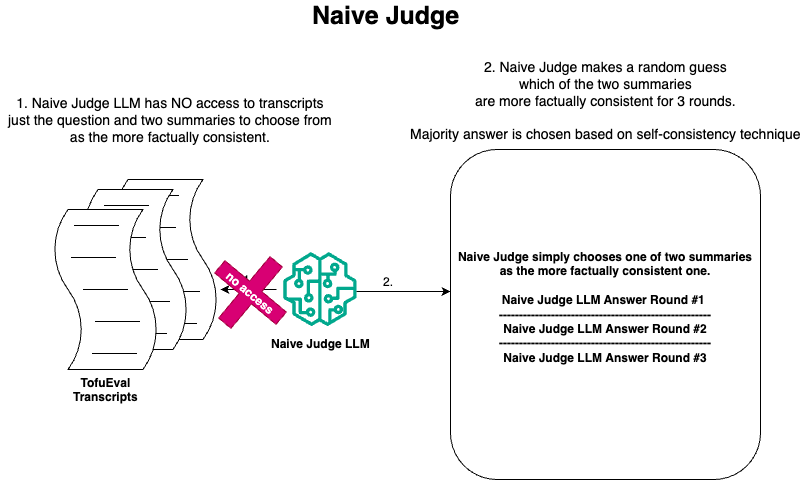

In this post, we demonstrate the potential of large language model (LLM) debates using a supervised dataset with ground truth. In this post, we navigate the LLM debating technique with persuasive LLMs having two expert debater LLMs (Anthropic Claude 3 Sonnet and Mixtral 8X7B) and one judge LLM (Mistral 7B v2 to measure, compare, and contrast its performance against other techniques like self-consistency (with naive and expert judges) and LLM consultancy.
Originally appeared here:
Improve factual consistency with LLM Debates
Go Here to Read this Fast! Improve factual consistency with LLM Debates