

What I learned doing semantic search on U.S. Presidents with four language model embeddings
I’m interested in trying to figure out what’s inside a language model embedding. You should be too, if one if these applies to you:
· The “thought processes” of large language models (LLMs) intrigues you.
· You build data-driven LLM systems, (especially Retrieval Augmented Generation systems) or would like to.
· You plan to use LLMs in the future for research (formal or informal).
· The idea of a brand new type of language representation intrigues you.
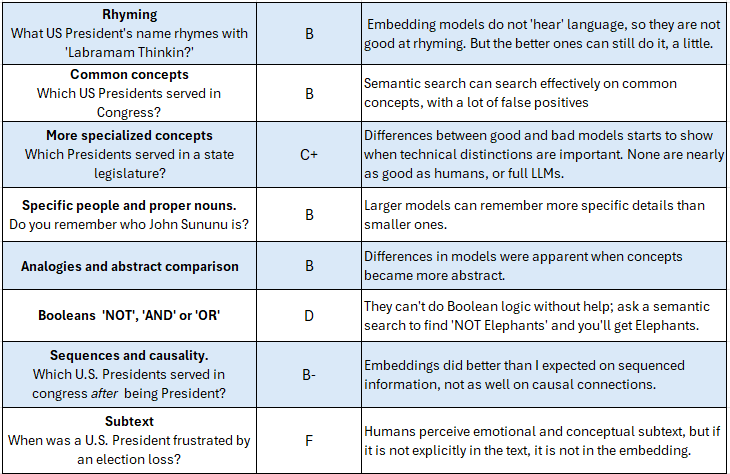
This blog post is intended to be understandable to any curious person, but even if you are language model specialist who works with them daily I think you will learn some useful things, as I did. Here’s a scorecard summary of what I learned about Language Model embeddings by performing semantic searches with them:
The Scorecard
What do embeddings “see” well enough to find passages in a larger dataset?
Along with many people, I have been fascinated by recent progress trying to look inside the ‘Black Box’ of large language models. There have recently been some incredible breakthroughs in understanding the inner workings of language models. Here are examples of this work by Anthropic, Google, and a nice review (Rai et al. 2024).
This exploration has similar goals, but we are studying embeddings, not full language models, and restricted to ‘black box’ inference from question responses, which is probably still the single best interpretability method.
Embeddings are what are created by LLMs in the first step, when they take a chunk of text and turn it into a long string of numbers that the language model networks can understand and use. Embeddings are used in Retrieval Augmented Generation (RAG) systems to allow searching on semantics (meanings) than are deeper than keyword-only searches. A set of texts, in my case the Wikipedia entries on U.S. Presidents, is broken into small chunks of text and converted to these numerical embeddings, then saved in a database. When a user asks a question, that question is also converted to embeddings. The RAG system then searches the database for an embedding similar to the user query, using a simple mathematical comparison between vectors, usually a cosine similarity. This is the ‘retrieval’ step, and the example code I provide ends there. In a full RAG system, whichever most-similar text chunks are retrieved from the database are then given to an LLM to use them as ‘context’ for answering the original question.
If you work with RAGs, you know there are many design variants of this basic process. One of the design choices is choosing a specific embedding model among the many available. Some models are longer, trained on more data, and cost more money, but without an understanding of what they are like and how they differ, the choice of which to use is often guesswork. How much do they differ, really?
If you don’t care about the RAG part
If you do not care about RAG systems but are just interested in learning more conceptually about how language models work, you might skip to the questions. Here is the upshot: embeddings encapsulate interesting data, information, knowledge, and maybe even wisdom gleaned from text, but neither their designers nor users knows exactly what they capture and what they miss. This post will search for information with different embeddings to try to understand what is inside them, and what is not.
The technical details: data, embeddings and chunk size
The dataset I’m using contains Wikipedia entries about U.S. Presidents. I use LlamaIndex for creating and searching a vector database of these text entries. I used a smaller than usual chunk size, 128 tokens, because larger chunks tend to overlay more content and I wanted a clean test of the system’s ability to find semantic matches. (I also tested chunk size 512 and results on most tests were similar.)
I’ll tests four embeddings:
1. BGE (bge-small-en-v1.5) is quite small at length 384. It the smallest of a line of BGE’s developed by the Beijing Academy of Artificial Intelligence. For it’s size, it does well on benchmark tests of retrieval (see leaderboard). It is F=free to use from HuggingFace.
2. ST (all-MiniLM-L6-v2) is another 384-length embedding. It excels at sentence comparisons; I’ve used it before for judging transcription accuracy. It was trained on the first billion sentence-pair corpus, which was about half Reddit data. It is also available HuggingFace.

3. Ada (text-embedding-ada-002) is the embedding scheme that OpenAI used from GPT-2 through GPT-4. It is much longer than the other embeddings at length 1536, but it is also older. How well can it compete with newer models?
4. Large (text-embedding-3-large) is Ada’s replacement — newer, longer, trained on more data, more expensive. We’ll use it with the max length of 3,072. Is it worth the extra cost and computing power? Let’s find out.
Questions, code available on GitHub
There is spreadsheet of question responses, a Jupyter notebook, and text dataset of Presidential Wikipedia entries available here:
GitHub – nathanbos/blog_embeddings: Files to accompany Medium blog on embeddings
Download the text and Jupyter notebook if you want to build your own; mine runs well on Google Colab.
The Spreadsheet of questions
I recommend downloading the spreadsheet to understand these results. It shows the top 20 text chunks returned for each question, plus a number of variants and follow-ups. Follow the link and choose ‘Download’ like this:

To browse the questions and responses, I find it easiest to drag the text entry cell at the top larger, and tab through the responses to read the text chunks there, as in this screenshot.
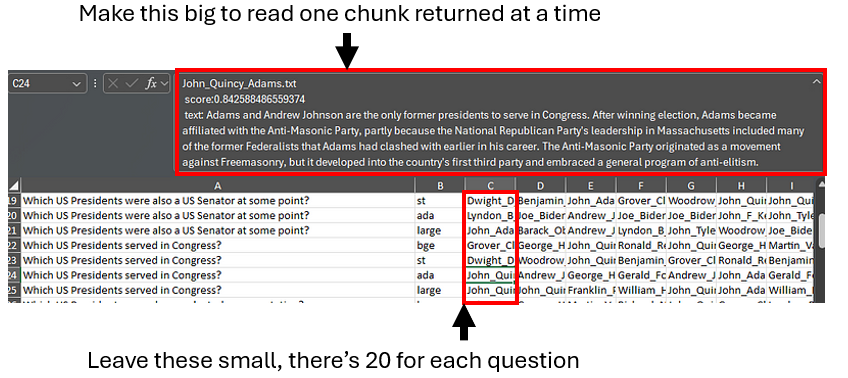
Not that this is the retrieved context only, there is no LLM synthesized response to these questions. The code has instructions for how to get those, using a query engine instead of just a retriever as I did.
Providing understanding that goes beyond leaderboards
We’re going to do something countercultural in this post: we’re going to focus on the actual results of individual question responses. This stands in contrast to current trends in LLM evaluation, which are about using larger and larger datasets and and presenting results aggregated to a higher and higher level. Corpus size matters a lot for training, but that is not as true for evaluation, especially if the goal is human understanding.
For aggregated evaluation of embedding search performance, consult the (very well implemented) HuggingFace leaderboard using the (excellent) MTEB dataset: https://huggingface.co/spaces/mteb/leaderboard.
Leaderboards are great for comparing performance broadly, but are not great for developing useful understanding. Most leaderboards do not publish actual question-by-question results, limiting what can be understood about those results. (They do usually provide code to re-run the tests yourself.) Leaderboards also tend to focus on tests that are roughly within the current technology’s abilities, which is reasonable if the goal is to compare current models, but does not help understand the limits of the state of the art. To develop usable understanding about what systems can and cannot do, I find there is no substitute for back-and-forth testing and close analysis of results.
What I’m presenting here is basically a pilot study. The next step would be to do the work of developing larger, precisely designed, understanding-focused test sets, then conduct iterative tests focused on deeper understanding of performance. This kind of study will likely only happen at scale when funding agencies and academic disciplines beyond computer science start caring about LLM interpretability. In the meantime, you can learn a lot just by asking.
Question: Which U.S. Presidents served in the Navy?
Let’s use the first question in my test set to illustrate the ‘black box’ method of using search to aid understanding.



The results:
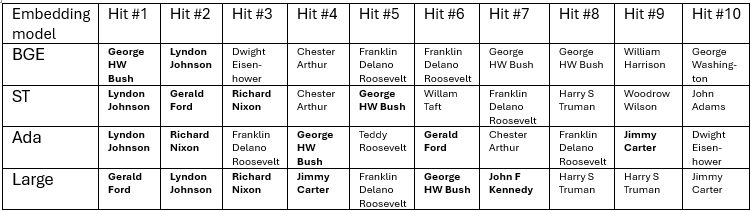
I gave the Navy question to each embedding index (database). Only one of the four embeddings, Large, was able to find all six Presidents who served in the Navy within the top ten hits. The table below shows the top 10 found passages from for each embedding model. See the spreadsheet for full text of the top 20. There are duplicate Presidents on the list, because each Wikipedia entry has been divided into many individual chunks, and any given search may find more than one from the same President.
Why were there so many incorrect hits? Let’s look at a few.
The first false hit from BGE is a chunk from Dwight D Eisenhower, an army general in WW2, that has a lot of military content but has nothing to do with the Navy. It appears that BGE does have some kind of semantic representation of ‘Navy’. BGE’s search was better than what you would get with a simple keyword matches on ‘Navy’, because it generalizes to other words that mean something similar. But it generalized too indiscriminately, and failed to differentiate Navy from general military topics, e.g. it does not consistently distinguish between the Navy and the Army. My friends in Annapolis would not be happy.
How did the two mid-level embedding models do? They seem to be clear on the Navy concept and can distinguish between the Navy and Army. But they each had many false hits on general naval topics; a section on Chester A Arthur’s naval modernization efforts shows up high on both lists. Other found sections have Presidential actions related to the Navy, or ships named after Presidents, like the U.S.S. Harry Truman.
The middle two embedding models seem to have a way to semantically represent ‘Navy’ but do not have a clear semantic representation of the concept ‘Served in the Navy’. This was enough to prevent either ST or Ada from finding all six Naval-serving Presidents in the top ten.
On this question, Large clearly outperforms the others, with six of the seven top hits corresponding to the six serving Presidents: Gerald Ford, Richard Nixon, Lyndon B. Johnson, Jimmy Carter, John F. Kennedy, and George H. W. Bush. Large appears to understand not just ‘Navy’ but ‘served in the Navy’.
What did Large get wrong?
What was the one mistake in Large? It was the chunk on Franklin Delano Roosevelt’s work as Assistant Secretary of the Navy. In this capacity, he was working for the Navy, but as a civilian employee, not in the Navy. I know from personal experience that the distinction between active duty and civilian employees can be confusing. The first time I did contract work for the military I was unclear on which of my colleagues were active duty versus civilian employees. A colleagues told me, in his very respectful military way, that this distinction was important, and I needed to get it straight, which I have since. (Another pro tip: don’t get the ranks confused.)
Question: Which U.S. Presidents worked as a civilian employees of the Navy?
In this question I probed to see whether the embeddings “understood” this distinction that I had at first missed: do they know how civilian employees of the Navy differs from people actually in the service? Both Roosevelts worked for the Navy in a civilian capacity. Theodore had also been in the Army (leading the charge of San Juan Hill), wrote books about the Navy, and built up the Navy as President, so there are many Navy-related chunks about TR, but he was never in the Navy. (Except as Commander in Chief; this role technically makes all Presidents part of the U.S. Navy, but that relationship did not affect search hits.)
The results of the civilian employee query can be seen in the results spreadsheet. The first hit for Large and second for Ada is a passage describing some of FDR’s work in the Navy, but this was partly luck because it included the word ‘civilian’ in a different context. Mentions were made of staff work by LBJ and Nixon, although it is clear from the passages that they were active duty at the time. (Some staff jobs can be filled by either military or civilian appointees.) Mention of Teddy Roosevelt’s civilian staff work did not show up at all, which would prevent an LLM from correctly answering the question based on these hits.
Overall there were only minor difference between the searches for Navy, “In the Navy” and “civilian employee”. Asking directly about active-duty Navy gave similar results. The larger embedding models had some correct associations, but overall could not make the necessary distinction well enough to answer the question.

Common Concepts
Question: Which U.S. Presidents were U.S. Senators before they were President?
All of the vectors seem to generally understand common concepts like this, and can give good results that an LLM could turn into an accurate response. The embeddings could also differentiate between the U.S. Senate and U.S. House of Representatives. They were clear on the difference between Vice President and President, the difference between a lawyer and a judge, and the general concept of an elected representative.
They also all did well when asked about Presidents who were artists, musicians, or poker players. They struggled a little with ‘author’ because there were so many false positives in the data relate to other authors.
More Specialized Concepts
As we saw, they each have their representational limits, which for Large was the concept of ‘civilian employee of the Navy.’ They also all did poorly on the distinction between national and state representatives.
Question: Which U.S. President served as elected representatives at the state level?
None of the models returned all, or even most of the Presidents who served in state legislatures. All of the models mostly returned hits relate to the U.S. House of Representatives, with some references to states or governors. Large’s first hit was on target: “Polk was elected to its state legislature in 1823”, but missed the rest. This topic could use some more probing, but in general this concept was a fail.
Question: Which US Presidents were not born in a US State?
All four embeddings returned Barack Obama as one of the top hits to this question. This is not factual — Hawaii was a state in 1961 when Obama was born there, but the misinformation is prevalent enough (thanks, Donald) to show up in the encoding. The Presidents who were born outside of the United States were the early ones, e.g. George Washington, because Virginia was not a state when he was born. This implied fact was not accessible via the embeddings. William Henry Harrison was returned in all cases, because his entry includes the passage “…he became the last United States president not born as an American citizen”, but none of the earlier President entries said this directly, so it was not found in the searches.
Search for specific, semi-famous people and places
Question: Which U.S. Presidents were asked to deliver a difficult message to John Sununu?

People who are old enough to have followed U.S. politics in the 1990s will remember this distinctive name: John Sununu was governor of New Hampshire, was a somewhat prominent political figure, and served as George H.W. Bush’s (Bush #1’s) chief of staff. But he isn’t mentioned in Bush #1’s entry. He is mentioned in a quirky offhand anecdote in the entry for George W. Bush (Bush #2) where Bush #1 asked Bush #2 to ask Sununu to resign. This was mentioned, I think, to illustrate one of Bush #2’s key strengths, likability, and the relationship between the two Bushes. A search for John Sununu, which would have been easy for a keyword search due to the unique name, fails to find this passage in three of the four embeddings. The one winner? Surprisingly, it is BGE, the underdog.
There was another interesting pattern: Large returned a number of hits on Bush #1, the President historically most associated with Sununu, even though he is never mentioned in the returned passages. This seems more than a coincidence; the embedding encoded some kind of association between Sununu and Bush #1 beyond what is stated in the text.
Which U.S. Presidents were criticized by Helen Prejean?

I observed the same thing with a second semi-famous name: Sister Helen Prejean was a moderately well-known critic of the death penalty; she wrote Dead Man Walking and Wikipedia briefly notes that she criticized Bush #2’s policies. None of the embeddings were able to find the Helen Prejean mention which, again, a keyword search would have found easily. Several of Large’s top hits are passages related to the death penalty, which seems like more than a coincidence. As with Sununu, Large appears to have some association with the name, even though it is not represented clearly enough in the embedding vocabulary to do an effective search for it.
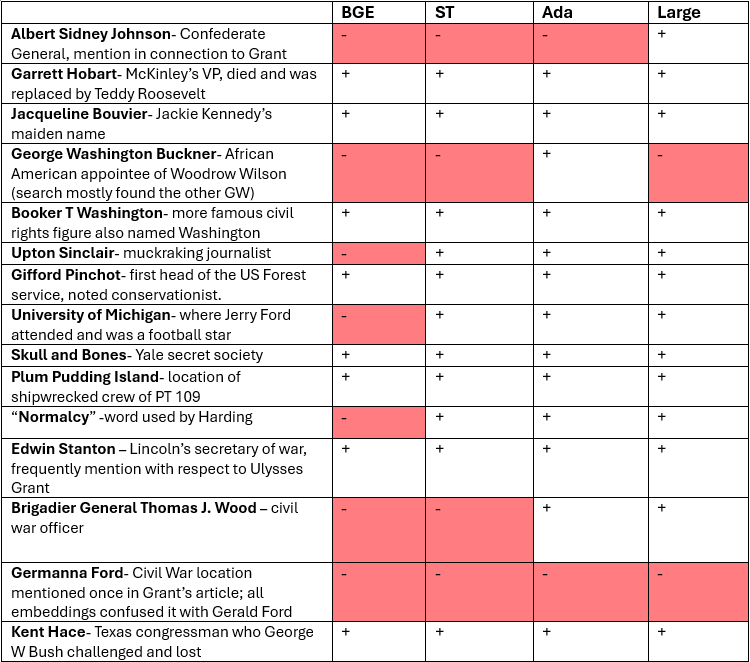
I tested a number of other specific names, places, and one weird word, ‘normalcy’, for the embedding models’ ability to encode and match them in the Wikipedia texts. The table below shows the hits and misses.
What does this tell us?
Language models encode more frequently-encountered names, i.e. more famous people, but are less likely to encode them the more infrequent they are. Larger embeddings, in general, encode more specific details. But there were cases here smaller models outperformed larger ones, and models also sometimes had to have some associations even with name that they cannot recognize well enough to find. A great follow up on this would be a more systematic study of how noun frequency affects representation in embeddings.
Tangent #1: Rhyming
This was a bit of a tangent but I had fun testing it. Large Language models cannot rhyme very well, because they neither speak or hear. Most humans learn to read aloud first, and learn to read silently only later. When we read silently, we can still subvocalize the words and ‘hear’ the rhymes in written verse as well. Language models do not do this. Theirs is a silent, text-only world. They know about rhyming only from reading about it, and never get very good at it. Embeddings could theoretically represent phonetics, and can usually give accurate phonetics for a given word. But I’ve been testing rhyming on and off since GPT-3, and LLMs usually can’t search on this. However, the embeddings surprised me a few times in this exercise.
Which President’s name rhymes with ‘Gimme Barter?’

This one turned out to be easy; all four vectors gave “Jimmy Carter” as the first returned hit. The cosine similarities were lowish, but since this was essentially a multiple choice test of Presidents, they all made the match easily. I think the spellings of Gimme Barter and Jimmy Carter are too similar, so let’s try some harder ones, with more carefully disguised rhymes that sound alike but have dissimilar spellings.
Which US President’s name rhymes with Laybramam Thinkin’?

This one was harder. Abraham Lincoln did not show up on BGE or ST’s top ten hits, but was #1 for Ada and #3 for Large.
Which US President’s names rhymes with Will-Ard Syl-Bor?
Millard Fillmore was a tough rhyme. It was #2 for Ada, #5 for Large, not in the top 10 for the others. The lack of Internet poetry about President Fillmore seems like a gap someone needs to fill. There were a lot of false hits for Bill Clinton, perhaps because of the double L’s?

And yet, this exists: https://www.classroompoems.com/millard-fillmore-poem.htm. Because it is the Internet.
Which US President’s name rhymes with Mayrolled Gored?
Gerald Ford was #7 for BGE , #4 for Ada, #5 for Large.
Rhyming was not covered at the Gerald R. Ford Presidential Museum in my hometown of Grand Rapids, Michigan. I would know, I visited it many times. More on that later.
Takeaway: the larger embedding schemes can rhyme, a little, although maybe less well than a human. How are they doing this, and what are the limits? Are they analyzing phonetics, taking advantage of existing rhyming content, or making good guesses another way? I have no idea. Phonetic encoding in embedding systems seems like a fine thesis topic for some enterprising linguistics student, or maybe a very nerdy English Lit major.
Embedding can’t do Booleans: no NOT, AND, or OR
Simple semantic search cannot do some basic operations the keyword query systems generally can, and are not good at searching for sequences of events.
Question: Which Presidents were NOT Vice President first?
Doing a vector search with ‘NOT’ is similar to the old adage about telling someone not to think about a Pink Elephant — saying the phrase usually causes the person to do so. Embeddings have no representation of ‘Not Vice President’, they only have Vice President.

The vector representing the question will contain both “President” and “Vice President” and tend to find chunks with both. One could try to kludge a compound query, searching first for all President, then all Vice Presidents, and subtract, but the limit on contexts returned would prevent returning all of the first list, and is not guaranteed to get all of the second. Boolean search with embeddings remains a problem.
Question: Which U.S. President was NOT elected as vice President and NEVER elected as President?
An exception the the ‘NOT’ fail: all of the embeddings could find the passage saying that Gerald Ford was the only President that was never elected to be Vice President (appointed when Spiro Agnew resigned) or President (took Nixon’s place when he resigned, lost the re-election race to Jimmy Carter.) They were able to find this because the ‘not’ was explicitly represented in the text, with no inference needed, and it is also a well-known fact about Ford.
Why is there a double negative in this question?
The unnecessary double negative in the prior question made this search better. A search on “Which U.S. President was not elected as either Vice President or President?” gave poorer results. I added the double negative wording as a hunch that the double negatives would have a compound effect of making the query more both negative and make it easier to connect the ‘not’ to both offices. This does not make grammatical sense but does make sense in the world of superimposed semantics.
Gerald R. Ford’s many accomplishments
People who have visited the Gerald R. Ford Presidential museum in my hometown of Grand Rapids, Michigan, a sufficient number of times will be aware that Ford made many important contributions despite not being elected to the highest offices. Just putting that out there.

Question: Which Presidents were President AND Vice President?
Semantic search has a sort of weak AND, more like an OR, but neither is a logical Boolean query. Embeddings do not link concepts with strict logic. Instead, think of them as superimposing concepts on top of each other on the same vector. This query would find chunks that load strongly on President (which is most of them in this dataset) and Vice President, but does not enforce the logical AND in any way. In this dataset it gives some correct hits, and a lot of extraneous mentions of Vice Presidents. This search for superimposed concepts is not a true logical OR either.
Embeddings and sequences of actions
Do embeddings connect concepts sequentially well enough to search on these sequences? My going-in assumption was that they cannot, but the embeddings did better than expected.
Humans have a specific types of memory for sequence, called episodic memory. Stories are an important type of information for us; we encode things like personal history, social information and also useful lessons as stories. We can also recognize stories similar to ones that we already know. We can read a story about a hero who fails because of his fatal flaw, or an ordinary person who rises to great heights, and recognize not just the concepts but the sequence of actions. In my previous blog post on RAG search using Aesop’s Fables, the RAG system did not seem to have any ability to search on sequences of actions. I expected a similar failure here, but the results were a little different.
Question: Which US Presidents served in Congress after being President?
There were many Presidents who served in congress before being President, but only two who served in congress after being President. All of the Embeddings returned a passage from John Quincy Adams, which directly gives the answer, as a top hit: Adams and Andrew Johnson are the only former presidents to serve in Congress. All of them also separately found entries for Andrew Johnson in the top 10. There were a number of false hits, but the critical information was there.
The embeddings did not do as well on the follow-ups, like Which US Presidents served as judges after being President? But all did find mention of Taft, who notably was the only person to serve as chief justice and president.
Does this really represent successfully searching on a sequence? Possibly not; in these cases the sequence may be encapsulated in a single searchable concept, like “former President”. I still suspect that embeddings would badly underperform humans on more difficult story-based searches. But this is a subtle point that would require more analysis.
What about causal connections?
Causal reasoning is such an important part of human reasoning that I wanted to separately test whether causal linkages are clearly represented and searchable. I tested these with two paired queries that had the causality reversed, and looked both at which search hits were returned, and how the pairs different. Both question pairs were quite interesting and results are shown in the spreadsheet; I will focus on this one:
Question: When did a President’s action cause an important world event? -vs- When did an important world event cause a President’s action?
ST failed this test, it returned exactly the same hits in the same order for both queries. The causal connection was not represented clearly enough to affect the search.
All of the embeddings returned multiple chunks related to Presidential world travel, weirdly failing to separate traveling from official actions.
None of the embeddings did well on the causal reversal. Every one had hits where world events coincided with Presidential actions, often very minor actions, with no causal link in either direction. There all had false hits where the logical linkage went in the wrong directions (Presidents causing events vs responding to events). There were multiple example of commentators calling out Presidential inaction, which suggests that ‘act’ and ‘not act’ are conflated. Causal language, especially the word ‘cause’ triggered a lot of matches, even when it was not attached to a Presidential action or world event.
A deeper exploration of how embeddings represent causality, maybe in a critical domain like medicine, would be in order. What I observed is a lack of evidence that embeddings represent and correctly use causality.
Analogies
Question: Which U.S. Presidents were similar to Simon Bolivar, and how?
Simon Bolivar, revolutionary leader and later political leader in South America, is sometimes called the “George Washington of South America”. Could the embedding models perceive this analogy in the other direction?
- BGE- Gave a very weird set of returned context, with no obvious connection besides some mentions of Central/ South American.
- ST- Found a passage about William Henry Harrison’s 1828 trip to Colombia and feuding with Bolivar, and other mentions of Latin America, but made no abstract matches.
- Ada- Found the Harrison passage + South America references, but no abstract matches that I can tell.
- Large- Returned George Washington as hit #5 behind Bolivar/ S America hits.
Large won this test in a landslide. This hit shows the clearest pattern of larger/better vectors outperforming others at abstract comparisons.


Abstract concepts
I tested a number of searches on more abstract concepts. Here are two examples:
Questions: Which US Presidents exceeded their power?
BGE: top hit: “In surveys of U.S. scholars ranking presidents conducted since 1948, the top three presidents are generally Lincoln, Washington, and Franklin Delano Roosevelt, although the order varies.” BGE found hits all related to Presidential noteworthiness, especially rankings by historians, I think keying on the words ‘power’ and ‘exceed’. This was a miss.
ST: “Roosevelt is widely considered to be one of the most important figures in the history of the United States.” Same patterns as BGE; a miss.
Ada: Ada’s hits were all on the topic of Presidential power, not just prestige, and so were more on-target than the smaller models. There is a common theme of increasing power, and some passages that imply exceeding, like this one: the Patriot Act “increased authority of the executive branch at the expense of judicial opinion…” Overall, not a clear win, but closer.
Large: It did not find the best 10 passages, but the hits were more on target. All had the concept of increasing Presidential power, and most has a flavor of exceeding some previous limit, e.g. “conservative columnist George Will wrote in The Washington Post that Theodore Roosevelt and Wilson were the “progenitors of today’s imperial presidency”
Again, there was a pattern of larger models having more precise, on-target abstractions. Large was the only one to get close to a correct representation of a President “exceeding their power” but even this performance left a lot of room for improvement.
Embeddings do not understand subtext
Subtext is meaning in a text that is not directly stated. People add meaning to what they read, making emotional associations, or recognizing related concepts that go beyond what is directly stated, but embeddings do this only in a very limited way.
Question: Give an example of a time when a U.S. President expressed frustration with losing an election?
In 1960, then-Vice President Richard Nixon lost a historically close election to John F Kennedy. Deeply hurt by the loss, Nixon decided to settle to return home to his home state of California and ran for governor in 1962. Nixon lost that race too. He famously announced at a press conference, “You don’t (won’t) have Nixon to kick around anymore because, gentlemen, this is my last press conference,” thus ending his political career, or so everyone thought.

What happens when you search for: “Give an example of a time when a U.S. President expressed frustration with losing an election”? None of the embeddings return this Nixon quote. Why? Because Wikipedia never directly states that he was frustrated, or had any other specific emotion; that is all subtext. When a mature human reads “You won’t have Nixon to kick around anymore”, we recognize some implied emotions, probably without consciously trying to do so. This might be so automatic when reading that one thinks it is in the text. But in his passage the emotion is never directly stated. And if it is subtext, not text, an embedding will (probably) not be able to represent it or be able to search it.
Wikipedia avoids speculating on emotional subtext as a part of fact-based reporting. Using subtext instead of text is also considered good tradecraft for fiction writers, even when the goal is to convey strong emotions. A common piece of advice for new writers is, “show, don’t tell.” Skilled writers reveal what characters are thinking and feeling without directly stating it. There’s even a name for pedantic writing that explains things too directly, it is called “on-the-nose dialogue”.
But “show, don’t tell” makes some content invisible to embeddings, and thus to vector-based RAG retrieval systems. This presents some fundamental barriers to what can be found in RAG system in the domain of emotional subtext, but also other layers of meaning that go beyond what is directly stated. I also did a lot of probing around concepts like Presidential mistakes, Presidential intentions, and analytic patterns that are just beyond what is directly stated in the text. Embedding-based search generally failed on this, mostly returning only direct statements, even when they were not relevant.
Why are embeddings shallow compared to Large Language Models?
Large Language Models like Claude and GPT-4 have the ability to understand subtext; they do a credible job explaining stories, jokes, poetry and Taylor Swift song lyrics. So why can’t embeddings do this?
Language models are comprised of layers, and in general the lower layers are shallower forms of processing, representing aspects like grammar and surface meanings, while higher level of abstraction occur in higher layers. Embeddings are the first stage in language model processing; they convert text into numbers and then let the LLM take over. This is the best explanation I know of for why the embedding search tests seem to plateau at shallower levels of semantic matching.
Embedding were not originally designed for RAGs; using them for semantic search is a clever, but ultimately limited secondary usage. That is changing, as embedding systems are being optimized for search. BGE was to some extend optimized for search, and ST was designed for sentence comparison; I would say this is why both BGE and ST were not too far behind Ada and Large despite being a fraction of the size. Large was probably designed with search in mind to a limited extent. But it was easy to push each of them to their semantic limits, as compared with the kind of semantics processed by full large language models.
Conclusion
What did we learn, conceptually, about embeddings in his exercise?
The embedding models, overall, surprised me on a few things. The semantic depth was less than I expected, based on the performance of the language models that use them. But they outperformed my expectations on a few things I expected them to fail completely at, like rhyming and searching for sequenced activities. This activity piqued my interest in probing some more specific areas; perhaps it did for you as well.
For RAG developers, this illuminated some of the specific ways that larger models may outperform smaller ones, including the precisions of their representation, the breadth of knowledge and the range of abstractions. As a sometime RAG builder, I have been skeptical that paying more for embeddings would lead to better performance, but this exercise convinced me that embedding choice can make a difference for some applications.
Embeddings systems will continue to incrementally improve, but I think some fundamental breakthroughs will be needed in this area. There is some current research on innovations like universal text embeddings.
Knowledge graphs are a popular current way to supplement semantic search. Graphs are good for making cross-document connections, but the LLM-derived graphs I have seen are semantically quite shallow. To get semantic depth from a knowledge graph probably requires a professionally-developed ontology to be available to serve as a starting point; these are available for some specialized fields.
My own preferred method is to improve text with more text. Since full language models can perceive and understand meaning that is not in embeddings, why not have a language model pre-process and annotate the text in your corpus with the specific types of semantics you are interested in? This might be too expensive for truly huge datasets, but for data in the small to medium range it can be an excellent solution.
I experimented with adding annotations to the Presidential dataset. To make emotional subtext searchable I had GPT4o write narratives for each President highlighting the personal and emotional content. These annotations were added back into the corpus. They are not great prose, but the concept worked. GPT’s annotation of the Nixon entry included the sentence: “The defeat was a bitter pill to swallow, compounded by his loss in the 1962 California gubernatorial race. In a moment of frustration, Nixon declared to the press, ‘You won’t have Nixon to kick around anymore,’ signaling what many believed to be the end of his political career”. This effectively turned subtext into text, making is searchable.
I experimented with a number of types of annotations. One that I was particularly happy used Claude to examine each Presidency and make comments on underlying system dynamical phenomena like delayed feedback and positive feedback loops. Searching on these terms on the original text gave nothing useful, but greatly improved with annotations. Claude’s analyses were not brilliant, or even always correct, but it found and annotated enough decent examples that searches using system dynamic language found useful content.


Embeddings Are Kind of Shallow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Embeddings Are Kind of Shallow