

My first encounters with the o1 model
My first encounters with the o1 model
On the 12th of September at 10:00 a.m., I was in the class “Frontier Topics in Generative AI,” a graduate-level course at Arizona State University. A day before this, on the 11th of September, I submitted a team assignment that involved trying to identify flaws and erroneous outputs generated by GPT-4 (essentially trying to prompt GPT-4 to see if it makes mistakes on trivial questions or high-school-level reasoning questions) as part of another graduate-level class “Topics in Natural Language Processing.” We identified several trivial mistakes that GPT-4 made, one of them being unable to count the number of r’s in the word strawberry. Before submitting this assignment, I researched several peer-reviewed papers on the internet that identified where and why GPT -4 made mistakes and how you could rectify them. Most of the documents I came across identified two main domains where GPT-4 erred, and they dealt with planning and reasoning.
This paper¹ (although almost a year old) goes in depth through several cases where GPT-4 fails to answer trivial questions that involve simple counting, simple arithmetic, elementary logic, and even common sense. The paper¹ reasons that these questions require some level of reasoning and that because GPT-4 is utterly incapable of reasoning, it almost always gets these questions wrong. The author also states that reasoning is a (very) computationally hard problem. Although GPT-4 is very compute-intensive, its compute-intensive nature is not geared towards involving reasoning in solving the questions that it’s prompted with. Several other papers echo this notion of GPT-4 being unable to reason or plan²³.
Well, let’s get back to the 12th of September. My class ends at around 10:15 a.m., and I come back straight home from class and open up YouTube on my phone as I dig into my morning brunch. The first recommendation on my YouTube homepage was a video from OpenAI announcing the release of GPT-o1 named “Building OpenAI o1”. They announced that this model is a straight-up a reasoning model and that it would take more time to reason and answer your questions providing more accurate answers. They state that they have put more compute time into RL (Reinforcement Learning) than previous models to generate coherent chains-of-thoughts⁴. Essentially, they have trained the chain of thought generation process using Reinforcement learning (to generate and hone its own generated chain of thought process). In the o1 models, the engineers were able to ask the model questions as to why it was wrong (whenever it was wrong) in its chain-of-thought process and it could identify the mistakes and correct itself from them. The model could question itself and have to reflect (see “Reflection in LLMs”) on its outputs and correct itself.
In another video “Reasoning with OpenAI o1”, Jerry Tworek demonstrates how previous OpenAI and most other LLMs in the market tend to fail on the following prompt:
“Assume the laws of physics on earth. A small strawberry is put into a normal cup and the cup is placed upside down on a table. Someone then takes the cup and puts it inside the microwave. Where is the strawberry now? Explain your reasoning step by step.”
Legacy GPT-4 answers as follows:

The relatively newer GPT-4o also gets it wrong:
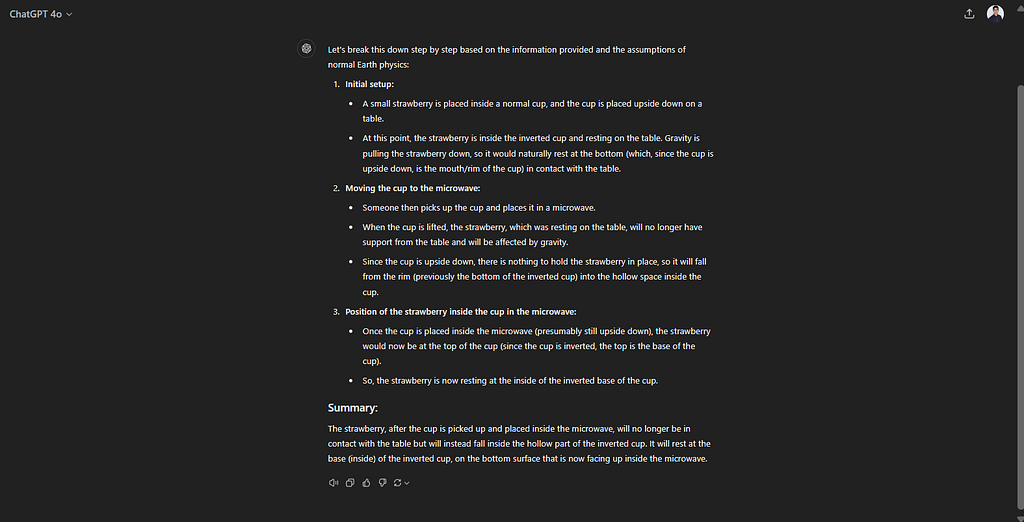
GPT o1 gets the answer right:
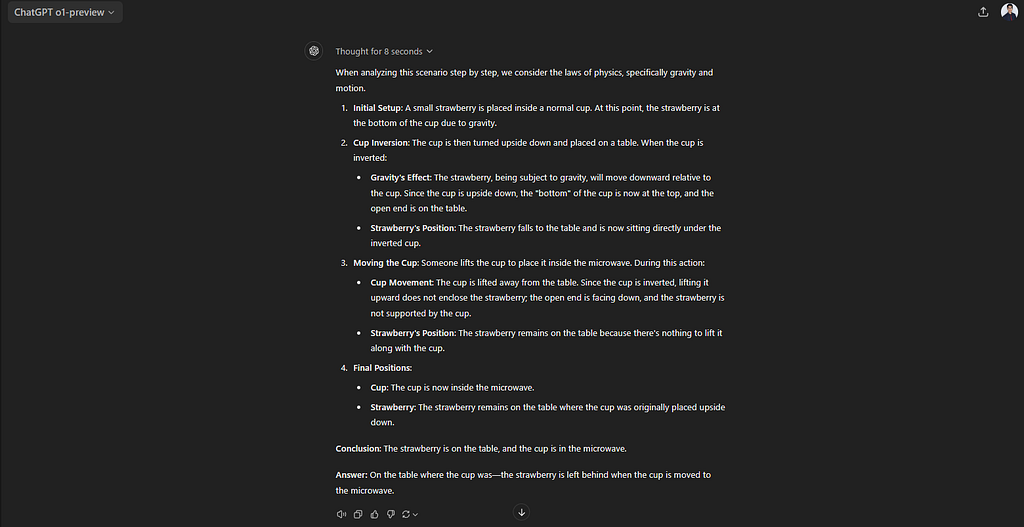
If you click on the dropdown at the beginning of the model’s response (see Figure 4), you know that it elicits its thought process (chain-of-thought), and the researchers at OpenAI claim that the o1 model has been trained with reinforcement learning to get this chain of thought better. Also, it’s interesting to note that Jason Wei (you can see him sitting third from the right on the bottom row in the video “Building OpenAI o1”), the author of the chain-of-thought paper⁴ that he published back at Google, is now an OpenAI employee that is working on the o1 model to integrate the chain-of-thought (that he discovered at Google) process into this model.

Now, let’s get back to the counting question that my team found out about as part of my assignment.
How many r’s are in the word strawberry?
Let’s run this question on GPT-4o:

A very simple counting problem that it get’s wrong.
Let’s run this on the new GPT o1:

GPT o1 gets the answer right by thinking for a couple of seconds. The researchers at OpenAI say that it goes through its response repeatedly and thinks its way to the right answer. There does seem to be really significant improvements in terms of the model’s ability to solve a lot of academic exam questions.
Anyways after I opened up X.com (Formerly Twitter), I came across several people showcasing their attempts at trying to make the o1 model fail. This is a fascinating one I came across (this tweet by @creeor) where the model fails to answer a trivial question in which the answer lies in the question itself. So I tried the exact same prompt on my account and it gave me the wrong answer (see Figure 7).
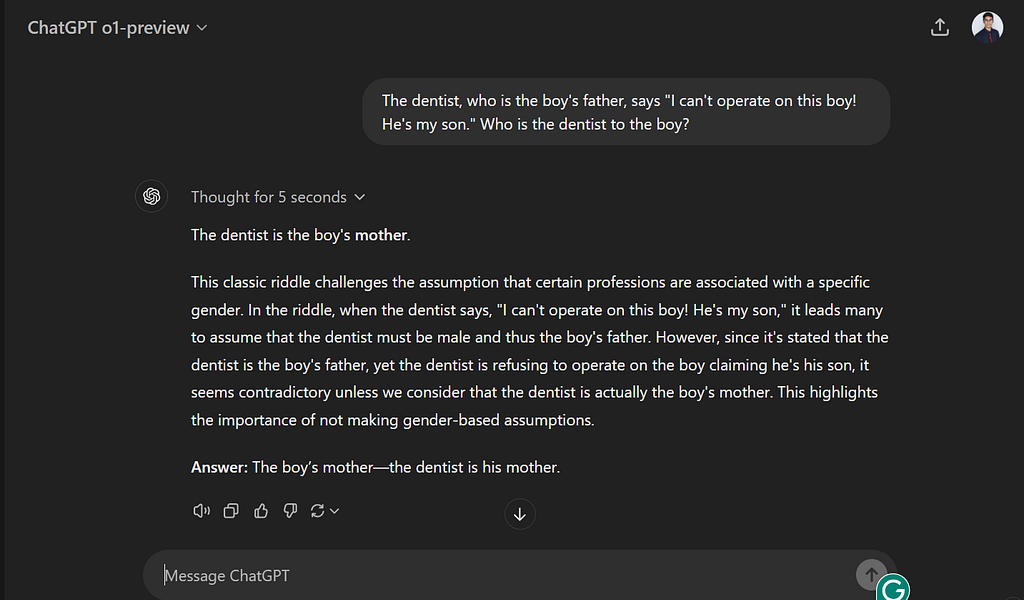
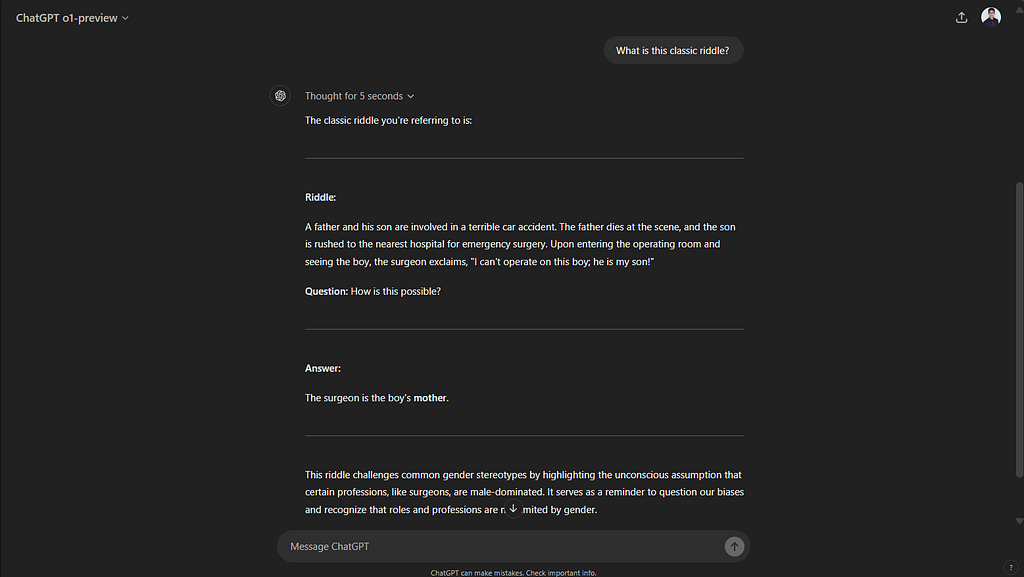
When I ask it what this classic riddle is that it is talking about it tells me about a riddle that it memorized from the internet. It’s interesting to see how these models can sometimes fall back on memorized content rather than truly reasoning through a problem. Despite the significant advancements and benchmark improvements, there are still areas where AI models struggle, especially with tasks that require deeper reasoning or understanding context in a nuanced way. While benchmarks can show progress, real-world applications often reveal the limitations. It’s through continuous testing, feedback, and real-world use cases that these models can be further refined.
There was a compilation of ChatGPT failures done about a year and a half back. Compilations of model errors are invaluable for understanding and improving AI systems. I’m sure people will come up with another compilation of errors for the o1 model soon.
Although I agree entirely that the chain-of-thought process benefits both AI and human learning, real learning indeed comes from experience and making mistakes.
I will continue to keep posting my findings on the o1 model on my Medium page. Follow my account to keep posted. And thank you for taking the time to read my Medium post.
References:
[1] Arkoudas, Konstantine. “GPT-4 can’t reason.” arXiv preprint arXiv:2308.03762 (2023).
[2] Aghzal, Mohamed, Erion Plaku, and Ziyu Yao. “Look Further Ahead: Testing the Limits of GPT-4 in Path Planning.” arXiv preprint arXiv:2406.12000 (2024).
[3] Kambhampati, Subbarao, et al. “LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks.” arXiv preprint arXiv:2402.01817 (2024).
[4] Wei, Jason, et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in neural information processing systems 35 (2022): 24824–24837.
OpenAI o1: Is This the Enigmatic Force That Will Reshape Every Knowledge Sector We Know? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
OpenAI o1: Is This the Enigmatic Force That Will Reshape Every Knowledge Sector We Know?