Theoretical derivation of the Robust Counterpart of Markov Decision Processes (MDPs) as a Linear Program (LP)

Introduction
Markov Decision Processes are foundational to sequential decision-making problems and serve as the building block for reinforcement learning. They model the dynamic interaction between an agent having to make a series of actions and their environment. Due to their wide applicability in fields such as robotics, finance, operations research and AI, MDPs have been extensively studied in both theoretical and practical contexts.
Yet, much of the existing MDP literature focuses on the idealized scenarios where model parameters — such as transition probabilities and reward functions — are assumed to be known with certainty. In practice, applying popular methods such as Policy Iteration and Value Iteration require precise estimates of these parameters, often obtained from real-world data. This reliance on data introduces significant challenges: the estimation process is inherently noisy and sensitive to limitations such as data scarcity, measurement errors and variability in the observed environment. Consequently, the performance of standard MDP methods can degrade substantially when applied to problems with uncertain or incomplete data.
In this article, we build on the Robust Optimization (RO) literature to propose a generic framework to address these issues. We provide a Robust Linear Programming (RLP) formulation of MDPs that is capable of handling various sources of uncertainty and adversarial perturbations.
MDP definition and LP formulation
Let’s start by giving a formal definition of MDPs:
A Markov Decision Process is a 5-tuple (S, A, R, P, γ) such that:
- S is the set of states the agent can be in
- A is the set of actions the agent can take
- R : S x A → R the reward function
- P is the set of probability distributions defined such that P(s’|s,a) is the probability of transitioning to state s’ if the agent takes action a in state s. Note that MDPs are Markov processes, meaning that the Markov property holds on the transition probabilities: P(Sₜ₊₁|S₀, A₀, …, Sₜ, Aₜ) = P(Sₜ₊₁|Sₜ, Aₜ)
- γ ∈ (0, 1] is a discount factor. While we usually deal with discounted problems (i.e. γ < 1), the formulations presented are also valid for undiscounted MDPs (γ = 1)
We then define the policy, i.e. what dictates the agent’s behavior in an MDP:
A policy π is a probability measure over the action space defined as: π(a|s) is the probability of taking action a when the agent is in state s.
We finally introduce the value function, i.e. the agent’s objective in an MDP:
The value function of a policy π is the expected discounted reward under this policy, when starting at a given state s:

In particular, the value function of the optimal policy π* satisfies the Bellman optimality equation:
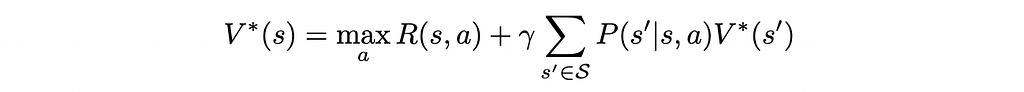
Which yields the deterministic optimal policy:
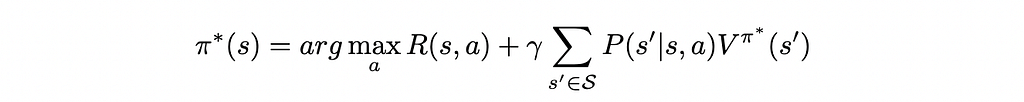
Deriving the LP formulation of MDPs:
Given the above definitions, we can start by noticing that any value function V that satisfies

is an upper bound on the optimal value function. To see it, we can start by noticing that such value function also satisfies:

We recognize the value iteration operator applied to V:
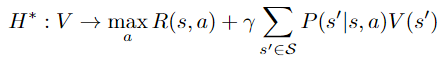
i.e.
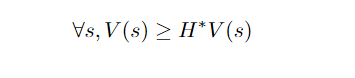
Also noticing that the H*operator is increasing, we can apply it iteratively to have:

where we used the property of V* being the fixed point of H*.
Therefore, finding V* comes down to finding the tightest upper bound V that obeys the above equation, which yields the following formulation:
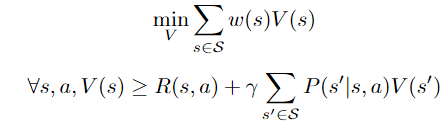
Here we added a weight term corresponding to the probability of starting in state s. We can see that the above problem is linear in V and can be rewritten as follows:
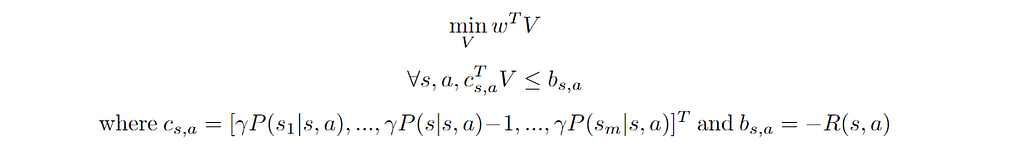
Further details can be found in [1] and [2].
Robust Optimization for Linear Programming
Given the above linear program in standard form, the RO framework assumes an adversarial noise in the inputs (i.e. cost vector and constraints). To model this uncertainty, we define an uncertainty set:

In short, we want to find the minimum of all linear programs, i.e. for each occurrence in the uncertainty set. Naturally this yields a completely intractable model (potentially an infinite number of LPs) since we did not make any assumption on the form of U.
Before addressing these issues, we make the following assumptions — without loss of generality:
- Uncertainty in w and b is equivalent to uncertainty in the constraints for a slightly modified LP — for this reason we consider uncertainty only in c
- Adversarial noise is applied constraint-wise, i.e. to each constraint individually
- The constraint of the robust problem are in the form:
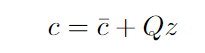
where: bar{c} is known as the nominal constraint vector (e.g. gotten from some estimation), z the uncertain factor and Q a fixed matrix intuitively corresponding to how the noise is applied to each coefficient of the constraint vector. Q can be used for instance to model correlation between the noise on difference components of c. See [3] for more details and proofs.
Note: we made a slight abuse of notation and dropped the (s, a) subscripts for readability — yet c, bar{c}, Q and z are all for a given state and action couple.
- Rather than optimizing for each entry of the uncertainty set, we optimize the worst case over U. In the context of uncertainty on the constraints only, this mean that the worst case over U must also be feasible
All this leads to the following formulation of the problem:

At this stage, we can make some assumptions on the form of U in order to further simplify the problem:
- While z can be a vector of arbitrary dimension L — as Q will be a |S| x L matrix — we make the simplifying assumption that z is of size |S| and Q is a square diagonal matrix of size |S| as well. This will allow to model separately an adversarial noise on each coefficient on the constraint vector (and no correlation between noises)
- We assume that the uncertainty set is a box of size 2d, i.e. that each coordinate of z can take any value from the interval [-d, d]. This is equivalent to saying that the L∞ norm of z is less than d
The optimization problem becomes:

which is equivalent to:

Finally, looking closer to the maximization problem in the constraint, we see that it has a closed form. Therefore the final problem can be written as (robust counterpart of a linear program with box uncertainty):
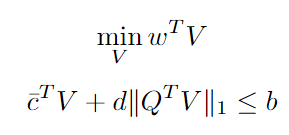
A few comments on the above formulation:
- The uncertainty term disappeared — robustness is brought by an additional safety term
- As the L1 norm can be linearized, this is a linear program
- The above formulation does not depend on the form of Q — the assumption made will be useful in the next section
For more details, the interested reader can refer to [3].
The RLP formulation of MDPs
Starting from the above formulation:
And finally, linearizing the absolute value in the constraints gives:

We notice that robustness translates into an additional safety term in the constraints — given the uncertainty on c (which mainly translates into uncertainty in the MDP’s transition probabilities).
As stated previously, considering uncertainty on the rewards as well can be easily done with a similar derivation. Coming back to the linear program in standard form, we add another noise term on the right hand side of the constraints:
After a similar reasoning as previously done, we have the all-in linear program:

Again similarly to before, additional robustness with regards to the reward function translates into another safety term in the constraints, which ultimately can yield a less optimal value function and policy but fills the constraints with margin. This tradeoff is controlled both by Q and the size of the uncertainty box d.
Conclusion
While this completes the derivation of the Robust MDP as a linear program, other robust MDP approaches have been developed in the literature, see for instance [4]. These approaches usually take a different route, for instance directly deriving a robust Policy Evaluation operator — which for instance has the advantage of having a better complexity as the LP approach. This proves particularly important when state and action spaces are large. Therefore why would we use such formulation?
- The RLP formulation allows to benefit from all theoretical properties of linear programming. This entails guarantees of a solution (when the problem is feasible and bounded), as well as known results from duality theory and sensitivity analysis
- The LP approach allows to easily use different geometries of uncertainty sets — see [3] for details
- This formulation allows to integrate naturally additional constraints on the MDP, while keeping the robustness properties
- We can furthermore apply some projection or approximation methods (see for instance [5]) to improve the LP complexity
References:
[1] M.L. Puterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming (1996), Wiley
[2] P. Pouppart, Sequential Decision Making and Reinforcement Learning (2013), University of Waterloo
[3] D. Bertsimas, D. Den Hertog, Robust and Adaptive Optimization (2022), Dynamic Ideas
[4] W. Wiesemann, D. Kuhn, B. Rustem, Robust Markov Decision Processes (2013), INFORMS
[5] K. Vu, P.-L. Poirion, L. Liberti, Random Projections for Linear Programming (2018), INFORMS
Uncertainty in Markov Decisions Processes: a Robust Linear Programming approach was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Uncertainty in Markov Decisions Processes: a Robust Linear Programming approach