

Yes, music and graphs do mix!
In this post, we take a look at one of my latest papers and open-source software: the GraphMuse Python library.
But before we dive in, let me introduce you to some basics of symbolic music processing.
And the story goes…
Symbolic music processing mainly refers to extracting information from musical scores. The term symbolic refers to the symbols present in any form of musical score or notation. A musical score can contain a variety of elements other than notes. Such elements may include time signature, key signature, articulation markings, dynamic markings, and many others. Music scores can exist in many formats such as MIDI, MusicXML, MEI, Kern, ABC, and others.
In recent years, Graph Neural Networks (GNNs) have become increasingly popular and have seen success in many domains from biology networks to recommender systems to music analysis. In the music analysis field, GNNs have been used to solve tasks such as harmonic analysis, phrase segmentation, and voice separation.
The idea is simple: every note in a score is a vertex in the graph and edges are defined by the temporal relations between the notes as shown in the figure below.
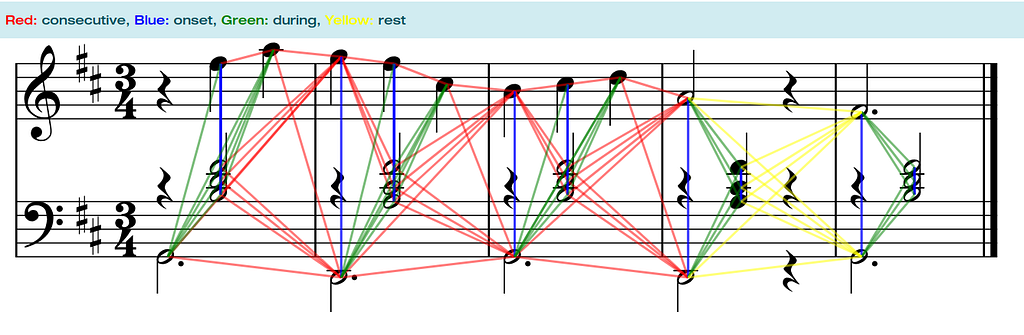
The edges are separated into 4 categories:
- Notes that start at the same time are connected by the “onset” edge (blue)
- Notes that start of at the end of some other note are connected by the “consecutive” edge (red)
- Notes that start in between the start and end of another note are connected the “during” edge (green)
- Finally, whenever there is silence all last note endings are connected to the first upcoming notes by the “silent” edge (yellow)
This minimal modeling of the graph guarantees that a score will be continuously connected from start to finish without any disconnected subgraphs.
What is GraphMuse
GraphMuse is a Python Library for training and applying deep graph models for music analysis on musical scores.
GraphMuse contains loaders, models, and utils for symbolic music processing with GNNs. It is built on top of PyTorch and PyTorch Geometric for more flexibility and interoperability.
PyTorch is an open-source machine learning library that enables efficient deep learning model building and supports GPU acceleration. PyTorch Geometric is a library built upon PyTorch to easily write and train Graph Neural Networks (GNNs) for a wide range of applications.
Finally, GraphMuse provides functionalities to transform musical scores into graphs. Graph creation is implemented in C code with Python bindings to speedup the graph building, up to x300 faster than the previous numpy-based implementation.
The Scientific Foundations
Graphs have been frequently used to analyze and represent music. To cite a few examples, the Tonnetz, Schenkerian analysis, and treelike form analysis are some notable mentions. The advantage of graphs is that they can capture both the hierarchical and the sequential nature of music with the same representation simply by the design of the edges.
Graph-based symbolic music processing using GNNs came about in 2021 with a performance generation model from the score. Since then many graph models have been introduced with some being the state-of-the-art for music analysis tasks up to the date of this post.
So, now that I argued for the necessity of graphs let’s face the complexities of designing and training graph models for symbolic music.
The main complexity of graphs and of course, music is that musical pieces are not always of the same length and the graphs that are created from them are not the same size either. Their size might vary considerably: for example, a Bach chorale might have only 200 notes whereas a Beethoven sonata can have well over 5000. In our graphs, the number of notes corresponds directly to the number of vertices in each score graph.
Training efficiently and fast on score graphs is not a trivial task and would require a sampling method that can maximize the computational resources in terms of both memory and time without deteriorating the performance of the model and sometimes even improving it.
In the training process, sampling involves combining graphs from different scores to create a new graph, often referred to as a “batch” in computer science. Each batch is then fed into the GNN model, where a loss is calculated. This loss is used to backpropagate and update the model’s parameters. This single iteration is called a training step. To optimize the model, this process is repeated many times until the training converges and ideally the model performs optimally.
This all sounds complicated but do not despair because GraphMuse can handle this part for you!!
The Inner Workings of GraphMuse

The general graph processing/training pipeline for symbolic music scores within GraphMuse involves the following steps:
- Preprocess the database of scores to generate input graphs, GraphMuse can do this for you fast and easy;
- Sample the input graphs to create memory-efficient batches, again GraphMuse got your back;
- Form a batch as a new graph with nodes and edges from various sampled input graphs; For each graph, a set of nodes is selected which we call target nodes. The neighbors of the target nodes can also be fetched by demand in a process called node-wise sampling.
- Update the target nodes’ representations through graph convolution to create node embeddings. GraphMuse provides some models that you can use, otherwise PyTorch Geometric can also be your friend;
- Use these embeddings for task-specific applications. This part is on you but I am sure you can make it!
Note that target nodes may include all or a subset of batch nodes depending on the sampling strategy.
Now that the process is graphically explained let’s take a closer look at how GraphMuse handles sampling notes from each score.

Sampling process per score.
- A randomly selected note (in yellow) is first sampled.
- The boundaries of the target notes are then computed with a budget of 15 notes in this example (pink and yellow notes).
- Then the k-hop neighbors are fetched for the targets (light blue for 1-hop and darker blue for 2-hop). The k-hop neighbors are computed with respect to the input graph (depicted with colored edges connecting noteheads in the figure above).
- We can also extend the sampling process for the beat and measure elements. Note that the k-hop neighbors need not be strictly related to a time window.
To maximize the computational resources (i.e. memory) the above process is repeated for many scores at once to create one batch. Using this process, GraphMuse asserts that every sampled segment is going to have the same size of target notes. Every sampled segment can be combined to a new graph which will be of size at most #_scores x #_target_notes. This new graph constitutes the batch for the current training step.
Hands-on with GraphMuse
For the hands-on part let’s try to use GraphMuse and use a model for pitch spelling. The pitch spelling task is about inferring the note name and accidentals when they are absent from the score. An example of this application is when we have a quantized midi and want to create a score such as the example in the figure below:

Before installing GraphMuse you will need to install PyTorch and PyTorch Geometric. Check out the appropriate version for your system here and here.
After this step, to install GraphMuse open your preferred terminal and type:
pip install graphmuse
After installation, let’s read a MIDI file from a URL and create the score graph with GraphMuse.
import graphmuse as gm
midi_url_raw = "https://github.com/CPJKU/partitura/raw/refs/heads/main/tests/data/midi/bach_midi_score.mid"
graph = gm.load_midi_to_graph(midi_url_raw)
The underlying process reads the file with Partitura and then feeds it through GraphMuse.
To train our model to handle Pitch Spelling, we first need a dataset of musical scores where the pitch spelling has already been annotated. For this, we’ll be using the ASAP Dataset (licenced under CC BY-NC-SA 4.0), which will serve as the foundation for our model’s learning. To get the ASAP Dataset you can download it using git or directly from github:
git clone https://github.com/cpjku/asap-dataset.git
The ASAP dataset includes scores and performances of various classical piano pieces. For our use-case we will use only the scores which end in .musicxml.
As we load this dataset, we’ll need two essential utilities: one to encode pitch spelling and another to handle key signature information, both of which will be converted into numerical labels. Fortunately, these utilities are available within the pre-built pitch spelling model in GraphMuse. Let’s begin by importing all the necessary packages and loading the first score to get started.
import graphmuse as gm
import partitura as pt
import os
import torch
import numpy as np
# Directory containing the dataset, change this to the location of your dataset
dataset_dir = "/your/path/to/the/asap-dataset"
# Find all the score files in the dataset (they are all named 'xml_score.musicxml')
score_files = [os.path.join(dp, f) for dp, dn, filenames in os.walk(dataset_dir) for f in filenames if f == 'xml_score.musicxml']
# Use the first 30 scores, change this number to use more or less scores
score_files = score_files[:30]
# probe the first score file
score = pt.load_score(score_files[0])
# Extract features and note array
features, f_names = gm.utils.get_score_features(score)
na = score.note_array(include_pitch_spelling=True, include_key_signature=True)
# Create a graph from the score features
graph = gm.create_score_graph(features, score.note_array())
# Get input feature size and metadata from the first graph
in_feats = graph["note"].x.shape[1]
metadata = graph.metadata()
# Create a model for pitch spelling prediction
model = gm.nn.models.PitchSpellingGNN(
in_feats=in_feats, n_hidden=128, out_feats_enc=64, n_layers=2, metadata=metadata, add_seq=True
)
# Create encoders for pitch and key signature labels
pe = model.pitch_label_encoder
ke = model.key_label_encoder
Next, we’ll load the remaining score files from the dataset to continue preparing our data for model training.
# Initialize lists to store graphs and encoders
graphs = [graph]
# Process each score file
for score_file in score_files[1:]:
# Load the score
score = pt.load_score(score_file)
# Extract features and note array
features, f_names = gm.utils.get_score_features(score)
na = score.note_array(include_pitch_spelling=True, include_key_signature=True)
# Encode pitch and key signature labels
labels_pitch = pe.encode(na)
labels_key = ke.encode(na)
# Create a graph from the score features
graph = gm.create_score_graph(features, score.note_array())
# Add encoded labels to the graph
graph["note"].y_pitch = torch.from_numpy(labels_pitch).long()
graph["note"].y_key = torch.from_numpy(labels_key).long()
# Append the graph to the list
graphs.append(graph)
Once the graph structures are ready, we can move on to creating the data loader, which is conveniently provided by GraphMuse. At this stage, we’ll also define standard training components like the loss function and optimizer to guide the learning process.
# Create a DataLoader to sample subgraphs from the graphs
loader = gm.loader.MuseNeighborLoader(graphs, subgraph_size=100, batch_size=16, num_neighbors=[3, 3])
# Define loss functions for pitch and key prediction
loss_pitch = torch.nn.CrossEntropyLoss()
loss_key = torch.nn.CrossEntropyLoss()
# Define the optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Let me comment a bit more on the gm.loader.MuseNeighborLoader.
This is the core dataloader in GraphMuse and it contains the sampling that was explained in the previous section. subgraph_size refers to the number of target nodes per input graph, batch_size is the number of sampled graphs per batch, and finally, num_neighbors refers to the number of neighbors sampled per sampled node in each layer.
With everything in place, we are finally ready to train the model. So, let’s dive in and start the training process!
# Train the model for 5 epochs
for epoch in range(5):
loss = 0
i = 0
for batch in loader:
# Zero the gradients
optimizer.zero_grad()
# Get neighbor masks for nodes and edges for more efficient training
neighbor_mask_node = {k: batch[k].neighbor_mask for k in batch.node_types}
neighbor_mask_edge = {k: batch[k].neighbor_mask for k in batch.edge_types}
# Forward pass through the model
pred_pitch, pred_key = model(
batch.x_dict, batch.edge_index_dict, neighbor_mask_node, neighbor_mask_edge,
batch["note"].batch[batch["note"].neighbor_mask == 0]
)
# Compute loss for pitch and key prediction
loss_pitch_val = loss_pitch(pred_pitch, batch["note"].y_pitch[batch["note"].neighbor_mask == 0])
loss_key_val = loss_key(pred_key, batch["note"].y_key[batch["note"].neighbor_mask == 0])
# Total loss
loss_val = loss_pitch_val + loss_key_val
# Backward pass and optimization
loss_val.backward()
optimizer.step()
# Accumulate loss
loss += loss_val.item()
i += 1
# Print average loss for the epoch
print(f"Epoch {epoch} Loss {loss / i}")
Hopefully, we’ll soon see the loss function decreasing, a positive sign that our model is effectively learning how to perform pitch spelling. Fingers crossed!

Why GraphMuse?
GraphMuse is a framework that tries to make the training and deployment of graph models for symbolic music processing easier.
For those who want to retrain, deploy, or finetune previous state-of-the-art models for symbolic music analysis, GraphMuse contains some of the necessary components to re-build and re-train your model faster and more efficiently.
GraphMuse retains its flexibility through its simplicity, for those who want to prototype, innovate, and design new models. It aims to provide a simple set of utilities rather than including complex chained pipelines that can block the innovation process.
For those who want to learn, visualize, and get hands-on experience, GraphMuse is good to get you started. It offers an easy introduction to basic functions and pipelines with a few lines of code. GraphMuse is also linked with MusGViz, which allows graphs and scores to be easily visualized together.
Limitations and Future Plans
We cannot talk about the positive aspects of any project without discussing the negative ones as well.
GraphMuse is a newborn project and in its current state, it is pretty simple. It is focused on covering the essential parts of graph learning rather than being a holistic framework that covers all possibilities. Therefore it still focuses a lot on user-based implementation on many parts of the aforementioned pipeline.
Like every open-source project in development GraphMuse needs help to grow. So please, if you find bugs or want more features do not hesitate to report, request, or contribute to the GraphMuse GitHub project.
Last but not least, GraphMuse uses C libraries such as torch-sparse and torch-scatter and has its own C-bindings to accelerate graph creation therefore installation is not always straightforward. The windows installation is more challenging judging from our user testing and user interaction reports, although not impossible (I am running it on Windows myself).
Future plans include:
- Making installation easier;
- Add more support for models and dataloaders for precise tasks;
- Grow the open-source community around GraphMuse to keep graph coding for music growing.
Conclusion
GraphMuse is a Python library that makes working with music graphs a little bit easier. It focuses on the training aspect of graph-based models for music but aims to retain flexibility when research-based projects require it.
If you would like to support the development and future growth of GraphMuse please star the repo here .
Happy graph coding !!!
GitHub – manoskary/graphmuse: A Graph Deep Learning Library for Music.
[all images are by the author]
GraphMuse: A Python Library for Symbolic Music Graph Processing was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
GraphMuse: A Python Library for Symbolic Music Graph Processing
Go Here to Read this Fast! GraphMuse: A Python Library for Symbolic Music Graph Processing