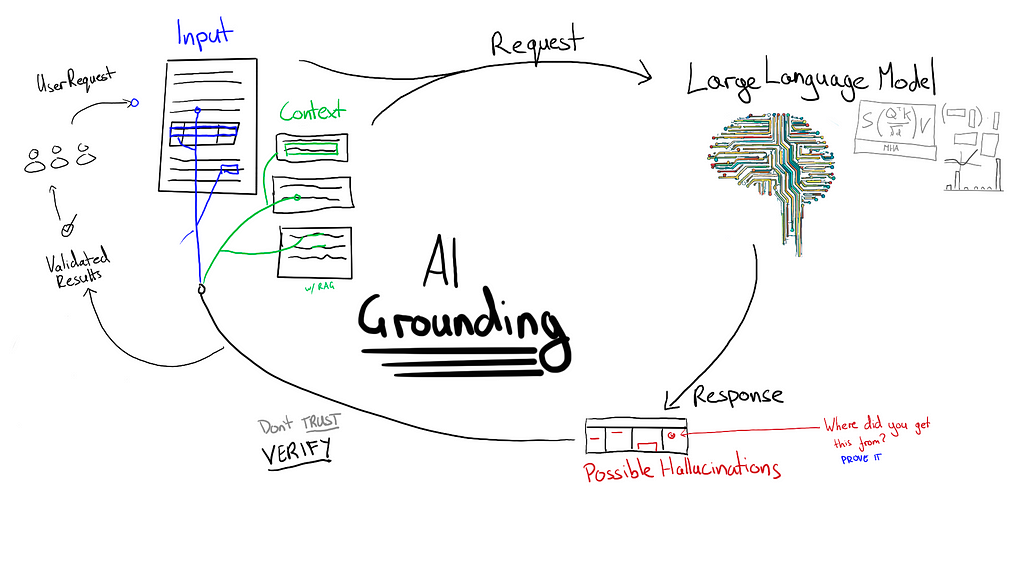
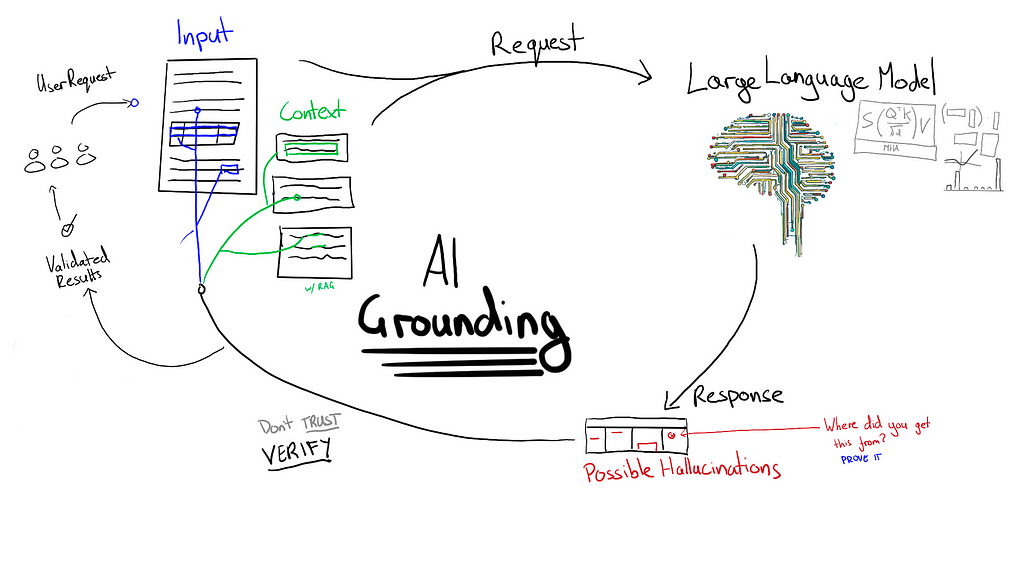
And the difference between weak vs strong grounding
I work as an AI Engineer in a particular niche: document automation and information extraction. In my industry using Large Language Models has presented a number of challenges when it comes to hallucinations. Imagine an AI misreading an invoice amount as $100,000 instead of $1,000, leading to a 100x overpayment. When faced with such risks, preventing hallucinations becomes a critical aspect of building robust AI solutions. These are some of the key principles I focus on when designing solutions that may be prone to hallucinations.
Using validation rules and “human in the loop”
There are various ways to incorporate human oversight in AI systems. Sometimes, extracted information is always presented to a human for review. For instance, a parsed resume might be shown to a user before submission to an Applicant Tracking System (ATS). More often, the extracted information is automatically added to a system and only flagged for human review if potential issues arise.
A crucial part of any AI platform is determining when to include human oversight. This often involves different types of validation rules:
1. Simple rules, such as ensuring line-item totals match the invoice total.
2. Lookups and integrations, like validating the total amount against a purchase order in an accounting system or verifying payment details against a supplier’s previous records.
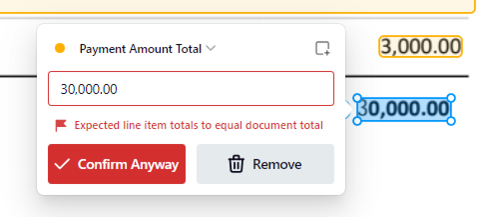
These processes are a good thing. But we also don’t want an AI that constantly triggers safeguards and forces manual human intervention. Hallucinations can defeat the purpose of using AI if it’s constantly triggering these safeguards.
Small Language Models
One solution to preventing hallucinations is to use Small Language Models (SLMs) which are “extractive”. This means that the model labels parts of the document and we collect these labels into structured outputs. I recommend trying to use a SLMs where possible rather than defaulting to LLMs for every problem. For example, in resume parsing for job boards, waiting 30+ seconds for an LLM to process a resume is often unacceptable. For this use case we’ve found an SLM can provide results in 2–3 seconds with higher accuracy than larger models like GPT-4o.
An example from our pipeline
In our startup a document can be processed by up to 7 different models — only 2 of which might be an LLM. That’s because an LLM isn’t always the best tool for the job. Some steps such as Retrieval Augmented Generation rely on a small multimodal model to create useful embeddings for retrieval. The first step — detecting whether something is even a document — uses a small and super-fast model that achieves 99.9% accuracy. It’s vital to break a problem down into small chunks and then work out which parts LLMs are best suited for. This way, you reduce the chances of hallucinations occurring.
Distinguishing Hallucinations from Mistakes
I make a point to differentiate between hallucinations (the model inventing information) and mistakes (the model misinterpreting existing information). For instance, selecting the wrong dollar amount as a receipt total is a mistake, while generating a non-existent amount is a hallucination. Extractive models can only make mistakes, while generative models can make both mistakes and hallucinations.
Risk tolerance and Grounding
When using generative models we need some way of eliminating hallucinations.
Grounding refers to any technique which forces a generative AI model to justify its outputs with reference to some authoritative information. How grounding is managed is a matter of risk tolerance for each project.
For example — a company with a general-purpose inbox might look to identify action items. Usually, emails requiring actions are sent directly to account managers. A general inbox that’s full of invoices, spam, and simple replies (“thanks”, “OK”, etc.) has far too many messages for humans to check. What happens when actions are mistakenly sent to this general inbox? Actions regularly get missed. If a model makes mistakes but is generally accurate it’s already doing better than doing nothing. In this case the tolerance for mistakes/hallucinations can be high.
Other situations might warrant particularly low risk tolerance — think financial documents and “straight-through processing”. This is where extracted information is automatically added to a system without review by a human. For example, a company might not allow invoices to be automatically added to an accounting system unless (1) the payment amount exactly matches the amount in the purchase order, and (2) the payment method matches the previous payment method of the supplier.
Even when risks are low, I still err on the side of caution. Whenever I’m focused on information extraction I follow a simple rule:
If text is extracted from a document, then it must exactly match text found in the document.
This is tricky when the information is structured (e.g. a table) — especially because PDFs don’t carry any information about the order of words on a page. For example, a description of a line-item might split across multiple lines so the aim is to draw a coherent box around the extracted text regardless of the left-to-right order of the words (or right-to-left in some languages).
Forcing the model to point to exact text in a document is “strong grounding”. Strong grounding isn’t limited to information extraction. E.g. customer service chat-bots might be required to quote (verbatim) from standardised responses in an internal knowledge base. This isn’t always ideal given that standardised responses might not actually be able to answer a customer’s question.
Another tricky situation is when information needs to be inferred from context. For example, a medical assistant AI might infer the presence of a condition based on its symptoms without the medical condition being expressly stated. Identifying where those symptoms were mentioned would be a form of “weak grounding”. The justification for a response must exist in the context but the exact output can only be synthesised from the supplied information. A further grounding step could be to force the model to lookup the medical condition and justify that those symptoms are relevant. This may still need weak grounding because symptoms can often be expressed in many ways.
Grounding for complex problems
Using AI to solve increasingly complex problems can make it difficult to use grounding. For example, how do you ground outputs if a model is required to perform “reasoning” or to infer information from context? Here are some considerations for adding grounding to complex problems:
- Identify complex decisions which could be broken down into a set of rules. Rather than having the model generate an answer to the final decision have it generate the components of that decision. Then use rules to display the result. (Caveat — this can sometimes make hallucinations worse. Asking the model multiple questions gives it multiple opportunities to hallucinate. Asking it one question could be better. But we’ve found current models are generally worse at complex multi-step reasoning.)
- If something can be expressed in many ways (e.g. descriptions of symptoms), a first step could be to get the model to tag text and standardise it (usually referred to as “coding”). This might open opportunities for stronger grounding.
- Set up “tools” for the model to call which constrain the output to a very specific structure. We don’t want to execute arbitrary code generated by an LLM. We want to create tools that the model can call and give restrictions for what’s in those tools.
- Wherever possible, include grounding in tool use — e.g. by validating responses against the context before sending them to a downstream system.
- Is there a way to validate the final output? If handcrafted rules are out of the question, could we craft a prompt for verification? (And follow the above rules for the verified model as well).
Key Takeaways
- When it comes to information extraction, we don’t tolerate outputs not found in the original context.
- We follow this up with verification steps that catch mistakes as well as hallucinations.
- Anything we do beyond that is about risk assessment and risk minimisation.
- Break complex problems down into smaller steps and identify if an LLM is even needed.
- For complex problems use a systematic approach to identify verifiable task:
— Strong grounding forces LLMs to quote verbatim from trusted sources. It’s always preferred to use strong grounding.
— Weak grounding forces LLMs to reference trusted sources but allows synthesis and reasoning.
— Where a problem can be broken down into smaller tasks use strong grounding on tasks where possible.
Affinda AI Platform
We’ve built a powerful AI document processing platform used by organisations around the world.
About the Author
I’m the Lead AI Engineer @ Affinda. I spent 10 years making a career change from UX to AI. Looking for a more in-depth understanding of generative AI? Read my deep dive: what Large Language Models actually understand.
How I Deal with Hallucinations at an AI Startup was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How I Deal with Hallucinations at an AI Startup
Go Here to Read this Fast! How I Deal with Hallucinations at an AI Startup