deep learning” era, the inductive bias was more “feature-related,” coming from the manual feature engineered for specific tasks. This inductive bias was not a bad thing, especially for specific tasks in which very good prior knowledge from human experts is gained, making the engineered features very useful. However, from the generalization perspective, the engineered features are very hard to generalize to universal tasks, like general image classification and segmentation.
But beyond feature bias, the architecture itself contains inductive bias as well. The ViT is a great example showing less inductive bias than CNN models in terms of architecture hierarchy, propagation uniformness, representation scale, and attention locality. See my previous medium post for a detailed discussion. But still, ViT remains a special type of inductive bias — locality. When the ViT processes a sequence of patch tokens, the pixels within the same patch are naturally treated by the model differently than those from different patches. And that’s where the locality comes from.
So, is it possible to remove the inductive bias of locality further? The answer is yes. The PiT proposed using the “pixel set” as input with different position embedding (PE) strategies: sin-cos, learnt, and none. It showed superior performance over ViT on supervised, self-supervised, and generation tasks. The proposed pipeline is shown in the figure below.
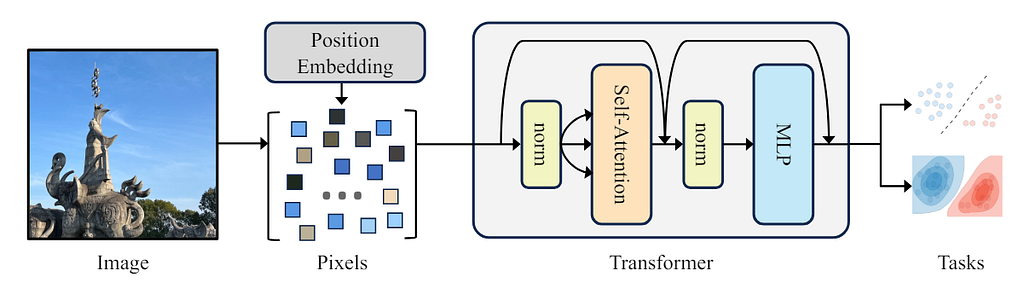
The idea seems simple and straightforward, and the authors claim they are “not introducing a new method” here. But still, the PiT shows great potential. On CIFAR-100 and ImageNet (reduced input size to 28*28) supervised classification tasks, the classification accuracy increased by more than 2% over ViT. See the table below.
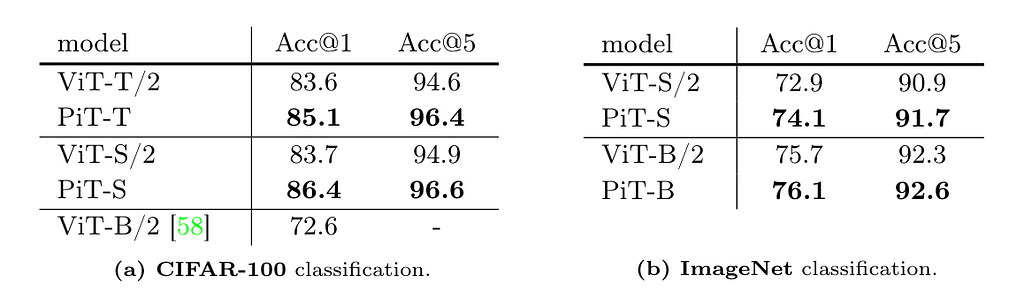
Similar improvement was also observed in self-supervised learning tasks and image generation tasks. What’s more, the authors also showed the trend of a performance increase when reducing the patch size from 8*8 to 1*1 (single pixel) as below:
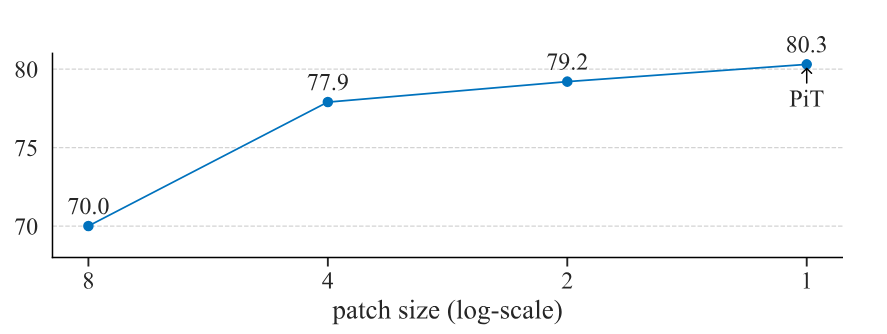
In terms of positional encoding.
As pointed out in this research paper, positional encoding is a prerequisite in transformer-based models for input token sequence ordering and improving accuracy. However, the PiT shows that even after dropping the PE, the model performance drops is minimal:

Why drop the positional encoding? It is not only because dropping the positional encoding means a good reduction of the locality bias. If we think of self-attention computation in a distributed manner, it will largely reduce the cross-device communication effort, which we’ll discuss in detail in the next section.
Ultra-long Sequences Transformers — a distributed query vector solution
The inductive bias of locality only told part of the story. If we look closely at the results in the PiT paper, we see that the experiments were limited to 28*28 resized images due to the computational limit. But the real world rarely uses images of such a small size. So the natural question is, even though PiT might be useful and outperform ViT, could it work on natural images of standard resolution, e.g., 244*244?
The paper “Ultra-long sequence distributed transformer,” released in 2023, answers the question. The paper proposed a solution to scale the transformer computation of a 50k-long sequence onto 3k GPUS.

The idea is simple: The transformer’s bottleneck is self-attention computation. To ensure global attention computation, the proposed method only distributes the query vectors across different devices while maintaining the same copies of key and value vectors on all devices.
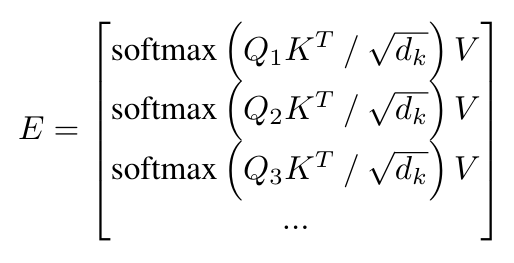
Positional Encoding-aware double gradient averaging. For architectures with learnable positional encoding parameters, gradient backpropagation is related to the positional encoding distribution. So, the authors proposed the double gradient averaging technique: when a gradient average is performed on two different segments from the same sequence, no positional encoding is involved, but when the corresponding segments from two sequences need to average gradients, the positional encoding parameters will be synced.
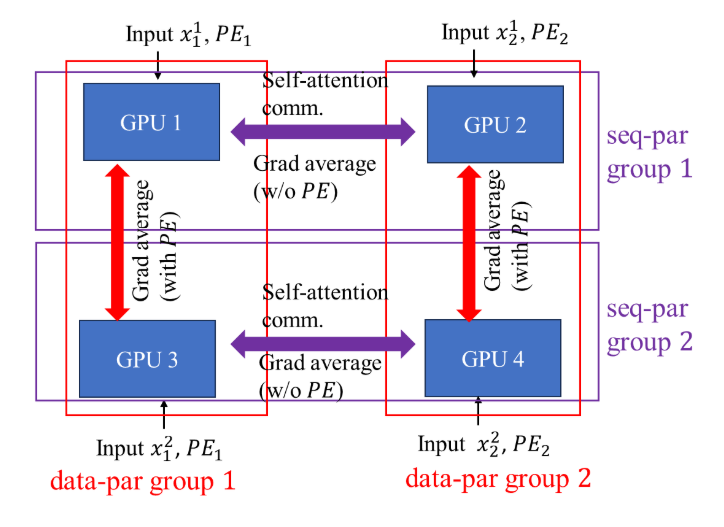
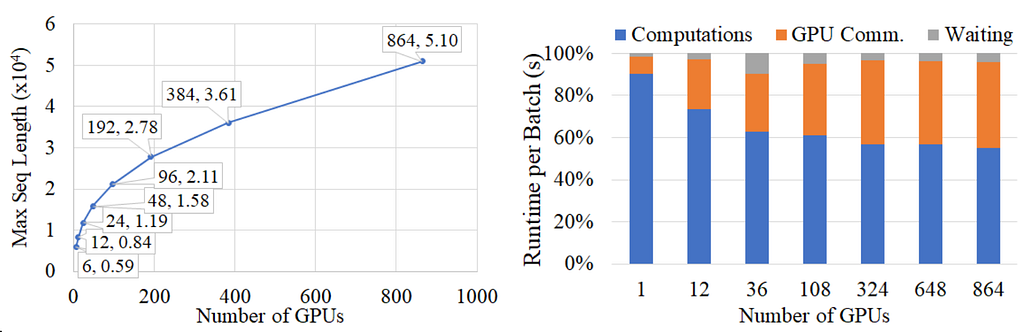
When we combine these two papers, things become interesting. Reducing the inductive bias not only helps with model performance but also plays a crucial role in distributed computation.
- Inductive bias of locality and device communication. The PiT paper shows the potential of building a positional encoding-free model by removing the locality bias. Furthermore, if we look at things from the distributed computing perspective, reducing the need for PE could further reduce the communication burden across devices.
- Inductive bias of locality in distributed sequence computation. Distributing self-attention on multi-GPUs means the query vector is segment-based. There is a natural locality bias if the segment depends on contiguous tokens. The PiT computes on a “token set, ” meaning there is no need for continuous segments, and it will make the query vector bias-free.
References:
- Nguyen et al., An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels. arXiv preprint 2024.
- Wang et al., Ultra long sequence distributed transformer. arXiv preprint 2023.
- Keles et al., On the computational complexity of self-attention. ALT 2023.
- Jiang et al. The encoding method of position embeddings in vision transformer. Journal of Visual Communication and Image Representation. 2022.
- Xie et al., SegFormer: Simple and efficient design for semantic segmentation with transformers. NeurIPS 2021. Github: https://github.com/NVlabs/SegFormer
- Liang et al., Swinir: Image restoration using swin transformer. ICCV 2021. Github: https://github.com/JingyunLiang/SwinIR
- Liu et al., Swin Transformer: Hierarchical vision transformer using shifted windows. ICCV 2021. Github: https://github.com/microsoft/Swin-Transformer
- Dosovitsckiy et al., An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint, 2020.
- Brown et al., Language models are few-shot learners. NeurIPS 2020. Github: https://github.com/openai/gpt-3
- Devlin et al., BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint 2018. HuggingFace Official: https://huggingface.co/docs/transformers/en/model_doc/bert
- Vaswani et al., Attention is all You need. NeurIPS 2017.
- Murphy, Machine learning: a probabilistic perspective. MIT press 2012.
A Patch is More than 16*16 Pixels was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Patch is More than 16*16 Pixels
Go Here to Read this Fast! A Patch is More than 16*16 Pixels