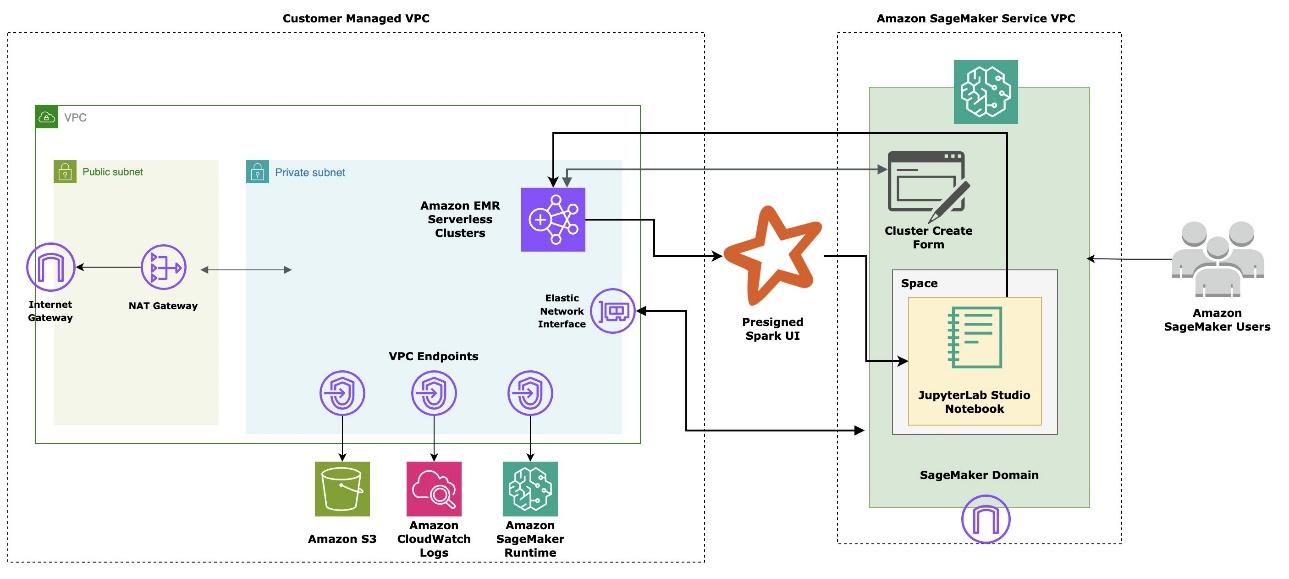

In this post, we explore how to build a scalable and efficient Retrieval Augmented Generation (RAG) system using the new EMR Serverless integration, Spark’s distributed processing, and an Amazon OpenSearch Service vector database powered by the LangChain orchestration framework. This solution enables you to process massive volumes of textual data, generate relevant embeddings, and store them in a powerful vector database for seamless retrieval and generation.
Originally appeared here:
Use LangChain with PySpark to process documents at massive scale with Amazon SageMaker Studio and Amazon EMR Serverless