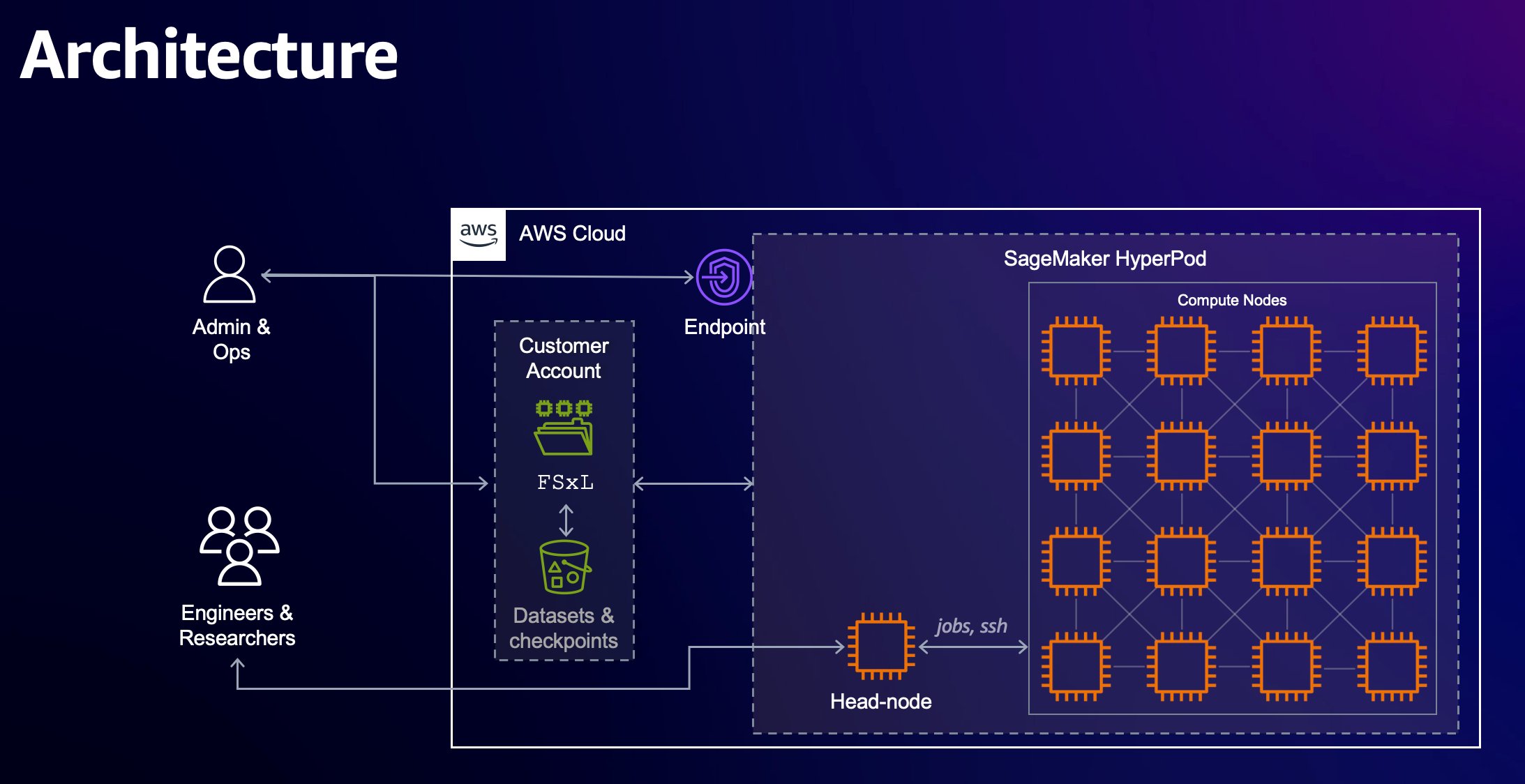
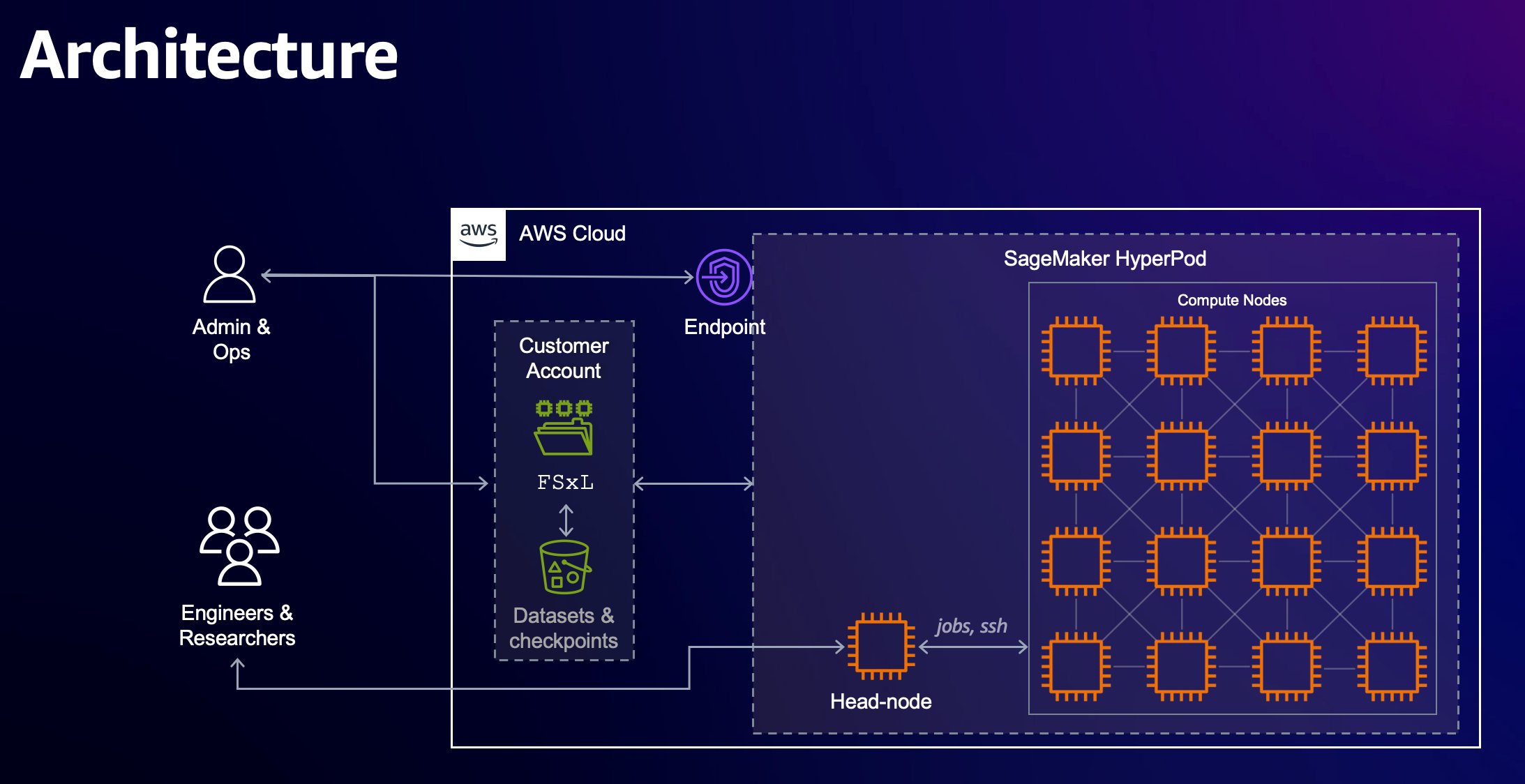
In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. We use HuggingFace’s Optimum-Neuron software development kit (SDK) to apply LoRA to fine-tuning jobs, and use SageMaker HyperPod as the primary compute cluster to perform distributed training on Trainium. Using LoRA supervised fine-tuning for Meta Llama 3 models, you can further reduce your cost to fine tune models by up to 50% and reduce the training time by 70%.
Originally appeared here:
PEFT fine tuning of Llama 3 on SageMaker HyperPod with AWS Trainium
Go Here to Read this Fast! PEFT fine tuning of Llama 3 on SageMaker HyperPod with AWS Trainium