A framework to select the simplest, fastest, cheapest architecture that will balance LLMs’ creativity and risk
Look at any LLM tutorial and the suggested usage involves invoking the API, sending it a prompt, and using the response. Suppose you want the LLM to generate a thank-you note, you could do:
import openai
recipient_name = "John Doe"
reason_for_thanks = "helping me with the project"
tone = "professional"
prompt = f"Write a thank you message to {recipient_name} for {reason_for_thanks}. Use a {tone} tone."
response = openai.Completion.create("text-davinci-003", prompt=prompt, n=1)
email_body = response.choices[0].text
While this is fine for PoCs, rolling to production with an architecture that treats an LLM as just another text-to-text (or text-to-image/audio/video) API results in an application that is under-engineered in terms of risk, cost, and latency.
The solution is not to go to the other extreme and over-engineer your application by fine-tuning the LLM and adding guardrails, etc. every time. The goal, as with any engineering project, is to find the right balance of complexity, fit-for-purpose, risk, cost, and latency for the specifics of each use case. In this article, I’ll describe a framework that will help you strike this balance.
The framework of LLM application architectures
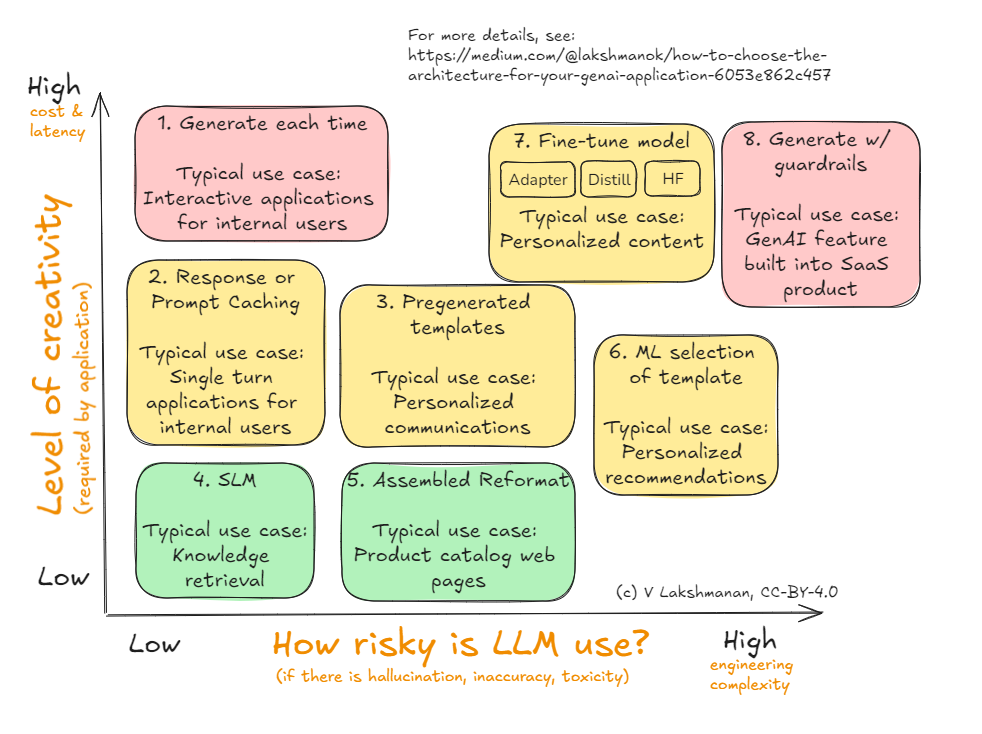
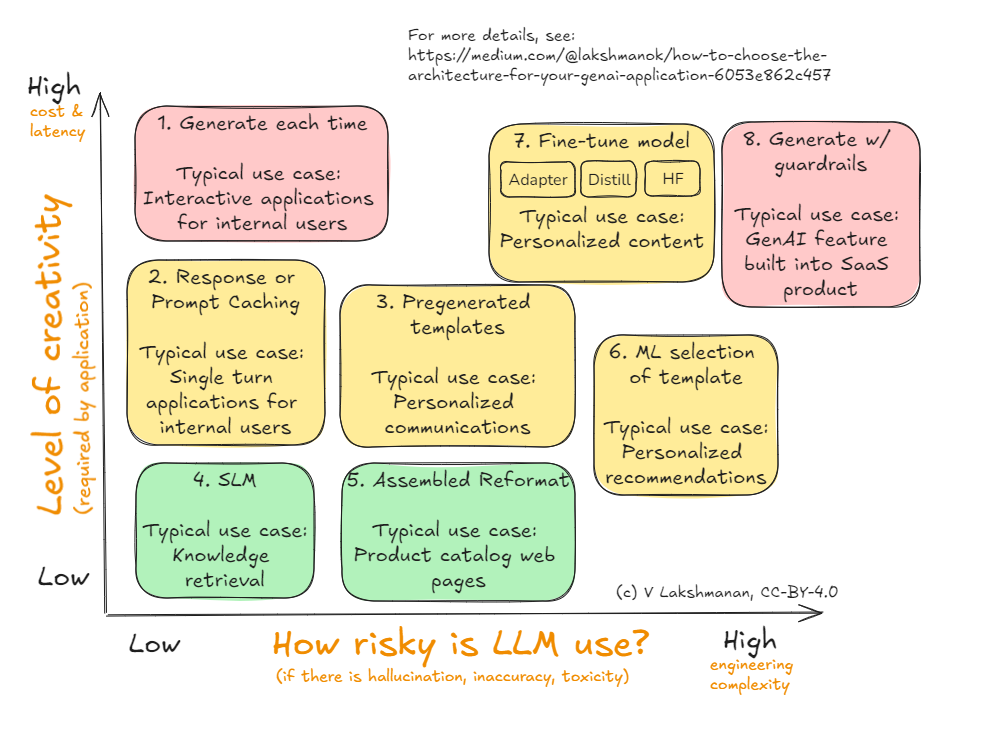
Here’s a framework that I suggest you use to decide on the architecture for your GenAI application or agent. I’ll cover each of the eight alternatives shown in the Figure below in the sections that follow.
The axes here (i.e., the decision criteria) are risk and creativity. For each use case where you are going to employ an LLM, start by identifying the creativity you need from the LLM and the amount of risk that the use case carries. This helps you narrow down the choice that strikes the right balance for you.
Note that whether or not to use Agentic Systems is a completely orthogonal decision to this — employ agentic systems when the task is too complex to be done by a single LLM call or if the task requires non-LLM capabilities. In such a situation, you’d break down the complex task into simpler tasks and orchestrate them in an agent framework. This article shows you how to build a GenAI application (or an agent) to perform one of those simple tasks.
Why the 1st decision criterion is creativity
Why are creativity and risk the axes? LLMs are a non-deterministic technology and are more trouble than they are worth if you don’t really need all that much uniqueness in the content being created.
For example, if you are generating a bunch of product catalog pages, how different do they really have to be? Your customers want accurate information on the products and may not really care that all SLR camera pages explain the benefits of SLR technology in the same way — in fact, some amount of standardization may be quite preferable for easy comparisons. This is a case where your creativity requirement on the LLM is quite low.
It turns out that architectures that reduce the non-determinism also reduce the total number of calls to the LLM, and so also have the side-effect of reducing the overall cost of using the LLM. Since LLM calls are slower than the typical web service, this also has the nice side-effect of reducing the latency. That’s why the y-axis is creativity, and why we have cost and latency also on that axis.
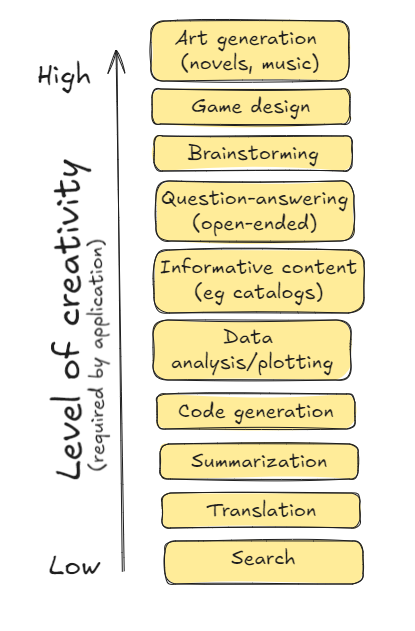
You could look at the illustrative use cases listed in the diagram above and argue whether they require low creativity or high. It really depends on your business problem. If you are a magazine or ad agency, even your informative content web pages (unlike the product catalog pages) may need to be creative.
Why the 2nd decision criterion is risk
LLMs have a tendency to hallucinate details and to reflect biases and toxicity in their training data. Given this, there are risks associated with directly sending LLM-generated content to end-users. Solving for this problem adds a lot of engineering complexity — you might have to introduce a human-in-the-loop to review content, or add guardrails to your application to validate that the generated content doesn’t violate policy.
If your use case allows end-users to send prompts to the model and the application takes actions on the backend (a common situation in many SaaS products) to generate a user-facing response, the risk associated with errors, hallucination, and toxicity is quite high.
The same use case (art generation) could carry different levels and kinds of risk depending on the context as shown in the figure below. For example, if you are generating background instrumental music to a movie, the risk associated might involve mistakenly reproducing copyrighted notes, whereas if you are generating ad images or videos broadcast to millions of users, you may be worried about toxicity. These different types of risk are associated with different levels of risk. As another example, if you are building an enterprise search application that returns document snippets from your corporate document store or technology documentation, the LLM-associated risks might be quite low. If your document store consists of medical textbooks, the risk associated with out-of-context content returned by a search application might be high.
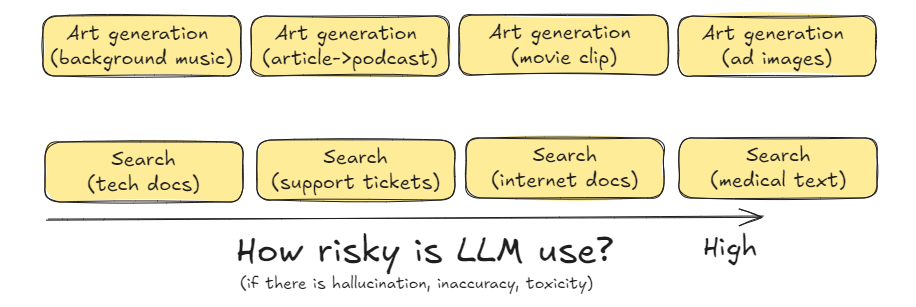
As with the list of use cases ordered by creativity, you can quibble with the ordering of use cases by risk. But once you identify the risk associated with the use case and the creativity it requires, the suggested architecture is worth considering as a starting point. Then, if you understand the “why” behind each of these architectural patterns, you can select an architecture that balances your needs.
In the rest of this article, I’ll describe the architectures, starting from #1 in the diagram.
1. Generate each time (for High Creativity, Low Risk tasks)
This is the architectural pattern that serves as the default — invoke the API of the deployed LLM each time you want generated content. It’s the simplest, but it also involves making an LLM call each time.
Typically, you’ll use a PromptTemplate and templatize the prompt that you send to the LLM based on run-time parameters. It’s a good idea to use a framework that allows you to swap out the LLM.
For our example of sending an email based on the prompt, we could use langchain:
prompt_template = PromptTemplate.from_template(
"""
You are an AI executive assistant to {sender_name} who writes letters on behalf of the executive.
Write a 3-5 sentence thank you message to {recipient_name} for {reason_for_thanks}.
Extract the first name from {sender_name} and sign the message with just the first name.
"""
)
...
response = chain.invoke({
"recipient_name": "John Doe",
"reason_for_thanks": "speaking at our Data Conference",
"sender_name": "Jane Brown",
})
Because you are calling the LLM each time, it’s appropriate only for tasks that require extremely high creativity (e.g., you want a different thank you note each time) and where you are not worried about the risk (e.g, if the end-user gets to read and edit the note before hitting “send”).
A common situation where this pattern is employed is for interactive applications (so it needs to respond to all kinds of prompts) meant for internal users (so low risk).
2. Response/Prompt caching (for Medium Creativity, Low Risk tasks)
You probably don’t want to send the same thank you note again to the same person. You want it to be different each time.
But what if you are building a search engine on your past tickets, such as to assist internal customer support teams? In such cases, you do want repeat questions to generate the same answer each time.
A way to drastically reduce cost and latency is to cache past prompts and responses. You can do such caching on the client side using langchain:
from langchain_core.caches import InMemoryCache
from langchain_core.globals import set_llm_cache
set_llm_cache(InMemoryCache())
prompt_template = PromptTemplate.from_template(
"""
What are the steps to put a freeze on my credit card account?
"""
)
chain = prompt_template | model | parser
When I tried it, the cached response took 1/1000th of the time and avoided the LLM call completely.
Caching is useful beyond client-side caching of exact text inputs and the corresponding responses (see Figure below). Anthropic supports “prompt caching” whereby you can ask the model to cache part of a prompt (typically the system prompt and repetitive context) server-side, while continuing to send it new instructions in each subsequent query. Using prompt caching reduces cost and latency per query while not affecting the creativity. It is particularly helpful in RAG, document extraction, and few-shot prompting when the examples get large.
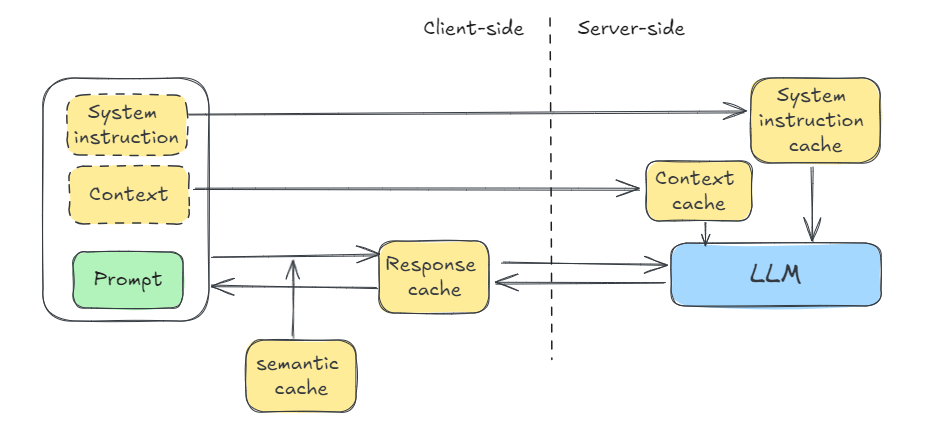
Gemini separates out this functionality into context caching (which reduces the cost and latency) and system instructions (which don’t reduce the token count, but do reduce latency). OpenAI recently announced support for prompt caching, with its implementation automatically caching the longest prefix of a prompt that was previously sent to the API, as long as the prompt is longer than 1024 tokens. Server-side caches like these do not reduce the capability of the model, only the latency and/or cost, as you will continue to potentially get different results to the same text prompt.
The built-in caching methods require exact text match. However, it is possible to implement caching in a way that takes advantage of the nuances of your case. For example, you could rewrite prompts to canonical forms to increase the chances of a cache hit. Another common trick is to store the hundred most frequent questions, for any question that is close enough, you could rewrite the prompt to ask the stored question instead. In a multi-turn chatbot, you could get user confirmation on such semantic similarity. Semantic caching techniques like this will reduce the capability of the model somewhat, since you will get the same responses to even similar prompts.
3. Pregenerated templates (for Medium Creativity, Low-Medium Risk tasks)
Sometimes, you don’t really mind the same thank you note being generated to everyone in the same situation. Perhaps you are writing the thank you note to a customer who bought a product, and you don’t mind the same thank you note being generated to any customer who bought that product.
At the same time, there is a higher risk associated with this use case because these communications are going out to end-users and there is no internal staff person able to edit each generated letter before sending it out.
In such cases, it can be helpful to pregenerate templated responses. For example, suppose you are a tour company and you offer 5 different packages. All you need is one thank you message for each of these packages. Maybe you want different messages for solo travelers vs. families vs. groups. You still need only 3x as many messages as you have packages.
prompt_template = PromptTemplate.from_template(
"""
Write a letter to a customer who has purchased a tour package.
The customer is traveling {group_type} and the tour is to {tour_destination}.
Sound excited to see them and explain some of the highlights of what they will see there
and some of the things they can do while there.
In the letter, use [CUSTOMER_NAME] to indicate the place to be replaced by their name
and [TOUR_GUIDE] to indicate the place to be replaced by the name of the tour guide.
"""
)
chain = prompt_template | model | parser
print(chain.invoke({
"group_type": "family",
"tour_destination": "Toledo, Spain",
}))
The result is messages like this for a given group-type and tour-destination:
Dear [CUSTOMER_NAME],
We are thrilled to welcome you to Toledo on your upcoming tour! We can't wait to show you the beauty and history of this enchanting city.
Toledo, known as the "City of Three Cultures," boasts a fascinating blend of Christian, Muslim, and Jewish heritage. You'll be mesmerized by the stunning architecture, from the imposing Alcázar fortress to the majestic Toledo Cathedral.
During your tour, you'll have the opportunity to:
* **Explore the historic Jewish Quarter:** Wander through the narrow streets lined with ancient synagogues and traditional houses.
* **Visit the Monastery of San Juan de los Reyes:** Admire the exquisite Gothic architecture and stunning cloisters.
* **Experience the panoramic views:** Take a scenic walk along the banks of the Tagus River and soak in the breathtaking views of the city.
* **Delve into the art of Toledo:** Discover the works of El Greco, the renowned painter who captured the essence of this city in his art.
Our expert tour guide, [TOUR_GUIDE], will provide insightful commentary and share fascinating stories about Toledo's rich past.
We know you'll have a wonderful time exploring the city's treasures. Feel free to reach out if you have any questions before your arrival.
We look forward to welcoming you to Toledo!
Sincerely,
The [Tour Company Name] Team
You can generate these messages, have a human vet them, and store them in your database.
As you can see, we asked the LLM to insert placeholders in the message that we can replace dynamically. Whenever you need to send out a response, retrieve the message from the database and replace the placeholders with actual data.
Using pregenerated templates turns a problem that would have required vetting hundreds of messages per day into one that requires vetting a few messages only when a new tour is added.
4. Small Language Models (Low Risk, Low Creativity)
Recent research shows that it is impossible to eliminate hallucination in LLMs because it arises from a tension between learning all the computable functions we desire. A smaller LLM for a more targeted task has less risk of hallucinating than one that’s too large for the desired task. You might be using a frontier LLM for tasks that don’t require the power and world-knowledge that it brings.
In use cases where you have a very simple task that doesn’t require much creativity and very low risk tolerance, you have the option of using a small language model (SLM). This does trade off accuracy — in a June 2024 study, a Microsoft researcher found that for extracting structured data from unstructured text corresponding to an invoice, their smaller text-based model (Phi-3 Mini 128K) could get 93% accuracy as compared to the 99% accuracy achievable by GPT-4o.
The team at LLMWare evaluates a wide range of SLMs. At the time of writing (2024), they found that Phi-3 was the best, but that over time, smaller and smaller models were achieving this performance.
Representing these two studies pictorially, SLMs are increasingly achieving their accuracy with smaller and smaller sizes (so less and less hallucination) while LLMs have been focused on increasing task ability (so more and more hallucination). The difference in accuracy between these approaches for tasks like document extraction has stabilized (see Figure).
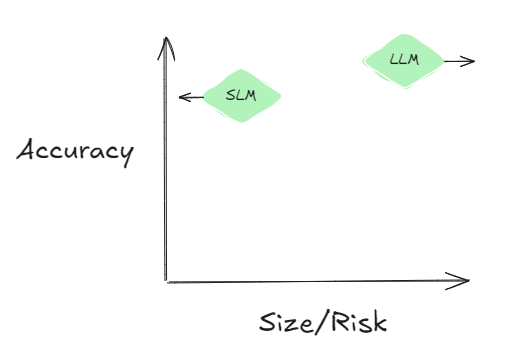
If this trend holds up, expect to be using SLMs and non-frontier LLMs for more and more enterprise tasks that require only low creativity and have a low tolerance for risk. Creating embeddings from documents, such as for knowledge retrieval and topic modeling, are use cases that tend to fit this profile. Use small language models for these tasks.
5. Assembled Reformat (Medium Risk, Low Creativity)
The underlying idea behind Assembled Reformat is to use pre-generation to reduce the risk on dynamic content, and use LLMs only for extraction and summarization, tasks that introduce only a low-level of risk even though they are done “live”.
Suppose you are a manufacturer of machine parts and need to create a web page for each item in your product catalog. You are obviously concerned about accuracy. You don’t want to claim some item is heat-resistant when it’s not. You don’t want the LLM to hallucinate the tools required to install the part.
You probably have a database that describes the attributes of each part. A simple approach is to employ an LLM to generate content for each of the attributes. As with pre-generated templates (Pattern #3 above), make sure to have a human review them before storing the content in your content management system.
prompt_template = PromptTemplate.from_template(
"""
You are a content writer for a manufacturer of paper machines.
Write a one-paragraph description of a {part_name}, which is one of the parts of a paper machine.
Explain what the part is used for, and reasons that might need to replace the part.
"""
)
chain = prompt_template | model | parser
print(chain.invoke({
"part_name": "wet end",
}))
However, simply appending all the text generated will result in something that’s not very pleasing to read. You could, instead, assemble all of this content into the context of the prompt, and ask the LLM to reformat the content into the desired website layout:
class CatalogContent(BaseModel):
part_name: str = Field("Common name of part")
part_id: str = Field("unique part id in catalog")
part_description: str = Field("short description of part")
price: str = Field("price of part")
catalog_parser = JsonOutputParser(pydantic_object=CatalogContent)
prompt_template = PromptTemplate(
template="""
Extract the information needed and provide the output as JSON.
{database_info}
Part description follows:
{generated_description}
""",
input_variables=["generated_description", "database_info"],
partial_variables={"format_instructions": catalog_parser.get_format_instructions()},
)
chain = prompt_template | model | catalog_parser
If you need to summarize reviews, or trade articles about the item, you can have this be done in a batch processing pipeline, and feed the summary into the context as well.
6. ML Selection of Template (Medium Creativity, Medium Risk)
The assembled reformat approach works for web pages where the content is quite static (as in product catalog pages). However, if you are an e-commerce retailer, and you want to create personalized recommendations, the content is much more dynamic. You need higher creativity out of the LLM. Your risk tolerance in terms of accuracy is still about the same.
What you can do in such cases is to continue to use pre-generated templates for each of your products, and then use machine learning to select which templates you will employ.
For personalized recommendations, for example, you’d use a traditional recommendations engine to select which products will be shown to the user, and pull in the appropriate pre-generated content (images + text) for that product.
This approach of combining pregeneration + ML can also be used if you are customizing your website for different customer journeys. You’ll pregenerate the landing pages and use a propensity model to choose what the next best action is.
7.Fine-tune (High Creativity, Medium Risk)
If your creativity needs are high, there is no way to avoid using LLMs to generate the content you need. But, generating the content every time means that you can not scale human review.
There are two ways to address this conundrum. The simpler one, from an engineering complexity standpoint, is to teach the LLM to produce the kind of content that you want and not generate the kinds of content you don’t. This can be done through fine-tuning.
There are three methods to fine-tune a foundational model: adapter tuning, distillation, and human feedback. Each of these fine-tuning methods address different risks:
- Adapter tuning retains the full capability of the foundational model, but allows you to select for specific style (such as content that fits your company voice). The risk addressed here is brand risk.
- Distillation approximates the capability of the foundational model, but on a limited set of tasks, and using a smaller model that can be deployed on premises or behind a firewall. The risk addressed here is of confidentiality.
- Human feedback either through RLHF or through DPO allows the model to start off with reasonable accuracy, but get better with human feedback. The risk addressed here is of fit-for-purpose.
Common use cases for fine-tuning include being able to create branded content, summaries of confidential information, and personalized content.
8. Guardrails (High Creativity, High Risk)
What if you want the full spectrum of capabilities, and you have more than one type of risk to mitigate — perhaps you are worried about brand risk, leakage of confidential information, and/or interested in ongoing improvement through feedback?
At that point, there is no alternative but to go whole hog and build guardrails. Guardrails may involve preprocessing the information going into the model, post-processing the output of the model, or iterating on the prompt based on error conditions.
Pre-built guardrails (eg. Nvidia’s NeMo) exist for commonly needed functionality such as checking for jailbreak, masking sensitive data in the input, and self-check of facts.
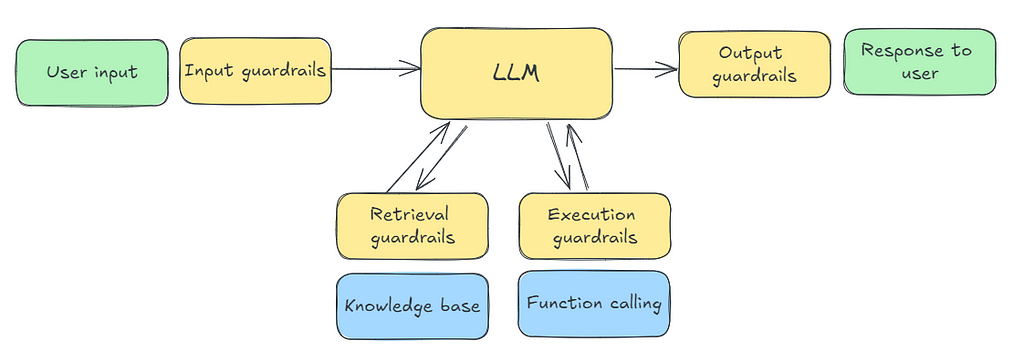
However, it’s likely that you’ll have to implement some of the guardrails yourself (see Figure above). An application that needs to be deployed alongside programmable guardrails is the most complex way that you could choose to implement a GenAI application. Make sure that this complexity is warranted before going down this route.
Summary
I suggest you use a framework that balances creativity and risk to decide on the architecture for your GenAI application or agent. Creativity refers to the level of uniqueness required in the generated content. Risk relates to the impact if the LLM generates inaccurate, biased, or toxic content. Addressing high-risk scenarios necessitates engineering complexity, such as human review or guardrails.
The framework consists of eight architectural patterns that address different combination of creativity and risk:
1. Generate Each Time: Invokes the LLM API for every content generation request, offering maximum creativity but with higher cost and latency. Suitable for interactive applications that don’t have much risk, such as internal tools..
2. Response/Prompt Caching: For medium creativity, low-risk tasks. Caches past prompts and responses to reduce cost and latency. Useful when consistent answers are desirable, such as internal customer support search engines. Techniques like prompt caching, semantic caching, and context caching enhance efficiency without sacrificing creativity.
3. Pregenerated Templates: Employs pre-generated, vetted templates for repetitive tasks, reducing the need for constant human review. Suitable for medium creativity, low-medium risk situations where standardized yet personalized content is required, such as customer communication in a tour company.
4. Small Language Models (SLMs): Uses smaller models to reduce hallucination and cost as compared to larger LLMs. Ideal for low creativity, low-risk tasks like embedding creation for knowledge retrieval or topic modeling.
5. Assembled Reformat: Uses LLMs for reformatting and summarization, with pre-generated content to ensure accuracy. Suitable for content like product catalogs where accuracy is paramount on some parts of the content, while creative writing is required on others.
6. ML Selection of Template: Leverages machine learning to select appropriate pre-generated templates based on user context, balancing personalization with risk management. Suitable for personalized recommendations or dynamic website content.
7. Fine-tune: Involves fine-tuning the LLM to generate desired content while minimizing undesired outputs, addressing risks related to one of brand voice, confidentiality, or accuracy. Adapter Tuning focuses on stylistic adjustments, distillation on specific tasks, and human feedback for ongoing improvement.
8. Guardrails: High creativity, high-risk tasks require guardrails to mitigate multiple risks, including brand risk and confidentiality, through preprocessing, post-processing, and iterative prompting. Off-the-shelf guardrails address common concerns like jailbreaking and sensitive data masking while custom-built guardrails may be necessary for industry/application-specific requirements.
By using the above framework to architect GenAI applications, you will be able to balance complexity, fit-for-purpose, risk, cost, and latency for each use case.
(Periodic reminder: these posts are my personal views, not those of my employers, past or present.)
How to Choose the Architecture for Your GenAI Application was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Choose the Architecture for Your GenAI Application
Go Here to Read this Fast! How to Choose the Architecture for Your GenAI Application