
A comparison of frameworks, models, and costs
Robert Corwin, CEO, Austin Artificial Intelligence
David Davalos, ML Engineer, Austin Artificial Intelligence
Oct 24, 2024
Large Language Models (LLMs) have rapidly transformed the technology landscape, but security concerns persist, especially with regard to sending private data to external third parties. In this blog entry, we dive into the options for deploying Llama models locally and privately, that is, on one’s own computer. We get Llama 3.1 running locally and investigate key aspects such as speed, power consumption, and overall performance across different versions and frameworks. Whether you’re a technical expert or simply curious about what’s involved, you’ll find insights into local LLM deployment. For a quick overview, non-technical readers can skip to our summary tables, while those with a technical background may appreciate the deeper look into specific tools and their performance.
All images by authors unless otherwise noted. The authors and Austin Artifical Intelligence, their employer, have no affiliations with any of the tools used or mentioned in this article.
Key Points
Running LLMs: LLM models can be downloaded and run locally on private servers using tools and frameworks widely available in the community. While running the most powerful models require rather expensive hardware, smaller models can be run on a laptop or desktop computer.
Privacy and Customizability: Running LLMs on private servers provides enhanced privacy and greater control over model settings and usage policies.
Model Sizes: Open-source Llama models come in various sizes. For example, Llama 3.1 comes in 8 billion, 70 billion, and 405 billion parameter versions. A “parameter” is roughly defined as the weight on one node of the network. More parameters increase model performance at the expense of size in memory and disk.
Quantization: Quantization saves memory and disk space by essentially “rounding” weights to fewer significant digits — at the expense of accuracy. Given the vast number of parameters in LLMs, quantization is very valuable for reducing memory usage and speeding up execution.
Costs: Local implementations, referencing GPU energy consumption, demonstrate cost-effectiveness compared to cloud-based solutions.
Privacy and Reliability as Motivations
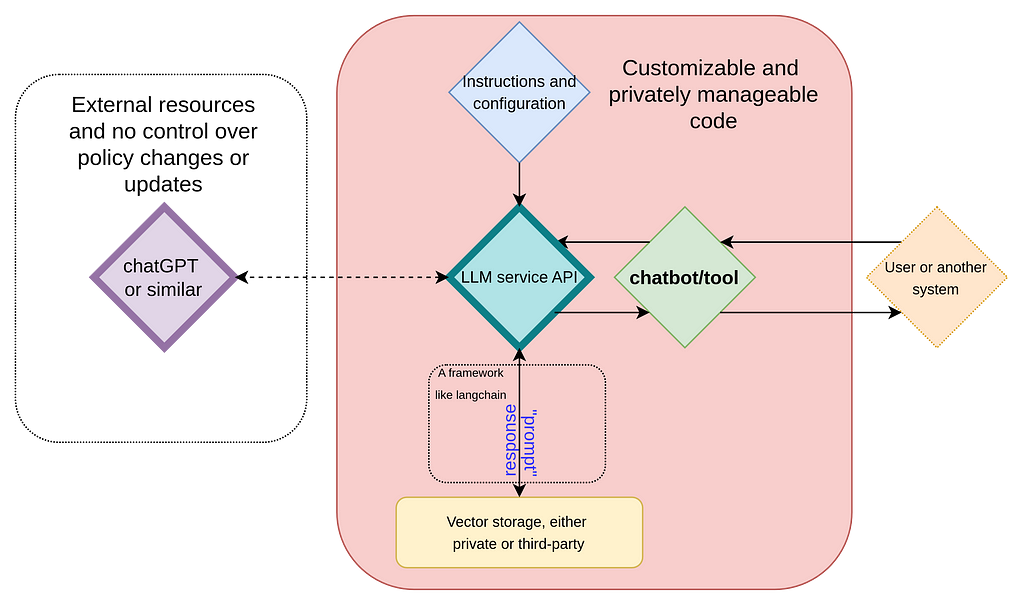
In one of our previous entries we explored the key concepts behind LLMs and how they can be used to create customized chatbots or tools with frameworks such as Langchain (see Fig. 1). In such schemes, while data can be protected by using synthetic data or obfuscation, we still must send data externally a third party and have no control over any changes in the model, its policies, or even its availability. A solution is simply to run an LLM on a private server (see Fig. 2). This approach ensures full privacy and mitigates the dependency on external service providers.
Concerns about implementing LLMs privately include costs, power consumption, and speed. In this exercise, we get LLama 3.1 running while varying the 1. framework (tools) and 2. degrees of quantization and compare the ease of use of the frameworks, the resultant performance in terms of speed, and power consumption. Understanding these trade-offs is essential for anyone looking to harness the full potential of AI while retaining control over their data and resources.
Fig. 1 Diagram illustrating a typical backend setup for chatbots or tools, with ChatGPT (or similar models) functioning as the natural language processing engine. This setup relies on prompt engineering to customize responses.”
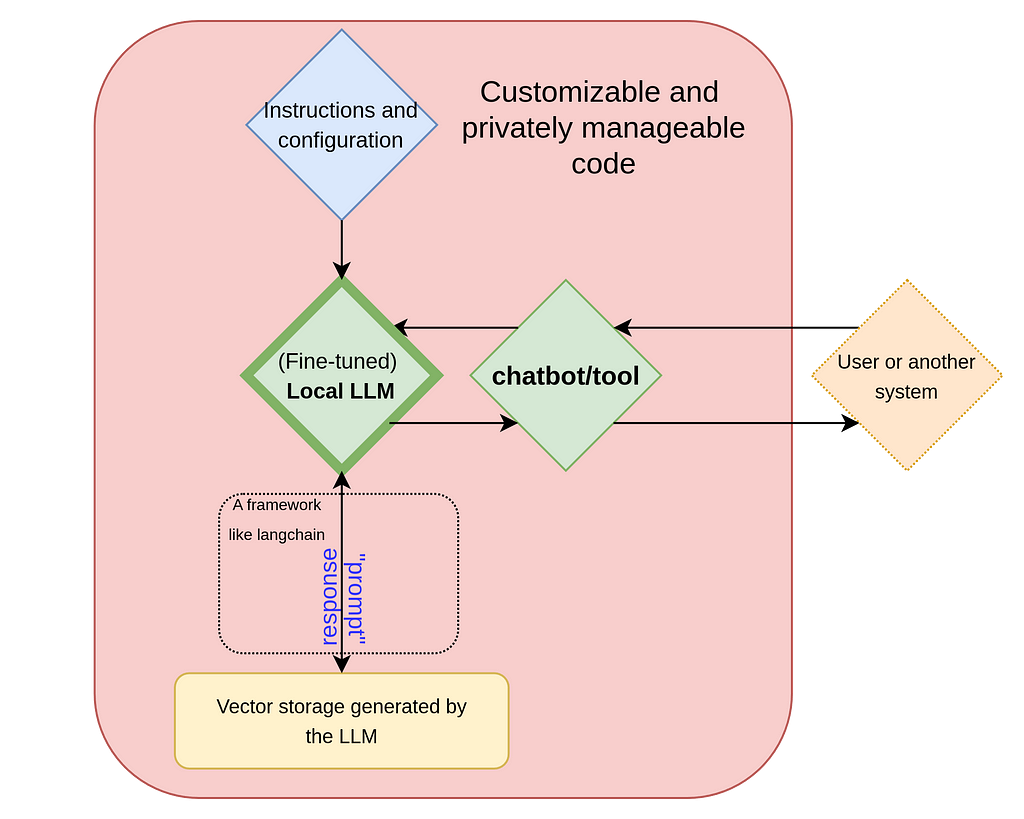
Fig. 2 Diagram of a fully private backend configuration where all components, including the large language model, are hosted on a secure server, ensuring complete control and privacy.
Quantization and GGUF Files
Before diving into our impressions of the tools we explored, let’s first discuss quantization and the GGUF format.
Quantization is a technique used to reduce the size of a model by converting weights and biases from high-precision floating-point values to lower-precision representations. LLMs benefit greatly from this approach, given their vast number of parameters. For example, the largest version of Llama 3.1 contains a staggering 405 billion parameters. Quantization can significantly reduce both memory usage and execution time, making these models more efficient to run across a variety of devices. For an in-depth explanation and nomenclature of quantization types, check out this great introduction. A conceptual overview can also be found here.
The GGUF format is used to store LLM models and has recently gained popularity for distributing and running quantized models. It is optimized for fast loading, reading, and saving. Unlike tensor-only formats, GGUF also stores model metadata in a standardized manner, making it easier for frameworks to support this format or even adopt it as the norm.
Tools and Models Analyzed
We explored four tools to run Llama models locally:
Our primary focus was on llama.cpp and Ollama, as these tools allowed us to deploy models quickly and efficiently right out of the box. Specifically, we explored their speed, energy cost, and overall performance. For the models, we primarily analyzed the quantized 8B and 70B Llama 3.1 versions, as they ran within a reasonable time frame.
First Impressions and Installation
HuggingFace
HuggingFace’s transformers library and Hub are well-known and widely used in the community. They offer a wide range of models and tools, making them a popular choice for many developers. Its installation generally does not cause major problems once a proper environment is set up with Python. At the end of the day, the biggest benefit of Huggingface was its online hub, which allows for easy access to quantized models from many different providers. On the other hand, using the transformers library directly to load models, especially quantized ones, was rather tricky. Out of the box, the library seemingly directly dequantizes models, taking a great amount of ram and making it unfeasible to run in a local server.
Although Hugging Face supports 4- and 8-bit quantization and dequantization with bitsandbytes, our initial impression is that further optimization is needed. Efficient inference may simply not be its primary focus. Nonetheless, Hugging Face offers excellent documentation, a large community, and a robust framework for model training.
vLLM
Similar to Hugging Face, vLLM is easy to install with a properly configured Python environment. However, support for GGUF files is still highly experimental. While we were able to quickly set it up to run 8B models, scaling beyond that proved challenging, despite the excellent documentation.
Overall, we believe vLLM has great potential. However, we ultimately opted for the llama.cpp and Ollama frameworks for their more immediate compatibility and efficiency. To be fair, a more thorough investigation could have been conducted here, but given the immediate success we found with other libraries, we chose to focus on those.
Ollama
We found Ollama to be fantastic. Our initial impression is that it is a user-ready tool for inferring Llama models locally, with an ease-of-use that works right out of the box. Installing it for Mac and Linux users is straightforward, and a Windows version is currently in preview. Ollama automatically detects your hardware and manages model offloading between CPU and GPU seamlessly. It features its own model library, automatically downloading models and supporting GGUF files. Although its speed is slightly slower than llama.cpp, it performs well even on CPU-only setups and laptops.
For a quick start, once installed, running ollama run llama3.1:latest will load the latest 8B model in conversation mode directly from the command line.
One downside is that customizing models can be somewhat impractical, especially for advanced development. For instance, even adjusting the temperature requires creating a new chatbot instance, which in turn loads an installed model. While this is a minor inconvenience, it does facilitate the setup of customized chatbots — including other parameters and roles — within a single file. Overall, we believe Ollama serves as an effective local tool that mimics some of the key features of cloud services.
It is worth noting that Ollama runs as a service, at least on Linux machines, and offers handy, simple commands for monitoring which models are running and where they’re offloaded, with the ability to stop them instantly if needed. One challenge the community has faced is configuring certain aspects, such as where models are stored, which requires technical knowledge of Linux systems. While this may not pose a problem for end-users, it perhaps slightly hurts the tool’s practicality for advanced development purposes.
llama.cpp
llama.cpp emerged as our favorite tool during this analysis. As stated in its repository, it is designed for running inference on large language models with minimal setup and cutting-edge performance. Like Ollama, it supports offloading models between CPU and GPU, though this is not available straight out of the box. To enable GPU support, you must compile the tool with the appropriate flags — specifically, GGML_CUDA=on. We recommend using the latest version of the CUDA toolkit, as older versions may not be compatible.
The tool can be installed as a standalone by pulling from the repository and compiling, which provides a convenient command-line client for running models. For instance, you can execute llama-cli -p ‘you are a useful assistant’ -m Meta-Llama-3-8B-Instruct.Q8_0.gguf -cnv. Here, the final flag enables conversation mode directly from the command line. llama-cli offers various customization options, such as adjusting the context size, repetition penalty, and temperature, and it also supports GPU offloading options.
Similar to Ollama, llama.cpp has a Python binding which can be installed via pip install llama-cpp-python. This Python library allows for significant customization, making it easy for developers to tailor models to specific client needs. However, just as with the standalone version, the Python binding requires compilation with the appropriate flags to enable GPU support.
One minor downside is that the tool doesn’t yet support automatic CPU-GPU offloading. Instead, users need to manually specify how many layers to offload onto the GPU, with the remainder going to the CPU. While this requires some fine-tuning, it is a straightforward, manageable step.
For environments with multiple GPUs, like ours, llama.cpp provides two split modes: row mode and layer mode. In row mode, one GPU handles small tensors and intermediate results, while in layer mode, layers are divided across GPUs. In our tests, both modes delivered comparable performance (see analysis below).
Our Analysis
► From now on, results concern only llama.cpp and Ollama.
We conducted an analysis of the speed and power consumption of the 70B and 8B Llama 3.1 models using Ollama and llama.cpp. Specifically, we examined the speed and power consumption per token for each model across various quantizations available in Quant Factory.
To carry out this analysis, we developed a small application to evaluate the models once the tool was selected. During inference, we recorded metrics such as speed (tokens per second), total tokens generated, temperature, number of layers loaded on GPUs, and the quality rating of the response. Additionally, we measured the power consumption of the GPU during model execution. A script was used to monitor GPU power usage (via nvidia-smi) immediately after each token was generated. Once inference concluded, we computed the average power consumption based on these readings. Since we focused on models that could fully fit into GPU memory, we only measured GPU power consumption.
Additionally, the experiments were conducted with a variety of prompts to ensure different output sizes, thus, the data encompass a wide range of scenarios.
Hardware and Software Setup
We used a pretty decent server with the following features:
- CPU: AMD Ryzen Threadripper PRO 7965WX 24-Cores @ 48x 5.362GHz.
- GPU: 2x NVIDIA GeForce RTX 4090.
- RAM: 515276MiB-
- OS: Pop 22.04 jammy.
- Kernel: x86_64 Linux 6.9.3–76060903-generic.
The retail cost of this setup was somewhere around $15,000 USD. We chose such a setup because it is a decent server that, while nowhere near as powerful as dedicated, high-end AI servers with 8 or more GPUs, is still quite functional and representative of what many of our clients might choose. We have found many clients hesitant to invest in high-end servers out of the gate, and this setup is a good compromise between cost and performance.
Speed
Let us first focus on speed. Below, we present several box-whisker plots depicting speed data for several quantizations. The name of each model starts with its quantization level; so for example “Q4” means a 4-bit quantization. Again, a LOWER quantization level rounds more, reducing size and quality but increasing speed.
► Technical Issue 1 (A Reminder of Box-Whisker Plots): Box-whisker plots display the median, the first and third quartiles, as well as the minimum and maximum data points. The whiskers extend to the most extreme points not classified as outliers, while outliers are plotted individually. Outliers are defined as data points that fall outside the range of Q1 − 1.5 × IQR and Q3 + 1.5 × IQR, where Q1 and Q3 represent the first and third quartiles, respectively. The interquartile range (IQR) is calculated as IQR = Q3 − Q1.
llama.cpp
Below are the plots for llama.cpp. Fig. 3 shows the results for all Llama 3.1 models with 70B parameters available in QuantFactory, while Fig. 4 depicts some of the models with 8B parameters available here. 70B models can offload up to 81 layers onto the GPU while 8B models up to 33. For 70B, offloading all layers is not feasible for Q5 quantization and finer. Each quantization type includes the number of layers offloaded onto the GPU in parentheses. As expected, coarser quantization yields the best speed performance. Since row split mode performs similarly, we focus on layer split mode here.
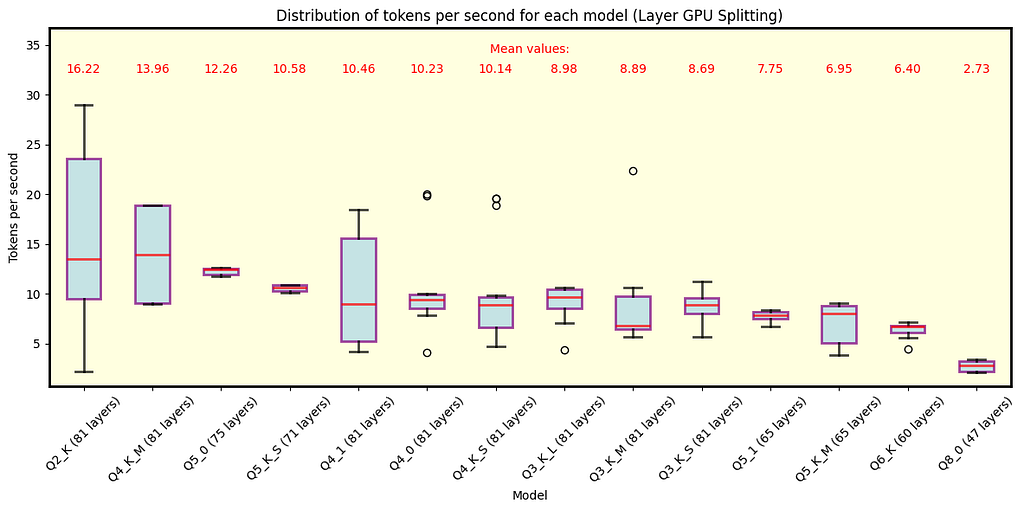
Fig. 3 Llama 3.1 models with 70B parameters running under llama.cpp with split mode layer. As expected, coarser quantization provides the best speed. The number of layers offloaded onto the GPU is shown in parentheses next to each quantization type. Models with Q5 and finer quantizations do not fully fit into VRAM.
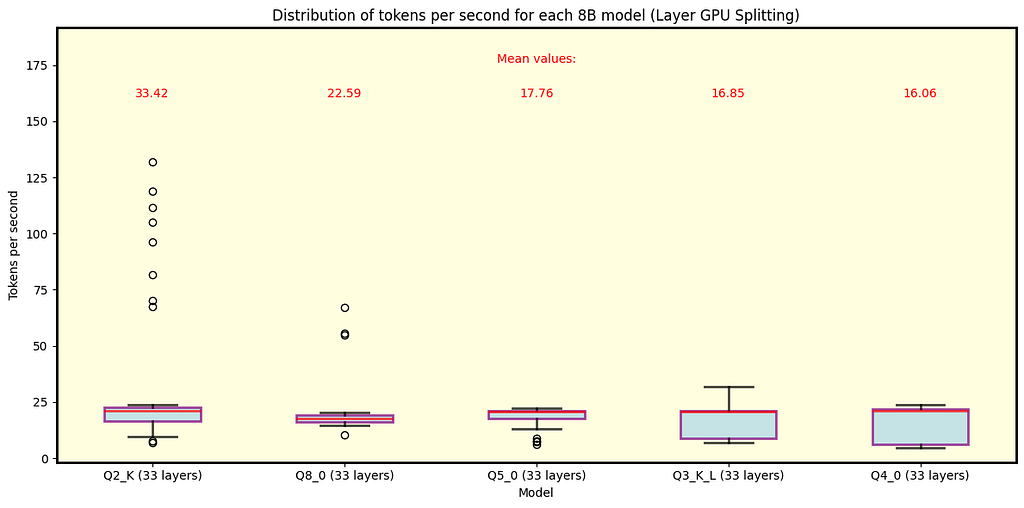
Fig. 4 Llama 3.1 models with 8B parameters running under llama.cpp using split mode layer. In this case, the model fits within the GPU memory for all quantization types, with coarser quantization resulting in the fastest speeds. Note that high speeds are outliers, while the overall trend hovers around 20 tokens per second for Q2_K.
Key Observations
- During inference we observed some high speed events (especially in 8B Q2_K), this is where gathering data and understanding its distribution is crucial, as it turns out that those events are quite rare.
- As expected, coarser quantization types yield the best speed performance. This is because the model size is reduced, allowing for faster execution.
- The results concerning 70B models that do not fully fit into VRAM must be taken with caution, as using the CPU too could cause a bottleneck. Thus, the reported speed may not be the best representation of the model’s performance in those cases.
Ollama
We executed the same analysis for Ollama. Fig. 5 shows the results for the default Llama 3.1 and 3.2 models that Ollama automatically downloads. All of them fit in the GPU memory except for the 405B model.
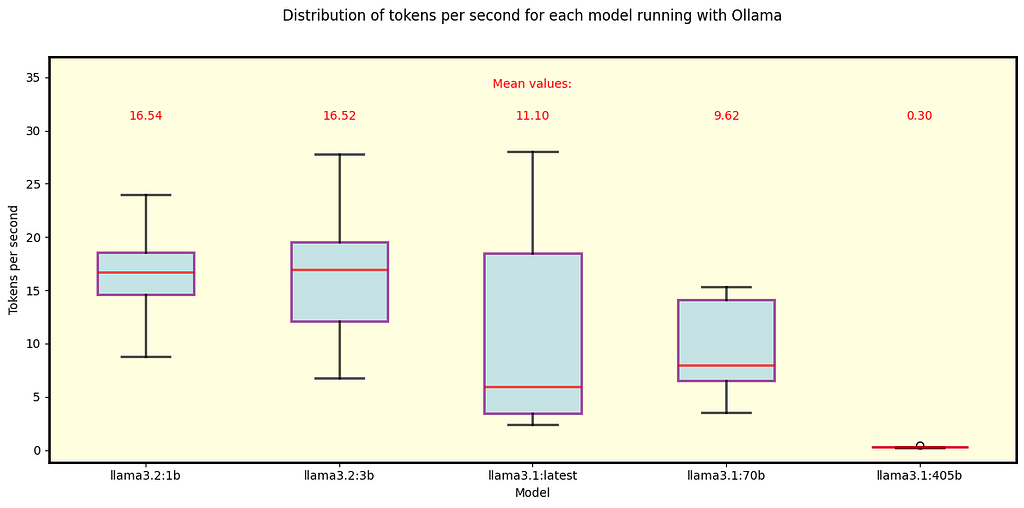
Fig. 5 Llama 3.1 and 3.2 models running under Ollama. These are the default models when using Ollama. All 3.1 models — specifically 405B, 70B, and 8B (labeled as “latest”) — use Q4_0 quantization, while the 3.2 models use Q8_0 (1B) and Q4_K_M (3B).
Key Observations
- We can compare the 70B Q4_0 model across Ollama and llama.cpp, with Ollama exhibiting a slightly slower speed.
- Similarly, the 8B Q4_0 model is slower under Ollama compared to its llama.cpp counterpart, with a more pronounced difference — llama.cpp processes about five more tokens per second on average.
Summary of Analyzed Frameworks
► Before discussing power consumption and rentability, let’s summarize the frameworks we analyzed up to this point.
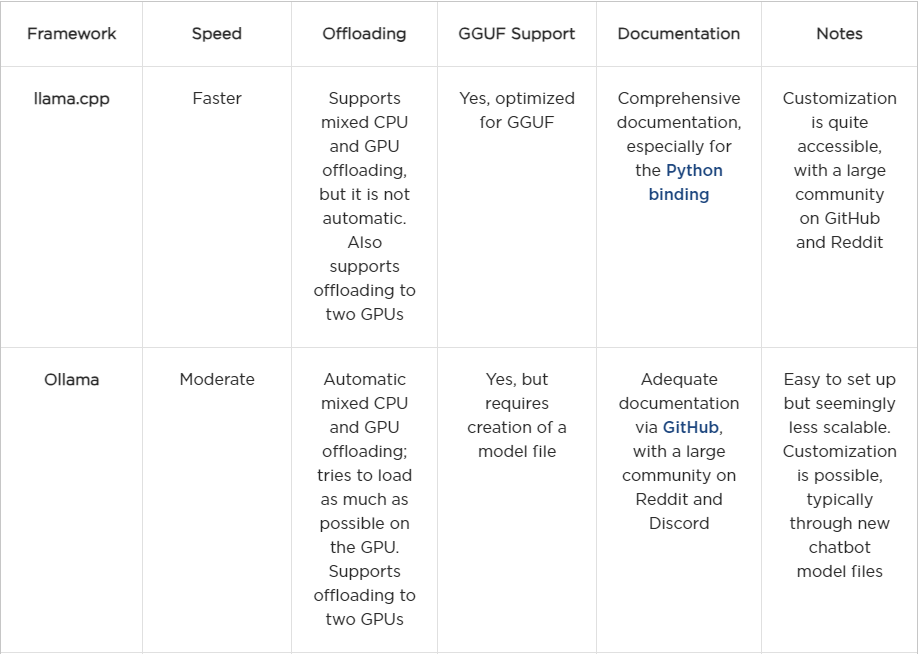
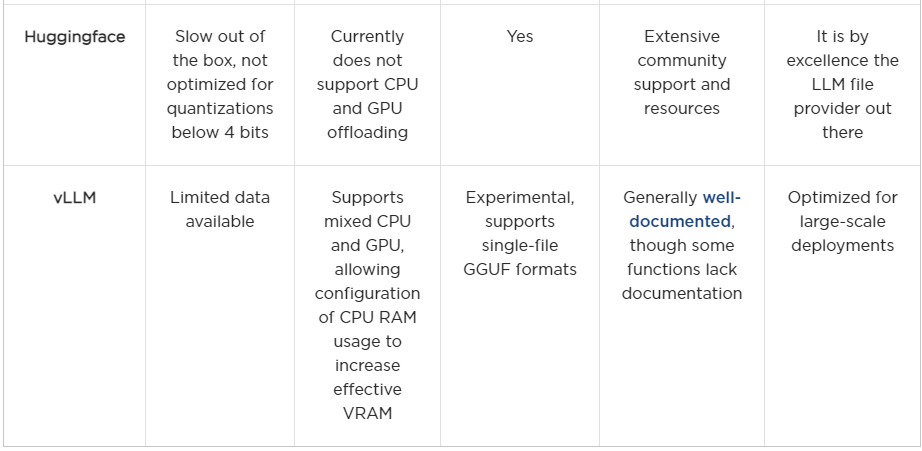
Power Consumption and Rentability
This analysis is particularly relevant to models that fit all layers into GPU memory, as we only measured the power consumption of two RTX 4090 cards. Nonetheless, it is worth noting that the CPU used in these tests has a TDP of 350 W, which provides an estimate of its power draw at maximum load. If the entire model is loaded onto the GPU, the CPU likely maintains a power consumption close to idle levels.
To estimate energy consumption per token, we use the following parameters: tokens per second (NT) and power drawn by both GPUs (P) measured in watts. By calculating P/NT, we obtain the energy consumption per token in watt-seconds. Dividing this by 3600 gives the energy usage per token in Wh, which is more commonly referenced.
llama.cpp
Below are the results for llama.cpp. Fig. 6 illustrates the energy consumption for 70B models, while Fig. 7 focuses on 8B models. These figures present energy consumption data for each quantization type, with average values shown in the legend.
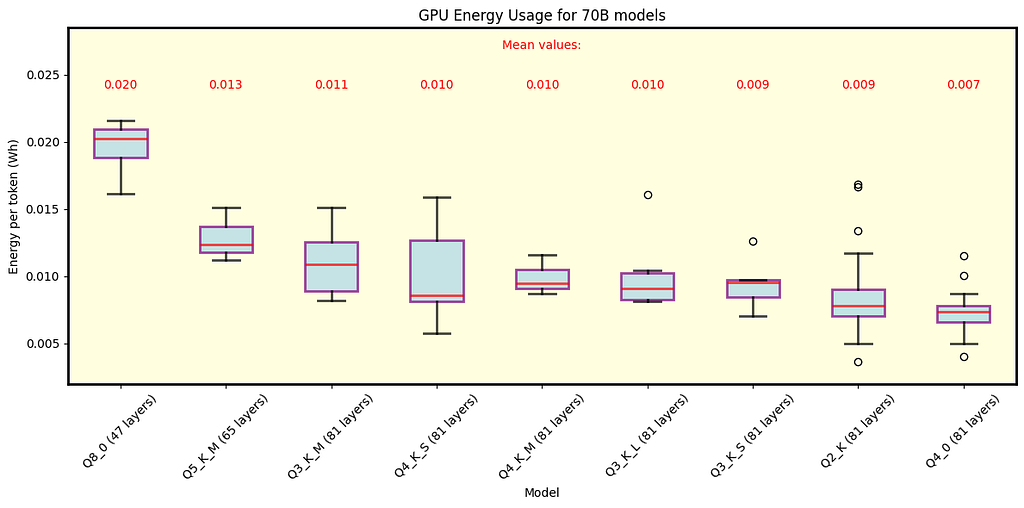
Fig. 6 Energy per token for various quantizations of Llama 3.1 models with 70B parameters under llama.cpp. Both row and layer split modes are shown. Results are relevant only for models that fit all 81 layers in GPU memory.
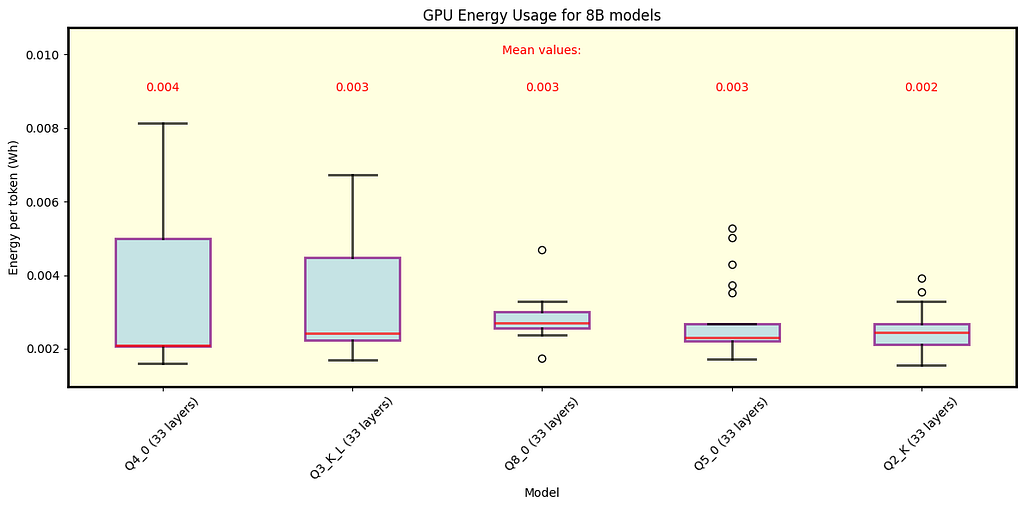
Fig. 7 Energy per token for various quantizations of Llama 3.1 models with 8B parameters under llama.cpp. Both row and layer split modes are shown. All models exhibit similar average consumption.
Ollama
We also analyzed the energy consumption for Ollama. Fig. 8 displays results for Llama 3.1 8B (Q4_0 quantization) and Llama 3.2 1B and 3B (Q8_0 and Q4_K_M quantizations, respectively). Fig. 9 shows separate energy consumption for the 70B and 405B models, both with Q4_0 quantization.
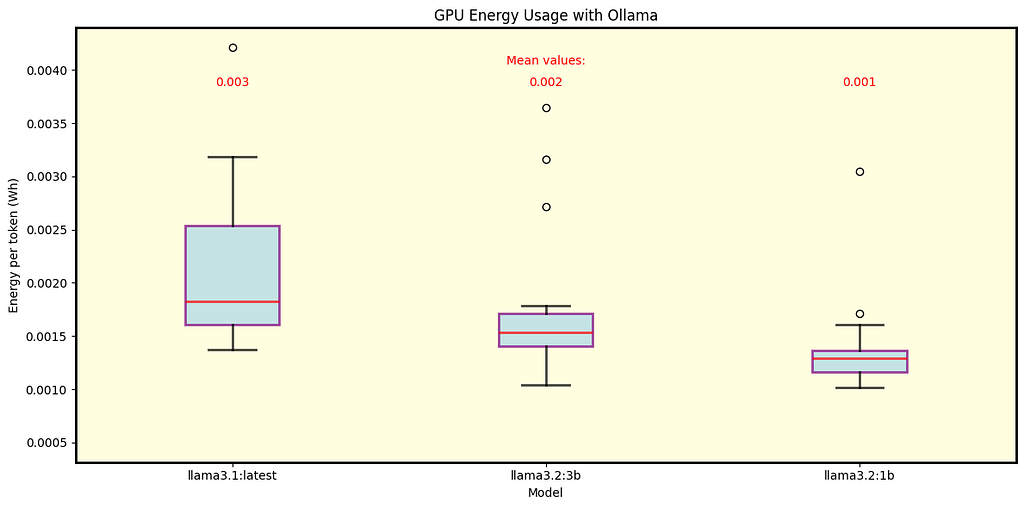
Fig. 8 Energy per token for Llama 3.1 8B (Q4_0 quantization) and Llama 3.2 1B and 3B models (Q8_0 and Q4_K_M quantizations, respectively) under Ollama.
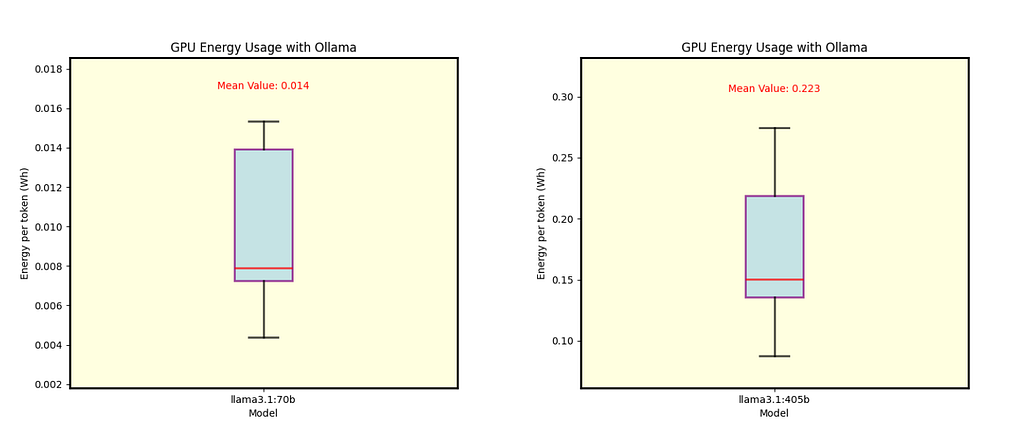
Fig. 9 Energy per token for Llama 3.1 70B (left) and Llama 3.1 405B (right), both using Q4_0 quantization under Ollama.
Summary of Costs
Instead of discussing each model individually, we will focus on those models that are comparable across llama.cpp and Ollama, as well of models with Q2_K quantization under llama.cpp, since it is the coarsest quantization explored here. To give a good idea of the costs, we show in the table below estimations of the energy consumption per one million generated tokens (1M) and the cost in USD. The cost is calculated based on the average electricity price in Texas, which is $0.14 per kWh according to this source. For a reference, the current pricing of GPT-4o is at least of $5 USD per 1M tokens and $0.3 USD per 1M tokens for GPT-o mini.
llama.cpp
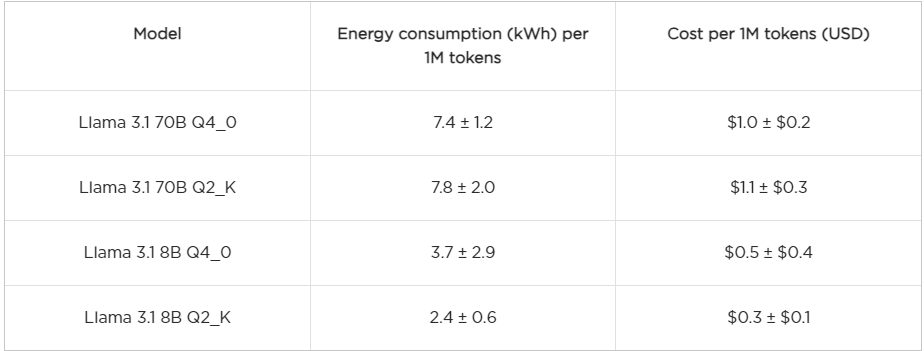
Ollama

Key Observations
- Using Llama 3.1 70B models with Q4_0, there is not much difference in the energy consumption between llama.cpp and Ollama.
- For the 8B model llama.cpp spends more energy than Ollama.
- Consider that the costs depicted here could be seen as a lower bound of the “bare costs” of running the models. Other costs, such as operation, maintenance, equipment costs and profit, are not included in this analysis.
- The estimations suggest that operating LLMs on private servers can be cost-effective compared to cloud services. In particular, comparing Llama 8B with GPT-45o mini and Llama 70B with GPT-4o models seem to be a potential good deal under the right circumstances.
► Technical Issue 2 (Cost Estimation): For most models, the estimation of energy consumption per 1M tokens (and its variability) is given by the “median ± IQR” prescription, where IQR stands for interquartile range. Only for the Llama 3.1 8B Q4_0 model do we use the “mean ± STD” approach, with STD representing standard deviation. These choices are not arbitrary; all models except for Llama 3.1 8B Q4_0 exhibit outliers, making the median and IQR more robust estimators in those cases. Additionally, these choices help prevent negative values for costs. In most instances, when both approaches yield the same central tendency, they provide very similar results.
Final Word

The analysis of speed and power consumption across different models and tools is only part of the broader picture. We observed that lightweight or heavily quantized models often struggled with reliability; hallucinations became more frequent as chat histories grew or tasks turned repetitive. This isn’t unexpected — smaller models don’t capture the extensive complexity of larger models. To counter these limitations, settings like repetition penalties and temperature adjustments can improve outputs. On the other hand, larger models like the 70B consistently showed strong performance with minimal hallucinations. However, since even the biggest models aren’t entirely free from inaccuracies, responsible and trustworthy use often involves integrating these models with additional tools, such as LangChain and vector databases. Although we didn’t explore specific task performance here, these integrations are key for minimizing hallucinations and enhancing model reliability.
In conclusion, running LLMs on private servers can provide a competitive alternative to LLMs as a service, with cost advantages and opportunities for customization. Both private and service-based options have their merits, and at Austin Ai, we specialize in implementing solutions that suit your needs, whether that means leveraging private servers, cloud services, or a hybrid approach.
Running Large Language Models Privately was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Running Large Language Models Privately
Go Here to Read this Fast! Running Large Language Models Privately