

How we use a shared Spark server to make our Spark infrastructure more efficient
Spark Connect is a relatively new component in the Spark ecosystem that allows thin clients to run Spark applications on a remote Spark cluster. This technology can offer some benefits to Spark applications that use the DataFrame API. Spark has long allowed to run SQL queries on a remote Thrift JDBC server. However, this ability to remotely run client applications written in any supported language (Scala, Python) appeared only in Spark 3.4.
In this article, I will share our experience using Spark Connect (version 3.5). I will talk about the benefits we gained, technical details related to running Spark client applications, and some tips on how to make your Spark Connect setup more efficient and stable.
Motivation for use
Spark is one of the key components of the analytics platform at Joom. We have a large number of internal users and over 1000 custom Spark applications. These applications run at different times of day, have different complexity, and require very different amounts of computing resources (ranging from a few cores for a couple of minutes to over 250 cores for several days). Previously, all of them were always executed as separate Spark applications (with their own driver and executors), which, in the case of small and medium-sized applications (we historically have many such applications), led to noticeable overhead. With the introduction of Spark Connect, it is now possible to set up a shared Spark Connect server and run many Spark client applications on it. Technically, the Spark Connect server is a Spark application with an embedded Spark Connect endpoint.
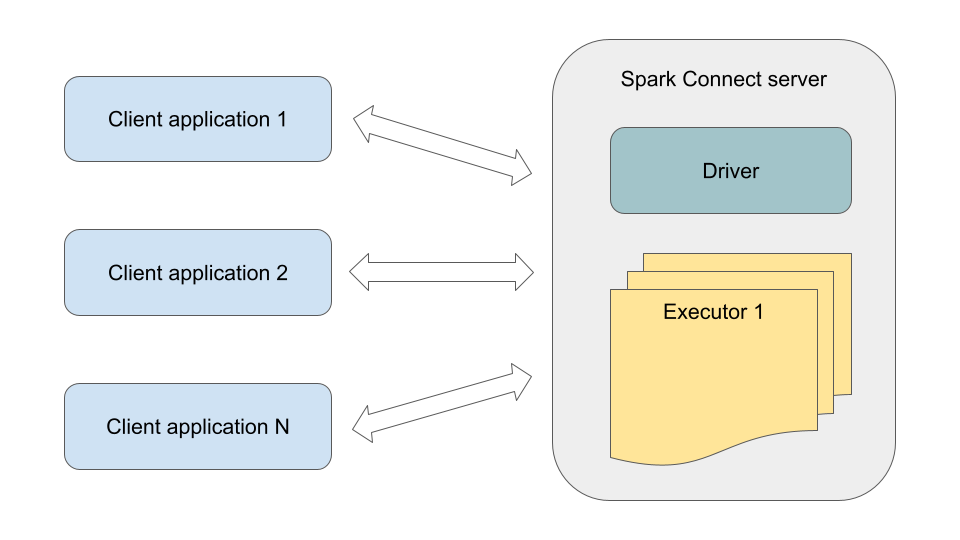
Here are the benefits we were able to get from this:
- Resource savings
– When running via Spark Connect, client applications do not require their own Spark driver (which typically uses over 1.5 GB of memory). Instead, they use a thin client with a typical memory consumption of 200 MB.
– Executor utilization improves since any executor can run the tasks of multiple client applications. For example, suppose some Spark application, at some point in its execution, starts using significantly fewer cores and memory than initially requested. There are many reasons why this can happen. Then, in the case of a separate Spark application, currently unused resources are often wasted since dynamic allocation often does not provide efficient scale-down. However, with the Spark Connect server, the freed-up cores and memory can immediately be used to run tasks of other client applications. - Reduced startup wait time
– For various reasons, we have to limit the number of simultaneously running separate Spark applications, and they may wait in the queue for quite a long time if all slots are currently occupied. It can negatively affect data readiness time and user experience. In the case of the Spark Connect server, we have so far been able to avoid such limitations, and all Spark Connect client applications start running immediately after launch.
– For ad-hoc executions, it is desirable to minimize the time to get results as much as possible and avoid keeping people waiting. In the case of separate Spark applications, launching a client application often requires provisioning additional EC2 nodes for its driver and executors, as well as initializing the driver and executors. All of this together can take more than 4 minutes. In the case of the Spark Connect server, at least its driver is always up and ready to accept requests, so it is only a matter of waiting for additional executors, and often executors are already available. This may significantly reduce the wait time for ad-hoc applications to be ready.
Our constraints
At the moment, we do not run long-running heavy applications on Spark Connect for the following reasons:
- They may cause failure or unstable behavior of the Spark Connect server (e.g., by overflowing disks on executor nodes). It can lead to large-scale problems for the entire platform.
- They often require unique memory settings and use specific optimization techniques (e.g., custom extraStrategies).
- We currently have a problem with giving the Spark Connect server a lot of executors to handle a very large simultaneous load (this is related to the behavior of Spark Task Scheduler and is beyond the scope of this article).
Therefore, heavy applications still run as separate Spark applications.
Launching client applications
We use Spark on Kubernetes/EKS and Airflow. Some code examples will be specific to this environment.
We have too many different, constantly changing Spark applications, and it would take too much time to manually determine for each one whether it should run on Spark Connect according to our criteria or not. Furthermore, the list of applications running on Spark Connect needs to be updated regularly. For example, suppose today, some application is light enough, so we have decided to run it on Spark Connect. But tomorrow, its developers may add several large joins, making it quite heavy. Then, it will be preferable to run it as a separate Spark application. The reverse situation is also possible.
Eventually, we created a service to automatically determine how to launch each specific client application. This service analyzes the history of previous runs for each application, evaluating such metrics as Total Task Time, Shuffle Write, Disk Spill, and others (this data is collected using SparkListener). Custom parameters set for the applications by developers (e.g., memory settings of drivers and executors) are also considered. Based on this data, the service automatically determines for each application whether it should be run this time on the Spark Connect server or as a separate Spark application. Thus, all our applications should be ready to run in either of the two ways.
In our environment, each client application is built independently of the others and has its own JAR file containing the application code, as well as specific dependencies (for example, ML applications often use third-party libraries like CatBoost and so on). The problem is that the SparkSession API for Spark Connect is somewhat different from the SparkSession API used for separate Spark applications (Spark Connect clients use the spark-connect-client-jvm artifact). Therefore, we are supposed to know at the build time of each client application whether it will run via Spark Connect or not. But we do not know that. The following describes our approach to launching client applications, which eliminates the need to build and manage two versions of JAR artifact for the same application.
For each Spark client application, we build only one JAR file containing the application code and specific dependencies. This JAR is used both when running on Spark Connect and when running as a separate Spark application. Therefore, these client JARs do not contain specific Spark dependencies. The appropriate Spark dependencies (spark-core/spark-sql or spark-connect-client-jvm) will be provided later in the Java classpath, depending on the run mode. In any case, all client applications use the same Scala code to initialize SparkSession, which operates depending on the run mode. All client application JARs are built for the regular Spark API. So, in the part of the code intended for Spark Connect clients, the SparkSession methods specific to the Spark Connect API (remote, addArtifact) are called via reflection:
val sparkConnectUri: Option[String] = Option(System.getenv("SPARK_CONNECT_URI"))
val isSparkConnectMode: Boolean = sparkConnectUri.isDefined
def createSparkSession(): SparkSession = {
if (isSparkConnectMode) {
createRemoteSparkSession()
} else {
SparkSession.builder
// Whatever you need to do to configure SparkSession for a separate
// Spark application.
.getOrCreate
}
}
private def createRemoteSparkSession(): SparkSession = {
val uri = sparkConnectUri.getOrElse(throw new Exception(
"Required environment variable 'SPARK_CONNECT_URI' is not set."))
val builder = SparkSession.builder
// Reflection is used here because the regular SparkSession API does not
// contain these methods. They are only available in the SparkSession API
// version for Spark Connect.
classOf[SparkSession.Builder]
.getDeclaredMethod("remote", classOf[String])
.invoke(builder, uri)
// A set of identifiers for this application (to be used later).
val scAppId = s"spark-connect-${UUID.randomUUID()}"
val airflowTaskId = Option(System.getenv("AIRFLOW_TASK_ID"))
.getOrElse("unknown_airflow_task_id")
val session = builder
.config("spark.joom.scAppId", scAppId)
.config("spark.joom.airflowTaskId", airflowTaskId)
.getOrCreate()
// If the client application uses your Scala code (e.g., custom UDFs),
// then you must add the jar artifact containing this code so that it
// can be used on the Spark Connect server side.
val addArtifact = Option(System.getenv("ADD_ARTIFACT_TO_SC_SESSION"))
.forall(_.toBoolean)
if (addArtifact) {
val mainApplicationFilePath =
System.getenv("SPARK_CONNECT_MAIN_APPLICATION_FILE_PATH")
classOf[SparkSession]
.getDeclaredMethod("addArtifact", classOf[String])
.invoke(session, mainApplicationFilePath)
}
Runtime.getRuntime.addShutdownHook(new Thread() {
override def run(): Unit = {
session.close()
}
})
session
}
In the case of Spark Connect mode, this client code can be run as a regular Java application anywhere. Since we use Kubernetes, this runs in a Docker container. All dependencies specific to Spark Connect are packed into a Docker image used to run client applications (a minimal example of this image can be found here). The image contains not only the spark-connect-client-jvm artifact but also other common dependencies used by almost all client applications (e.g., hadoop-aws since we almost always have interaction with S3 storage on the client side).
FROM openjdk:11-jre-slim
WORKDIR /app
# Here, we copy the common artifacts required for any of our Spark Connect
# clients (primarily spark-connect-client-jvm, as well as spark-hive,
# hadoop-aws, scala-library, etc.).
COPY build/libs/* /app/
COPY src/main/docker/entrypoint.sh /app/
RUN chmod +x ./entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
This common Docker image is used to run all our client applications when it comes to running them via Spark Connect. At the same time, it does not contain client JARs with the code of particular applications and their dependencies because there are many such applications that are constantly updated and may depend on any third-party libraries. Instead, when a particular client application is launched, the location of its JAR file is passed using an environment variable, and that JAR is downloaded during initialization in entrypoint.sh:
#!/bin/bash
set -eo pipefail
# This variable will also be used in the SparkSession builder within
# the application code.
export SPARK_CONNECT_MAIN_APPLICATION_FILE_PATH="/tmp/$(uuidgen).jar"
# Download the JAR with the code and specific dependencies of the client
# application to be run. All such JAR files are stored in S3, and when
# creating a client Pod, the path to the required JAR is passed to it
# via environment variables.
java -cp "/app/*" com.joom.analytics.sc.client.S3Downloader
${MAIN_APPLICATION_FILE_S3_PATH} ${SPARK_CONNECT_MAIN_APPLICATION_FILE_PATH}
# Launch the client application. Any MAIN_CLASS initializes a SparkSession
# at the beginning of its execution using the code provided above.
java -cp ${SPARK_CONNECT_MAIN_APPLICATION_FILE_PATH}:"/app/*" ${MAIN_CLASS} "$@"
Finally, when it comes time to launch the application, our custom SparkAirflowOperator automatically determines the execution mode (Spark Connect or separate) based on the statistics of previous runs of this application.
- In the case of Spark Connect, we use KubernetesPodOperator to launch the client Pod of the application. KubernetesPodOperator takes as parameters the previously described Docker image, as well as the environment variables (MAIN_CLASS, JAR_PATH and others), which will be available for use within entrypoint.sh and the application code. There is no need to allocate many resources to the client Pod (for example, its typical consumption in our environment: memory — 200 MB, vCPU — 0.15).
- In the case of a separate Spark application, we use our custom AirflowOperator, which runs Spark applications using spark-on-k8s-operator and the official Spark Docker image. Let’s skip the details about our Spark AirflowOperator for now, as it is a large topic deserving a separate article.
Compatibility issues with regular Spark applications
Not all existing Spark applications can be successfully executed on Spark Connect since its SparkSession API is different from the SparkSession API used for separate Spark applications. For example, if your code uses sparkSession.sparkContext or sparkSession.sessionState, it will fail in the Spark Connect client because the Spark Connect version of SparkSession does not have these properties.
In our case, the most common cause of problems was using sparkSession.sessionState.catalog and sparkSession.sparkContext.hadoopConfiguration. In some cases, sparkSession.sessionState.catalog can be replaced with sparkSession.catalog, but not always. sparkSession.sparkContext.hadoopConfiguration may be needed if the code executed on the client side contains operations on your data storage, such as this:
def delete(path: Path, recursive: Boolean = true)
(implicit hadoopConfig: Configuration): Boolean = {
val fs = path.getFileSystem(hadoopConfig)
fs.delete(path, recursive)
}
Fortunately, it is possible to create a standalone SessionCatalog for use within the Spark Connect client. In this case, the class path of the Spark Connect client must also include org.apache.spark:spark-hive_2.12, as well as libraries for interacting with your storage (since we use S3, so in our case, it is org.apache.hadoop:hadoop-aws).
import org.apache.spark.SparkConf
import org.apache.hadoop.conf.Configuration
import org.apache.spark.sql.hive.StandaloneHiveExternalCatalog
import org.apache.spark.sql.catalyst.catalog.{ExternalCatalogWithListener, SessionCatalog}
// This is just an example of what the required properties might look like.
// All of them should already be set for existing Spark applications in one
// way or another, and their complete list can be found in the UI of any
// running separate Spark application on the Environment tab.
val sessionCatalogConfig = Map(
"spark.hadoop.hive.metastore.uris" -> "thrift://metastore.spark:9083",
"spark.sql.catalogImplementation" -> "hive",
"spark.sql.catalog.spark_catalog" -> "org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
val hadoopConfig = Map(
"hive.metastore.uris" -> "thrift://metastore.spark:9083",
"fs.s3.impl" -> "org.apache.hadoop.fs.s3a.S3AFileSystem",
"fs.s3a.aws.credentials.provider" -> "com.amazonaws.auth.DefaultAWSCredentialsProviderChain",
"fs.s3a.endpoint" -> "s3.amazonaws.com",
// and others...
)
def createStandaloneSessionCatalog(): (SessionCatalog, Configuration) = {
val sparkConf = new SparkConf().setAll(sessionCatalogConfig)
val hadoopConfiguration = new Configuration()
hadoopConfig.foreach {
case (key, value) => hadoopConfiguration.set(key, value)
}
val externalCatalog = new StandaloneHiveExternalCatalog(
sparkConf, hadoopConfiguration)
val sessionCatalog = new SessionCatalog(
new ExternalCatalogWithListener(externalCatalog)
)
(sessionCatalog, hadoopConfiguration)
}
You also need to create a wrapper for HiveExternalCatalog accessible in your code (because the HiveExternalCatalog class is private to the org.apache.spark package):
package org.apache.spark.sql.hive
import org.apache.hadoop.conf.Configuration
import org.apache.spark.SparkConf
class StandaloneHiveExternalCatalog(conf: SparkConf, hadoopConf: Configuration)
extends HiveExternalCatalog(conf, hadoopConf)
Additionally, it is often possible to replace code that does not work on Spark Connect with an alternative, for example:
- sparkSession.createDataFrame(sparkSession.sparkContext.parallelize(data), schema) ==> sparkSession.createDataFrame(data.toList.asJava, schema)
- sparkSession.sparkContext.getConf.get(“some_property”) ==> sparkSession.conf.get(“some_property”)
Fallback to a separate Spark application
Unfortunately, it is not always easy to fix a particular Spark application to make it work as a Spark Connect client. For example, third-party Spark components used in the project pose a significant risk, as they are often written without considering compatibility with Spark Connect. Since, in our environment, any Spark application can be automatically launched on Spark Connect, we found it reasonable to implement a fallback to a separate Spark application in case of failure. Simplified, the logic is as follows:
- If some application fails on Spark Connect, we immediately try to rerun it as a separate Spark application. At the same time, we increment the counter of failures that occurred during execution on Spark Connect (each client application has its own counter).
- The next time this application is launched, we check the failure counter of this application:
– If there are fewer than 3 failures, we assume that the last time, the application may have failed not because of incompatibility with Spark Connect but due to any other possible temporary reasons. So, we try to run it on Spark Connect again. If it completes successfully this time, the failure counter of this client application is reset to zero.
– If there are already 3 failures, we assume that the application cannot work on Spark Connect and stop attempting to run it there for now. Further, it will be launched only as a separate Spark application. - If the application has 3 failures on Spark Connect, but the last one was more than 2 months ago, we try to run it on Spark Connect again (in case something has changed in it during that time, making it compatible with Spark Connect). If it succeeds this time, we reset the failure counter to zero again. If unsuccessful again, the next attempt will be in another 2 months.
This approach is somewhat simpler than maintaining code that identifies the reasons for failures from logs, and it works well in most cases. Attempts to run incompatible applications on Spark Connect usually do not have any significant negative impact because, in the vast majority of cases, if an application is incompatible with Spark Connect, it fails immediately after launch without wasting time and resources. However, it is important to mention that all our applications are idempotent.
Statistics gathering
As I already mentioned, we collect Spark statistics for each Spark application (most of our platform optimizations and alerts depend on it). This is easy when the application runs as a separate Spark application. In the case of Spark Connect, the stages and tasks of each client application need to be separated from the stages and tasks of all other client applications that run simultaneously within the shared Spark Connect server.
You can pass any identifiers to the Spark Connect server by setting custom properties for the client SparkSession:
val session = builder
.config("spark.joom.scAppId", scAppId)
.config("spark.joom.airflowTaskId", airflowTaskId)
.getOrCreate()
Then, in the SparkListener on the Spark Connect server side, you can retrieve all the passed information and associate each stage/task with the particular client application.
class StatsReportingSparkListener extends SparkListener {
override def onStageSubmitted(stageSubmitted: SparkListenerStageSubmitted): Unit = {
val stageId = stageSubmitted.stageInfo.stageId
val stageAttemptNumber = stageSubmitted.stageInfo.attemptNumber()
val scAppId = stageSubmitted.properties.getProperty("spark.joom.scAppId")
// ...
}
}
Here, you can find the code for the StatsReportingSparkListener we use to collect statistics. You might also be interested in this free tool for finding performance issues in your Spark applications.
Optimization and stability improvement
The Spark Connect server is a permanently running Spark application where a large number of clients can run their Jobs. Therefore, it can be worthwhile to customize its properties, which can make it more reliable and prevent waste of resources. Here are some settings that turned out to be useful in our case:
// Using dynamicAllocation is important for the Spark Connect server
// because the workload can be very unevenly distributed over time.
spark.dynamicAllocation.enabled: true // default: false
// This pair of parameters is responsible for the timely removal of idle
// executors:
spark.dynamicAllocation.cachedExecutorIdleTimeout: 5m // default: infinity
spark.dynamicAllocation.shuffleTracking.timeout: 5m // default: infinity
// To create new executors only when the existing ones cannot handle
// the received tasks for a significant amount of time. This allows you
// to save resources when a small number of tasks arrive at some point
// in time, which do not require many executors for timely processing.
// With increased schedulerBacklogTimeout, unnecessary executors do not
// have the opportunity to appear by the time all incoming tasks are
// completed. The time to complete the tasks increases slightly with this,
// but in most cases, this increase is not significant.
spark.dynamicAllocation.schedulerBacklogTimeout: 30s // default: 1s
// If, for some reason, you need to stop the execution of a client
// application (and free up resources), you can forcibly terminate the client.
// Currently, even explicitly closing the client SparkSession does not
// immediately end the execution of its corresponding Jobs on the server.
// They will continue to run for a duration equal to 'detachedTimeout'.
// Therefore, it may be reasonable to reduce it.
spark.connect.execute.manager.detachedTimeout: 2m // default: 5m
// We have encountered a situation when killed tasks may hang for
// an unpredictable amount of time, leading to bad consequences for their
// executors. In this case, it is better to remove the executor on which
// this problem occurred.
spark.task.reaper.enabled: true // default: false
spark.task.reaper.killTimeout: 300s // default: -1
// The Spark Connect server can run for an extended period of time. During
// this time, executors may fail, including for reasons beyond our control
// (e.g., AWS Spot interruptions). This option is needed to prevent
// the entire server from failing in such cases.
spark.executor.maxNumFailures: 1000
// In our experience, BroadcastJoin can lead to very serious performance
// issues in some cases. So, we decided to disable broadcasting.
// Disabling this option usually does not result in a noticeable performance
// degradation for our typical applications anyway.
spark.sql.autoBroadcastJoinThreshold: -1 // default: 10MB
// For many of our client applications, we have to add an artifact to
// the client session (method sparkSession.addArtifact()).
// Using 'useFetchCache=true' results in double space consumption for
// the application JAR files on executors' disks, as they are also duplicated
// in a local cache folder. Sometimes, this even causes disk overflow with
// subsequent problems for the executor.
spark.files.useFetchCache: false // default: true
// To ensure fair resource allocation when multiple applications are
// running concurrently.
spark.scheduler.mode: FAIR // default: FIFO
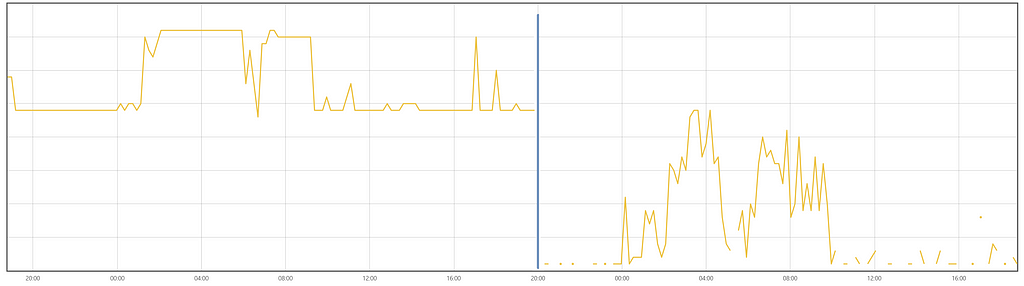
For example, after we adjusted the idle timeout properties, the resource utilization changed as follows:
Preventive restart
In our environment, the Spark Connect server (version 3.5) may become unstable after a few days of continuous operation. Most often, we face randomly hanging client application jobs for an infinite amount of time, but there may be other problems as well. Also, over time, the probability of a random failure of the entire Spark Connect server increases dramatically, and this can happen at the wrong moment.
As this component evolves, it will likely become more stable (or we will find out that we have done something wrong in our Spark Connect setup). But currently, the simplest solution has turned out to be a daily preventive restart of the Spark Connect server at a suitable moment (i.e., when no client applications are running on it). An example of what the restart code might look like can be found here.
Conclusion
In this article, I described our experience using Spark Connect to run a large number of diverse Spark applications.
To summarize the above:
- This component can help save resources and reduce the wait time for the execution of Spark client applications.
- It is better to be careful about which applications should be run on the shared Spark Connect server, as resource-intensive applications may cause problems for the entire system.
- You can create an infrastructure for launching client applications so that the decision on how to run any application (either as a separate Spark application or as a Spark Connect client) can be made automatically at the moment of launch.
- It is important to note that not all applications will be able to run on Spark Connect, but the number of such cases can be significantly reduced. If there is a possibility of running applications that have not been tested for compatibility with the Spark Connect version of SparkSession API, it is worth implementing a fallback to separate Spark applications.
- It is worth paying attention to the Spark properties that can improve resource utilization and increase the overall stability of the Spark Connect server. It may also be reasonable to set up a periodic preventive restart of the Spark Connect server to reduce the probability of accidental failure and unwanted behavior.
Overall, we have had a positive experience using Spark Connect in our company. We will continue to watch the development of this technology with great interest, and there is a plan to expand its use.
Adopting Spark Connect was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Adopting Spark Connect