A comprehensive guide on getting the most out of your Chinese topic models, from preprocessing to interpretation.
With our recent paper on discourse dynamics in European Chinese diaspora media, our team has tapped into an almost unanimous frustration with the quality of topic modelling approaches when applied to Chinese data. In this article, I will introduce you to our novel topic modelling method, KeyNMF, and how to apply it most effectively to Chinese textual data.
Topic Modelling with Matrix Factorization
Before diving into practicalities, I would like to give you a brief introduction to topic modelling theory, and motivate the advancements introduced in our paper.
Topic modelling is a discipline of Natural Language Processing for uncovering latent topical information in textual corpora in an unsupervised manner, that is then presented to the user in a human-interpretable way (usually 10 keywords for each topic).
There are many ways to formalize this task in mathematical terms, but one rather popular conceptualization of topic discovery is matrix factorization. This is a rather natural and intuitive way to tackle the problem, and in a minute, you will see why. The primary insight behind topic modelling as matrix factorization is the following: Words that frequently occur together, are likely to belong to the same latent structure. In other words: Terms, the occurrence of which are highly correlated, are part of the same topic.
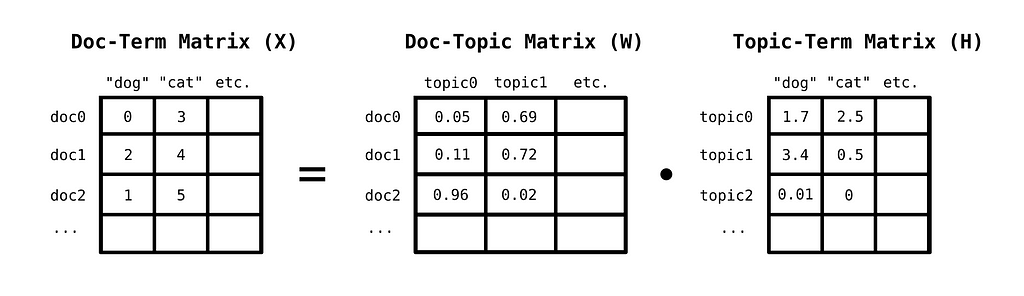
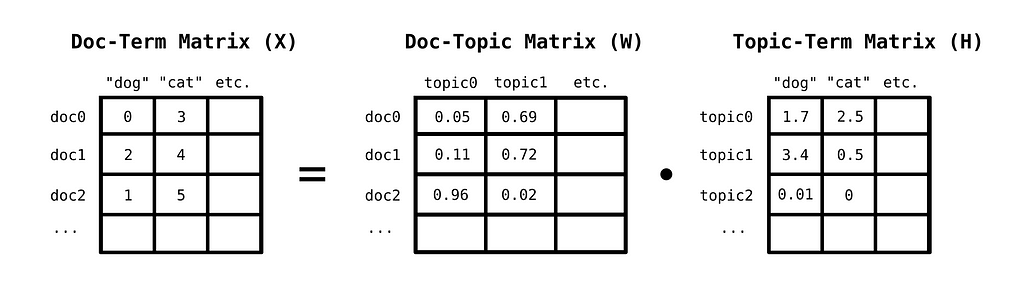
You can discover topics in a corpus, by first constructing a bag-of-words matrix of documents. A bag-of-words matrix represents documents in the following way: Each row corresponds to a document, while each column to a unique word from the model’s vocabulary. The values in the matrix are then the number of times a word occurs in a given document.
This matrix can be decomposed into the linear combination of a topic-term matrix, which indicates how important a word is for a given topic, and a document-topic matrix, which indicates how important a given topic is for a given document. A method for this decomposition is Non-negative Matrix Factorization, where we decompose a non-negative matrix to two other strictly non-negative matrices, instead of allowing arbitrary signed values.
NMF is not the only method one can use for decomposing the bag-of-words matrix. A method of high historical significance, Latent Semantic Analysis, utilizes Truncated Singular-Value Decomposition for this purpose. NMF, however, is generally a better choice, as:
- The discovered latent factors are of different quality from other decomposition methods. NMF typically discovers localized patterns or parts in the data, which are easier to interpret.
- Non-negative topic-term and document-topic relations are easier to interpret than signed ones.
Using NMF with just BoW matrices, however attractive and simple it may be, does come with its setbacks:
- NMF typically minimizes the Frobenius norm of the error matrix. This entails an assumption of Gaussianity of the outcome variable, which is obviously false, as we are modelling word counts.
- BoW representations are just word counts. This means that words won’t be interpreted in context, and syntactical information will be ignored.
KeyNMF
To account for these limitations, and with the help of new transformer-based language representations, we can significantly improve NMF for our purposes.
The key intuition behind KeyNMF is that most words in a document are semantically insignificant, and we can get an overview of topical information in the document by highlighting the top N most relevant terms. We will select these terms by using contextual embeddings from sentence-transformer models.
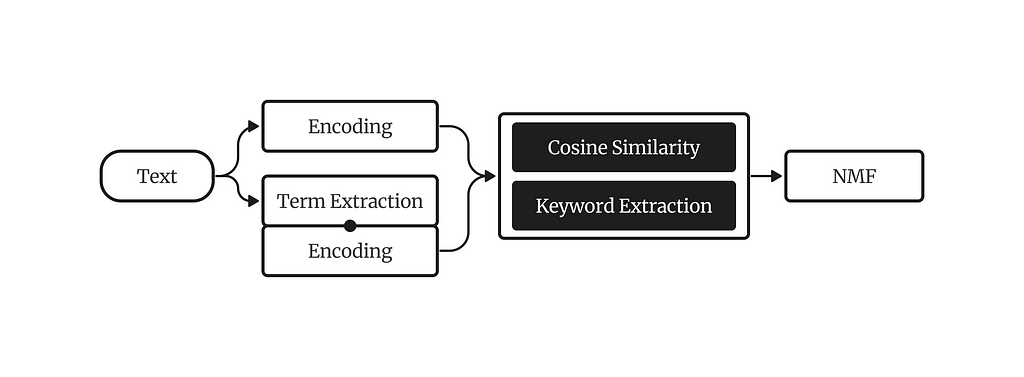
The KeyNMF algorithm consists of the following steps:
- Embed each document using a sentence-transformer, along with all words in the document.
- Calculate cosine similarities of word embeddings to document embeddings.
- For each document, keep the highest N words with positive cosine similarities to the document.
- Arrange cosine similarities into a keyword-matrix, where each row is a document, each column is a keyword, and values are cosine similarities of the word to the document.
- Decompose the keyword matrix with NMF.
This formulation helps us in multiple ways. a) We substantially reduce the model’s vocabulary, thereby having less parameters, resulting in faster and better model fit b) We get continuous distribution, which is a better fit for NMF’s assumptions and c) We incorporate contextual information into our topic model.
Chinese Topic Modelling with KeyNMF
Now that you understand how KeyNMF works, let’s get our hands dirty and apply the model in a practical context.
Preparation and Data
First, let’s install the packages we are going to use in this demonstration:
pip install turftopic[jieba] datasets sentence_transformers topicwizard
Then let’s get some openly available data. I chose to go with the SIB200 corpus, as it is freely available under the CC-BY-SA 4.0 open license. This piece of code will fetch us the corpus.
from datasets import load_dataset
# Loads the dataset
ds = load_dataset("Davlan/sib200", "zho_Hans", split="all")
corpus = ds["text"]
Building a Chinese Topic Model
There are a number of tricky aspects to applying language models to Chinese, since most of these systems are developed and tested on English data. When it comes to KeyNMF, there are two aspects that need to be taken into account.
Firstly, we will need to figure out how to tokenize texts in Chinese. Luckily, the Turftopic library, which contains our implementation of KeyNMF (among other things), comes prepackaged with tokenization utilities for Chinese. Normally, you would use a CountVectorizer object from sklearn to extract words from text. We added a ChineseCountVectorizer object that uses the Jieba tokenizer in the background, and has an optionally usable Chinese stop word list.
from turftopic.vectorizers.chinese import ChineseCountVectorizer
vectorizer = ChineseCountVectorizer(stop_words="chinese")
Then we will need a Chinese embedding model for producing document and word representations. We will use the paraphrase-multilingual-MiniLM-L12-v2 model for this, as it is quite compact and fast, and was specifically trained to be used in multilingual retrieval contexts.
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
We can then build a fully Chinese KeyNMF model! I will initialize a model with 20 topics and N=25 (a maximum of 15 keywords will be extracted for each document)
from turftopic import KeyNMF
model = KeyNMF(
n_components=20,
top_n=25,
vectorizer=vectorizer,
encoder=encoder,
random_state=42, # Setting seed so that our results are reproducible
)
We can then fit the model to the corpus and see what results we get!
document_topic_matrix = model.fit_transform(corpus)
model.print_topics()
┏━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Topic ID ┃ Highest Ranking ┃
┡━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 0 │ 旅行, 非洲, 徒步旅行, 漫步, 活动, 通常, 发展中国家, 进行, 远足, 徒步 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 1 │ 滑雪, 活动, 滑雪板, 滑雪运动, 雪板, 白雪, 地形, 高山, 旅游, 滑雪者 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 2 │ 会, 可能, 他们, 地球, 影响, 北加州, 并, 它们, 到达, 船 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 3 │ 比赛, 选手, 锦标赛, 大回转, 超级, 男子, 成绩, 获胜, 阿根廷, 获得 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 4 │ 航空公司, 航班, 旅客, 飞机, 加拿大航空公司, 机场, 达美航空公司, 票价, 德国汉莎航空公司, 行李 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 5 │ 原子核, 质子, 能量, 电子, 氢原子, 有点像, 原子弹, 氢离子, 行星, 粒子 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 6 │ 疾病, 传染病, 疫情, 细菌, 研究, 病毒, 病原体, 蚊子, 感染者, 真菌 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 7 │ 细胞, cella, 小房间, cell, 生物体, 显微镜, 单位, 生物, 最小, 科学家 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 8 │ 卫星, 望远镜, 太空, 火箭, 地球, 飞机, 科学家, 卫星电话, 电话, 巨型 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 9 │ 猫科动物, 动物, 猎物, 狮子, 狮群, 啮齿动物, 鸟类, 狼群, 行为, 吃 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 10 │ 感染, 禽流感, 医院, 病毒, 鸟类, 土耳其, 病人, h5n1, 家禽, 医护人员 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 11 │ 抗议, 酒店, 白厅, 抗议者, 人群, 警察, 保守党, 广场, 委员会, 政府 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 12 │ 旅行者, 文化, 耐心, 国家, 目的地, 适应, 人们, 水, 旅行社, 国外 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 13 │ 速度, 英里, 半英里, 跑步, 公里, 跑, 耐力, 月球, 变焦镜头, 镜头 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 14 │ 原子, 物质, 光子, 微小, 粒子, 宇宙, 辐射, 组成, 亿, 而光 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 15 │ 游客, 对, 地区, 自然, 地方, 旅游, 时间, 非洲, 开车, 商店 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 16 │ 互联网, 网站, 节目, 大众传播, 电台, 传播, toginetradio, 广播剧, 广播, 内容 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 17 │ 运动, 运动员, 美国, 体操, 协会, 支持, 奥委会, 奥运会, 发现, 安全 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 18 │ 火车, metroplus, metro, metrorail, 车厢, 开普敦, 通勤, 绕城, 城内, 三等舱 │
├──────────┼──────────────────────────────────────────────────────────────────────────────────────────────┤
│ 19 │ 投票, 投票箱, 信封, 选民, 投票者, 法国, 候选人, 签名, 透明, 箱内 │
└──────────┴──────────────────────────────────────────────────────────────────────────────────────────────┘
As you see, we’ve already gained a sensible overview of what there is in our corpus! You can see that the topics are quite distinct, with some of them being concerned with scientific topics, such as astronomy (8), chemistry (5) or animal behaviour (9), while others were oriented at leisure (e.g. 0, 1, 12), or politics (19, 11).
Visualization
To gain further aid in understanding the results, we can use the topicwizard library to visually investigate the topic model’s parameters.
Since topicwizard uses wordclouds, we will need to tell the library that it should be using a font that is compatible with Chinese. I took a font from the ChineseWordCloud repo, that we will download and then pass to topicwizard.
import urllib.request
import topicwizard
urllib.request.urlretrieve(
"https://github.com/shangjingbo1226/ChineseWordCloud/raw/refs/heads/master/fonts/STFangSong.ttf",
"./STFangSong.ttf",
)
topicwizard.visualize(
corpus=corpus, model=model, wordcloud_font_path="./STFangSong.ttf"
)
This will open the topicwizard web app in a notebook or in your browser, with which you can interactively investigate your topic model:
Conclusion
In this article, we’ve looked at what KeyNMF is, how it works, what it’s motivated by and how it can be used to discover high-quality topics in Chinese text, as well as how to visualize and interpret your results. I hope this tutorial will prove useful to those who are looking to explore Chinese textual data.
For further information on the models, and how to improve your results, I encourage you to check out our Documentation. If you should have any questions or encounter issues, feel free to submit an issue on Github, or reach out in the comments :))
All figures presented in the article were produced by the author.
Contextual Topic Modelling in Chinese Corpora with KeyNMF was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Contextual Topic Modelling in Chinese Corpora with KeyNMF
Go Here to Read this Fast! Contextual Topic Modelling in Chinese Corpora with KeyNMF