Elevating RAG accuracy and performance by structuring long documents into explorable graphs and implementing graph-based agent systems

Large Language Models (LLMs) are great at traditional NLP tasks like summarization and sentiment analysis but the stronger models also demonstrate promising reasoning abilities. LLM reasoning is often understood as the ability to tackle complex problems by formulating a plan, executing it, and assessing progress at each step. Based on this evaluation, they can adapt by revising the plan or taking alternative actions. The rise of agents is becoming an increasingly compelling approach to answering complex questions in RAG applications.
In this blog post, we’ll explore the implementation of the GraphReader agent. This agent is designed to retrieve information from a structured knowledge graph that follows a predefined schema. Unlike the typical graphs you might see in presentations, this one is closer to a document or lexical graph, containing documents, their chunks, and relevant metadata in the form of atomic facts.
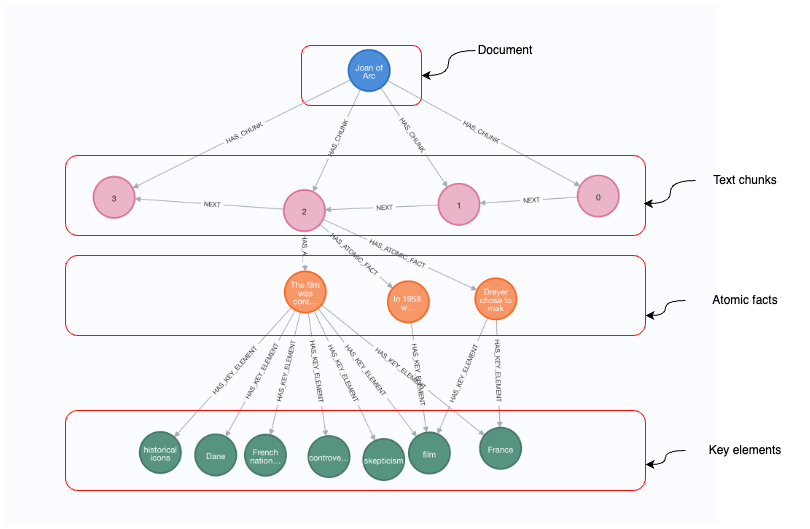
The image above illustrates a knowledge graph, beginning at the top with a document node labeled Joan of Arc. This document is broken down into text chunks, represented by numbered circular nodes (0, 1, 2, 3), which are connected sequentially through NEXT relationships, indicating the order in which the chunks appear in the document. Below the text chunks, the graph further breaks down into atomic facts, where specific statements about the content are represented. Finally, at the bottom level of the graph, we see the key elements, represented as circular nodes with topics like historical icons, Dane, French nation, and France. These elements act as metadata, linking the facts to the broader themes and concepts relevant to the document.
Once we have constructed the knowledge graph, we will follow the implementation provided in the GraphReader paper.
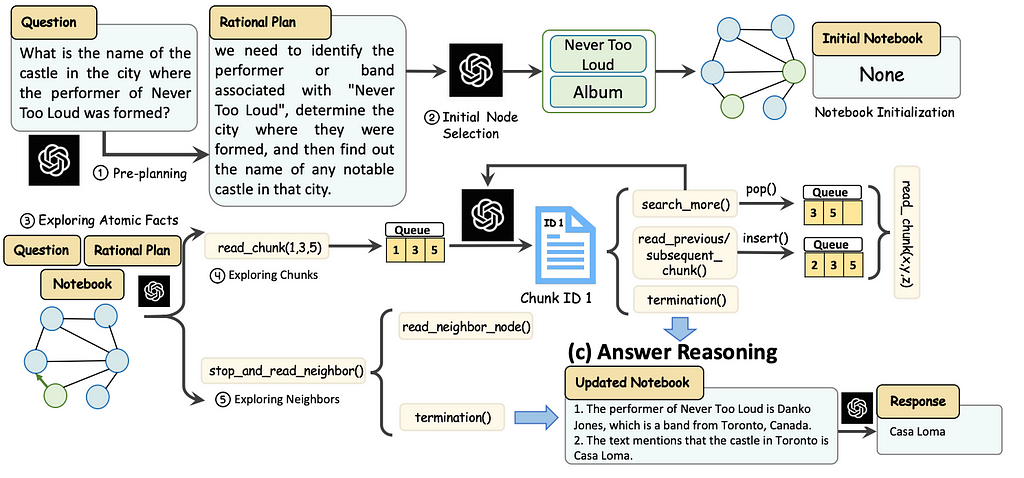
The agent exploration process involves initializing the agent with a rational plan and selecting initial nodes to start the search in a graph. The agent explores these nodes by first gathering atomic facts, then reading relevant text chunks, and updating its notebook. The agent can decide to explore more chunks, neighboring nodes, or terminate based on gathered information. When the agent decided to terminate, the answer reasoning step is executed to generate the final answer.
In this blog post, we will implement the GraphReader paper using Neo4j as the storage layer and LangChain in combination with LangGraph to define the agent and its flow.
The code is available on GitHub.
Environment Setup
You need to setup a Neo4j to follow along with the examples in this blog post. The easiest way is to start a free instance on Neo4j Aura, which offers cloud instances of Neo4j database. Alternatively, you can also setup a local instance of the Neo4j database by downloading the Neo4j Desktop application and creating a local database instance.
The following code will instantiate a LangChain wrapper to connect to Neo4j Database.
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
graph = Neo4jGraph(refresh_schema=False)
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (c:Chunk) REQUIRE c.id IS UNIQUE")
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (c:AtomicFact) REQUIRE c.id IS UNIQUE")
graph.query("CREATE CONSTRAINT IF NOT EXISTS FOR (c:KeyElement) REQUIRE c.id IS UNIQUE")
Additionally, we have also added constraints for the node types we will be using. The constraints ensure faster import and retrieval performance.
Additionally, you will require an OpenAI api key that you pass in the following code:
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Graph construction
We will be using the Joan of Arc Wikipedia page in this example. We will use LangChain built-in utility to retrieve the text.
wikipedia = WikipediaQueryRun(
api_wrapper=WikipediaAPIWrapper(doc_content_chars_max=10000)
)
text = wikipedia.run("Joan of Arc")
As mentioned before, the GraphReader agent expects knowledge graph that contains chunks, related atomic facts, and key elements.

First, the document is split into chunks. In the paper they maintained paragraph structure while chunking. However, that is hard to do in a generic way. Therefore, we will use naive chunking here.
Next, each chunk is processed by the LLM to identify atomic facts, which are the smallest, indivisible units of information that capture core details. For instance, from the sentence “The CEO of Neo4j, which is in Sweden, is Emil Eifrem” an atomic fact could be broken down into something like “The CEO of Neo4j is Emil Eifrem.” and “Neo4j is in Sweden.” Each atomic fact is focused on one clear, standalone piece of information.
From these atomic facts, key elements are identified. For the first fact, “The CEO of Neo4j is Emil Eifrem,” the key elements would be “CEO,” “Neo4j,” and “Emil Eifrem.” For the second fact, “Neo4j is in Sweden,” the key elements would be “Neo4j” and “Sweden.” These key elements are the essential nouns and proper names that capture the core meaning of each atomic fact.
The prompt used to extract the graph are provided in the appendix of the paper.

The authors used prompt-based extraction, where you instruct the LLM what it should output and then implement a function that parses the information in a structured manner. My preference for extracting structured information is to use the with_structured_output method in LangChain, which utilizes the tools feature to extract structured information. This way, we can skip defining a custom parsing function.
Here is the prompt that we can use for extraction.
construction_system = """
You are now an intelligent assistant tasked with meticulously extracting both key elements and
atomic facts from a long text.
1. Key Elements: The essential nouns (e.g., characters, times, events, places, numbers), verbs (e.g.,
actions), and adjectives (e.g., states, feelings) that are pivotal to the text’s narrative.
2. Atomic Facts: The smallest, indivisible facts, presented as concise sentences. These include
propositions, theories, existences, concepts, and implicit elements like logic, causality, event
sequences, interpersonal relationships, timelines, etc.
Requirements:
#####
1. Ensure that all identified key elements are reflected within the corresponding atomic facts.
2. You should extract key elements and atomic facts comprehensively, especially those that are
important and potentially query-worthy and do not leave out details.
3. Whenever applicable, replace pronouns with their specific noun counterparts (e.g., change I, He,
She to actual names).
4. Ensure that the key elements and atomic facts you extract are presented in the same language as
the original text (e.g., English or Chinese).
"""
construction_human = """Use the given format to extract information from the
following input: {input}"""
construction_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
construction_system,
),
(
"human",
(
"Use the given format to extract information from the "
"following input: {input}"
),
),
]
)
We have put the instruction in the system prompt, and then in the user message we provide relevant text chunks that need to be processed.
To define the desired output, we can use the Pydantic object definition.
class AtomicFact(BaseModel):
key_elements: List[str] = Field(description="""The essential nouns (e.g., characters, times, events, places, numbers), verbs (e.g.,
actions), and adjectives (e.g., states, feelings) that are pivotal to the atomic fact's narrative.""")
atomic_fact: str = Field(description="""The smallest, indivisible facts, presented as concise sentences. These include
propositions, theories, existences, concepts, and implicit elements like logic, causality, event
sequences, interpersonal relationships, timelines, etc.""")
class Extraction(BaseModel):
atomic_facts: List[AtomicFact] = Field(description="List of atomic facts")
We want to extract a list of atomic facts, where each atomic fact contains a string field with the fact, and a list of present key elements. It is important to add description to each element to get the best results.
Now we can combine it all in a chain.
model = ChatOpenAI(model="gpt-4o-2024-08-06", temperature=0.1)
structured_llm = model.with_structured_output(Extraction)
construction_chain = construction_prompt | structured_llm
To put it all together, we’ll create a function that takes a single document, chunks it, extracts atomic facts and key elements, and stores the results into Neo4j.
async def process_document(text, document_name, chunk_size=2000, chunk_overlap=200):
start = datetime.now()
print(f"Started extraction at: {start}")
text_splitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
texts = text_splitter.split_text(text)
print(f"Total text chunks: {len(texts)}")
tasks = [
asyncio.create_task(construction_chain.ainvoke({"input":chunk_text}))
for index, chunk_text in enumerate(texts)
]
results = await asyncio.gather(*tasks)
print(f"Finished LLM extraction after: {datetime.now() - start}")
docs = [el.dict() for el in results]
for index, doc in enumerate(docs):
doc['chunk_id'] = encode_md5(texts[index])
doc['chunk_text'] = texts[index]
doc['index'] = index
for af in doc["atomic_facts"]:
af["id"] = encode_md5(af["atomic_fact"])
# Import chunks/atomic facts/key elements
graph.query(import_query,
params={"data": docs, "document_name": document_name})
# Create next relationships between chunks
graph.query("""MATCH (c:Chunk) WHERE c.document_name = $document_name
WITH c ORDER BY c.index WITH collect(c) AS nodes
UNWIND range(0, size(nodes) -2) AS index
WITH nodes[index] AS start, nodes[index + 1] AS end
MERGE (start)-[:NEXT]->(end)
""",
params={"document_name":document_name})
print(f"Finished import at: {datetime.now() - start}")
At a high level, this code processes a document by breaking it into chunks, extracting information from each chunk using an AI model, and storing the results in a graph database. Here’s a summary:
- It splits the document text into chunks of a specified size, allowing for some overlap. The chunk size of 2000 tokens is used by the authors in the paper.
- For each chunk, it asynchronously sends the text to an LLM for extraction of atomic facts and key elements.
- Each chunk and fact is given a unique identifier using an md5 encoding function.
- The processed data is imported into a graph database, with relationships established between consecutive chunks.
We can now run this function on our Joan of Arc text.
await process_document(text, "Joan of Arc", chunk_size=500, chunk_overlap=100)
We used a smaller chunk size because it’s a small document, and we want to have a couple of chunks for demonstration purposes. If you explore the graph in Neo4j Browser, you should see a similar visualization.
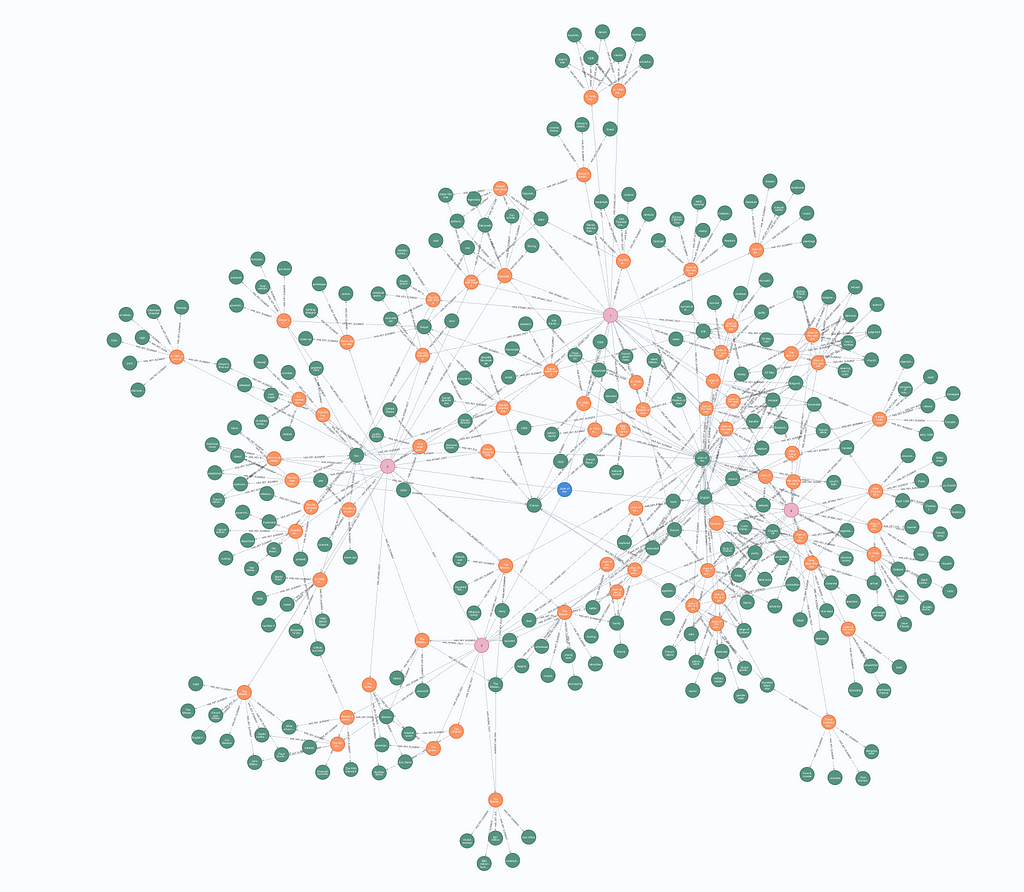
At the center of the structure is the document node (blue), which branches out to chunk nodes (pink). These chunk nodes, in turn, are linked to atomic facts (orange), each of which connects to key elements (green).
Let’s examine the constructed graph a bit. We’ll start of by examining the token count distribution of atomic facts.
def num_tokens_from_string(string: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model("gpt-4")
num_tokens = len(encoding.encode(string))
return num_tokens
atomic_facts = graph.query("MATCH (a:AtomicFact) RETURN a.text AS text")
df = pd.DataFrame.from_records(
[{"tokens": num_tokens_from_string(el["text"])} for el in atomic_facts]
)
sns.histplot(df["tokens"])
Results
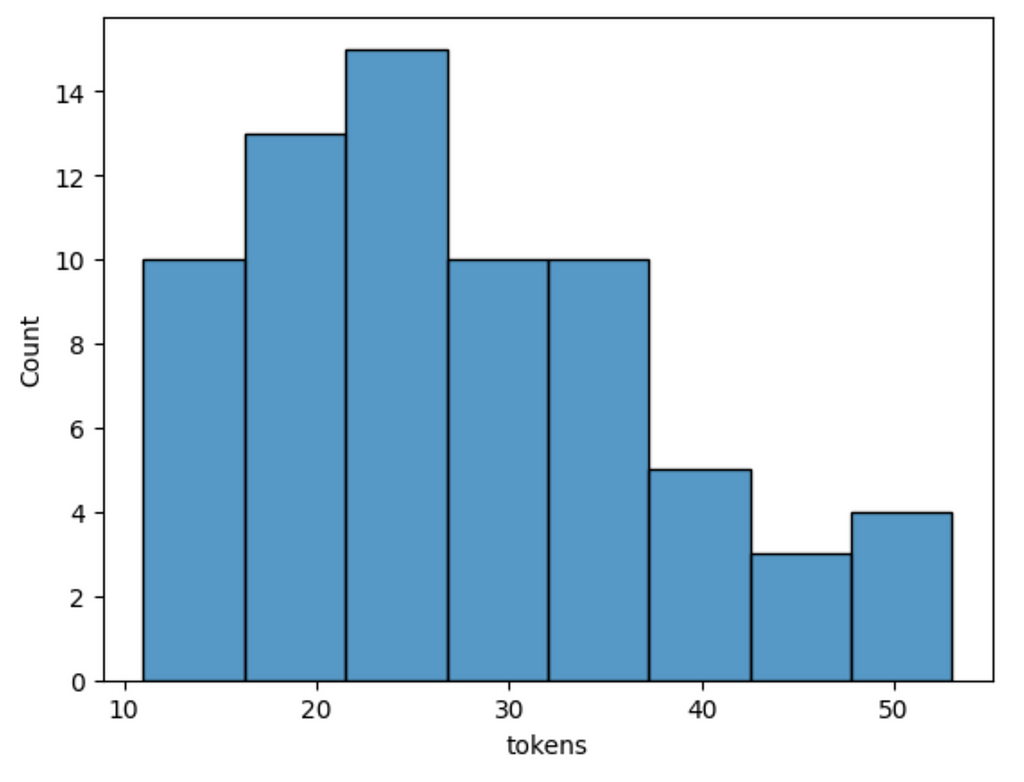
Atomic facts are relatively short, with the longest being only about 50 tokens. Let’s examine a couple to get a better idea.
graph.query("""MATCH (a:AtomicFact)
RETURN a.text AS text
ORDER BY size(text) ASC LIMIT 3
UNION ALL
MATCH (a:AtomicFact)
RETURN a.text AS text
ORDER BY size(text) DESC LIMIT 3""")
Results

Some of the shortest facts lack context. For example, the original score and screenplay don’t directly mention which. Therefore, if we processed multiple documents, these atomic facts might be less helpful. This lack of context might be solved with additional prompt engineering.
Let’s also examine the most frequent keywords.
data = graph.query("""
MATCH (a:KeyElement)
RETURN a.id AS key,
count{(a)<-[:HAS_KEY_ELEMENT]-()} AS connections
ORDER BY connections DESC LIMIT 5""")
df = pd.DataFrame.from_records(data)
sns.barplot(df, x='key', y='connections')
Results
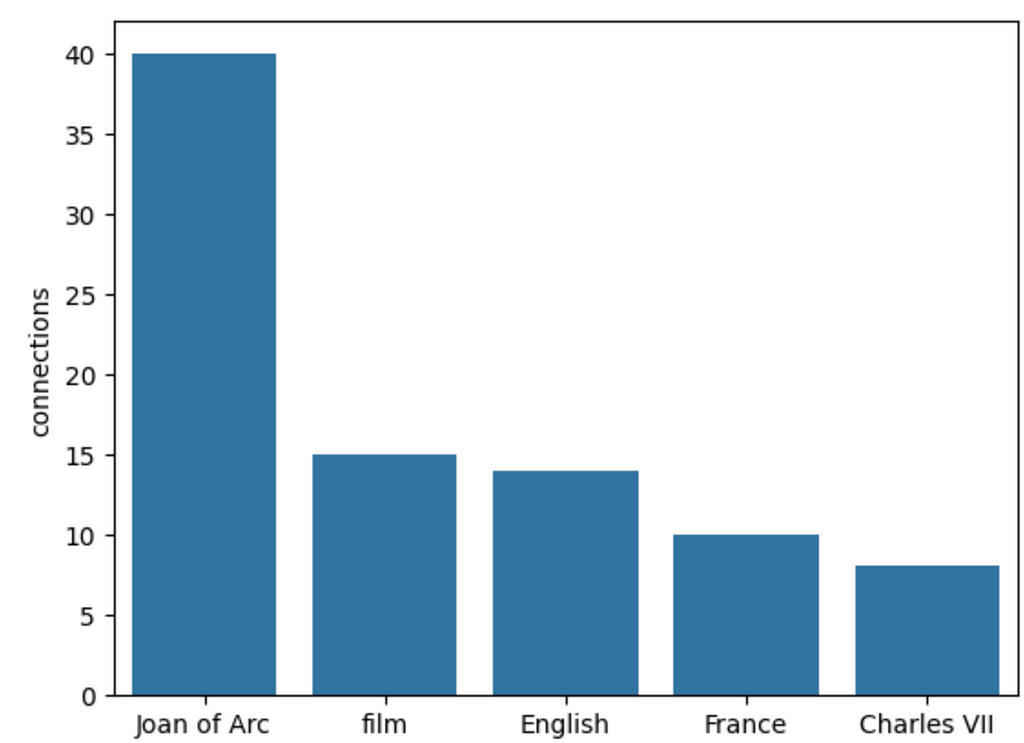
Unsurprisingly, Joan of Arc is the most mentioned keyword or element. Following are broad keywords like film, English, and France. I suspect that if we parsed many documents, broad keywords would end up having a lot of connections, which might lead to some downstream problems that aren’t dealt with in the original implementation. Another minor problem is the non-determinism of the extraction, as the results will be slight different on every run.
Additionally, the authors employ key element normalization as described in Lu et al. (2023), specifically using frequency filtering, rule, semantic, and association aggregation. In this implementation, we skipped this step.
GraphReader Agent
We’re ready to implement GraphReader, a graph-based agent system. The agent starts with a couple of predefined steps, followed by the steps in which it can traverse the graph autonomously, meaning the agent decides the following steps and how to traverse the graph.
Here is the LangGraph visualization of the agent we will implement.
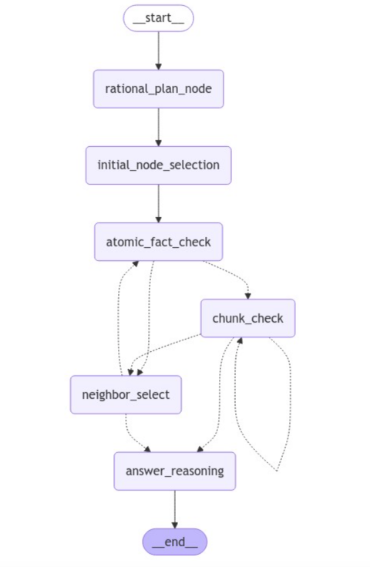
The process begins with a rational planning stage, after which the agent makes an initial selection of nodes (key elements) to work with. Next, the agent checks atomic facts linked to the selected key elements. Since all these steps are predefined, they are visualized with a full line.
Depending on the outcome of the atomic fact check, the flow proceeds to either read relevant text chunks or explore the neighbors of the initial key elements in search of more relevant information. Here, the next step is conditional and based on the results of an LLM and is, therefore, visualized with a dotted line.
In the chunk check stage, the LLM reads and evaluates whether the information gathered from the current text chunk is sufficient. Based on this evaluation, the LLM has a few options. It can decide to read additional text chunks if the information seems incomplete or unclear. Alternatively, the LLM may choose to explore neighboring key elements, looking for more context or related information that the initial selection might not have captured. If, however, the LLM determines that enough relevant information has been gathered, it will proceed directly to the answer reasoning step. At this point, the LLM generates the final answer based on the collected information.
Throughout this process, the agent dynamically navigates the flow based on the outcomes of the conditional checks, making decisions on whether to repeat steps or continue forward depending on the specific situation. This provides flexibility in handling different inputs while maintaining a structured progression through the steps.
Now, we’ll go over the steps and implement them using LangGraph abstraction. You can learn more about LangGraph through LangChain’s academy course.
LangGraph state
To build a LangGraph implementation, we start by defining a state passed along the steps in the flow.
class InputState(TypedDict):
question: str
class OutputState(TypedDict):
answer: str
analysis: str
previous_actions: List[str]
class OverallState(TypedDict):
question: str
rational_plan: str
notebook: str
previous_actions: Annotated[List[str], add]
check_atomic_facts_queue: List[str]
check_chunks_queue: List[str]
neighbor_check_queue: List[str]
chosen_action: str
For more advanced use cases, multiple separate states can be used. In our implementation, we have separate input and output states, which define the input and output of the LangGraph, and a separate overall state, which is passed between steps.
By default, the state is overwritten when returned from a node. However, you can define other operations. For example, with the previous_actions we define that the state is appended or added instead of overwritten.
The agent begins by maintaining a notebook to record supporting facts, which are eventually used to derive the final answer. Other states will be explained as we go along.
Let’s move on to defining the nodes in the LangGraph.
Rational plan
In the rational plan step, the agent breaks the question into smaller steps, identifies the key information required, and creates a logical plan. The logical plan allows the agent to handle complex multi-step questions.
While the code is unavailable, all the prompts are in the appendix, so we can easily copy them.

The authors don’t explicitly state whether the prompt is provided in the system or user message. For the most part, I have decided to put the instructions as a system message.
The following code shows how to construct a chain using the above rational plan as the system message.
rational_plan_system = """As an intelligent assistant, your primary objective is to answer the question by gathering
supporting facts from a given article. To facilitate this objective, the first step is to make
a rational plan based on the question. This plan should outline the step-by-step process to
resolve the question and specify the key information required to formulate a comprehensive answer.
Example:
#####
User: Who had a longer tennis career, Danny or Alice?
Assistant: In order to answer this question, we first need to find the length of Danny’s
and Alice’s tennis careers, such as the start and retirement of their careers, and then compare the
two.
#####
Please strictly follow the above format. Let’s begin."""
rational_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
rational_plan_system,
),
(
"human",
(
"{question}"
),
),
]
)
rational_chain = rational_prompt | model | StrOutputParser()
Now, we can use this chain to define a rational plan node. A node in LangGraph is a function that takes the state as input and updates it as output.
def rational_plan_node(state: InputState) -> OverallState:
rational_plan = rational_chain.invoke({"question": state.get("question")})
print("-" * 20)
print(f"Step: rational_plan")
print(f"Rational plan: {rational_plan}")
return {
"rational_plan": rational_plan,
"previous_actions": ["rational_plan"],
}
The function starts by invoking the LLM chain, which produces the rational plan. We do a little printing for debugging and then update the state as the function’s output. I like the simplicity of this approach.
Initial node selection
In the next step, we select the initial nodes based on the question and rational plan. The prompt is the following:

The prompt starts by giving the LLM some context about the overall agent system, followed by the task instructions. The idea is to have the LLM select the top 10 most relevant nodes and score them. The authors simply put all the key elements from the database in the prompt for an LLM to select from. However, I think that approach doesn’t really scale. Therefore, we will create and use a vector index to retrieve a list of input nodes for the prompt.
neo4j_vector = Neo4jVector.from_existing_graph(
embedding=embeddings,
index_name="keyelements",
node_label="KeyElement",
text_node_properties=["id"],
embedding_node_property="embedding",
retrieval_query="RETURN node.id AS text, score, {} AS metadata"
)
def get_potential_nodes(question: str) -> List[str]:
data = neo4j_vector.similarity_search(question, k=50)
return [el.page_content for el in data]
The from_existing_graph method pulls the defined text_node_properties from the graph and calculates embeddings where they are missing. Here, we simply embed the id property of KeyElement nodes.
Now let’s define the chain. We’ll first copy the prompt.
initial_node_system = """
As an intelligent assistant, your primary objective is to answer questions based on information
contained within a text. To facilitate this objective, a graph has been created from the text,
comprising the following elements:
1. Text Chunks: Chunks of the original text.
2. Atomic Facts: Smallest, indivisible truths extracted from text chunks.
3. Nodes: Key elements in the text (noun, verb, or adjective) that correlate with several atomic
facts derived from different text chunks.
Your current task is to check a list of nodes, with the objective of selecting the most relevant initial nodes from the graph to efficiently answer the question. You are given the question, the
rational plan, and a list of node key elements. These initial nodes are crucial because they are the
starting point for searching for relevant information.
Requirements:
#####
1. Once you have selected a starting node, assess its relevance to the potential answer by assigning
a score between 0 and 100. A score of 100 implies a high likelihood of relevance to the answer,
whereas a score of 0 suggests minimal relevance.
2. Present each chosen starting node in a separate line, accompanied by its relevance score. Format
each line as follows: Node: [Key Element of Node], Score: [Relevance Score].
3. Please select at least 10 starting nodes, ensuring they are non-repetitive and diverse.
4. In the user’s input, each line constitutes a node. When selecting the starting node, please make
your choice from those provided, and refrain from fabricating your own. The nodes you output
must correspond exactly to the nodes given by the user, with identical wording.
Finally, I emphasize again that you need to select the starting node from the given Nodes, and
it must be consistent with the words of the node you selected. Please strictly follow the above
format. Let’s begin.
"""
initial_node_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
initial_node_system,
),
(
"human",
(
"""Question: {question}
Plan: {rational_plan}
Nodes: {nodes}"""
),
),
]
)
Again, we put most of the instructions as the system message. Since we have multiple inputs, we can define them in the human message. However, we need a more structured output this time. Instead of writing a parsing function that takes in text and outputs a JSON, we can simply use the use_structured_outputmethod to define the desired output structure.
class Node(BaseModel):
key_element: str = Field(description="""Key element or name of a relevant node""")
score: int = Field(description="""Relevance to the potential answer by assigning
a score between 0 and 100. A score of 100 implies a high likelihood of relevance to the answer,
whereas a score of 0 suggests minimal relevance.""")
class InitialNodes(BaseModel):
initial_nodes: List[Node] = Field(description="List of relevant nodes to the question and plan")
initial_nodes_chain = initial_node_prompt | model.with_structured_output(InitialNodes)
We want to output a list of nodes containing the key element and the score. We can easily define the output using a Pydantic model. Additionally, it is vital to add descriptions to each of the field, so we can guide the LLM as much as possible.
The last thing in this step is to define the node as a function.
def initial_node_selection(state: OverallState) -> OverallState:
potential_nodes = get_potential_nodes(state.get("question"))
initial_nodes = initial_nodes_chain.invoke(
{
"question": state.get("question"),
"rational_plan": state.get("rational_plan"),
"nodes": potential_nodes,
}
)
# paper uses 5 initial nodes
check_atomic_facts_queue = [
el.key_element
for el in sorted(
initial_nodes.initial_nodes,
key=lambda node: node.score,
reverse=True,
)
][:5]
return {
"check_atomic_facts_queue": check_atomic_facts_queue,
"previous_actions": ["initial_node_selection"],
}
In the initial node selection, we start by getting a list of potential nodes using the vector similarity search based on the input. An option is to use rational plan instead. The LLM is prompted to output the 10 most relevant nodes. However, the authors say that we should use only 5 initial nodes. Therefore, we simply order the nodes by their score and take the top 5 ones. We then update the check_atomic_facts_queue with the selected initial key elements.
Atomic fact check
In this step, we take the initial key elements and inspect the linked atomic facts. The prompt is:

All prompts start by giving the LLM some context, followed by task instructions. The LLM is instructed to read the atomic facts and decide whether to read the linked text chunks or if the atomic facts are irrelevant, search for more information by exploring the neighbors. The last bit of the prompt is the output instructions. We will use the structured output method again to avoid manually parsing and structuring the output.
Since chains are very similar in their implementation, different only by prompts, we’ll avoid showing every definition in this blog post. However, we’ll look at the LangGraph node definitions to better understand the flow.
def atomic_fact_check(state: OverallState) -> OverallState:
atomic_facts = get_atomic_facts(state.get("check_atomic_facts_queue"))
print("-" * 20)
print(f"Step: atomic_fact_check")
print(
f"Reading atomic facts about: {state.get('check_atomic_facts_queue')}"
)
atomic_facts_results = atomic_fact_chain.invoke(
{
"question": state.get("question"),
"rational_plan": state.get("rational_plan"),
"notebook": state.get("notebook"),
"previous_actions": state.get("previous_actions"),
"atomic_facts": atomic_facts,
}
)
notebook = atomic_facts_results.updated_notebook
print(
f"Rational for next action after atomic check: {atomic_facts_results.rational_next_action}"
)
chosen_action = parse_function(atomic_facts_results.chosen_action)
print(f"Chosen action: {chosen_action}")
response = {
"notebook": notebook,
"chosen_action": chosen_action.get("function_name"),
"check_atomic_facts_queue": [],
"previous_actions": [
f"atomic_fact_check({state.get('check_atomic_facts_queue')})"
],
}
if chosen_action.get("function_name") == "stop_and_read_neighbor":
neighbors = get_neighbors_by_key_element(
state.get("check_atomic_facts_queue")
)
response["neighbor_check_queue"] = neighbors
elif chosen_action.get("function_name") == "read_chunk":
response["check_chunks_queue"] = chosen_action.get("arguments")[0]
return response
The atomic fact check node starts by invoking the LLM to evaluate the atomic facts of the selected nodes. Since we are using the use_structured_output we can parse the updated notebook and the chosen action output in a straightforward manner. If the selected action is to get additional information by inspecting the neighbors, we use a function to find those neighbors and append them to the check_atomic_facts_queue. Otherwise, we append the selected chunks to the check_chunks_queue. We update the overall state by updating the notebook, queues, and the chosen action.
Text chunk check
As you might imagine by the name of the LangGraph node, in this step, the LLM reads the selected text chunk and decides the best next step based on the provided information. The prompt is the following:

The LLM is instructed to read the text chunk and decide on the best approach. My gut feeling is that sometimes relevant information is at the start or the end of a text chunk, and parts of the information might be missing due to the chunking process. Therefore, the authors decided to give the LLM the option to read a previous or next chunk. If the LLM decides it has enough information, it can hop on to the final step. Otherwise, it has the option to search for more details using the search_morefunction.
Again, we’ll just look at the LangGraph node function.
def chunk_check(state: OverallState) -> OverallState:
check_chunks_queue = state.get("check_chunks_queue")
chunk_id = check_chunks_queue.pop()
print("-" * 20)
print(f"Step: read chunk({chunk_id})")
chunks_text = get_chunk(chunk_id)
read_chunk_results = chunk_read_chain.invoke(
{
"question": state.get("question"),
"rational_plan": state.get("rational_plan"),
"notebook": state.get("notebook"),
"previous_actions": state.get("previous_actions"),
"chunk": chunks_text,
}
)
notebook = read_chunk_results.updated_notebook
print(
f"Rational for next action after reading chunks: {read_chunk_results.rational_next_move}"
)
chosen_action = parse_function(read_chunk_results.chosen_action)
print(f"Chosen action: {chosen_action}")
response = {
"notebook": notebook,
"chosen_action": chosen_action.get("function_name"),
"previous_actions": [f"read_chunks({chunk_id})"],
}
if chosen_action.get("function_name") == "read_subsequent_chunk":
subsequent_id = get_subsequent_chunk_id(chunk_id)
check_chunks_queue.append(subsequent_id)
elif chosen_action.get("function_name") == "read_previous_chunk":
previous_id = get_previous_chunk_id(chunk_id)
check_chunks_queue.append(previous_id)
elif chosen_action.get("function_name") == "search_more":
# Go over to next chunk
# Else explore neighbors
if not check_chunks_queue:
response["chosen_action"] = "search_neighbor"
# Get neighbors/use vector similarity
print(f"Neighbor rational: {read_chunk_results.rational_next_move}")
neighbors = get_potential_nodes(
read_chunk_results.rational_next_move
)
response["neighbor_check_queue"] = neighbors
response["check_chunks_queue"] = check_chunks_queue
return response
We start by popping a chunk ID from the queue and retrieving its text from the graph. Using the retrieved text and additional information from the overall state of the LangGraph system, we invoke the LLM chain. If the LLM decides it wants to read previous or subsequent chunks, we append their IDs to the queue. On the other hand, if the LLM chooses to search for more information, we have two options. If there are any other chunks to read in the queue, we move to reading them. Otherwise, we can use the vector search to get more relevant key elements and repeat the process by reading their atomic facts and so on.
The paper is slightly dubious about the search_more function. On the one hand, it states that the search_more function can only read other chunks in the queue. On the other hand, in their example in the appendix, the function clearly explores the neighbors.
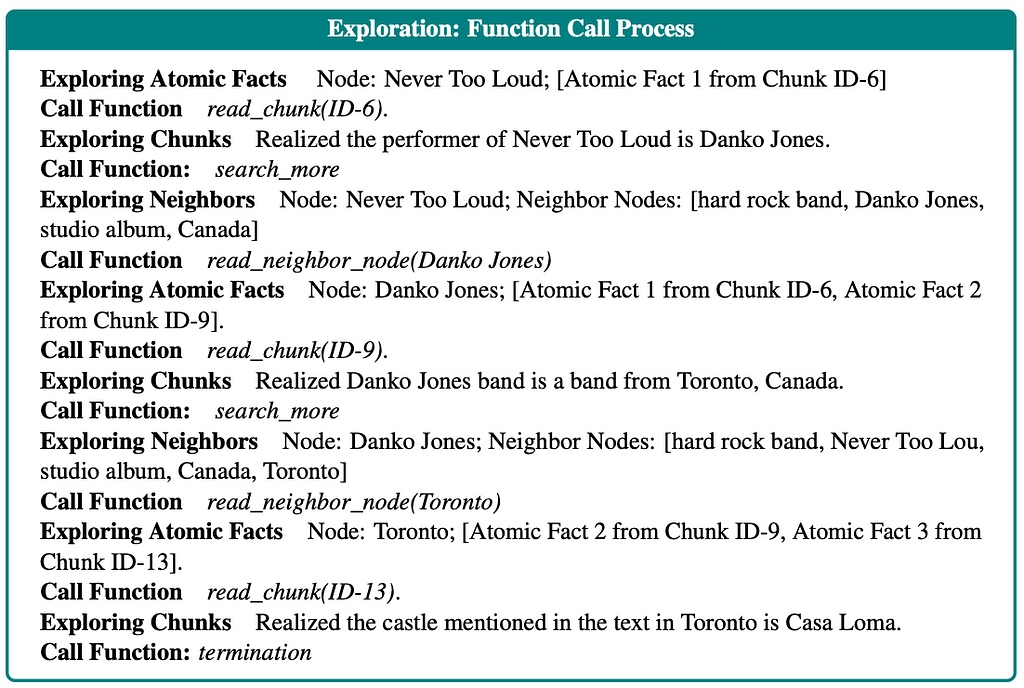
To clarify, I emailed the authors, and they confirmed that the search_morefunction first tries to go through additional chunks in the queue. If none are present, it moves on to exploring the neighbors. Since how to explore the neighbors isn’t explicitly defined, we again use the vector similarity search to find potential nodes.
Neighbor selection
When the LLM decides to explore the neighbors, we have helper functions to find potential key elements to explore. However, we don’t explore all of them. Instead, an LLM decides which of them is worth exploring, if any. The prompt is the following:

Based on the provided potential neighbors, the LLM can decide which to explore. If none are worth exploring, it can decide to terminate the flow and move on to the answer reasoning step.
The code is:
def neighbor_select(state: OverallState) -> OverallState:
print("-" * 20)
print(f"Step: neighbor select")
print(f"Possible candidates: {state.get('neighbor_check_queue')}")
neighbor_select_results = neighbor_select_chain.invoke(
{
"question": state.get("question"),
"rational_plan": state.get("rational_plan"),
"notebook": state.get("notebook"),
"nodes": state.get("neighbor_check_queue"),
"previous_actions": state.get("previous_actions"),
}
)
print(
f"Rational for next action after selecting neighbor: {neighbor_select_results.rational_next_move}"
)
chosen_action = parse_function(neighbor_select_results.chosen_action)
print(f"Chosen action: {chosen_action}")
# Empty neighbor select queue
response = {
"chosen_action": chosen_action.get("function_name"),
"neighbor_check_queue": [],
"previous_actions": [
f"neighbor_select({chosen_action.get('arguments', [''])[0] if chosen_action.get('arguments', ['']) else ''})"
],
}
if chosen_action.get("function_name") == "read_neighbor_node":
response["check_atomic_facts_queue"] = [
chosen_action.get("arguments")[0]
]
return response
Here, we execute the LLM chain and parse results. If the chosen action is to explore any neighbors, we add them to the check_atomic_facts_queue .
Answer reasoning
The last step in our flow is to ask the LLM to construct the final answer based on the collected information in the notebook. The prompt is:

This node implementation is fairly straightforward as you can see by the code:
def answer_reasoning(state: OverallState) -> OutputState:
print("-" * 20)
print("Step: Answer Reasoning")
final_answer = answer_reasoning_chain.invoke(
{"question": state.get("question"), "notebook": state.get("notebook")}
)
return {
"answer": final_answer.final_answer,
"analysis": final_answer.analyze,
"previous_actions": ["answer_reasoning"],
}
We simply input the original question and the notebook with the collected information to the chain and ask it to formulate the final answer and provide the explanation in the analysis part.
LangGraph flow definition
The only thing left is to define the LangGraph flow and how it should traverse between the nodes. I am quite fond of the simple approach the LangChain team has chosen.
langgraph = StateGraph(OverallState, input=InputState, output=OutputState)
langgraph.add_node(rational_plan_node)
langgraph.add_node(initial_node_selection)
langgraph.add_node(atomic_fact_check)
langgraph.add_node(chunk_check)
langgraph.add_node(answer_reasoning)
langgraph.add_node(neighbor_select)
langgraph.add_edge(START, "rational_plan_node")
langgraph.add_edge("rational_plan_node", "initial_node_selection")
langgraph.add_edge("initial_node_selection", "atomic_fact_check")
langgraph.add_conditional_edges(
"atomic_fact_check",
atomic_fact_condition,
)
langgraph.add_conditional_edges(
"chunk_check",
chunk_condition,
)
langgraph.add_conditional_edges(
"neighbor_select",
neighbor_condition,
)
langgraph.add_edge("answer_reasoning", END)
langgraph = langgraph.compile()
We begin by defining the state graph object, where we can define the information passed along in the LangGraph. Each node is simply added with the add_node method. Normal edges, where one step always follows the other, can be added with a add_edge method. On the other hand, if the traversals is dependent on previous actions, we can use the add_conditional_edge and pass in the function that selects the next node. For example, the atomic_fact_condition looks like this:
def atomic_fact_condition(
state: OverallState,
) -> Literal["neighbor_select", "chunk_check"]:
if state.get("chosen_action") == "stop_and_read_neighbor":
return "neighbor_select"
elif state.get("chosen_action") == "read_chunk":
return "chunk_check"
As you can see, it’s about as simple as it gets to define the conditional edge.
Evaluation
Finally we can test our implementation on a couple of questions. Let’s begin with a simple one.
langgraph.invoke({"question":"Did Joan of Arc lose any battles?"})
Results

The agent begins by forming a rational plan to identify the battles Joan of Arc participated in during her military career and to determine whether any were lost. After setting this plan, it moves to an atomic fact check about key battles such as the Siege of Orléans, the Siege of Paris, and La Charité. Rather than expanding the graph, the agent directly confirms the facts it needs. It reads text chunks that provide further details on Joan of Arc’s unsuccessful campaigns, particularly the failed Siege of Paris and La Charité. Since this information answers the question about whether Joan lost any battles, the agent stops here without expanding its exploration further. The process concludes with a final answer, confirming that Joan did indeed lose some battles, notably at Paris and La Charité, based on the evidence gathered.
Let’s now throw it a curveball.
langgraph.invoke({"question":"What is the weather in Spain?"})
Results

After the rational plan, the agent selected the initial key elements to explore. However, the issue is that none of these key elements exists in the database, and the LLM simply hallucinated them. Maybe some prompt engineering could solve hallucinations, but I haven’t tried. One thing to note is that it’s not that terrible, as these key elements don’t exist in the database, so we can’t pull any relevant information. Since the agent didn’t get any relevant data, it searched for more information. However, none of the neighbors are relevant either, so the process is stopped, letting the user know that the information is unavailable.
Now let’s try a multi-hop question.
langgraph.invoke(
{"question":"Did Joan of Arc visit any cities in early life where she won battles later?"})
Results

It’s a bit too much to copy the whole flow, so I copied only the answer part. The flow for this questions is quite non-deterministic and very dependent on the model being used. It’s kind of funny, but as I was testing the newer the model, the worse it performed. So the GPT-4 was the best (also used in this example), followed by GPT-4-turbo, and the last place goes to GPT-4o.
Summary
I’m very excited about GraphReader and similar approaches, specifically because I think such an approach to (Graph)RAG can be pretty generic and applied to any domain. Additionally, you can avoid the whole graph modeling part as the graph schema is static, allowing the graph agent to traverse it using predefined functions.
We discussed some issues with this implementation along the way. For example, the graph construction on many documents might result in broad key elements ending up as supernodes, and sometimes, the atomic facts don’t contain the full context.
The retriever part is super reliant on extracted and selected key elements. In the original implementation, they put all the key elements in the prompt to choose from. However, I doubt that that approach scales well. Perhaps we also need an additional function to allow the agent to search for more information in other ways than just to explore the neighbor key elements.
Lastly, the agent system is highly dependent on the performance of the LLM. Based on my testing, the best model from OpenAI is the original GPT-4, which is funny as it’s the oldest. I haven’t tested the o1, though.
All in all, I am excited to explore more of these document graphs implementations, where metadata is extracted from text chunk and used to navigate the information better. Let me know if you have any ideas how to improve this implementation or have any other you like.
As always, the code is available on GitHub.
Implementing GraphReader with Neo4j and LangGraph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Implementing GraphReader with Neo4j and LangGraph
Go Here to Read this Fast! Implementing GraphReader with Neo4j and LangGraph