Supercharge Your LLM Apps Using DSPy and Langfuse
Build Production Grade LLM Apps with Ease

The Rise of LLMs
Large Language Models (LLMs) have emerged as a transformative force, revolutionizing how we interact with and process information. These powerful AI models, capable of understanding and generating human-like text, have found applications in a wide array of fields, from chatbots and virtual assistants to content creation and data analysis.
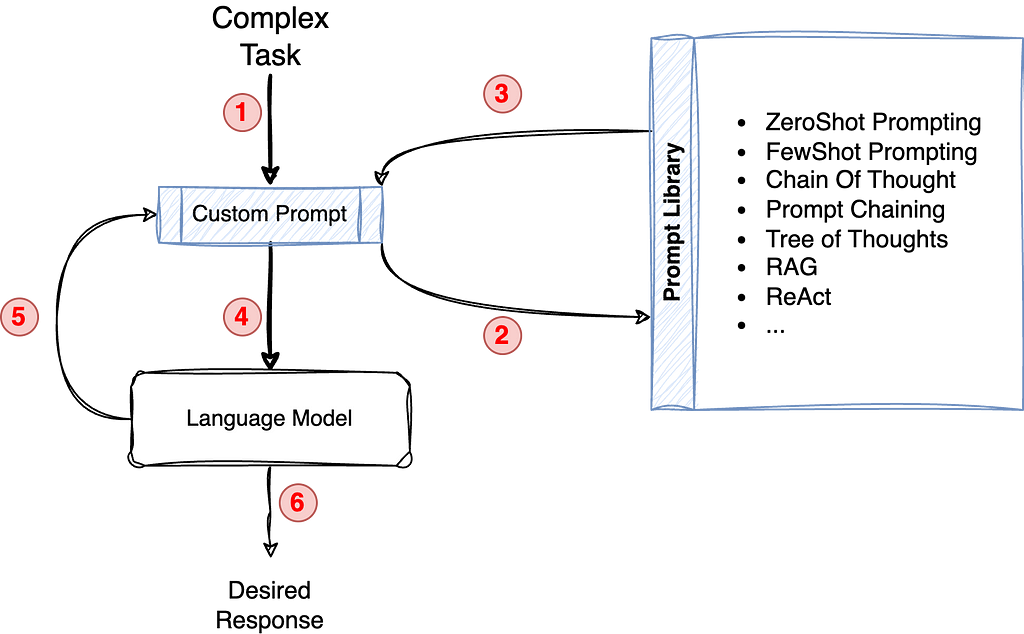
However, building and maintaining effective LLM-powered applications is not without its challenges. Prompt engineering, the art of crafting precise instructions for LLMs, can be a time-consuming and iterative process. Debugging and troubleshooting LLM behavior can also be complex, given the inherent “black box” nature of these models. Additionally, gaining insights into the performance and cost implications of LLM applications is crucial for optimization and scalability (key components for any production grade setup).
The LLM Ecosystem
The ecosystem for LLMs is still in its nascent stages. To address some of these challenges, a number of innovative tools and frameworks are being developed. DSPy from Stanford University is one such unique take towards formalizing LLM-based app development. Langfuse on the other hand has emerged as an offering to streamline and operationalize aspects of LLM app maintenance. To put it in brief:
- DSPY provides a modular and composable framework for building LLM applications, abstracting away the complexities of prompt engineering and enabling developers to focus on the core logic of their applications.
- Langfuse offers a comprehensive observability platform for LLM apps, providing deep insights into model performance, cost, and user interactions.
By combining DSPy and Langfuse, developers can unlock the full potential of LLMs, building robust, scalable, and insightful applications that deliver exceptional user experiences.
Unlocking LLM Potential with DSPy
Language Models are extremely complex machines with capabilities to retrieve and reformulate information from an extremely large latent space. To guide this search and achieve desired responses we heavily rely on complex, long and brittle prompts which (at times) are very specific to certain LLMs.
Being an open area of research, teams are working from different perspectives to abstract and enable rapid development of LLM-enabled systems. DSPy is one such framework for algorithmically optimizing LLM prompts and weights.
Ok, You Got Me Intrigued, Tell Me More?
The DSPy framework takes inspiration from deep learning frameworks such as PyTorch.
For instance, to build a deep neural network using PyTorch we simply use standard layers such as convolution, dropout, linear and attach them to optimizers like Adam and train without worrying about implementing these from scratch every time.
Similarly, DSPy provides a a set of standard general purpose modules (such as ChainOfThought,Predict), optimizers (such as BootstrapFewShotWithRandomSearch) and helps us build systems by composing these components as layers into a Program without explicitly dealing with prompts! Neat isn’t it?
The DSPy Building Blocks & Workflow
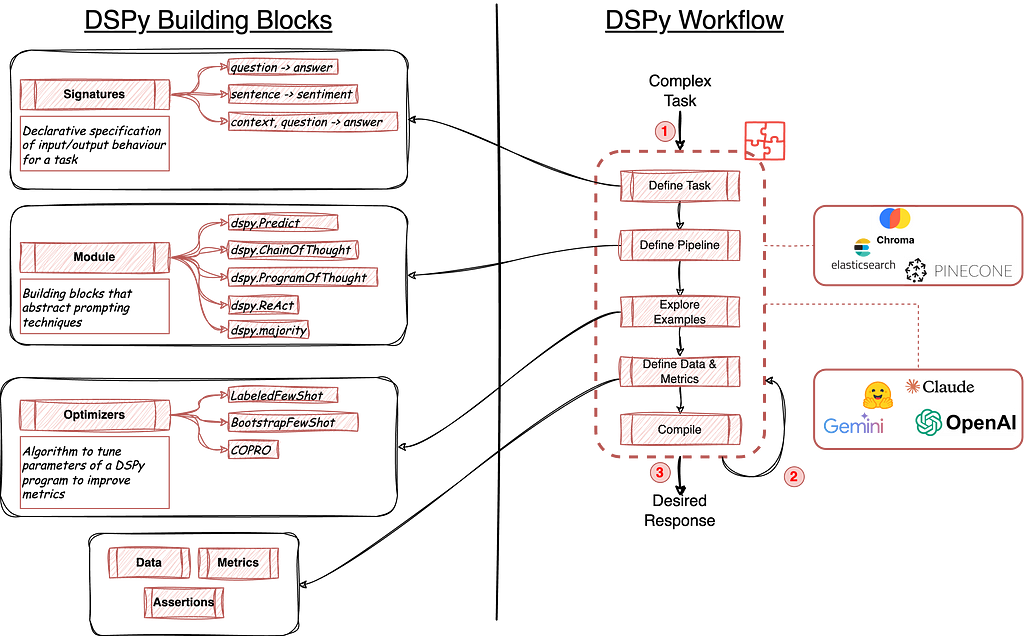
As illustrated in figure 1, DSPy is a pytorch-like/lego-like framework for building LLM-based apps. Out of the box, it comes with:
- Signatures: These are specifications to define input and output behaviour of a DSPy program. These can be defined using short-hand notation (like “question -> answer” where the framework automatically understands question is the input while answer is the output) or using declarative specification using python classes (more on this in later sections)
- Modules: These are layers of predefined components for powerful concepts like Chain of Thought, ReAct or even the simple text completion (Predict). These modules abstract underlying brittle prompts while still providing extensibility through custom components.
- Optimizers: These are unique to DSPy framework and draw inspiration from PyTorch itself. These optimizers make use of annotated datasets and evaluation metrics to help tune/optimize our LLM-powered DSPy programs.
- Data, Metrics, Assertions and Trackers are some of the other components of this framework which act as glue and work behind the scenes to enrich this overall framework.
To build an app/program using DSPy, we go through a modular yet step by step approach (as shown in figure 1 (right)). We first define our task to help us clearly define our program’s signature (input and output specifications). This is followed by building a pipeline program which makes use of one or more abstracted prompt modules, language model module as well as retrieval model modules. One we have all of this in place, we then proceed to have some examples along with required metrics to evaluate our setup which are used by optimizers and assertion components to compile a powerful app.
Gaining LLM Insights with Langfuse
Langfuse is an LLM Engineering platform designed to empower developers in building, managing, and optimizing LLM-powered applications. While it offers both managed and self-hosting solutions, we’ll focus on the self-hosting option in this post, providing you with complete control over your LLM infrastructure.
Key Highlights of Langfuse Setup
Langfuse equips you with a suite of powerful tools to streamline the LLM development workflow:
- Prompt Management: Effortlessly version and retrieve prompts, ensuring reproducibility and facilitating experimentation.
- Tracing: Gain deep visibility into your LLM applications with detailed traces, enabling efficient debugging and troubleshooting. The intuitive UI out of the box enables teams to annotate model interactions to develop and evaluate training datasets.
- Metrics: Track crucial metrics such as cost, latency, and token usage, empowering you to optimize performance and control expenses.
- Evaluation: Capture user feedback, annotate LLM responses, and even set up evaluation functions to continuously assess and improve your models.
- Datasets: Manage and organize datasets derived from your LLM applications, facilitating further fine-tuning and model enhancement.
Effortless Setup
Langfuse’s self-hosting solution is remarkably easy to set up, leveraging a docker-based architecture that you can quickly spin up using docker compose. This streamlined approach minimizes deployment complexities and allows you to focus on building your LLM applications.
Framework Compatibility
Langfuse seamlessly integrates with popular LLM frameworks like LangChain, LlamaIndex, and, of course, DSPy, making it a versatile tool for a wide range of LLM development frameworks.
The Power of DSPY + Langfuse
By integrating Langfuse into your DSPy applications, you unlock a wealth of observability capabilities that enable you to monitor, analyze, and optimize your models in real time.
Integrating Langfuse into Your DSPy App
The integration process is straightforward and involves instrumenting your DSPy code with Langfuse’s SDK.
import dspy
from dsp.trackers.langfuse_tracker import LangfuseTracker
# configure tracker
langfuse = LangfuseTracker()
# instantiate openai client
openai = dspy.OpenAI(
model='gpt-4o-mini',
temperature=0.5,
max_tokens=1500
)
# dspy predict supercharged with automatic langfuse trackers
openai("What is DSPy?")
Gaining Insights with Langfuse
Once integrated, Langfuse provides a number of actionable insights into your DSPy application’s behavior:
- Trace-Based Debugging: Follow the execution flow of your DSPY programs, pinpoint bottlenecks, and identify areas for improvement.
- Performance Monitoring: Track key metrics like latency and token usage to ensure optimal performance and cost-efficiency.
- User Interaction Analysis: Understand how users interact with your LLM app, identify common queries, and opportunities for enhancement.
- Data Collection & Fine-Tuning: Collect and annotate LLM responses, building valuable datasets for further fine-tuning and model refinement.
Use Cases Amplified
The combination of DSPy and Langfuse is particularly important in the following scenarios:
- Complex Pipelines: When dealing with complex DSPy pipelines involving multiple modules, Langfuse’s tracing capabilities become indispensable for debugging and understanding the flow of information.
- Production Environments: In production settings, Langfuse’s monitoring features ensure your LLM app runs smoothly, providing early warnings of potential issues while keeping an eye on costs involved.
- Iterative Development: Langfuse’s evaluation and dataset management tools facilitate data-driven iteration, allowing you to continuously refine your LLM app based on real-world usage.
The Meta Use Case: Q&A Bot for my Workshop
To truly showcase the power and versatility of DSPy combined with amazing monitoring capabilities of langfuse, I’ve recently applied them to a unique dataset: my recent LLM workshop GitHub repository. This recent full day workshop contains a lot of material to get you started with LLMs. The aim of this Q&A bot was to assist participants during and after the workshop with answers to a host NLP and LLM related topics covered in the workshop. This “meta” use case not only demonstrates the practical application of these tools but also adds a touch of self-reflection to our exploration.
The Task: Building a Q&A System
For this exercise, we’ll leverage DSPy to build a Q&A system capable of answering questions about the content of my workshop (notebooks, markdown files, etc.). This task highlights DSPy’s ability to process and extract information from textual data, a crucial capability for a wide range of LLM applications. Imagine having a personal AI assistant (or co-pilot) that can help you recall details from your past weeks, identify patterns in your work, or even surface forgotten insights! It also presents a strong case of how such a modular setup can be easily extended to any other textual dataset with little to no effort.
Let us begin by setting up the required objects for our program.
import os
import dspy
from dsp.trackers.langfuse_tracker import LangfuseTracker
config = {
'LANGFUSE_PUBLIC_KEY': 'XXXXXX',
'LANGFUSE_SECRET_KEY': 'XXXXXX',
'LANGFUSE_HOST': 'http://localhost:3000',
'OPENAI_API_KEY': 'XXXXXX',
'OPENAI_BASE_URL': 'XXXXXX',
'OPENAI_PROVIDER': 'XXXXXX',
'CHROMA_DB_PATH': './chromadb/',
'CHROMA_COLLECTION_NAME':"supercharged_workshop_collection",
'CHROMA_EMB_MODEL': 'all-MiniLM-L6-v2'
}
# setting config
os.environ["LANGFUSE_PUBLIC_KEY"] = config.get('LANGFUSE_PUBLIC_KEY')
os.environ["LANGFUSE_SECRET_KEY"] = config.get('LANGFUSE_SECRET_KEY')
os.environ["LANGFUSE_HOST"] = config.get('LANGFUSE_HOST')
os.environ["OPENAI_API_KEY"] = config.get('OPENAI_API_KEY')
# setup Langfuse tracker
langfuse_tracker = LangfuseTracker(session_id='supercharger001')
# instantiate language-model for DSPY
llm_model = dspy.OpenAI(
api_key=config.get('OPENAI_API_KEY'),
model='gpt-4o-mini'
)
# instantiate chromadb client
chroma_emb_fn = embedding_functions.
SentenceTransformerEmbeddingFunction(
model_name=config.get(
'CHROMA_EMB_MODEL'
)
)
client = chromadb.HttpClient()
# setup chromadb collection
collection = client.create_collection(
config.get('CHROMA_COLLECTION_NAME'),
embedding_function=chroma_emb_fn,
metadata={"hnsw:space": "cosine"}
)
Once we have these clients and trackers in place, let us quickly add some documents to our collection (refer to this notebook for a detailed walk through of how I prepared this dataset in the first place).
# Add to collection
collection.add(
documents=[v for _,v in nb_scraper.notebook_md_dict.items()],
ids=doc_ids, # must be unique for each doc
)
The next step is to simply connect our chromadb retriever to the DSPy framework. The following snippet created a RM object and tests if the retrieval works as intended.
retriever_model = ChromadbRM(
config.get('CHROMA_COLLECTION_NAME'),
config.get('CHROMA_DB_PATH'),
embedding_function=chroma_emb_fn,
client=client,
k=5
)
# Test Retrieval
results = retriever_model("RLHF")
for result in results:
display(Markdown(f"__Document__::{result.long_text[:100]}... n"))
display(Markdown(f">- __Document id__::{result.id} n>- __Document score__::{result.score}"))
The output looks promising given that without any intervention, Chromadb is able to fetch the most relevant documents.
Document::# Quick Overview of RLFH
The performance of Language Models until GPT-3 was kind of amazing as-is. ...
- Document id::6_module_03_03_RLHF_phi2
- Document score::0.6174977412306334
Document::# Getting Started : Text Representation Image
The NLP domain ...
- Document id::2_module_01_02_getting_started
- Document score::0.8062083377747705
Document::# Text Generation <a target="_blank" href="https://colab.research.google.com/github/raghavbali/llm_w" > ...
- Document id::3_module_02_02_simple_text_generator
- Document score::0.8826038964887366
Document::# Image DSPy: Beyond Prompting
<img src= "./assets/dspy_b" > ...
- Document id::12_module_04_05_dspy_demo
- Document score::0.9200280698248913
The final step is to piece all of this together in preparing a DSPy program. For our simple Q&A use-case we make prepare a standard RAG program leveraging Chromadb as our retriever and Langfuse as our tracker. The following snippet presents the pytorch-like approach of developing LLM based apps without worrying about brittle prompts!
# RAG Signature
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often less than 50 words")
# RAG Program
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
# compile a RAG
# note: we are not using any optimizers for this example
compiled_rag = RAG()
Phew! Wasn’t that quick and simple to do? Let us now put this into action using a few sample questions.
my_questions = [
"List the models covered in module03",
"Brief summary of module02",
"What is LLaMA?"
]
for question in my_questions:
# Get the prediction. This contains `pred.context` and `pred.answer`.
pred = compiled_rag(question)
display(Markdown(f"__Question__: {question}"))
display(Markdown(f"__Predicted Answer__: _{pred.answer}_"))
display(Markdown("__Retrieved Contexts (truncated):__"))
for idx,cont in enumerate(pred.context):
print(f"{idx+1}. {cont[:200]}..." )
print()
display(Markdown('---'))
The output is indeed quite on point and serves the purpose of being an assistant to this workshop material answering questions and guiding the attendees nicely.

The Langfuse Advantage
Earlier in this article we discussed how langfuse completes the picture by enabling us to monitor LLM usage and improve upon other aspects of the pipeline. The amazing integration of langfuse as a tracker glues everything behind the scenes with a nice and easy to use interface. For our current setting, the langfuse dashboard presents a quick summary of our LLM usage.
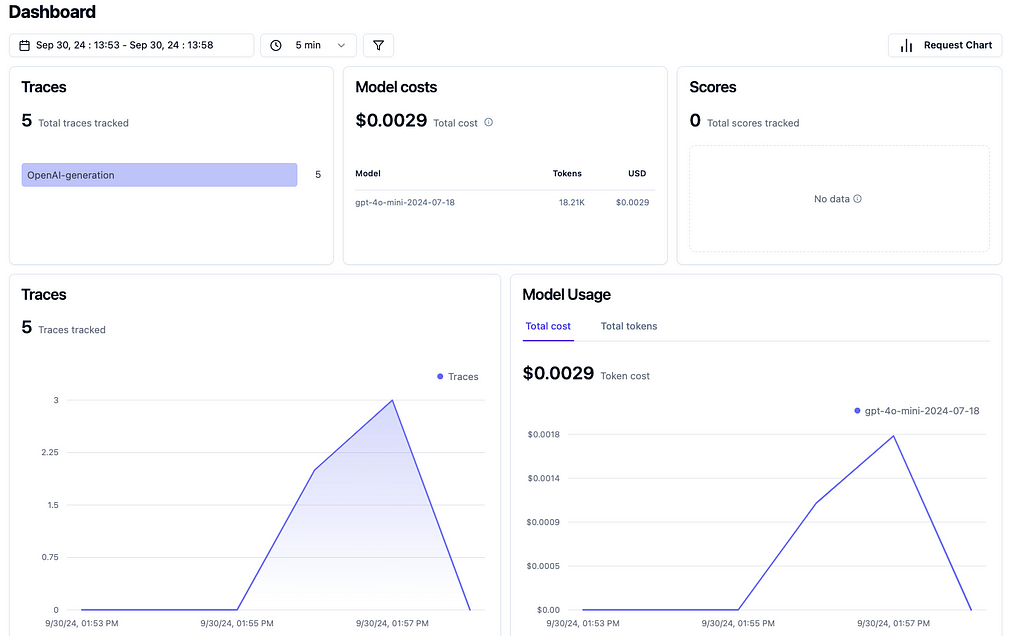
The dashboard is complete with metrics such as number of traces, overall costs and even token usage (which is quite handy when it comes to optimize your pipelines).
Insights and Benefits
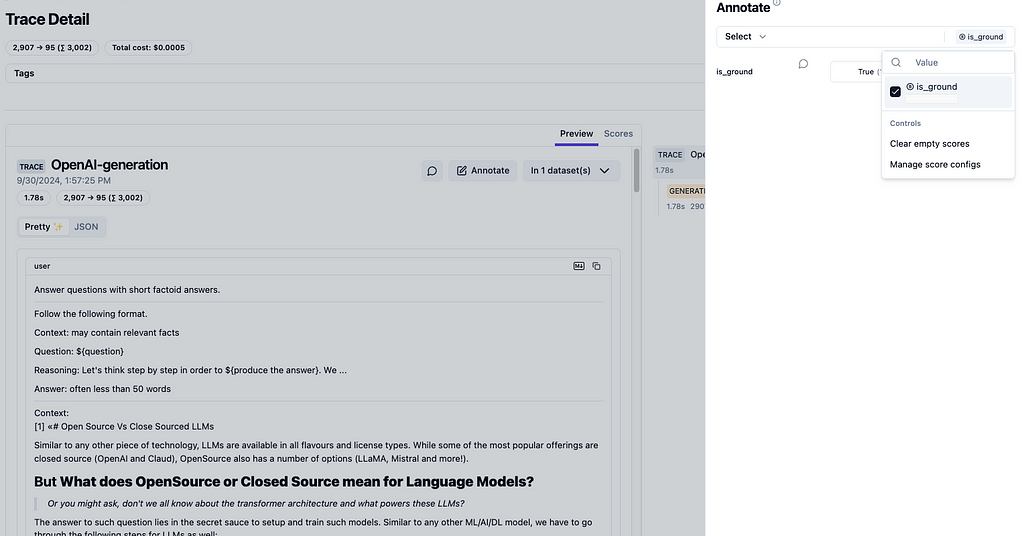
Langfuse’s utility does not end with top-level dashboard of metrics. It provides trace level details (as shown in figure 4).
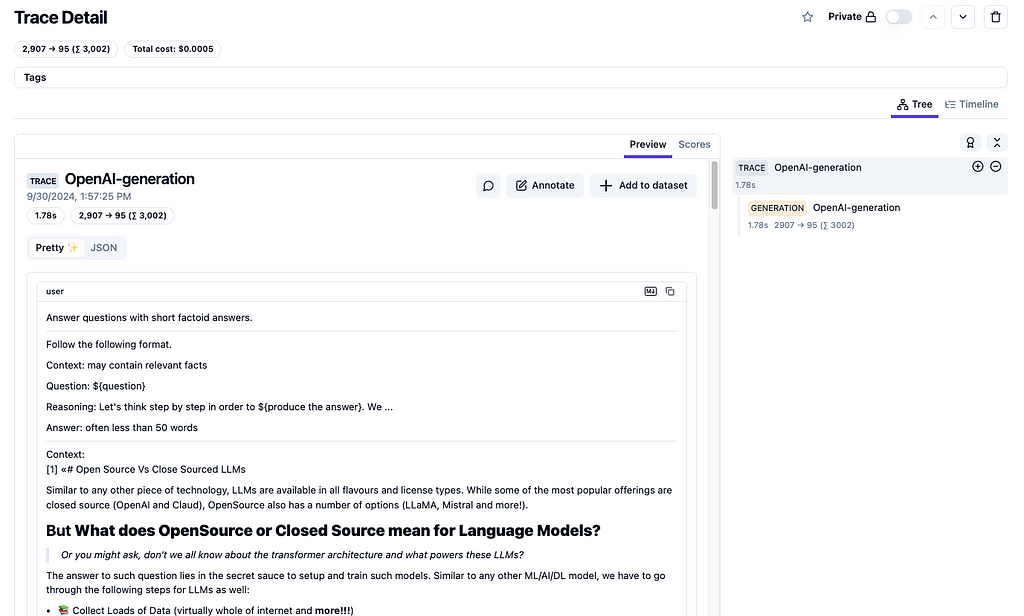
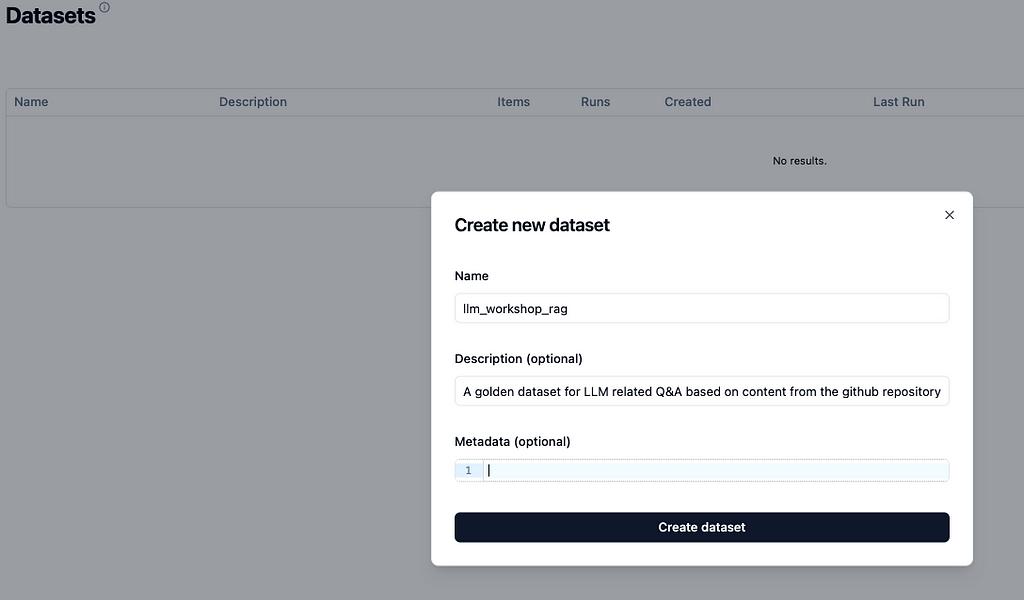
This interface is a gateway to a number of other aspects that are very useful in terms of iterating and improving LLM based apps. The first and foremost capability is to prepare datasets based on real world usage. These datasets can be used for fine-tuning LLMs, optimizing DSPy programs, etc. Figure 5 illustrates how simple it is to define a dataset from the web-UI itself and then add traces (input request along with model’s response) as needed to the dataset.
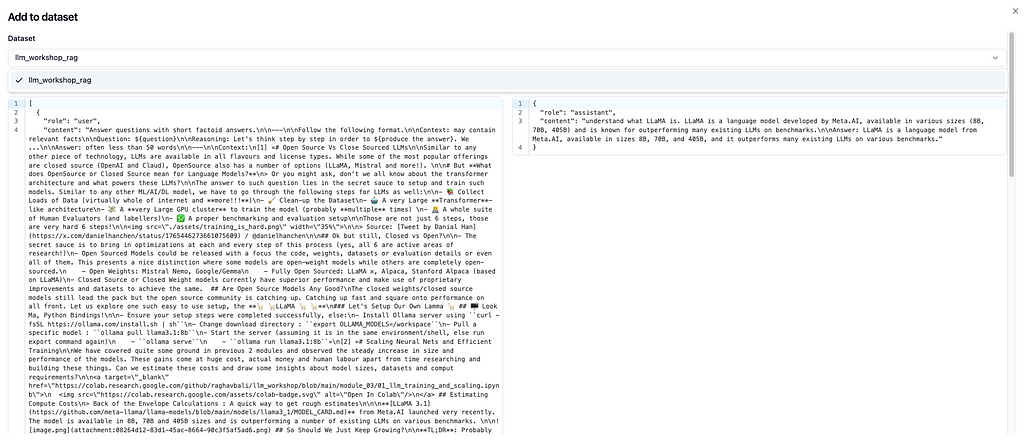
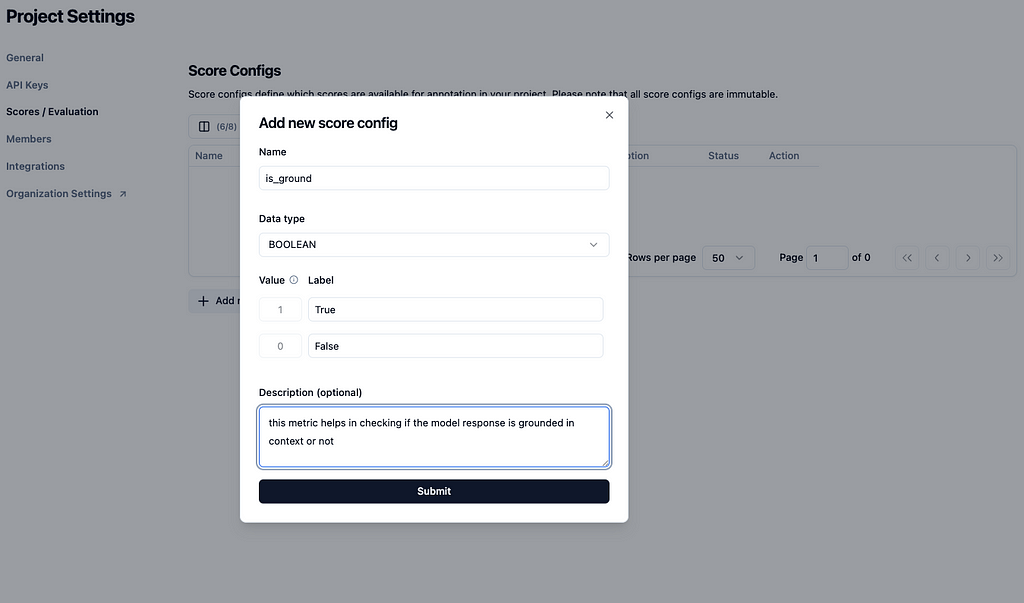
Similar to dataset creation and adding data points to it, langfuse simplifies creation of metrics and annotating datapoints. Figure 6 illustrates how simple it is to do the same at the click of a couple of buttons.
Once we have a dataset prepared, langfuse provides a straightforward SDK to use it in your language of of preference. The following snippet makes use of get_dataset utility from langfuse to get to a couple of traces we added to the sample dataset. We then use LLaMA 3.1 to power our DSPy RAG program with just one line change (talk about modularity 😉 ).
# get annotated dataset
annotated_dataset = langfuse.get_dataset("llm_workshop_rag")
# ensure ollama is available in your environment
ollama_dspy = dspy.OllamaLocal(model='llama3.1',temperature=0.5)
# get langfuse client from the dspy tracker object
langfuse =langfuse_tracker.langfuse
# Set up the ollama as LM and RM
dspy.settings.configure(lm=ollama_dspy,rm=retriever_model)
# test rag using ollama
ollama_rag = RAG()
# iterate through samples from the annotated dataset
for item in annotated_dataset.items:
question = item.input[0]['content'].split('Question: ')[-1].split('n')[0]
answer = item.expected_output['content'].split('Answer: ')[-1]
o_pred = ollama_rag(question)
# add observations to dataset related experiments
with item.observe(
run_name='ollama_experiment',
run_description='compare LLaMA3.1 RAG vs GPT4o-mini RAG ',
run_metadata={"model": "llama3.1"},
) as trace_id:
langfuse.score(
name="visual-eval",
# any float value
value=1.0,
comment="LLaMA3.1 is very verbose",
)
# attach trace with new run
langfuse.trace(input=question,output=o_pred.answer,metadata={'model':'LLaMA3.1'})
display(Markdown(f"__Question__: {question}"))
display(Markdown(f"__Predicted Answer (LLaMA 3.1)__: {o_pred.answer}"))
display(Markdown(f">__Annotated Answer (GPT-4o-mini)__: _{answer}_"))
As shown in the above snippet, we simply iterate through the datapoints in our dataset and visually compare the output from both models (see figure 7). Using Langfuse SDK we attach experiment observations along with new traces and evaluation scores very easily.


The output presented in figure 7 clearly shows how LLaMA3.1 powered RAG does answer the questions but strays from the instructions of being brief. This can be easily captured using DSPy assertions as well as scores can be tracked using langfuse SDK for further improvements.
Conclusion
In this rapidly evolving landscape of LLM applications, tools like DSPy and Langfuse emerge as invaluable allies for developers & data scientists. DSPy streamlines the development process, empowering you to build sophisticated LLM applications with ease and efficiency. Meanwhile, Langfuse provides the crucial observability layer, enabling you to gain deep insights into your models’ performance, optimize resource utilization, and continuously improve your applications based on real-world data.
The combination of DSPY and Langfuse unlocks a world of possibilities, allowing you to harness the full potential of LLMs. Whether you’re building Q&A systems, content generators, or any other LLM-powered application, these tools provide the foundation for creating robust, scalable, and insightful solutions.
As I’ve demonstrated through the meta usecase of answering questions for my recent LLM-workshop, DSPy and Langfuse can be applied creatively to extract valuable insights from even your own personal data. The possibilities are truly endless.
I encourage you to explore these tools/frameworks in your own projects. Interested folks can leverage the comprehensive hands-on driven workshop material for more topics on my GitHub repository. With these tools at your disposal, you’re well-equipped to supercharge your LLM applications and stay ahead in the ever-evolving world of AI.
References
GitHub – raghavbali/llm_workshop: LLM Workshop 2024
Supercharge Your LLM Apps using DSPy and Langfuse was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Supercharge Your LLM Apps using DSPy and Langfuse
Go Here to Read this Fast! Supercharge Your LLM Apps using DSPy and Langfuse