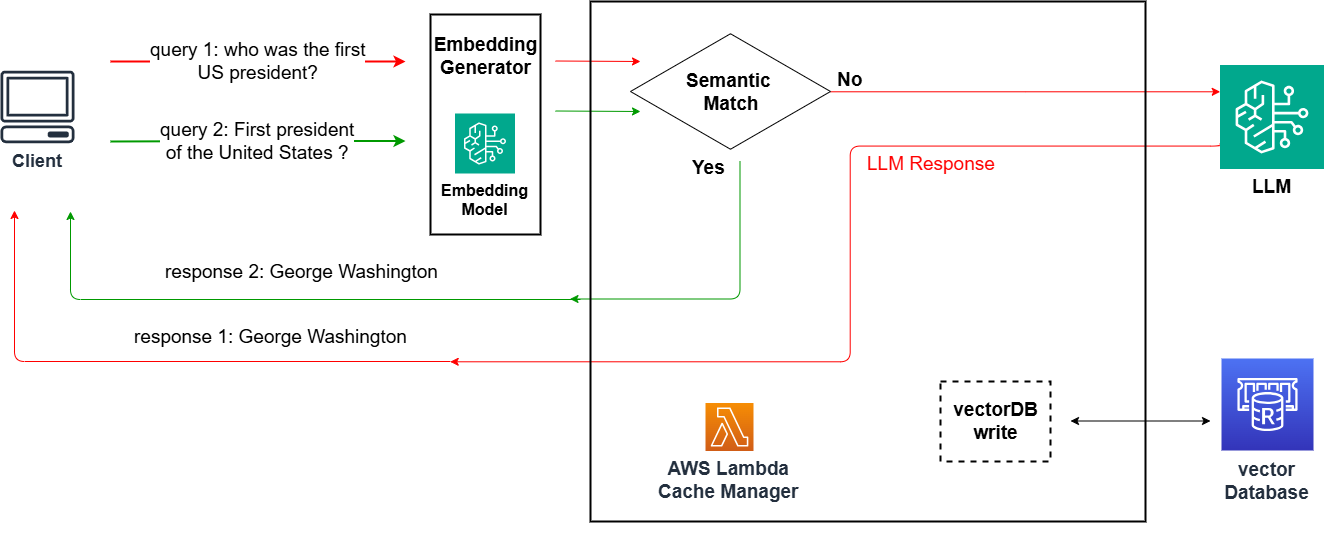

This post presents a strategy for optimizing LLM-based applications. Given the increasing need for efficient and cost-effective AI solutions, we present a serverless read-through caching blueprint that uses repeated data patterns. With this cache, developers can effectively save and access similar prompts, thereby enhancing their systems’ efficiency and response times.
Originally appeared here:
Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock