One answer and many best practices for how larger organizations can operationalizing data quality programs for modern data platforms
I’ve spoken with dozens of enterprise data professionals at the world’s largest corporations, and one of the most common data quality questions is, “who does what?” This is quickly followed by, “why and how?”
There is a reason for this. Data quality is like a relay race. The success of each leg — detection, triage, resolution, and measurement — depends on the other. Every time the baton is passed, the chances of failure skyrocket.

Practical questions deserve practical answers.
However, every organization is organized around data slightly differently. I’ve seen organizations with 15,000 employees centralize ownership of all critical data while organizations half their size decide to completely federate data ownership across business domains.
For the purposes of this article, I’ll be referencing the most common enterprise architecture which is a hybrid of the two. This is the aspiration for most data teams, and it also features many cross-team responsibilities that make it particularly complex and worth discussing.
Just keep in mind what follows is AN answer, not THE answer.
In This Article:
The Importance of Data Products
Whether pursuing a data mesh strategy or something else entirely, a common realization for modern data teams is the need to align around and invest in their most valuable data products.
This is a designation given to a dataset, application, or service with an output particularly valuable to the business. This could be a revenue generating machine learning application or a suite of insights derived from well curated data.
As scale and sophistication grows, data teams will further differentiate between foundational and derived data products. A foundational data product is typically owned by a central data platform team (or sometimes a source aligned data engineering team). They are designed to serve hundreds of use cases across many teams or business domains.
Derived data products are built atop of these foundational data products. They are owned by domain aligned data teams and designed for a specific use case.
For example, a “Single View of Customer” is a common foundational data product that might feed derived data products such as a product up-sell model, churn forecasting, and an enterprise dashboard.
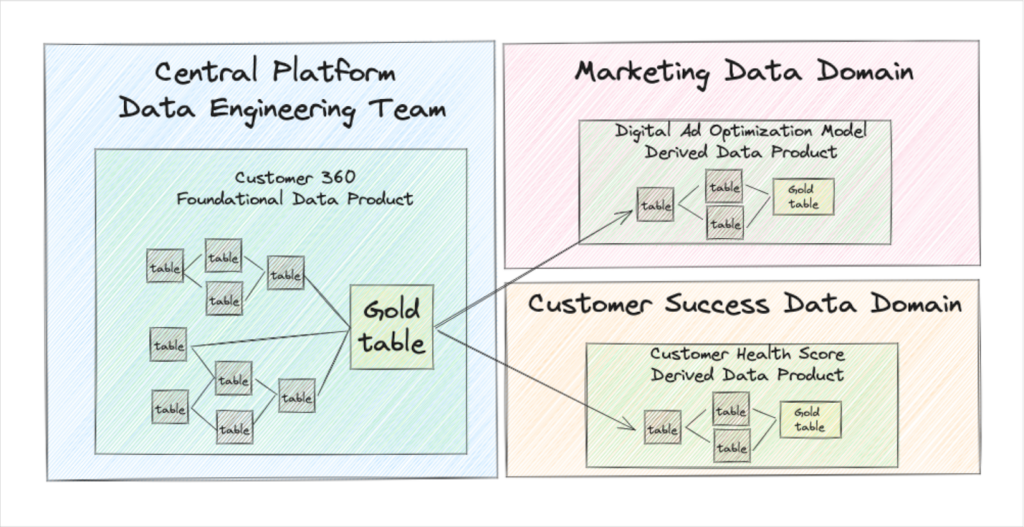
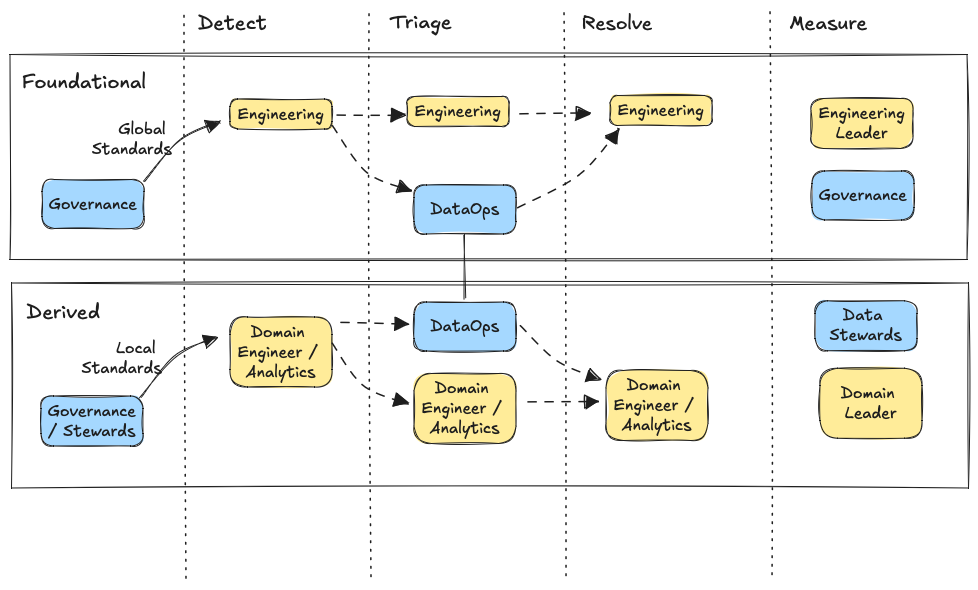
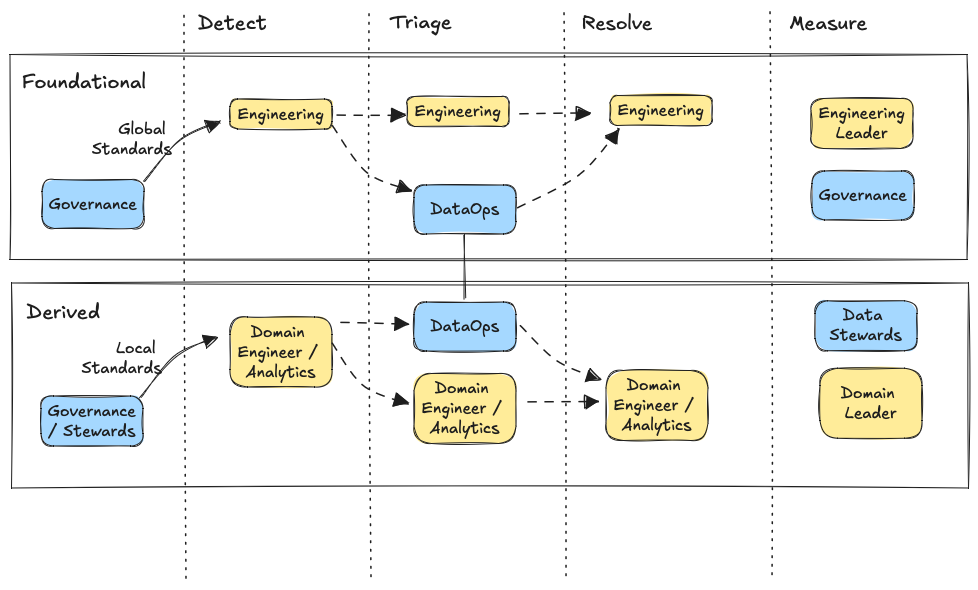
There are different processes for detecting, triaging, resolving, and measuring data quality incidents across these two data product types. Bridging the chasm between them is vital. Here’s one popular way I’ve seen data teams do it.
Detection
Foundational Data Products
Prior to becoming discoverable, there should be a designated data platform engineering owner for every foundational data product. This is the team responsible for applying monitoring for freshness, volume, schema, and baseline quality end-to-end across the entire pipeline. A good rule of thumb most teams follow is, “you built it, you own it.”
By baseline quality, I am referring very specifically to requirements that can be broadly generalized across many datasets and domains. They are often defined by a central governance team for critical data elements and generally conform to the 6 dimensions of data quality. Requirements like “id columns should always be unique,” or “this field is always formatted as valid US state code.”
In other words, foundational data product owners cannot simply ensure the data arrives on time. They need to ensure the source data is complete and valid; data is consistent across sources and subsequent loads; and critical fields are free from error. Machine learning anomaly detection models can be particularly effective in this regard.
More precise and customized data quality requirements are typically use case dependent, and better applied by derived data product owners and analysts downstream.
Derived Data Products
Data quality monitoring also needs to occur at the derived data product level as bad data can infiltrate at any point in the data lifecycle.

However, at this level there is more surface area to cover. “Monitoring all tables for every possibility” isn’t a practical option.
There are many factors for when a collection of tables should become a derived data product, but they can all be boiled down to a judgment of sustained value. This is often best executed by domain based data stewards who are close to the business and empowered to follow general guidelines around frequency and criticality of usage.
For example, one of my colleagues in his previous role as the head of data platform at a national media company, had an analyst develop a Master Content dashboard that quickly became popular across the newsroom. Once it became ingrained in the workflow of enough users, they realized this ad-hoc dashboard needed to become productized.
When a derived data product is created or identified, it should have a domain aligned owner responsible for end-to-end monitoring and baseline data quality. For many organizations that will be domain data stewards as they are most familiar with global and local policies. Other ownership models include designating the embedded data engineer that built the derived data product pipeline or the analyst that owns the last mile table.
The other key difference in the detection workflow at the derived data product level are business rules.
There are some data quality rules that can’t be automated or generated from central standards. They can only come from the business. Rules like, “the discount_percentage field can never be greater than 10 when the account_type equals commercial and customer_region equals EMEA.”
These rules are best applied by analysts, specifically the table owner, based on their experience and feedback from the business. There is no need for every rule to trigger the creation of a data product, it’s too heavy and burdensome. This process should be completely decentralized, self-serve, and lightweight.
Triage
Foundational Data Products
In some ways, ensuring data quality for foundational data products is less complex than for derived data products. There are fewer foundational products by definition, and they are typically owned by technical teams.
This means the data product owner, or an on-call data engineer within the platform team, can be responsible for common triage tasks such as responding to alerts, determining a likely point of origin, assessing severity, and communicating with consumers.
Every foundational data product should have at least one dedicated alert channel in Slack or Teams.
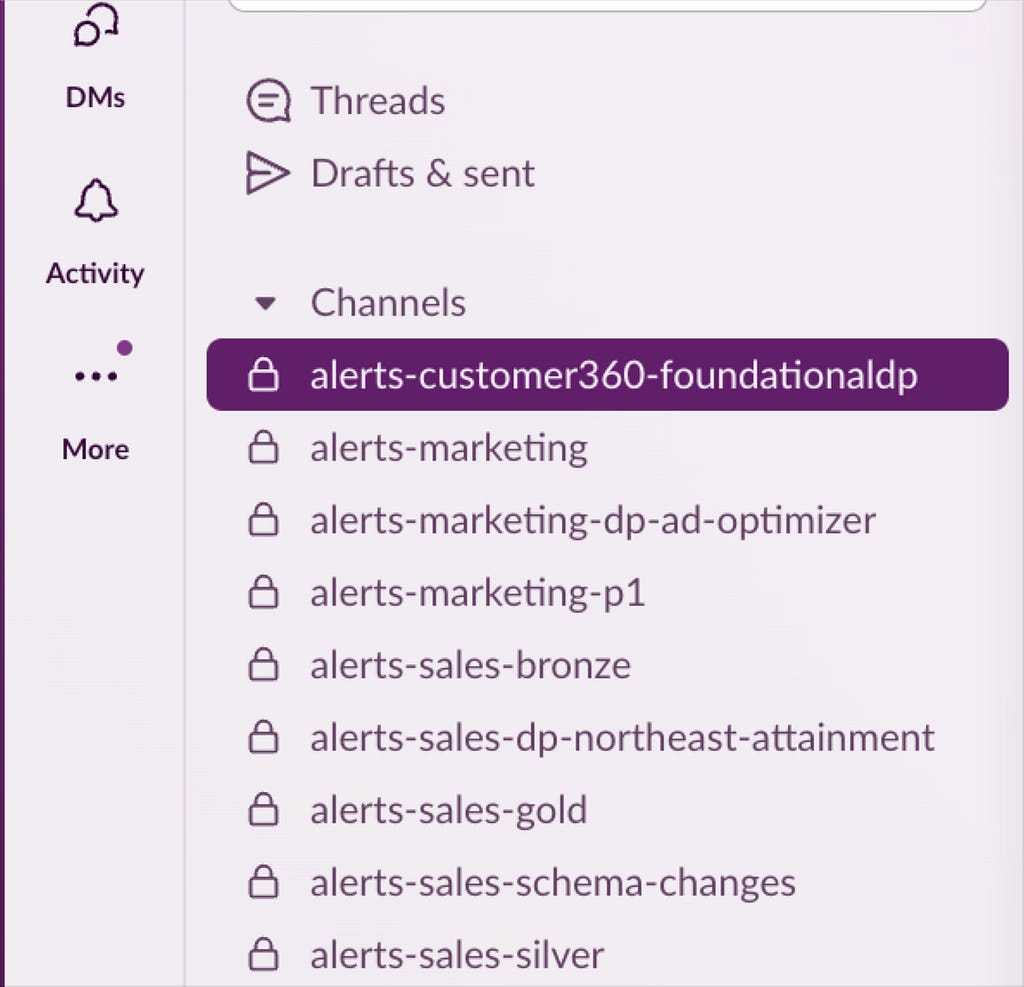
This avoids the alert fatigue and can serve as a central communication channel for all derived data product owners with dependencies. To the extent they’d like, they can stay abreast of issues and be proactively informed of any upcoming schema or other changes that may impact their operations.
Derived Data Products
Typically, there are too many derived data products for data engineers to properly triage given their bandwidth.
Making each derived data product owner responsible for triaging alerts is a commonly deployed strategy (see image below), but it can also break down as the number of dependencies grow.
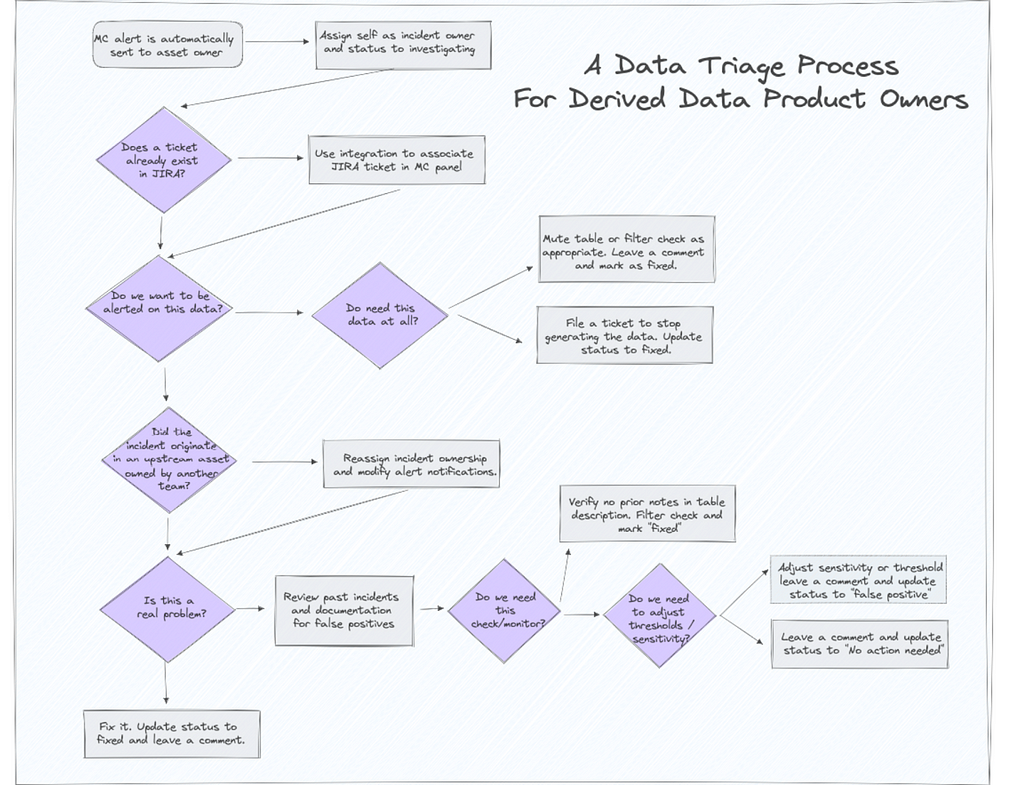
A failed orchestration job, for example, can cascade downstream creating dozens alerts across multiple data product owners. The overlapping fire drills are a nightmare.
One increasingly adopted best practice is for a dedicated triage team (often labeled as dataops) to support all products within a given domain.
This can be a Goldilocks zone that reaps the efficiencies of specialization, without becoming so impossibly large that they become a bottleneck devoid of context. These teams must be coached and empowered to work across domains, or you will simply reintroduce the silos and overlapping fire drills.
In this model the data product owner has accountability, but not responsibility.
Resolution
Wakefield Research surveyed more than 200 data professionals, and the average incidents per month was 60 and the median time to resolve each incident once detected was 15 hours. It’s easy to see how data engineers get buried in backlog.
There are many contributing factors for this, but the biggest is that we’ve separated the anomaly from the root cause both technologically and procedurally. Data engineers look after their pipelines and analysts look after their metrics. Data engineers set their Airflow alerts and analysts write their SQL rules.
But pipelines–the data sources, the systems that move the data, and the code that transforms it–are the root cause for why metric anomalies occur.
To reduce the average time to resolution, these technical troubleshooters need a data observability platform or some sort of central control plane that connects the anomaly to the root cause. For example, a solution that surfaces how a distribution anomaly in the discount_amount field is related to an upstream query change that occurred at the same time.
Measure
Foundational Data Products
Speaking of proactive communications, measuring and surfacing the health of foundational data products is vital to their adoption and success. If the consuming domains downstream don’t trust the quality of the data or the reliability of its delivery, they will go straight to the source. Every. Single. Time.
This of course defeats the entire purpose of foundational data products. Economies of scale, standard onboarding governance controls, clear visibility into provenance and usage are now all out of the window.
It can be challenging to provide a general standard of data quality that is applicable to a diverse set of use cases. However, what data teams downstream really want to know is:
- How often is the data refreshed?
- How well maintained is it? How quickly are incidents resolved?
- Will there be frequent schema changes that break my pipelines?
Data governance teams can help here by uncovering these common requirements and critical data elements to help set and surface smart SLAs in a marketplace or catalog (more specifics than you could ever want on implementation here).
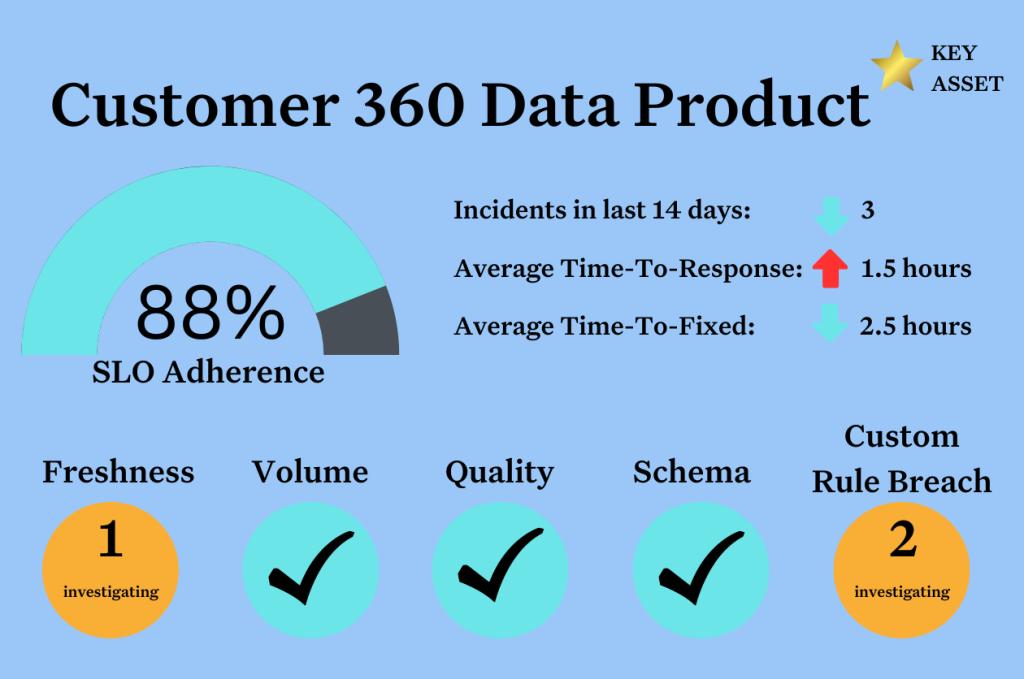
This is the approach of the Roche data team that has created one of the most successful enterprise data meshes in the world, which they estimate has generated about 200 data products and an estimated $50 million of value.
Derived Data Products
For derived data products, explicit SLAs across should be set based on the defined use case. For instance, a financial report may need to be highly accurate with some margin for timeliness whereas a machine learning model may be the exact opposite.
Table level health scores can be helpful, but the common mistake is to assume that on a shared table the business rules placed by one analyst will be relevant to another. A table appears to be of low quality, but upon closer inspection a few outdated rules have repeatedly failed day after day without any action taking place to either resolve the issue or the rule’s threshold.
Going For Data Quality Gold
We covered a lot of ground. This article was more marathon than relay race.
The above workflows are a way to be successful with data quality and data observability programs but they aren’t the only way. If you prioritize clear processes for:
- Data product creation and ownership;
- Applying end-to-end coverage across those data products;
- Self-serve business rules for downstream assets;
- Responding to and investigating alerts;
- Accelerating root cause analysis; and
- Building trust by communicating data health and operational response
…you will find your team crossing the data quality finish line.
Follow me on Medium for more stories on data engineering, data quality, and related topics.
The “Who Does What” Guide To Enterprise Data Quality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The “Who Does What” Guide To Enterprise Data Quality
Go Here to Read this Fast! The “Who Does What” Guide To Enterprise Data Quality