

Text analytics hints at how volumes of writing get created
In the broadest of strokes, Natural Language Processing transforms language into constructs that can be usefully manipulated. Since deep-learning embeddings have proven so powerful, they’ve also become the default: pick a model, embed your data, pick a metric, do some RAG. To add new value, it helps to have a different take on crunching language.
The one I’ll share today started years ago, with a single book.
The Orchid Thief is both non-fiction and full of mischief. I had first read it in my 20s, skipping most of the historical anecdata, itching for its first-person accounts. At the time, I laughed out loud but turned the pages in quiet fury, that someone could live so deeply and write so well. I wasn’t all that sure these were different things.
Within a year I had moved to London to start anew.
I went into financial services, which is like a theme park for nerds. And, for the ensuing decade, would only take jobs with lots of writing.
Lots being the operative word.
Behind the modern façade of professional services, British industry is alive to its old factories and shipyards. It employs Alice to do a thing, and then hand it over to Bob; he turns some screws, and it’s on to Charlie. One month on, we all do it again. As a newcomer, I noticed habits weren’t so much a ditch to fall into, but a mound to stake.
I was also reading lots. Okay, I was reading the New Yorker. My most favourite thing was to flip a fresh one on its cover, open it from the back, and read the opening sentences of one, Anthony Lane, who writes film reviews. Years and years, not once did I go see a movie.
Every now and again, a flicker would catch me off-guard. A barely-there thread between the New Yorker corpus and my non-Pulitzer outputs. In both corpora, each piece was different to its siblings, but also…not quite. Similarities echoed. And I knew the ones in my work had arisen out of a repetitive process.
In 2017 I began meditating on the threshold separating writing that feels formulaic from one that can be explicitly written out as a formula.
The argument goes like this: volume of repetition hints at a (typically tacit) form of algorithmic decision-making. But procedural repetition leaves fingerprints. Trace the fingerprints to surface the procedure; suss out the algorithm; and the software practically writes itself.
In my last job, I was no longer writing lots. My software was.
Companies can, in principle, learn enough about their own flows to reap enormous gains, but few bother. Folks seem far more enthralled with what somebody else is doing.
For example, my bosses, and later my clients, kept wishing their staff could mimic the Economist’s house style. But how would you find which steps the Economist takes to end up sounding the way it does?
Enter Text Analytics
Read a single Economist article, and it feels breezy and confident. Read lots of them, and they sound kind of alike. A full printed magazine comes out once a week. Yeah, I was betting on process.
For fun, let’s apply a readability function (measured in years of education) to several hundred Economist articles. Let’s also do the same to hundreds of articles published by a frustrated European asset manager.
Then, let’s get ourselves a histogram to see how those readability scores are distributed.
Just two functions, and look at the insights we get!
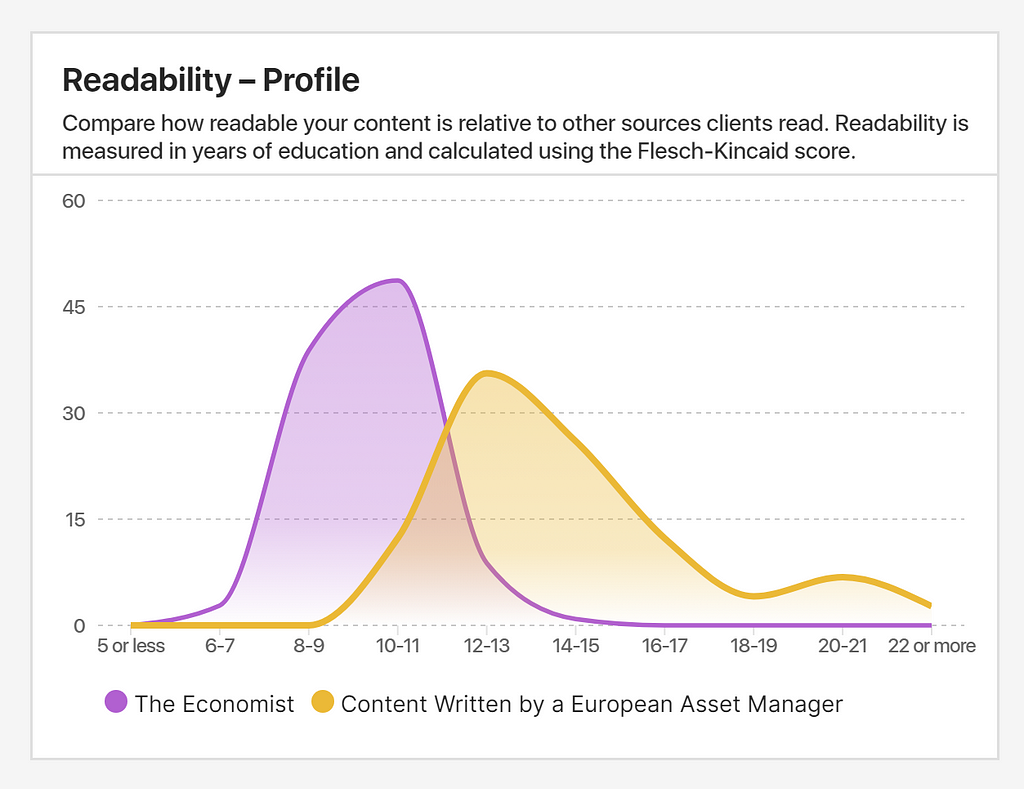
Notice how separated the curves are; this asset manager is not sounding like the Economist. We could drill further to see what’s causing this disparity. (For a start, it’s often crazy-long sentences.)
But also, notice how the Economist puts a hard limit on the readability score they allow. The curve is inorganic, betraying they apply a strict readability check in their editing process.
Finally — and many of my clients struggled with this — the Economist vows to write plainly enough that an average highschooler could take it in.
I had expected these charts. I had scribbled them on paper. But when a real one first lit up my screen, it was as though language herself had giggled.
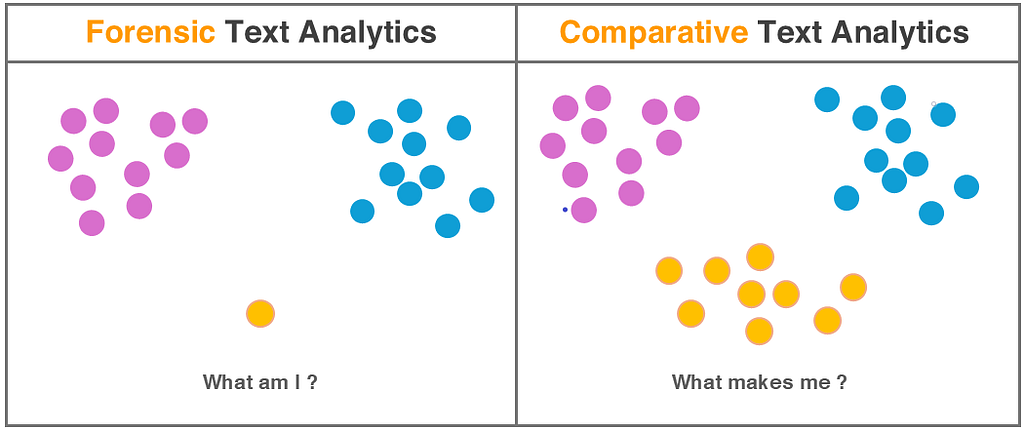
Now, I wasn’t exactly the first on the scene. In 1964, statisticians Frederick Mosteller and David Wallace landed on the cover of Time magazine, their forensic literary analysis settling a 140-year old debate over the authorship of a famed dozen of anonymously-written essays.
But forensic analytics always looks at the single item in relation to two corpora: the one created by the suspected author, and the null hypothesis. Comparative analytics only cares about comparing bodies of text.
Building A Text Analytics Engine
Let’s retrace our steps: given a corpus, we applied the same function on each of the texts (the readability function). This mapped the corpus onto a set (in this case, numbers). On this set we applied another function (the histogram). Finally, we did it to two different corpora — and compared the results.
If you squint, you’ll see I’ve just described Excel.
What looks like a table is actually a pipeline, crunching columns sequentially. First along the column, followed by functions on the results, followed by comparative analysis functions.
Well, I wanted Excel, but for text.
Not strings — text. I wanted to apply functions like Count Verbs or First Paragraph Subjector First Important Sentence. And it had to be flexible enough so I could ask any question; who knows what would end up mattering?
In 2020 this kind of solution did not exist, so I built it. And boy did this software not ‘practically write itself’! Making it possible to ask any question needed some good architecture decisions, which I got wrong twice before ironing out the kinks.
In the end, functions are defined once, by what they do to a single input text. Then, you pick and choose the pipeline steps, and the corpora on which they act.
With that, I started a writing-tech consulting company, FinText. I planned to build while working with clients, and see what sticks.
What the Market Said
The first commercial use case I came up with was social listening. Market research and polling are big business. It’s now the height of the pandemic, everyone’s at home. I figured that processing active chatter on dedicated online communities could be a new way to access client thinking.
Any first software client would have felt special, but this one was thrilling, because my concoction actually helped real people get out of a tight spot:
Working towards a big event, they had planned to launch a flagship report, with data from a paid YouGov survey. But its results were tepid. So, with their remaining budget, they bought a FinText study. It was our findings that they put front and centre in their final report.

But social listening did not take off. Investment land is quirky because pools of money will always need a home; the only question is who’s the landlord. Industry people I talked to mostly wanted to know what their competitors were up to.
So the second use case — competitive content analytics — was met with warmer response. I sold about half a dozen companies on this solution (including, for example, Aviva Investors).
All along, our engine was collecting data no one else had. Such was my savvy, it wasn’t even my idea to run training sessions, a client first asked for one. That’s how I learned companies like buying training.
Otherwise, my steampunk take on writing was proving tricky to sell. It was all too abstract. What I needed was a dashboard: pretty charts, with real numbers, crunched from live data. A pipeline did the crunching, and I hired a small team to do the pretty charts.
Within the dashboard, two charts showed a breakdown of topics, and the rest dissected the writing style. I’ll say a few words about this choice.
Everyone believes what they say matters. If others don’t care, really it’s a moral failure, of weighing style over substance. A bit like how bad taste is something only other people have.
Scientists have counted clicks, tracked eyes, monitored scrolls, timed attention. We know it takes a split second for readers to decide whether something is “for them”, and they decide by vaguely comparing new information to what they already like. Style is an entry pass.
What The Dashboard Showed
Before, I hadn’t been tracking the data being collected, but now I had all those pretty charts. And they were showing I had been both right, and very, very wrong.
Initially, I only had direct knowledge of a few large investment firms, and had suspected their competitors’ flows look much the same. This proved correct.
But I had also assumed that slightly smaller companies would have only slightly fewer outputs. This just isn’t true.
Text analytics proved helpful if a company already had writing production capacity. Otherwise, what they needed was a working factory. There were too few companies in the first bucket, because everyone else was crowding the second.
Epilogue
As a product, text analytics has been a mixed bag. It made some money, could have probably made some more, but was unlikely to become a runaway success.
Also, I’d lost my appetite for the New Yorker. At some point it all tipped too far on the side of formulaic, and the magic was gone.
Words are now in their wholesale era, what with large language models like ChatGPT. Early on, I considered applying pipelines to discern whether text is machine generated, but what would be the point?
Instead, in late 2023 I began working on a solution that helps companies expand their capacity to write for expert clients. It’s an altogether different adventure, still in its infancy.
In the end, I came to think of text analytics as an extra pair of glasses. On occasion, it turns fuzziness sharp. I keep it in my pocket, just in case.
Is Complex Writing Nothing But Formulas? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Is Complex Writing Nothing But Formulas?
Go Here to Read this Fast! Is Complex Writing Nothing But Formulas?