Dance Between Dense and Sparse Embeddings: Enabling Hybrid Search in LangChain-Milvus
How to create and search multi-vector-store in langchain-milvus
This blog post was co-authored by Omri Levy and Ohad Eytan, as part of the work we have done in IBM Research Israel.
Intro
Recently, we — at IBM Research — needed to use hybrid search in the Milvus vector store. Since we were already using the LangChain framework, we decided to roll up our sleeves and contribute what was needed to enable it in langchain-milvus. That included support for sparse embeddings (PR) and multi-vector search (PR) through the langchain interface.
In this blog post, we will briefly introduce the difference between dense and sparse embeddings, and how you can leverage both using hybrid search. We’ll also provide a code walk-through to demonstrate how to use these new features in langchain-milvus.
To use the code in this blog post, you should install some packages:
pip install langchain_milvus==0.1.6
pip install langchain-huggingface==0.1.0
pip install "pymilvus[model]==2.4.8"
and import these:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_milvus.utils.sparse import BM25SparseEmbedding
from langchain_milvus.vectorstores import Milvus
You can also see and clone the whole code in this gist.
Let’s go.
Dense Embeddings
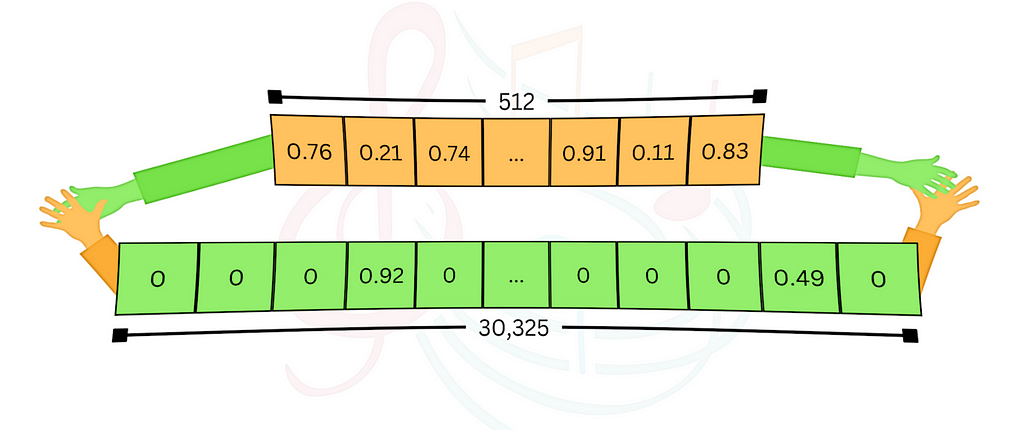
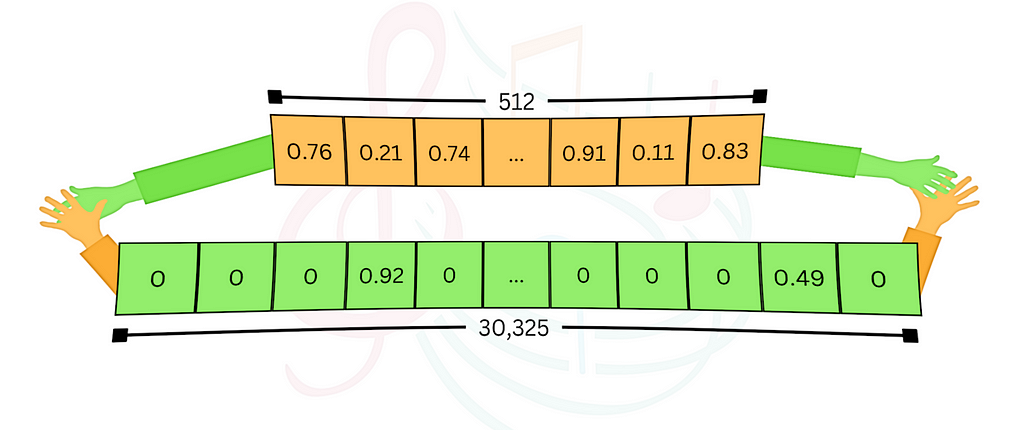
The most common way to use vector stores is with dense embeddings. Here we use a pre-trained model to embed the data (usually text, but could be other media like images etc.) into high dimensional vectors, and store it in the vector database. The vectors have a couple of hundred (or even thousands of) dimensions, and each entry is a floating-point number. Typically, all of the entries in the vectors are occupied with non-zero values, hence the term “dense”. Given a query, we embed it using the same model, and the vector store retrieves similar, relevant data based on vector similarity. Using langchain-milvus, it’s just a couple lines of code. Let’s see how it’s done.
First, we define the vector store using a model from HuggingFace:
dense_embedding = HuggingFaceEmbeddings(model_name=
"sentence-transformers/all-MiniLM-L6-v2")
vector_store = Milvus(
embedding_function=dense_embedding,
connection_args={"uri": "./milvus_dense.db"}, # Using milvus-lite for simplicity
auto_id=True,
)
Second, we insert our data into the vector store:
document = [
"Today was very warm during the day but cold at night",
"In Israel, Hot is a TV provider that broadcasts 7 days a week",
]
vector_store.add_texts(documents)
Behind the scenes, each document is embedded into a vector using the model we supplied, and is stored alongside the original text.
Finally, we can search for a query and print the result we got:
query = "What is the weather? is it hot?"
dense_output = vector_store.similarity_search(query=query, k=1)
print(f"Dense embeddings results:n{dense_output[0].page_content}n")
# output: Dense embeddings results:
# Today was very warm during the day but cold at night
Here, the query is embedded, and the vector store does the (usually approximated) similarity search and returns the closest content it found.
Dense embeddings models are trained to capture the semantic meaning of the data and represent it in the multidimensional space. The advantage is clear — it enables semantic search, which means the results are based on the query’s meaning. But sometimes that’s not enough. If you look for specific keywords, or even words without broader meaning (like names), the semantic search will misguide you and this approach will fail.
Sparse embeddings
Ages before LLMs became a thing, and learned models weren’t so popular, search engines used traditional methods such as TF-IDF or its modern enhancement, BM25 (known for it’s use in Elastic), to search relevant data. With these methods, the number of dimensions is the vocabulary size (typically tens of thousands, much larger than the dense vector space), and each entry represents the relevance of a keyword to a document, while taking into consideration the frequency of the term and its rarity across the corpus of documents. For each data point, most of the entries are zeros (for words that don’t appear), hence the term “sparse”. Although under the hood the implementation is different, with langchain-milvus interface it becomes very similar. Let’s see it in action:
sparse_embedding = BM25SparseEmbedding(corpus=documents)
vector_store = Milvus(
embedding_function=sparse_embedding,
connection_args={"uri": "./milvus_sparse.db"},
auto_id=True,
)
vector_store.add_texts(documents)
query = "Does Hot cover weather changes during weekends?"
sparse_output = vector_store.similarity_search(query=query, k=1)
print(f"Sparse embeddings results:n{sparse_output[0].page_content}n")
# output: Sparse embeddings results:
# In Israel, Hot is a TV provider that broadcast 7 days a week
BM25 is effective for exact keyword matching, which is useful for terms or names that lack clear semantic meaning. However, it will not capture the intent of the query, and will yield poor results in many cases where semantic understanding is needed.
Note: the term “Sparse embeddings” also refers to advanced methods like SPLADE or Elastic Elser. These methods can also be used with Milvus and can be integrated into hybrid search!
Hybrid Search
If you swap the queries between the two examples above, and use each one with the other’s embedding, both will produce the wrong result. This demonstrates the fact that each method has its strengths but also its weaknesses. Hybrid search combines the two, aiming to leverage the best from both worlds. By indexing data with both dense and sparse embeddings, we can perform searches that consider both semantic relevance and keyword matching, balancing results based on custom weights. Again, the internal implementation is more complicated, but langchain-milvus makes it pretty simple to use. Let’s look at how this works:
vector_store = Milvus(
embedding_function=[
sparse_embedding,
dense_embedding,
],
connection_args={"uri": "./milvus_hybrid.db"},
auto_id=True,
)
vector_store.add_texts(documents)
In this setup, both sparse and dense embeddings are applied. Let’s test the hybrid search with equal weighting:
query = "Does Hot cover weather changes during weekends?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.49, 0.51]}, # Combine both results!
)
print(f"Hybrid search results:n{hybrid_output[0].page_content}")
# output: Hybrid search results:
# In Israel, Hot is a TV provider that broadcast 7 days a week
This searches for similar results using each embedding function, gives each score a weight, and returns the result with the best weighted score. We can see that with slightly more weight to the dense embeddings, we get the result we desired. This is true for the second query as well.
If we give more weight to the dense embeddings, we will once again get non-relevant results, as with the dense embeddings alone:
query = "When and where is Hot active?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.2, 0.8]}, # Note -> the weights changed
)
print(f"Hybrid search results:n{hybrid_output[0].page_content}")
# output: Hybrid search results:
# Today was very warm during the day but cold at night
Finding the right balance between dense and sparse is not a trivial task, and can be seen as part of a wider hyper-parameter optimization problem. There is an ongoing research and tools that trying to solve such issues in this area, for example IBM’s AutoAI for RAG.
There are many more ways you can adapt and use the hybrid search approach. For instance, if each document has an associated title, you could use two dense embedding functions (possibly with different models) — one for the title and another for the document content — and perform a hybrid search on both indices. Milvus currently supports up to 10 different vector fields, providing flexibility for complex applications. There are also additional configurations for indexing and reranking methods. You can see Milvus documentation about the available params and options.
Closing words
With Milvus’s multi-vector search capabilities now accessible through LangChain, you can integrate hybrid search into your applications easily. This opens up new possibilities to apply different search strategies in your application, making it easy to tailor search logic to fit specific use cases. For us, it was a good opportunity to contribute to an open source project. Many of the libraries and tools we use on a daily basis are open source, and it’s nice to give back to the community. Hopefully it will be useful for others.
Finally, a big shout-out to Erick Friis and Cheng Zi for all the effort they put on langchain-milvus, and in these PRs particularly. This work couldn’t have happened without them.
Dance between dense and sparse embeddings: Enabling Hybrid Search in LangChain-Milvus was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Dance between dense and sparse embeddings: Enabling Hybrid Search in LangChain-Milvus