Revisiting CPU for ML in an Era of GPU Scarcity

The recent successes in AI are often attributed to the emergence and evolutions of the GPU. The GPU’s architecture, which typically includes thousands of multi-processors, high-speed memory, dedicated tensor cores, and more, is particularly well-suited to meet the intensive demands of AI/ML workloads. Unfortunately, the rapid growth in AI development has led to a surge in the demand for GPUs, making them difficult to obtain. As a result, ML developers are increasingly exploring alternative hardware options for training and running their models. In previous posts, we discussed the possibility of training on dedicated AI ASICs such as Google Cloud TPU, Haban Gaudi, and AWS Trainium. While these options offer significant cost-saving opportunities, they do not suit all ML models and can, like the GPU, also suffer from limited availability. In this post we return to the good old-fashioned CPU and revisit its relevance to ML applications. Although CPUs are generally less suited to ML workloads compared to GPUs, they are much easier to acquire. The ability to run (at least some of) our workloads on CPU could have significant implications on development productivity.
In previous posts (e.g., here) we emphasized the importance of analyzing and optimizing the runtime performance of AI/ML workloads as a means of accelerating development and minimizing costs. While this is crucial regardless of the compute engine used, the profiling tools and optimization techniques can vary greatly between platforms. In this post, we will discuss some of the performance optimization options that pertain to CPU. Our focus will be on Intel® Xeon® CPU processors (with Intel® AVX-512) and on the PyTorch (version 2.4) framework (although similar techniques can be applied to other CPUs and frameworks, as well). More specifically, we will run our experiments on an Amazon EC2 c7i instance with an AWS Deep Learning AMI. Please do not view our choice of Cloud platform, CPU version, ML framework, or any other tool or library we should mention, as an endorsement over their alternatives.
Our goal will be to demonstrate that although ML development on CPU may not be our first choice, there are ways to “soften the blow” and — in some cases — perhaps even make it a viable alternative.
Disclaimers
Our intention in this post is to demonstrate just a few of the ML optimization opportunities available on CPU. Contrary to most of the online tutorials on the topic of ML optimization on CPU, we will focus on a training workload rather than an inference workload. There are a number of optimization tools focused specifically on inference that we will not cover (e.g., see here and here).
Please do not view this post as a replacement of the official documentation on any of the tools or techniques that we mention. Keep in mind that given the rapid pace of AI/ML development, some of the content, libraries, and/or instructions that we mention may become outdated by the time you read this. Please be sure to refer to the most-up-to-date documentation available.
Importantly, the impact of the optimizations that we discuss on runtime performance is likely to vary greatly based on the model and the details of the environment (e.g., see the high degree of variance between models on the official PyTorch TouchInductor CPU Inference Performance Dashboard). The comparative performance numbers we will share are specific to the toy model and runtime environment that we will use. Be sure to reevaluate all of the proposed optimizations on your own model and runtime environment.
Lastly, our focus will be solely on throughput performance (as measured in samples per second) — not on training convergence. However, it should be noted that some optimization techniques (e.g., batch size tuning, mixed precision, and more) could have a negative effect on the convergence of certain models. In some cases, this can be overcome through appropriate hyperparameter tuning.
Toy Example — ResNet-50
We will run our experiments on a simple image classification model with a ResNet-50 backbone (from Deep Residual Learning for Image Recognition). We will train the model on a fake dataset. The full training script appears in the code block below (loosely based on this example):
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import time
# A dataset with random images and labels
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=index % 10, dtype=torch.uint8)
return rand_image, label
train_set = FakeDataset()
batch_size=128
num_workers=0
train_loader = DataLoader(
dataset=train_set,
batch_size=batch_size,
num_workers=num_workers
)
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
batch_time = time.perf_counter() - t0
if idx > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if idx > 100:
break
print(f'average step time: {summ/count}')
print(f'throughput: {count*batch_size/summ}')
Running this script on a c7i.2xlarge (with 8 vCPUs) and the CPU version of PyTorch 2.4, results in a throughput of 9.12 samples per second. For the sake of comparison, we note that the throughput of the same (unoptimized script) on an Amazon EC2 g5.2xlarge instance (with 1 GPU and 8 vCPUs) is 340 samples per second. Taking into account the comparative costs of these two instance types ($0.357 per hour for a c7i.2xlarge and $1.212 for a g5.2xlarge, as of the time of this writing), we find that training on the GPU instance to give roughly eleven(!!) times better price performance. Based on these results, the preference for using GPUs to train ML models is very well founded. Let’s assess some of the possibilities for reducing this gap.
PyTorch Performance Optimizations
In this section we will explore some basic methods for increasing the runtime performance of our training workload. Although you may recognize some of these from our post on GPU optimization, it is important to highlight a significant difference between training optimization on CPU and GPU platforms. On GPU platforms much of our effort was dedicated to maximizing the parallelization between (the training data preprocessing on) the CPU and (the model training on) the GPU. On CPU platforms all of the processing occurs on the CPU and our goal will be to allocate its resources most effectively.
Batch Size
Increasing the training batch size can potentially increase performance by reducing the frequency of the model parameter updates. (On GPUs it has the added benefit of reducing the overhead of CPU-GPU transactions such as kernel loading). However, while on GPU we aimed for a batch size that would maximize the utilization of the GPU memory, the same strategy might hurt performance on CPU. For reasons beyond the scope of this post, CPU memory is more complicated and the best approach for discovering the most optimal batch size may be through trial and error. Keep in mind that changing the batch size could affect training convergence.
The table below summarizes the throughput of our training workload for a few (arbitrary) choices of batch size:
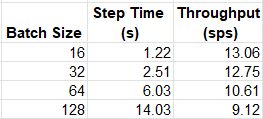
Contrary to our findings on GPU, on the c7i.2xlarge instance type our model appears to prefer lower batch sizes.
Multi-process Data Loading
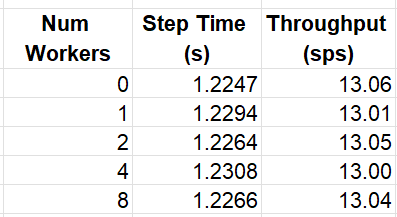
A common technique on GPUs is to assign multiple processes to the data loader so as to reduce the likelihood of starvation of the GPU. On GPU platforms, a general rule of thumb is to set the number of workers according to the number of CPU cores. However, on CPU platforms, where the model training uses the same resources as the data loader, this approach could backfire. Once again, the best approach for choosing the optimal number of workers may be trial and error. The table below shows the average throughput for different choices of num_workers:
Mixed Precision
Another popular technique is to use lower precision floating point datatypes such as torch.float16 or torch.bfloat16 with the dynamic range of torch.bfloat16 generally considered to be more amiable to ML training. Naturally, reducing the datatype precision can have adverse effects on convergence and should be done carefully. PyTorch comes with torch.amp, an automatic mixed precision package for optimizing the use of these datatypes. Intel® AVX-512 includes support for the bfloat16 datatype. The modified training step appears below:
for idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
with torch.amp.autocast('cpu',dtype=torch.bfloat16):
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
The throughput following this optimization is 24.34 samples per second, an increase of 86%!!
Channels Last Memory Format
Channels last memory format is a beta-level optimization (at the time of this writing), pertaining primarily to vision models, that supports storing four dimensional (NCHW) tensors in memory such that the channels are the last dimension. This results in all of the data of each pixel being stored together. This optimization pertains primarily to vision models. Considered to be more “friendly to Intel platforms”, this memory format is reported boost the performance of a ResNet-50 on an Intel® Xeon® CPU. The adjusted training step appears below:
for idx, (data, target) in enumerate(train_loader):
data = data.to(memory_format=torch.channels_last)
optimizer.zero_grad()
with torch.amp.autocast('cpu',dtype=torch.bfloat16):
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
The resulting throughput is 37.93 samples per second — an additional 56% improvement and a total of 415% compared to our baseline experiment. We are on a role!!
Torch Compilation
In a previous post we covered the virtues of PyTorch’s support for graph compilation and its potential impact on runtime performance. Contrary to the default eager execution mode in which each operation is run independently (a.k.a., “eagerly”), the compile API converts the model into an intermediate computation graph which is then JIT-compiled into low-level machine code in a manner that is optimal for the underlying training engine. The API supports compilation via different backend libraries and with multiple configuration options. Here we will limit our evaluation to the default (TorchInductor) backend and the ipex backend from the Intel® Extension for PyTorch, a library with dedicated optimizations for Intel hardware. Please see the documentation for appropriate installation and usage instructions. The updated model definition appears below:
import intel_extension_for_pytorch as ipex
model = torchvision.models.resnet50()
backend='inductor' # optionally change to 'ipex'
model = torch.compile(model, backend=backend)
In the case of our toy model, the impact of torch compilation is only apparent when the “channels last” optimization is disabled (and increase of ~27% for each of the backends). When “channels last” is applied, the performance actually drops. As a result, we drop this optimization from our subsequent experiments.
Memory and Thread Optimizations
There are a number of opportunities for optimizing the use of the underlying CPU resources. These include optimizing memory management and thread allocation to the structure of the underlying CPU hardware. Memory management can be improved through the use of advanced memory allocators (such as Jemalloc and TCMalloc) and/or reducing memory accesses that are slower (i.e., across NUMA nodes). Threading allocation can be improved through appropriate configuration of the OpenMP threading library and/or use of Intel’s Open MP library.
Generally speaking, these kinds of optimizations require a deep level understanding of the CPU architecture and the features of its supporting SW stack. To simplify matters, PyTorch offers the torch.backends.xeon.run_cpu script for automatically configuring the memory and threading libraries so as to optimize runtime performance. The command below will result in the use of the dedicated memory and threading libraries. We will return to the topic of NUMA nodes when we discuss the option of distributed training.
We verify appropriate installation of TCMalloc (conda install conda-forge::gperftools) and Intel’s Open MP library (pip install intel-openmp), and run the following command.
python -m torch.backends.xeon.run_cpu train.py
The use of the run_cpu script further boosts our runtime performance to 39.05 samples per second. Note that the run_cpu script includes many controls for further tuning performance. Be sure to check out the documentation in order to maximize its use.
The Intel Extension for PyTorch
The Intel® Extension for PyTorch includes additional opportunities for training optimization via its ipex.optimize function. Here we demonstrate its default use. Please see the documentation to learn of its full capabilities.
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
model, optimizer = ipex.optimize(
model,
optimizer=optimizer,
dtype=torch.bfloat16
)
Combined with the memory and thread optimizations discussed above, the resultant throughput is 40.73 samples per second. (Note that a similar result is reached when disabling the “channels last” configuration.)
Distributed Training on CPU
Intel® Xeon® processors are designed with Non-Uniform Memory Access (NUMA) in which the CPU memory is divided into groups, a.k.a., NUMA nodes, and each of the CPU cores is assigned to one node. Although any CPU core can access the memory of any NUMA node, the access to its own node (i.e., its local memory) is much faster. This gives rise to the notion of distributing training across NUMA nodes, where the CPU cores assigned to each NUMA node act as a single process in a distributed process group and data distribution across nodes is managed by Intel® oneCCL, Intel’s dedicated collective communications library.
We can run data distributed training across NUMA nodes easily using the ipexrun utility. In the following code block (loosely based on this example) we adapt our script to run data distributed training (according to usage detailed here):
import os, time
import torch
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist
import torchvision
import oneccl_bindings_for_pytorch as torch_ccl
import intel_extension_for_pytorch as ipex
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["RANK"] = os.environ.get("PMI_RANK", "0")
os.environ["WORLD_SIZE"] = os.environ.get("PMI_SIZE", "1")
dist.init_process_group(backend="ccl", init_method="env://")
rank = os.environ["RANK"]
world_size = os.environ["WORLD_SIZE"]
batch_size = 128
num_workers = 0
# define dataset and dataloader
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=index % 10, dtype=torch.uint8)
return rand_image, label
train_dataset = FakeDataset()
dist_sampler = DistributedSampler(train_dataset)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
sampler=dist_sampler
)
# define model artifacts
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
model, optimizer = ipex.optimize(
model,
optimizer=optimizer,
dtype=torch.bfloat16
)
# configure DDP
model = torch.nn.parallel.DistributedDataParallel(model)
# run training loop
# destroy the process group
dist.destroy_process_group()
Unfortunately, as of the time of this writing, the Amazon EC2 c7i instance family does not include a multi-NUMA instance type. To test our distributed training script, we revert back to a Amazon EC2 c6i.32xlarge instance with 64 vCPUs and 2 NUMA nodes. We verify the installation of Intel® oneCCL Bindings for PyTorch and run the following command (as documented here):
source $(python -c "import oneccl_bindings_for_pytorch as torch_ccl;print(torch_ccl.cwd)")/env/setvars.sh
# This example command would utilize all the numa sockets of the processor, taking each socket as a rank.
ipexrun cpu --nnodes 1 --omp_runtime intel train.py
The following table compares the performance results on the c6i.32xlarge instance with and without distributed training:
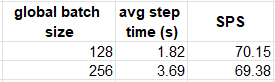
In our experiment, data distribution did not boost the runtime performance. Please see ipexrun documentation for additional performance tuning options.
CPU Training with Torch/XLA
In previous posts (e.g., here) we discussed the PyTorch/XLA library and its use of XLA compilation to enable PyTorch based training on XLA devices such as TPU, GPU, and CPU. Similar to torch compilation, XLA uses graph compilation to generate machine code that is optimized for the target device. With the establishment of the OpenXLA Project, one of the stated goals was to support high performance across all hardware backends, including CPU (see the CPU RFC here). The code block below demonstrates the adjustments to our original (unoptimized) script required to train using PyTorch/XLA:
import torch
import torchvision
import timeimport torch_xla
import torch_xla.core.xla_model as xm
device = xm.xla_device()
model = torchvision.models.resnet50().to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
model.train()
for idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
xm.mark_step()
Unfortunately, (as of the time of this writing) the XLA results on our toy model seem far inferior to the (unoptimized) results we saw above (— by as much as 7X). We expect this to improve as PyTorch/XLA’s CPU support matures.
Results
We summarize the results of a subset of our experiments in the table below. For the sake of comparison, we add the throughput of training our model on Amazon EC2 g5.2xlarge GPU instance following the optimization steps discussed in this post. The samples per dollar was calculated based on the Amazon EC2 On-demand pricing page ($0.357 per hour for a c7i.2xlarge and $1.212 for a g5.2xlarge, as of the time of this writing).
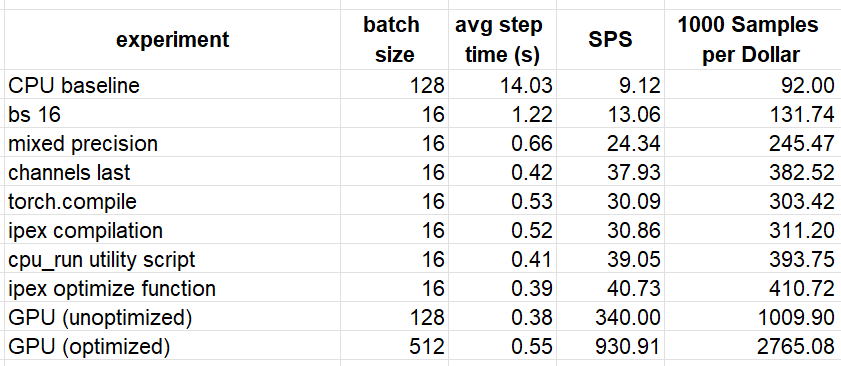
Although we succeeded in boosting the training performance of our toy model on the CPU instance by a considerable margin (446%), it remains inferior to the (optimized) performance on the GPU instance. Based on our results, training on GPU would be ~6.7 times cheaper. It is likely that with additional performance tuning and/or applying additional optimizations strategies, we could further close the gap. Once again, we emphasize that the comparative performance results we have reached are unique to this model and runtime environment.
Amazon EC2 Spot Instances Discounts
The increased availability of cloud-based CPU instance types (compared to GPU instance types) may imply greater opportunity for obtaining compute power at discounted rates, e.g., through Spot Instance utilization. Amazon EC2 Spot Instances are instances from surplus cloud service capacity that are offered for a discount of as much as 90% off the On-Demand pricing. In exchange for the discounted price, AWS maintains the right to preempt the instance with little to no warning. Given the high demand for GPUs, you may find CPU spot instances easier to get ahold of than their GPU counterparts. At the time of this writing, c7i.2xlarge Spot Instance price is $0.1291 which would improve our samples per dollar result to 1135.76 and further reduces the gap between the optimized GPU and CPU price performances (to 2.43X).
While the runtime performance results of the optimized CPU training of our toy model (and our chosen environment) were lower than the GPU results, it is likely that the same optimization steps applied to other model architectures (e.g., ones that include components that are not supported by GPU) may result in the CPU performance matching or beating that of the GPU. And even in cases where the performance gap is not bridged, there may very well be cases where the shortage of GPU compute capacity would justify running some of our ML workloads on CPU.
Summary
Given the ubiquity of the CPU, the ability to use them effectively for training and/or running ML workloads could have huge implications on development productivity and on end-product deployment strategy. While the nature of the CPU architecture is less amiable to many ML applications when compared to the GPU, there are many tools and techniques available for boosting its performance — a select few of which we have discussed and demonstrated in this post.
In this post we focused optimizing training on CPU. Please be sure to check out our many other posts on medium covering a wide variety of topics pertaining to performance analysis and optimization of machine learning workloads.
Training AI Models on CPU was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Training AI Models on CPU