Assessing plausibility and usefulness of data we generated from real data
Synthetic data serves many purposes, and has been gathering attention for a while, partly due to the convincing capabilities of LLMs. But what is «good» synthetic data, and how can we know we managed to generate it ?

What is synthetic data ?
Synthetic data is data that has been generated with the intent to look like real data, at least on some aspects (schema at the very least, statistical distributions, …). It is usually generated randomly, using a wide range of models : random sampling, noise addition, GAN, diffusion models, variational autoencoders, LLM, …
It is used for many purposes, for instance :
- training and education (eg, discovering a new database or teaching a course),
- data augmentation (ie, creating new samples to train a model),
- sharing data while protecting privacy (especially useful from an open science point of view),
- conducting research while protecting privacy.
It is particularily used in software testing, and in sensitive domains like healthcare technology : having access to data that behaves like real data without jeopardizing patients privacy is a dream come true.
Synthetic data quality principles
Individual plausibility
For a sample to be useful it must, in some way, look like real data. The ultimate goal is that generated samples must be indistinguishable from real samples : generate hyper-realistic faces, sentences, medical records, … Obviously, the more complex the source data, the harder it is to generate «good» synthetic data.
Usefulness
In many cases, especially data augmentation, we need more than one realistic sample, we need a whole dataset. And it is not the same to generate a single sample and a whole dataset : the problem is very well known, under the name of mode collapse, which is especially frequent when training a generative adversarial network (GAN). Essentially, the generator (more generally, the model that generates synthetic data) could learn to generate a single type of sample and totally miss out on the rest of the sample space, leading to a synthetic dataset that is not as useful as the original dataset.
For instance, if we train a model to generate animal pictures, and it finds a very efficient way to generate cat pictures, it could stop generating anything else than cat pictures (in particular, no dog pictures). Cat pictures would then be the “mode” of the generated distribution.
This type of behaviour is harmful if our initial goal is to augment our data, or create a dataset for training. What we need is a dataset that is realistic in itself, which in absolute means that any statistic derived from this dataset should be close enough to the same statistic on real data. Statistically speaking, this means that univariate and multivariate distributions should be the same (or at least “close enough”).
Privacy
We will not dive too deep on this topic, which would deserve an article in itself. To keep it short : according to our initial goal, we may have to share data (more or less publicly), which means, if it is personal data, that it should be protected. For instance, we need to make sure we cannot retrieve any information on any given individual of the original dataset using the synthetic dataset. In particular, that means being cautious about outliers, or checking that no original sample was generated by the generator.
One way to consider the privacy issue is to use the differential privacy framework.
Evaluation in practice

Let’s start by loading data and generating a synthetic dataset from this data. We’ll start with the famous `iris` dataset. To generate it synthetic counterpart, we’ll use the Synthetic Data Vault package.
pip install sdv
from sklearn.datasets import load_iris
from sdv.single_table import GaussianCopulaSynthesizer
from sdv.metadata.metadata import Metadata
data = load_iris(return_X_y=False, as_frame=True)
real_data = data["data"]
# metadata of the `iris` dataset
metadata = Metadata().load_from_dict({
"tables": {
"iris": {
"columns": {
"sepal length (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"sepal width (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"petal length (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
},
"petal width (cm)": {
"sdtype": "numerical",
"computer_representation": "Float"
}
},
"primary_key": None
}
},
"relationships": [],
"METADATA_SPEC_VERSION": "V1"
})
# train the synthesizer
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(data=real_data)
# generate samples - in this case,
# synthetic_data has the same shape as real_data
synthetic_data = synthesizer.sample(num_rows=150)
Sample level
Now, we want to test whether it is possible to tell if a single sample is synthetic or not.
With this formulation, we easily see it is fundamentally a binary classification problem (synthetic vs original). Hence, we can train any model to classify original data from synthetic data : if this model achieves a good accuracy (which here means significantly above 0.5), the synthetic samples are not realistic enough. We aim for 0.5 accuracy (if the test set contains half original samples and half synthetic samples), which would mean that the classifier is making random guesses.
As in any classification problem, we should not limit ourself to weak models and give a fair amount of effort in hyperparameters selection and model training.
Now for the code :
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
def classification_evaluation(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame
) -> float:
X = pd.concat((real_data, synthetic_data))
y = np.concatenate(
(
np.zeros(real_data.shape[0]),
np.ones(synthetic_data.shape[0])
)
)
Xtrain, Xtest, ytrain, ytest = train_test_split(
X,
y,
test_size=0.2,
stratify=y
)
clf = RandomForestClassifier()
clf.fit(Xtrain, ytrain)
score = accuracy_score(clf.predict(Xtest), ytest)
return score
classification_evaluation(real_data, synthetic_data)
>>> 0.9
In this case, it appears the synthesizer was not able to fool our classifier : the synthetic data is not realistic enough.
Dataset level
If our samples were realistic enough to fool a reasonably powerful classifier, we would need to evaluate our dataset as a whole. This time, it cannot be translated into a classification problem, and we need to use several indicators.
Statistical distributions
The most obvious tests are statistical tests : are the univariate distributions in the original dataset the same as in the synthetic dataset ? Are the correlations the same ?
Ideally, we would like to test N-variate distributions for any N, which can be particularily expensive for a high number of variables. However, even univariate distributions make it possible to see if our dataset is subject to mode collapse.
Now for the code :
import pandas as pd
from scipy.stats import ks_2samp
def univariate_distributions_tests(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame
) -> None:
for col in real_data.columns:
if real_data[col].dtype.kind in "biufc":
stat, p_value = ks_2samp(real_data[col], synthetic_data[col])
print(f"Column: {col}")
print(f"P-value: {p_value:.4f}")
print("Significantly different" if p_value < 0.05 else "Not significantly different")
print("---")
univariate_distributions_tests(real_data, synthetic_data)
>>> Column: sepal length (cm)
P-value: 0.9511
Not significantly different
---
Column: sepal width (cm)
P-value: 0.0000
Significantly different
---
Column: petal length (cm)
P-value: 0.0000
Significantly different
---
Column: petal width (cm)
P-value: 0.1804
Not significantly different
---
In our case, out of the 4 variables, only 2 have similar distributions in the real dataset and in the synthetic dataset. This shows that our synthesizer fails to reproduce basic properties of this dataset.
Visual inspection
Though no mathematically proof, a visual comparison of the datasets can be useful.
The first method is to plot bivariate distributions (or correlation plots).
We can also represent all the dataset dimensions at once: for instance, given a tabular dataset and its synthetic equivalent, we can plot both datasets using a dimension reduction technique, such as t-SNE, PCA or UMAP. With a perfect synthetizer, the scatter plots should look the same.
Now for the code :
pip install umap-learn
import pandas as pd
import seaborn as sns
import umap
import matplotlib.pyplot as plt
def plot(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame,
kind: str = "pairplot"
):
assert kind in ["umap", "pairplot"]
real_data["label"] = "real"
synthetic_data["label"] = "synthetic"
X = pd.concat((real_data, synthetic_data))
if kind == "pairplot":
sns.pairplot(X, hue="label")
elif kind == "umap":
reducer = umap.UMAP()
embedding = reducer.fit_transform(X.drop("label", axis=1))
plt.scatter(
embedding[:, 0],
embedding[:, 1],
c=[sns.color_palette()[x] for x in X["label"].map({"real":0, "synthetic":1})],
s=30,
edgecolors="white"
)
plt.gca().set_aspect('equal', 'datalim')
sns.despine(top=True, right=True, left=False, bottom=False)
plot(real_data, synthetic_data, kind="pairplot")

We already see on these plots that the bivariate distributions are not identical between real data and synthetic data, which is one more hint that the synthetization process failed to reproduce high-order relationship between data dimensions.
Now let’s take a look at a representation of the four dimensions at once :
plot(real_data, synthetic_data, kind="umap")
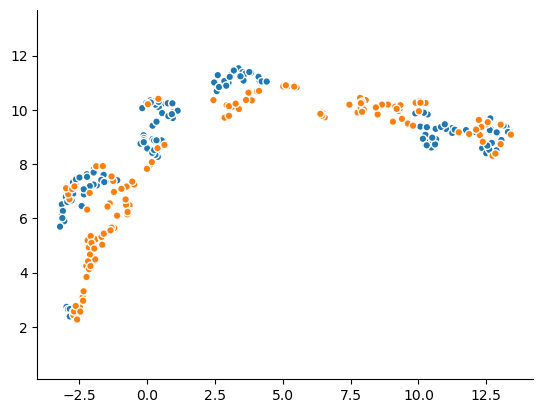
In this image is also clear that the two datasets are distinct from one another.
Information
A synthetic dataset should be as useful as the original dataset. Especially, it should be equivalently useful for prediction tasks, meaning it should capture complex relationships between features. Hence a comparison : TSTR vs TRTR, which mean “Train on Synthetic Test on Real” vs “Train on Real Test on Real”. What does it mean in practice ?
For a given dataset, we take a given task, like predicting the next token or the next event, or predicting a column given the others. For this given task, we train a first model on the synthetic dataset, and a second model on the original dataset. We then evaluate these two models on a common test set, which is an extract of the original dataset. Our synthetic dataset is considered useful if the performance of the first model is close to the performance of the second model, whatever the performance. It would mean that it is possible to learn the same patterns in the synthetic dataset as in the original dataset, which is ultimately what we want (especially in the case of data augmentation).
Now for the code :
import pandas as pd
from typing import Tuple
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
def tstr(
real_data: pd.DataFrame,
synthetic_data: pd.DataFrame,
target: str = None
) -> Tuple[float]:
# if no target is specified, use the last column of the dataset
if target is None:
target = real_data.columns[-1]
X_real_train, X_real_test, y_real_train, y_real_test = train_test_split(
real_data.drop(target, axis=1),
real_data[target],
test_size=0.2
)
X_synthetic, y_synthetic = synthetic_data.drop(target, axis=1), synthetic_data[target]
# create regressors (could have been classifiers)
reg_real = RandomForestRegressor()
reg_synthetic = RandomForestRegressor()
# train the models
reg_real.fit(X_real_train, y_real_train)
reg_synthetic.fit(X_synthetic, y_synthetic)
# evaluate
trtr_score = reg_real.score(X_real_test, y_real_test)
tstr_score = reg_synthetic.score(X_real_test, y_real_test)
return trtr_score, tstr_score
tstr(real_data, synthetic_data)
>>> (0.918261846477529, 0.5644428690930647)
It appears clearly that a certain relationship was learnt by the “real” regressor, whereas the “synthetic” regressor failed to learn this relationship. This hints that the relationship was not faithfully reproduced in the synthetic dataset.
Conclusion
Synthetic data quality evaluation does not rely on a single indicator, and one should combine metrics to get the whole idea. This article displays some indicators that can easily be built . I hope that this article gave you some useful hints on how to do it best in your use case !
Feel free to share and comment ✨
Evaluating synthetic data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Evaluating synthetic data