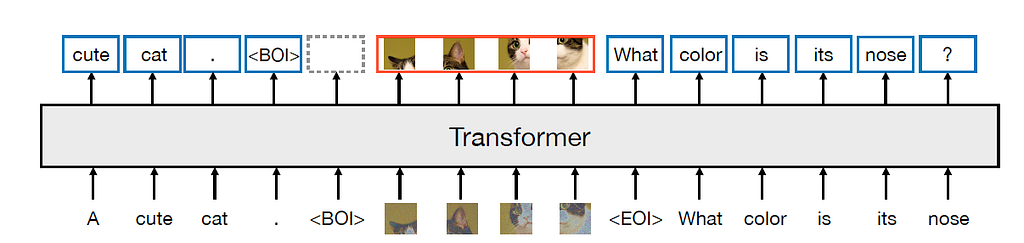
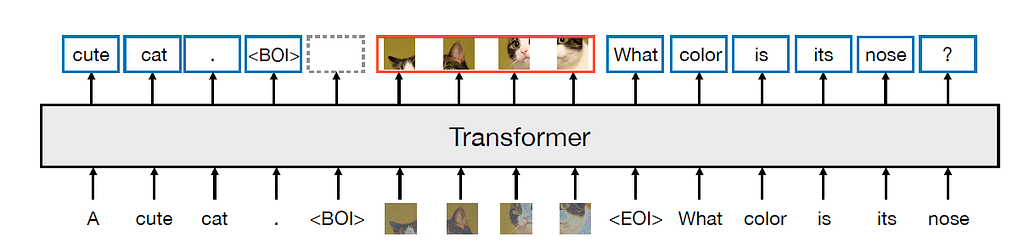
A gentle introduction to the latest multi-modal transfusion model
Recently, Meta and Waymo released their latest paper — Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, which integrates the popular transformer model with the diffusion model for multi-modal training and prediction purposes.
Like Meta’s previous work, the Transfusion model is based on the Llama architecture with early fusion, which takes both the text token sequence and the image token sequence and uses a single transformer model to generate the prediction. But different from previous art, the Transfusion model addresses the image tokens differently:
- The image token sequence is generated by a pre-trained Variational Auto-Encoder part.
- The transformer attention for the image sequence is bi-directional rather than causal.
Let’s discuss the following in detail. We’ll first review the basics, like auto-regressive and diffusion models, then dive into the Transfusion architecture.
Auto-regressive Models
Nowadays, large language models (LLMs) are primarily based on transformer architectures, which were proposed in the Attention is All You Need paper in 2017. The transformer architecture contains two parts: the encoder and the decoder.
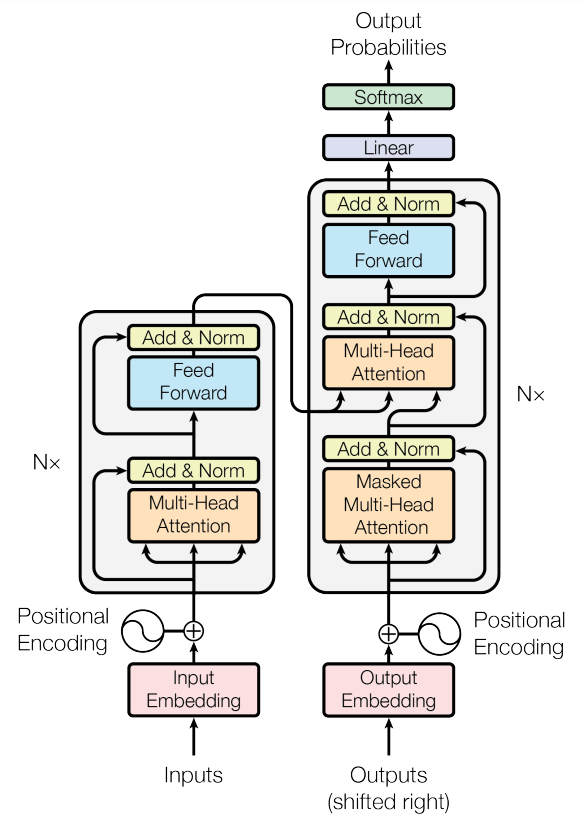
Masked Language Models like BERT use the encoder part pre-trained with randomly bidirectional masked token prediction tasks (and next sentence prediction). For auto-regressive models like the latest LLMs, the decoder part is usually trained on the next token prediction task, where the LM loss is minimized:
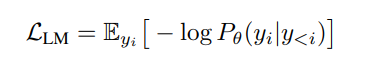
In the equation above, theta is the model parameter set, and y_i is the token at index i in a sequence of length n. y<i are all the tokens before y_i.
Diffusion Models
What is the diffusion model? It is a series of deep learning models commonly used in computer vision (especially for medical image analysis) for image generation/denoising and other purposes. One of the most well-known diffusion models is the DDPM, which is from the Denoising diffusion probabilistic models paper published in 2020. The model is a parameterized Markov chain containing a backward and forward transition, as shown below.

What is a Markov chain? It’s a statistical process in which the current step only relies on the previous step, and the reverse is vice versa. By assuming a Markov process, the model can start with a clean image by iteratively adding Gaussian noise in the forward process (right -> left in the figure above) and iteratively “learn” the noise by using a Unet-based architecture in the reverse process (left -> right in the figure above). That’s why we can sometimes see the diffusion model as a generative model (when used from left to right) and sometimes as a denoising model (when used from right to left). The DDPM loss is given below, where the theta is the model parameter set, epsilon is the known noise, and the epsilon_theta is the noise estimated by a deep learning model (usually a UNet):
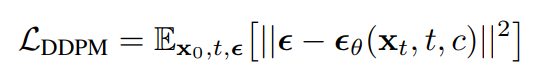
Diffusion Model in the Latent Space
The idea of diffusion was further extended to the latent space in the CVPR’22 paper, where the images are first “compressed” onto the latent space by using the encoder part of a pre-trained Variational Auto Encoder (VAE). Then, the diffusion and reverse processes are performed on the latent space and mapped back to pixel space using the decoder part of the VAE. This could largely improve the learning speed and efficiency, as most calculations are performed in a lower dimensional space.
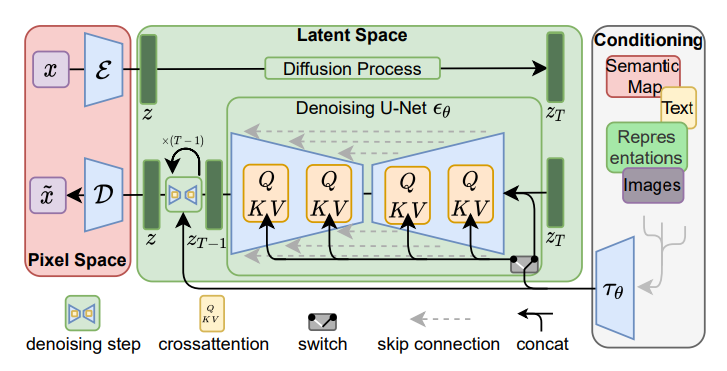
VAE-based Image Transfusion
The core part of the Transfusion model is the fusion between the diffusion and the transformer for input images. First, an image is divided into a sequence of 8*8 patches; each patch is passed into a pre-trained VAE encoder to “compress” into an 8-element latent vector representation. Then, noise is added to the latent representation and further processed by a linear layer/U-Net encoder to generate the “noisy” x_t. Third, the transformer model processes the sequence of noisy latent representations. Last, the outputs are reversely processed by another linear/U-Net decoder before using a VAE decoder to generate the “true” x_0 image.
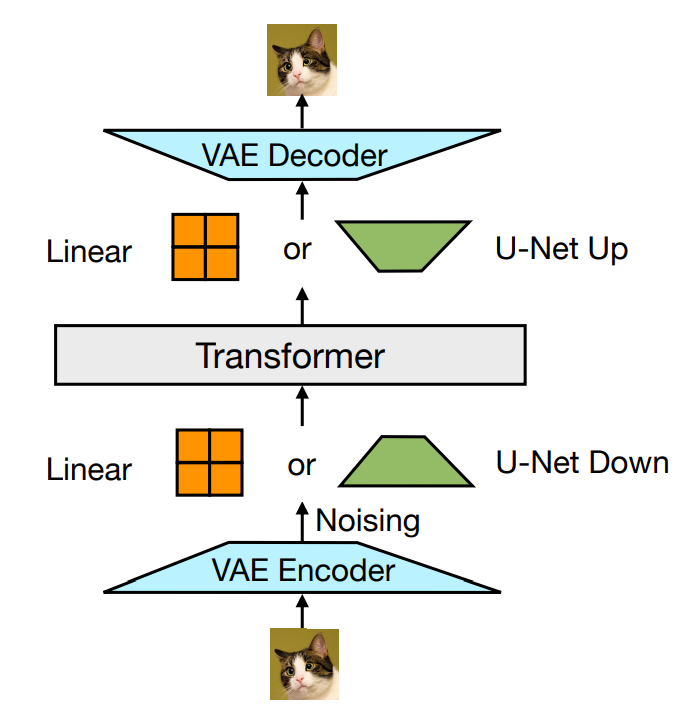
In the actual implementation, the beginning of the image (BOI) token and the end of the image (EOI) token are padded to both sides of the image representation sequence before concatenating the text tokens. Self-attention for image training is bi-directional attention, while self-attention for text tokens is causal. At the training stage, the loss for the image sequence is DDPM loss, while the rest of the text tokens use the LM loss.
So why bother? Why do we need such a complicated procedure for processing image patch tokens? The paper explains that the token space for text and images is different. While the text tokens are discrete, the image tokens/patches are naturally continuous. In the previous art, image tokens need to be “discretized” before fusing into the transformer model, while integrating the diffusion model directly could resolve this issue.
Compare with state-of-the-art
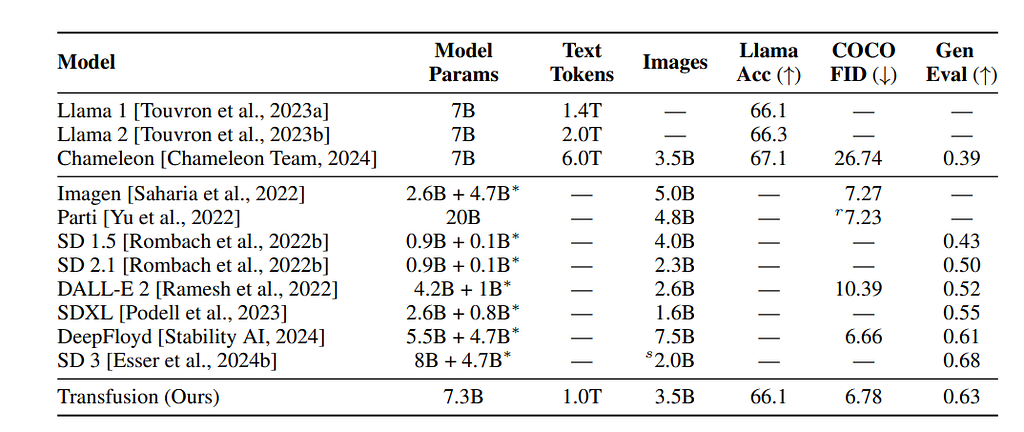
The primary multi-modal model the paper compares to is the Chameleon model, which Meta proposed earlier this year. Here, we compare the difference between architecture and training set size between the Chameleon-7B and Transfusion-7B.
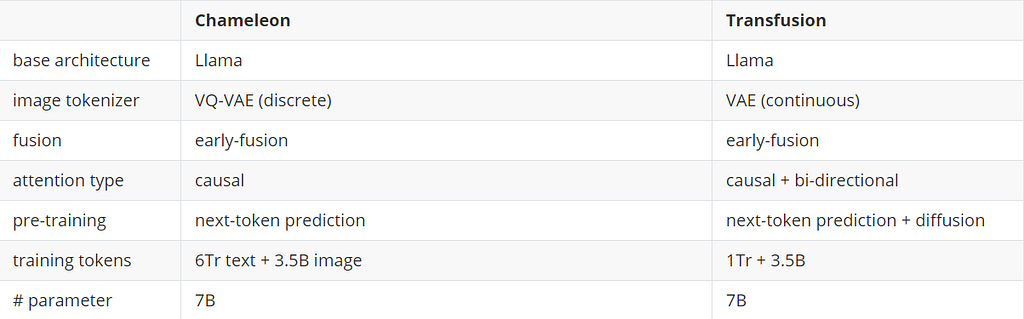
The paper lists the performance comparison over the Llama2 pre-training suite accuracy, COCO zero-shot Frechet Inception Distance (FID) and GenEval benchmark. We can see that the Transfusion performs much better than Chameleon on the image-related benchmarks (COCO and Gen) while losing very little margin compared to Chameleon, with the same amount of parameters.
Further Comments.
Although the idea of the paper is super interesting, the “Diffusion” part of the Transfusion is hardly an actual Diffusion, as there are only two timestamps in the Markov process. Besides, the pre-trained VAE makes the model no longer strictly end-to-end. Also, the VAE + Linear/UNet + Transformer Encoder + Linear/UNet + VAE design looks so complicated, which makes the audience can’t help but ask, is there a more elegant way to implement this idea? Besides, I previously wrote about the latest publication from Apple on the generalization benefits of using autoregressive modelling on images, so it might be interesting to give a second thought to the “MIM + autoregressive” approach.
If you find this post interesting and would like to discuss it, you’re welcome to leave a comment, and I’m happy to further the discussion there 🙂
References
- Zhou et al., Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model. arXiv 2024.
- Team C. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint 2024.
- Touvron et al., Llama: Open and efficient foundation language models. arXiv 2023.
- Rombach et al., High-resolution image synthesis with latent diffusion models. CVPR 2022.
- Ho et al., Denoising diffusion probabilistic models. NeurIPS 2020.
- Vaswani, Attention is all you need. NeurIPS 2017.
- Kingma, Auto-encoding variational bayes. arXiv preprint 2013.
Transformer? Diffusion? Transfusion! was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Transformer? Diffusion? Transfusion!
Go Here to Read this Fast! Transformer? Diffusion? Transfusion!