

Demystifying NLP: From Text to Embeddings
What is tokenization?
In computer science, we refer to human languages, like English and Mandarin, as “natural” languages. In contrast, languages designed to interact with computers, like Assembly and LISP, are called “machine” languages, following strict syntactic rules that leave little room for interpretation. While computers excel at processing their own highly structured languages, they struggle with the messiness of human language.
Language — especially text — makes up most of our communication and knowledge storage. For example, the internet is mostly text. Large language models like ChatGPT, Claude, and Llama are trained on enormous amounts of text — essentially all the text available online — using sophisticated computational techniques. However, computers operate on numbers, not words or sentences. So, how do we bridge the gap between human language and machine understanding?
This is where Natural Language Processing (NLP) comes into play. NLP is a field that combines linguistics, computer science, and artificial intelligence to enable computers to understand, interpret, and generate human language. Whether translating text from English to French, summarizing articles, or engaging in conversation, NLP allows machines to produce meaningful outputs from textual inputs.
The first critical step in NLP is transforming raw text into a format that computers can work with effectively. This process is known as tokenization. Tokenization involves breaking down text into smaller, manageable units called tokens, which can be words, subwords, or even individual characters. Here’s how the process typically works:
- Standardization: Before tokenizing, the text is standardized to ensure consistency. This may include converting all letters to lowercase, removing punctuation, and applying other normalization techniques.
- Tokenization: The standardized text is then split into tokens. For example, the sentence “The quick brown fox jumps over the lazy dog” can be tokenized into words:
["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]
- Numerical representation: Since computers operate on numerical data, each token is converted into a numerical representation. This can be as simple as assigning a unique identifier to each token or as complex as creating multi-dimensional vectors that capture the token’s meaning and context.
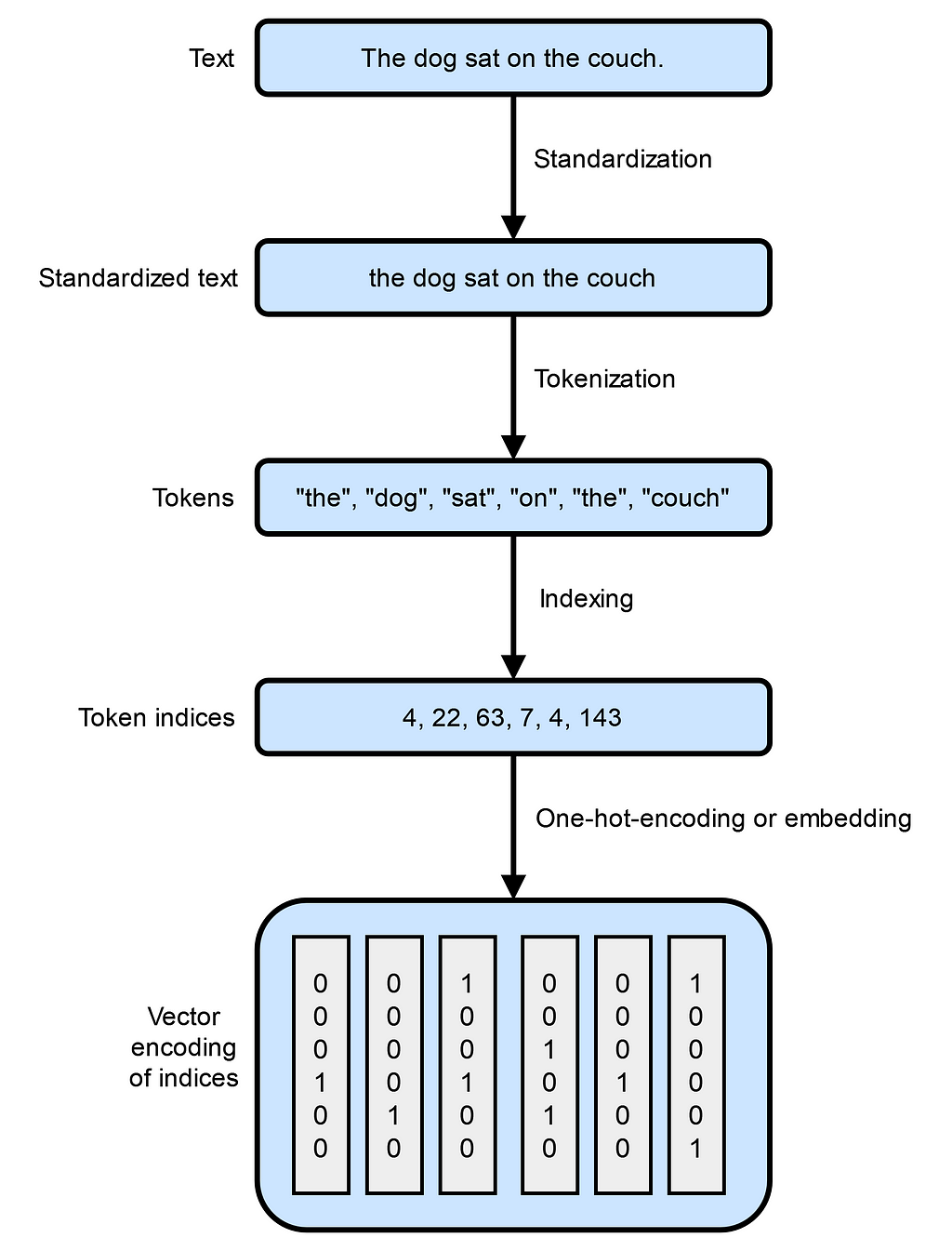
Tokenization is more than just splitting text; it’s about preparing language data in a way that preserves meaning and context for computational models. Different tokenization methods can significantly impact how well a model understands and processes language.
In this article, we focus on text standardization and tokenization, exploring a few techniques and implementations. We’ll lay the groundwork for converting text into numerical forms that machines can process — a crucial step toward advanced topics like word embeddings and language modeling that we’ll tackle in future articles.
Text standardization
Consider these two sentences:
1. “dusk fell, i was gazing at the Sao Paulo skyline. Isnt urban life vibrant??”
2. “Dusk fell; I gazed at the São Paulo skyline. Isn’t urban life vibrant?”
At first glance, these sentences convey a similar meaning. However, when processed by a computer, especially during tasks like tokenization or encoding, they can appear vastly different due to subtle variations:
- Capitalization: “dusk” vs. “Dusk”
- Punctuation: Comma vs. semicolon; presence of question marks
- Contractions: “Isnt” vs. “Isn’t”
- Spelling and Special Characters: “Sao Paulo” vs. “São Paulo”
These differences can significantly impact how algorithms interpret the text. For example, “Isnt” without an apostrophe may not be recognized as the contraction of “is not”, and special characters like “ã” in “São” may be misinterpreted or cause encoding issues.
Text standardization is a crucial preprocessing step in NLP that addresses these issues. By standardizing text, we reduce irrelevant variability and ensure that the data fed into models is consistent. This process is a form of feature engineering where we eliminate differences that are not meaningful for the task at hand.
A simple method for text standardization includes:
- Converting to lowercase: Reduces discrepancies due to capitalization.
- Removing punctuation: Simplifies the text by eliminating punctuation marks.
- Normalizing special characters: Converts characters like “ã” to their standard forms (“a”).
Applying these steps to our sentences, we get:
1. “dusk fell i was gazing at the sao paulo skyline isnt urban life vibrant”
2. “dusk fell i gazed at the sao paulo skyline isnt urban life vibrant”
Now, the sentences are more uniform, highlighting only the meaningful differences in word choice (e.g., “was gazing at” vs. “gazed at”).
While there are more advanced standardization techniques like stemming (reducing words to their root forms) and lemmatization (reducing words to their dictionary form), this basic approach effectively minimizes superficial differences.
Python implementation of text standardization
Here’s how you can implement basic text standardization in Python:
import re
import unicodedata
def standardize_text(text:str) -> str:
# Convert text to lowercase
text = text.lower()
# Normalize unicode characters to ASCII
text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8')
# Remove punctuation
text = re.sub(r'[^ws]', '', text)
# Remove extra whitespace
text = re.sub(r's+', ' ', text).strip()
return text
# Example sentences
sentence1 = "dusk fell, i was gazing at the Sao Paulo skyline. Isnt urban life vibrant??"
sentence2 = "Dusk fell; I gazed at the São Paulo skyline. Isn't urban life vibrant?"
# Standardize sentences
std_sentence1 = standardize_text(sentence1)
std_sentence2 = standardize_text(sentence2)
print(std_sentence1)
print(std_sentence2)
Output:
dusk fell i was gazing at the sao paulo skyline isnt urban life vibrant
dusk fell i gazed at the sao paulo skyline isnt urban life vibrant
By standardizing the text, we’ve minimized differences that could confuse a computational model. The model can now focus on the variations between the sentences, such as the difference between “was gazing at” and “gazed at”, rather than discrepancies like punctuation or capitalization.
Tokenization
After text standardization, the next critical step in natural language processing is tokenization. Tokenization involves breaking down the standardized text into smaller units called tokens. These tokens are the building blocks that models use to understand and generate human language. Tokenization prepares the text for vectorization, where each token is converted into numerical representations that machines can process.
We aim to convert sentences into a form that computers can efficiently and effectively handle. There are three common methods for tokenization:
1. Word-level tokenization
Splits text into individual words based on spaces and punctuation. It’s the most intuitive way to break down text.
text = "dusk fell i gazed at the sao paulo skyline isnt urban life vibrant"
tokens = text.split()
print(tokens)
Output:
['dusk', 'fell', 'i', 'gazed', 'at', 'the', 'sao', 'paulo', 'skyline', 'isnt', 'urban', 'life', 'vibrant']
2. Character-level tokenization
Breaks text into individual characters, including letters and sometimes punctuation.
text = "Dusk fell"
tokens = list(text)
print(tokens)
Output:
['D', 'u', 's', 'k', ' ', 'f', 'e', 'l', 'l']
3. Subword tokenization
Splits words into smaller, meaningful subword units. This method balances the granularity of character-level tokenization with the semantic richness of word-level tokenization. Algorithms like Byte-Pair Encoding (BPE) and WordPiece fall under this category. For instance, the BertTokenizer tokenizes “I have a new GPU!” as follows:
from transformers import BertTokenizer
text = "I have a new GPU!"
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize(text)
print(tokens)
Output:
['i', 'have', 'a', 'new', 'gp', '##u', '!']
Here, “GPU” is split into “gp” and “##u”, where “##” indicates that “u” is a continuation of the previous subword.
Subword tokenization offers a balanced approach between vocabulary size and semantic representation. By decomposing rare words into common subwords, it maintains a manageable vocabulary size without sacrificing meaning. Subwords carry semantic information that aids models in understanding context more effectively. This means models can process new or rare words by breaking them down into familiar subwords, increasing their ability to handle a wider range of language inputs.
For example, consider the word “annoyingly” which might be rare in a training corpus. It can be decomposed into the subwords “annoying” and “ly”. Both “annoying” and “ly” appear more frequently on their own, and their combined meanings retain the essence of “annoyingly”. This approach is especially beneficial in agglutinative languages like Turkish, where words can become exceedingly long by stringing together subwords to convey complex meanings.
Notice that the standardization step is often integrated into the tokenizer itself. Large language models use tokens as both inputs and outputs when processing text. Here’s a visual representation of tokens generated by Llama-3–8B on Tiktokenizer:
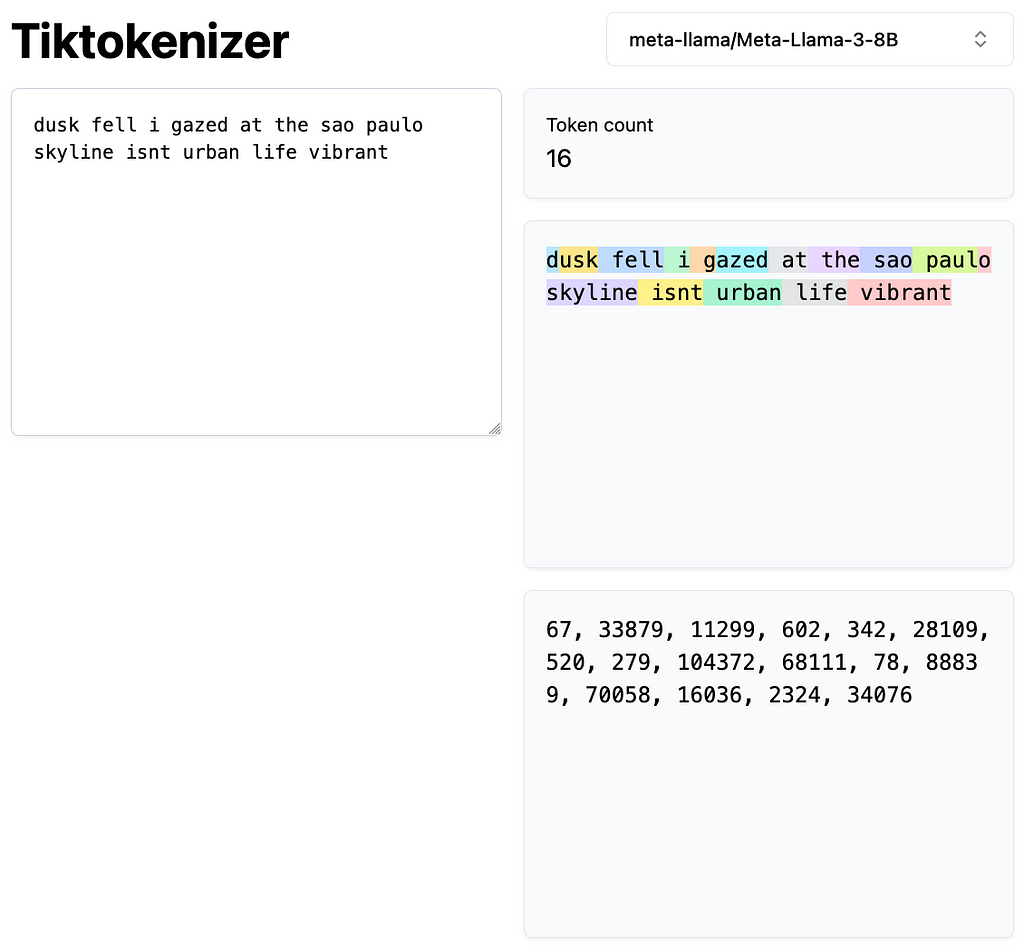
Additionally, Hugging Face provides an excellent summary of the tokenizers guide, in which I use some of its examples in this article.
Let’s now explore how different subword tokenization algorithms work. Note that all of those tokenization algorithms rely on some form of training which is usually done on the corpus the corresponding model will be trained on.
Byte-Pair Encoding (BPE)
Byte-Pair Encoding is a subword tokenization method introduced in Neural Machine Translation of Rare Words with Subword Unites by Sennrich et al. in 2015. BPE starts with a base vocabulary consisting of all unique characters in the training data and iteratively merges the most frequent pairs of symbols — which can be characters or sequences of characters — to form new subwords. This process continues until the vocabulary reaches a predefined size, which is a hyperparameter you choose before training.
Suppose we have the following words with their frequencies:
- “hug” (10 occurrences)
- “pug” (5 occurrences)
- “pun” (12 occurrences)
- “bun” (4 occurrences)
- “hugs” (5 occurrences)
Our initial base vocabulary consists of the following characters: [“h”, “u”, “g”, “p”, “n”, “b”, “s”].
We split the words into individual characters:
- “h” “u” “g” (hug)
- “p” “u” “g” (pug)
- “p” “u” “n” (pun)
- “b” “u” “n” (bun)
- “h” “u” “g” “s” (hugs)
Next, we count the frequency of each symbol pair:
- “h u”: 15 times (from “hug” and “hugs”)
- “u g”: 20 times (from “hug”, “pug”, “hugs”)
- “p u”: 17 times (from “pug”, “pun”)
- “u n”: 16 times (from “pun”, “bun”)
The most frequent pair is “u g” (20 times), so we merge “u” and “g” to form “ug” and update our words:
- “h” “ug” (hug)
- “p” “ug” (pug)
- “p” “u” “n” (pun)
- “b” “u” “n” (bun)
- “h” “ug” “s” (hugs)
We continue this process, merging the next most frequent pairs, such as “u n” into “un”, until we reach our desired vocabulary size.
BPE controls the vocabulary size by specifying the number of merge operations. Frequent words remain intact, reducing the need for extensive memorization. And, rare or unseen words can be represented through combinations of known subwords. It’s used in models like GPT and RoBERTa.
The Hugging Face tokenizers library provides a fast and flexible way to train and use tokenizers, including BPE.
Training a BPE Tokenizer
Here’s how to train a BPE tokenizer on a sample dataset:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# Initialize a tokenizer
tokenizer = Tokenizer(BPE())
# Set the pre-tokenizer to split on whitespace
tokenizer.pre_tokenizer = Whitespace()
# Initialize a trainer with desired vocabulary size
trainer = BpeTrainer(vocab_size=1000, min_frequency=2, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# Files to train on
files = ["path/to/your/dataset.txt"]
# Train the tokenizer
tokenizer.train(files, trainer)
# Save the tokenizer
tokenizer.save("bpe-tokenizer.json")
Using the trained BPE Tokenizer:
from tokenizers import Tokenizer
# Load the tokenizer
tokenizer = Tokenizer.from_file("bpe-tokenizer.json")
# Encode a text input
encoded = tokenizer.encode("I have a new GPU!")
print("Tokens:", encoded.tokens)
print("IDs:", encoded.ids)
Output:
Tokens: ['I', 'have', 'a', 'new', 'GP', 'U', '!']
IDs: [12, 45, 7, 89, 342, 210, 5]
WordPiece
WordPiece is another subword tokenization algorithm, introduced by Schuster and Nakajima in 2012 and popularized by models like BERT. Similar to BPE, WordPiece starts with all unique characters but differs in how it selects which symbol pairs to merge.
Here’s how WordPiece works:
- Initialization: Start with a vocabulary of all unique characters.
- Pre-tokenization: Split the training text into words.
- Building the Vocabulary: Iteratively add new symbols (subwords) to the vocabulary.
- Selection Criterion: Instead of choosing the most frequent symbol pair, WordPiece selects the pair that maximizes the likelihood of the training data when added to the vocabulary.
Using the same word frequencies as before, WordPiece evaluates which symbol pair, when merged, would most increase the probability of the training data. This involves a more probabilistic approach compared to BPE’s frequency-based method.
Similar to BPE, we can train a WordPiece tokenizer using the tokenizers library.
Training a WordPiece Tokenizer
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
from tokenizers.pre_tokenizers import Whitespace
# Initialize a tokenizer
tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
# Set the pre-tokenizer
tokenizer.pre_tokenizer = Whitespace()
# Initialize a trainer
trainer = WordPieceTrainer(vocab_size=1000, min_frequency=2, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# Train the tokenizer
tokenizer.train(files, trainer)
# Save the tokenizer
tokenizer.save("wordpiece-tokenizer.json")
Using the trained WordPiece tokenizer:
from tokenizers import Tokenizer
# Load the tokenizer
tokenizer = Tokenizer.from_file("wordpiece-tokenizer.json")
# Encode a text input
encoded = tokenizer.encode("I have a new GPU!")
print("Tokens:", encoded.tokens)
print("IDs:", encoded.ids)
Output:
Tokens: ['I', 'have', 'a', 'new', 'G', '##PU', '!']
IDs: [10, 34, 5, 78, 301, 502, 8]
Conclusion
Tokenization is a foundational step in NLP that prepares text data for computational models. By understanding and implementing appropriate tokenization strategies, we enable models to process and generate human language more effectively, setting the stage for advanced topics like word embeddings and language modeling.
All the code in this article is also available on my GitHub repo: github.com/murilogustineli/nlp-medium
Other Resources
- Let’s build the GPT Tokenizer | Andrej Karpathy on YouTube
- Tokenization | Mistral AI Large Language Models
- Summary of the tokenizers | Hugging Face
- Building a tokenizer, block by block | Hugging Face
Unless otherwise noted, all images are created by the author.
The Art of Tokenization: Breaking Down Text for AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Art of Tokenization: Breaking Down Text for AI
Go Here to Read this Fast! The Art of Tokenization: Breaking Down Text for AI