
An accessible guide to leveraging causal machine learning for optimizing client retention strategies
Details of this series
This article is the second in a series on uplift modeling and causal machine learning. The idea is to dive deep into these methodologies both from a business and a technical perspective.
Before jumping into this one, I highly recommend reading the previous episode which explains what uplift modeling is and how it can help your company in general.
Link can be found below.
From insights to impact: leveraging data science to maximize customer value
Introduction
Picture this: you’ve been a client of a bank for a couple years. However, for a month or two, you’ve been considering leaving because their application has become too complicated. Suddenly, an employee of the bank calls you. He asks about your experience and ends up quickly explaining to you how to use the app. In the meantime, your daughter, who’s a client of the same bank also thinks about leaving them because of their trading fees; she thinks they’re too expensive. While about to unsubscribe, out of the blue, she receives a voucher allowing her to trade for free for a month! How is that even possible?
In my previous article, I introduced the mysterious technique behind this level of personalisation: uplift modeling. When traditional approaches usually predict an outcome — e.g. the probability of churn of a customer— , uplift modeling predicts the potential result of an action taken on a customer. The likelihood of a customer staying if called or if offered a voucher, for example!
This approach allows us to target the right customers — as we’ll be removing customers who wouldn’t react positively to our approach — but also to increase our chance of success by tailoring our approach to each customer. Thanks to uplift modeling, not only do we focus our resources toward the right population, we also maximise their impact!
Sounds interesting, wouldn’t you agree? Well this is your lucky day as in this article we’ll dive deep into the implementation of this approach by solving a concrete example: improving our retention. We’ll go through every step, from defining our precise use case to evaluating our models results. Our goal today is to provide you with the right knowledge and tools to be able to apply this technique within your own organisation, adapted to your own data and use case, of course.
Here’s what we’ll cover:
- We’ll start by clearly defining our use case. What is churn? Who do we target? What actions will we set up to try and retain our clients with?
- Then, we’ll look into getting the right data for the job. What data do we need to implement uplift modeling and how to get it?
- After that, we’ll look into the actual modeling, focusing on understanding the various models behind uplift modeling.
- Then, we’ll apply our newly acquired knowledge to a first case with a single retention action: an email campaign.
- Finally, we’ll deep dive into a more complicated implementation with many treatments, approaching user-level personalisation
Our use case: improving customer retention
Before we can apply uplift modeling to improve customer retention, we need to clearly define the context. What constitutes “churn” in our business context? Do we want to target specific users? If yes, why? Which actions do we plan on setting up to retain them? Do we have budget constraints? Let’s try answering these questions.
Defining Churn
This is our first step. By precisely and quantitatively defining churn, we’ll be able to define retention and understand where we stand, how it has evolved and, if needed, take action. The churn definition you’ll choose will 100% depend on your business model and sector. Here are some factors to consider:
- If you’re in a transaction-based company, you can look at transaction frequency, or transaction volumes evolution. You could also look at the time since the last transaction occured or a drop in account activity.
- If you’re in a subscription based company, it can be as simple as looking at users who have unsubscribed, or subscribed users who have stopped using the product.
If you’re working in a transaction based tech company, churn could be defined as “customer who has not done a transaction in 90 days”, whereas if you’re working for a mobile app you may prefer to define it as “customer who has not logged in in 30 days”. Both the time frame and the nature of churn has to be defined beforehand as flagging churned user will be our first step.
The complexity of your definition will depend on your company’s specificities as well as the number of metrics you want to consider. However, the idea is to set up definitions that provide thresholds that are easy to understand and that enable us identify churners.
Churn Prediction Window
Now that we know what churn is, we need to define exactly what we want to avoid. What I mean is, do we want to prevent customers from churning within the next 15 days or 30 days? Based on the answer here, you’ll have to organise your data in a specific manner, and define different retention actions. I would recommend not to be too optimistic here for 2 reasons:
- The longer the time horizon the harder it is for a model to have good performances.
- The longer we wait after the treatment, the harder it will be to capture its effect.
So let’s be reasonable here. If our definition of churn encompasses a 30-day timeframe, let’s go with a 30 days horizon and let’s try to limit churn within the next 30 days.
The idea is that our timeframe must give us enough time to implement our retention strategies and observe their impact on user behavior, while maintaining our models’ performances.
Selecting Target Users [Optional]
Another question we need to answer is: are we targeting a specific population with our retention actions? Multiple reasons could motivate such an idea.
- We noticed an increase in churn in a specific segment.
- We want to target highly valuable customers to maximize our ROI with those actions.
- We want to target new customers to ensure a durable activation.
- We want to target customers that are likely to churn soon.
Depending on your own use case, you may want to select only a subset of your customers.
In our case, we’ll choose to target clients with a higher probability of churn, so that we target customers that need us most.
Defining retention Actions
Finally, we have to select the actual retention actions we want to use on our clients. This is not an easy one, and working alongside your business stakeholders here is probably a good idea. In our case, we’ll select 4 different actions:
- Personalized email
- In-app notifications highlighting new features or opportunities
- Directly calling our customer
- Special offers or discounts — another uplift model could help us identify the best voucher amount, should we explore that next?
Our uplift model will help us determine which of these actions (if any) is most likely to be effective for each individual user.
We’re ready! We defined churn, picked a prediction window, and selected the actions we want to retain our customers with. Now, the fun part begins, let’s gather some data and build a causal machine learning model!
Data gathering: the foundation of our uplift model
Building an effective uplift model requires a good dataset combining both existing user information with experimental data.
Leveraging existing user data
First, let’s look at our available data. Tech companies usually have access to a lot of those! In our case, we need customer level data such as:
- Customer information (like age, geography, gender, acquisition channel etc.)
- Product specifics (creation or subscription date, subscription tier etc.)
- Transactions information ( frequency of transactions, average transaction value, total spend, types of products/services purchased, time since last transaction etc.)
- Engagement (e.g., login frequency, time spent on platform, feature usage statistics, etc.)
We can look at this data raw, but what brings even more value is to understand how it evolves over time. It enables us to identify behavioral patterns that will likely improve our models’ performances. Lucky for us, it’s quite simple to do, we just have to look at our data from a different perspective; here are a few transformations that can help:
- Taking moving averages (7, 30 days…) of our main usage metrics — transactions for instance.
- Looking at the percentage changes over time.
- Aggregating our data at different time scales such as daily, weekly etc.
- Or even adding seasonality indicators such as the day of week or week of year.
These features bring “dynamic information” that could be valuable when it comes to detect future changes! Understanding more precisely which features we should select is beyond the scope of this article, however those approaches are best practices when it comes to work with temporal data.
Remember, our goal is to create a comprehensive user profile that evolves over time. This temporal data will serve as the foundation of our uplift model, enabling us to predict not who might churn, but who is most likely to respond positively to our retention efforts.
Gathering Experimental Data for Uplift Modeling
The second part of our data gathering journey is about collecting data related to our retention actions. Now, uplift modeling does not require experimental data. If you have historical data because of past events — you may already have sent emails to customers or offered vouchers — you can leverage those. However, the more recent and unbiased your data is, the better your results will be. Debiasing observational or non randomized data requires extra steps that we will not discuss here.
So what exactly do we need? Well, we need to have an idea of the impact of the actions you plan to take. We need to set up a randomized experiment where we test these actions. A lot of extremely good articles already discuss how to set those up, and I will not dive into it here. I just want to add that the better the setup, and the bigger the training set, the better it is us!
After the experiment, we’ll obviously analyse the results. And while those are not helping us directly in our quest, it will provide us with additional understanding of the expected impact of our treatments as well as a good effect baseline we’ll try to outperform with our models. Not to bore you too much with definitions and acronyms, but the result of a randomized experiment is called “Average treatment effect” or ATE. On our side, we’re looking to estimate the Conditional Average Treatment Effect (CATE), also known as Individual Treatment Effect (ITE).
While experimental data is ideal, uplift modeling can still provide insights with observational data if an experiment isn’t feasible. If not randomized, several techniques exists to debias our dataset, such as propensity score matching. The key is to have a rich dataset that captures user characteristics, behaviors, and outcomes in relation to our retention efforts.
Generating synthetic data
For the purpose of this example, we’ll be generating synthetic data using the causalml package from Uber. Uber has communicated a lot on uplift modeling and even created an easy to use and well documented Python package.
Here’s how we can generate our synthetic data if you’re curious about it.
import pandas as pd
from causalml.dataset import make_uplift_classification
# Dictionary specifying the number of features that will have a positive effect on retention for each treatment
n_uplift_increase_dict = {
"email_campaign": 2,
"in_app_notification": 3,
"call_campaign": 3,
"voucher": 4
}
# Dictionary specifying the number of features that will have a negative effect on retention for each treatment
n_uplift_decrease_dict = {
"email_campaign": 1,
"in_app_notification": 1,
"call_campaign": 2,
"voucher": 1
}
# Dictionary specifying the magnitude of positive effect on retention for each treatment
delta_uplift_increase_dict = {
"email_campaign": 0.05, # Email campaign increases retention by 5 percentage points
"in_app_notification": 0.03, # In-app notifications have a smaller but still positive effect
"call_campaign": 0.08, # Direct calls have a strong positive effect
"voucher": 0.10 # Vouchers have the strongest positive effect
}
# Dictionary specifying the magnitude of negative effect on retention for each treatment
delta_uplift_decrease_dict = {
"email_campaign": 0.02, # Email campaign might slightly decrease retention for some customers
"in_app_notification": 0.01, # In-app notifications have minimal negative effect
"call_campaign": 0.03, # Calls might annoy some customers more
"voucher": 0.02 # Vouchers might make some customers think the product is overpriced
}
# Dictionary specifying the number of mixed features (combination of informative and positive uplift) for each treatment
n_uplift_increase_mix_informative_dict = {
"email_campaign": 1,
"in_app_notification": 2,
"call_campaign": 1,
"voucher": 2
}
# Dictionary specifying the number of mixed features (combination of informative and negative uplift) for each treatment
n_uplift_decrease_mix_informative_dict = {
"email_campaign": 1,
"in_app_notification": 1,
"call_campaign": 1,
"voucher": 1
}
positive_class_proportion = 0.7 # Baseline retention rate
# Generate the dataset
df, feature_names = make_uplift_classification(
n_samples=20000, # Increased sample size for more robust results
treatment_name=['email_campaign', 'in_app_notification', 'call_campaign', 'voucher'],
y_name='retention',
n_classification_features=20, # Increased number of features
n_classification_informative=10,
n_uplift_increase_dict=n_uplift_increase_dict,
n_uplift_decrease_dict=n_uplift_decrease_dict,
delta_uplift_increase_dict=delta_uplift_increase_dict,
delta_uplift_decrease_dict=delta_uplift_decrease_dict,
n_uplift_increase_mix_informative_dict=n_uplift_increase_mix_informative_dict,
n_uplift_decrease_mix_informative_dict=n_uplift_decrease_mix_informative_dict,
positive_class_proportion=positive_class_proportion,
random_seed=42
)
#Encoding treatments variables
encoding_dict = {
'call_campaign': 3,
'email_campaign': 1,
'voucher': 4,
'in_app_notification':2,
'control': 0
}
# Create a new column with encoded values
df['treatment_group_numeric'] = df['treatment_group_key'].map(encoding_dict)
Ouf final data should be organized like this:
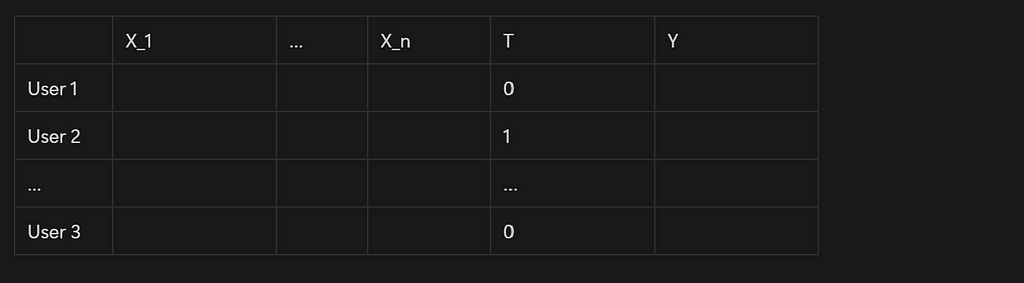
In a “real life use case”, this data would be aggregated at time level, for instance this would be for each user a daily or weekly aggregation of data gathered before we reached out to them.
- X_1 to X_n would be our user level features
- T would be the actual treatment (1 or 0, treatment or control, treatment 1, treatment 2, control depending on your use case)
- And Y is the actual outcome: did the user stay or not?
Data preparation
In our case, in order to analyse both our use cases, we need further preparation. Let’s create 2 distinct datasets — training and a testing set — for each use case:
- First use case: a single treatment case, where we’ll focus on a single retention strategy: sending email to our customers.
- Second use case: a multi treatment case, where we’ll compare the effectiveness of different treatments and most importantly find the best one for each customer.
from sklearn.model_selection import train_test_split
def prepare_data(df, feature_names, y_name, test_size=0.3, random_state=42):
"""
Prepare data for uplift modeling, including splitting into train and test sets,
and creating mono-treatment subsets.
"""
# Create binary treatment column
df['treatment_col'] = np.where(df['treatment_group_key'] == 'control', 0, 1)
# Split data into train and test sets
df_train, df_test = train_test_split(df, test_size=test_size, random_state=random_state)
# Create mono-treatment subsets
df_train_mono = df_train[df_train['treatment_group_key'].isin(['email_campaign', 'control'])]
df_test_mono = df_test[df_test['treatment_group_key'].isin(['email_campaign', 'control'])]
# Prepare features, treatment, and target variables for full dataset
X_train = df_train[feature_names].values
X_test = df_test[feature_names].values
treatment_train = df_train['treatment_group_key'].values
treatment_test = df_test['treatment_group_key'].values
y_train = df_train[y_name].values
y_test = df_test[y_name].values
# Prepare features, treatment, and target variables for mono-treatment dataset
X_train_mono = df_train_mono[feature_names].values
X_test_mono = df_test_mono[feature_names].values
treatment_train_mono = df_train_mono['treatment_group_key'].values
treatment_test_mono = df_test_mono['treatment_group_key'].values
y_train_mono = df_train_mono[y_name].values
y_test_mono = df_test_mono[y_name].values
return {
'df_train': df_train, 'df_test': df_test,
'df_train_mono': df_train_mono, 'df_test_mono': df_test_mono,
'X_train': X_train, 'X_test': X_test,
'X_train_mono': X_train_mono, 'X_test_mono': X_test_mono,
'treatment_train': treatment_train, 'treatment_test': treatment_test,
'treatment_train_mono': treatment_train_mono, 'treatment_test_mono': treatment_test_mono,
'y_train': y_train, 'y_test': y_test,
'y_train_mono': y_train_mono, 'y_test_mono': y_test_mono
}
# Usage
data = prepare_data(df, feature_names, y_name)
# Print shapes for verification
print(f"Full test set shape: {data['df_test'].shape}")
print(f"Mono-treatment test set shape: {data['df_test_mono'].shape}")
# Access prepared data
df_train, df_test = data['df_train'], data['df_test']
df_train_mono, df_test_mono = data['df_train_mono'], data['df_test_mono']
X_train, y_train = data['X_train'], data['y_train']
X_test, y_test = data['X_test'], data['y_test']
X_train_mono, y_train_mono = data['X_train_mono'], data['y_train_mono']
X_test_mono, y_test_mono = data['X_test_mono'], data['y_test_mono']
treatment_train, treatment_test = data['treatment_train'], data['treatment_test']
treatment_train_mono, treatment_test_mono = data['treatment_train_mono'], data['treatment_test_mono']
Now that our data is ready, let’s go through a bit of theory and investigate the different approaches available to us!
Understanding uplift modeling approaches
As we now know, uplift modeling uses machine learning algorithms to estimate the heterogeneous treatment effect of an intervention on a population. This modelling approach focuses on the Conditional Average Treatment Effect (CATE), which quantifies the expected difference in outcome with and without the intervention for our customers.
Here are the main models we can use to estimate it:
Direct uplift modeling
- This approach is the simplest one. We simply use a specific algorithm, such as an uplift decision tree, which loss function is optimized to solve this problem. These models are designed to maximize the difference in outcomes between treated and untreated groups within the same model.
- We’ll be using an Uplift Random ForestClassifier as an example of this.
Meta-learners
- Meta-learners use known machine learning models to estimate the CATE. They can combine multiple models used in different ways, or be trained on the predictions of other models.
- While many exist, we’ll focus on two types : the S-Learner and the T-Learner
Let’s quickly understand what those are!
1. S-Learner (Single-Model)

The S-Learner is the simplest meta-learner of all. Why? Because it only consists of using a traditional machine learning model that includes the treatment feature as input. While simple to implement, it may struggle if the importance of the treatment variable is low.
2. T-Learner (Two-Model)

“The T-Learner tries to solve the problem of discarding the treatment entirely by forcing the learner to first split on it. Instead of using a single model, we will use one model per treatment variable.
In the binary case, there are only two models that we need to estimate (hence the name T)” Source [3]
Each of these approaches has its pros and cons. How well they work will depend on your data and what you’re trying to achieve.
In this article we’ll try out all three: an Uplift Random Forest Classifier, a S-Learner, and a T-Learner, and compare their performances when it comes to improving our company’s retention.
Single treatment uplift model implementation with causal ML
Model Training
Now let’s train our models. We’ll start with our direct uplift model, the uplift random forest classifier. Then we’ll train our meta models using an XGBoost regressor. Two things to note here:
- The algorithm choice behind your meta-models will obviously impact the final model performances, thus you may want to select it carefully.
- Yes, we’re selecting regressors as meta models rather than classifiers, mainly because they provide more flexibility, outputting a precise effect.
Here are the different steps you’ll find in the below code:
- We initialize our result dataframe
- Then we train each model on our training set
- Finally we predict our treatment effects on the test sets before saving the results
from causalml.inference.meta import BaseSRegressor, BaseTRegressor
from causalml.inference.tree import UpliftRandomForestClassifier
from xgboost import XGBRegressor
#save results in a df
df_results_mono = df_test_mono.copy()
# Initialize and train a randomForest Classifier
rfc = UpliftRandomForestClassifier(control_name='control')
rfc.fit(X_train_mono, treatment_train_mono, y_train_mono)
# Initialize and train S-Learner
learner_s = BaseSRegressor(
learner=XGBRegressor(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
),
control_name='control'
)
learner_s.fit(X_train_mono, treatment_train_mono, y_train_mono)
# Initialize and train T-Learner
learner_t = BaseTRegressor(
learner=XGBRegressor(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
),
control_name='control'
)
learner_t.fit(X_train_mono, treatment_train_mono, y_train_mono)
# Predict treatment effects
df_results_mono[["mono_S_learner"]] = learner_s.predict(X=X_test_mono)
df_results_mono[["mono_T_learner"]] = learner_t.predict(X=X_test_mono)
df_results_mono["random_forest_learner"] = rfc.predict(X_test_mono)
display(df_results_mono[["mono_S_learner", "mono_T_learner", "random_forest_learner"]].mean())
df_mono_results_plot = df_results_mono[["mono_S_learner","mono_T_learner", "random_forest_learner","retention","treatment_col"]].copy()
Note that we’re still using causalml here, and that the API is extremely simple to use, very close to a sklearn-like implementation.
Model evaluation
How to evaluate and compare our models’ performances? That is a great question! As we’re predicting something we do not know — we don’t know the effect of our treatment on our customers as each customer either received the treatment or was in the control group. We cannot use classic evaluation metrics. Hopefully, there are other ways:
The Gain curve: The gain curve offers an easy way to visualise our model’s performance. The idea behind gain is simple:
- We compute the estimated effect of each of our customers, order them from the biggest effect to the lesser.
- From here, we move point by point. At each point, we calculate the average treatment effect meaning, both the average effect — for control and treatment — and we take the difference.
- We do that for both our models ordering and a random ordering, simulating random selection, and compare both curves!
It helps us understand which improvement our model would have brought versus a random selection.
The AAUC score: the AAUC score is very close to the actual gain curve as it measures the Area under the curve of the gain curve of our model, enabling us to compare it with the one of the random model. It summarizes the gain curve in an easy to compare number.
In the following code, we calculate these metrics
from causalml.metrics import plot_gain
from causalml.metrics import auuc_score
#AAUC score
aauc_normalized = auuc_score(df_mono_results_plot, outcome_col='retention', treatment_col='treatment_col', normalize=True, tmle=False)
print(f"AAUC Score Normalized: {aauc_normalized}")
# Plot Gain Curve
plot_gain(df_mono_results_plot, outcome_col='retention', treatment_col='treatment_col')
plt.title('Gain Curve - T-Learner')
plt.show()
Here are the results we got. Higher scores are better of course.
- T-Learner: ~6.4 (best performer)
- S-Learner: ~6.3 (very close second)
- Random Forest: ~5.7 (good, but not as good as the others)
- Random targeting: ~0.5 (baseline)
What do these results mean?
- Well, all our models are performing way better than random targeting. This is reassuring. They’re about 12 times more effective! We’ll understand what it means in terms of impact just after.
- We also understand from these AAUC score that, while all models are performing quite well, the T-Leaner is the best performer
Now let’s take a look at the gain curve.
Gain Curve
How to read a gain curve:
- X-Axis (Population): This represents the size of the population you’re targeting, starting from the most responsive individuals (on the left) to the least responsive (on the right).
- Y-Axis (Gain): This shows the cumulative gain, which is the improvement in your outcome (e.g., increased retention).
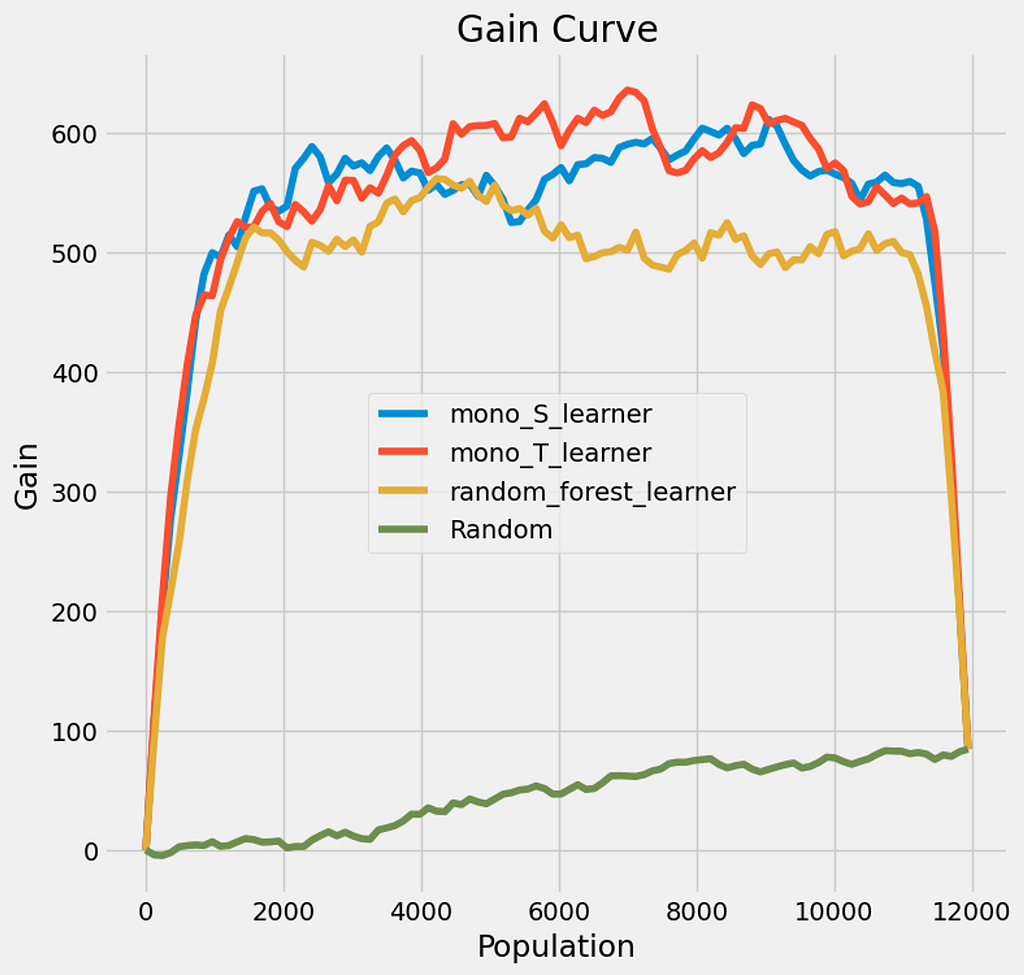
Gain curve Interpretation
The gain curve shows us the benefit — in our initial unit hence “people retained” — of targeting the population using our uplif model or randomly targeting.
- In that case it seems that if we reach out to the whole population with our emails, we would retain approximately 100 additional users. This is our baseline scenario. Note that every curve ends by this result which is expected considering our gain definition.
- So how to interpret this? Well, looking at the curve we can say that using our model, by reaching out to only 50% of the population, we can save 600 additional users! Six times more than by reaching out to everyone. How is that possible? By targeting only users that are likely to react positively to our outreach, while ignoring those who would leverage this email to actually churn for instance.
It is time for a small disclaimer: we’re using synthetic data here, our results are extremely unlikely in the real world, but it is good to illustrate.
In this case, our models enable us to do more with less. This is a good example on how we can optimize our resources using uplift modeling and targeting a lower share of the population, hence limiting the operation costs, to obtain a good share of the results. A kind of Pareto effect if you’d like.
But let’s head over to the really cool stuff : how can we personalize our approach to every customer.
Multi treatment model: let’s move to Personalization
Let’s now restart our analysis, considering all our retention strategies described above:
- Email campaign
- Call campaign
- In-app notification
- Vouchers
In order to achieve this, we need experimentation results of either a multi-treatment experimentation of all those actions, or to aggregate the results of multiple experimentation. the better the experimental data, the better predictive output we’ll get. However, setting up such experiments can take time and resources.
Let’s use our previously generated data, keeping in mind that obtaining this data in the first place is probably the biggest challenge of this approach!
Model Training
Let’s start by training our models. We’ll keep the same model type as before, a Random Forest, S-Learner, and T-Learner.
However, these models will now learn to differentiate between the effects of our four distinct treatments.
#save results in a df
df_results_multi = df_test.copy()
# Define treatment actions
actions = ['call_campaign', 'email_campaign', 'in_app_notification', 'voucher']
# Initialize and train Uplift Random Forest Classifier
rfc = UpliftRandomForestClassifier(
n_estimators=100,
max_depth=5,
min_samples_leaf=50,
min_samples_treatment=10,
n_reg=10,
control_name='control',
random_state=42
)
rfc.fit(X_train , treatment_train, y_train)
# Initialize and train S-Learner
learner_s = BaseSRegressor(
learner=XGBRegressor(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
),
control_name='control'
)
learner_s.fit(X_train , treatment_train, y_train)
# Initialize and train T-Learner
learner_t = BaseTRegressor(
learner=XGBRegressor(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
),
control_name='control'
)
learner_t.fit(X_train , treatment_train, y_train)
Predictions
Now that our models are trained, let’s generate our predictions for each treatment. For each user, we’ll get the uplift of each treatment. This will enable us to choose the most effective treatment by user, if any treatment has a positive uplift. Otherwise, we just won’t reach out to this person!
def predict_multi(df, learner, learner_name, X_test):
"""
Predict treatment effects for multiple treatments and determine the best treatment.
"""
# Predict treatment effects
cols = [f'{learner_name}_learner_{action}' for action in actions]
df[cols] = learner.predict(X=X_test)
# Determine the best treatment effect
df[f'{learner_name}_learner_effect'] = df[cols].max(axis=1)
# Determine the best treatment
df[f"{learner_name}_best_treatment"] = df[cols].idxmax(axis=1)
df.loc[df[f'{learner_name}_learner_effect'] < 0, f"{learner_name}_best_treatment"] = "control"
return df
# Apply predictions for each model
df_results_multi = predict_multi(df_results_multi, rfc, 'rf', X_test)
df_results_multi = predict_multi(df_results_multi, learner_s, 's', X_test)
df_results_multi = predict_multi(df_results_multi, learner_t, 't', X_test)
Here is the kind of data we’ll obtain from this, for each model:
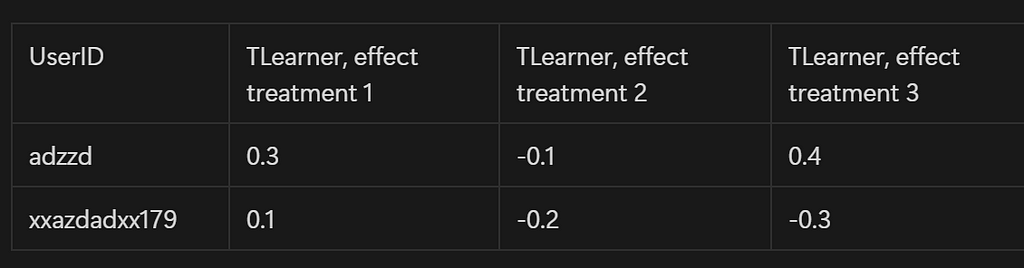
We’ll be able, for each model, to pick the best treatment for each user!
Model evaluation
Now let’s look at our approach evaluation. As we have multiple treatments, it is slightly different:
- For each user we select the best treatment.
- Then we order our user based on their best treatment effect
- And look at what really happened : either the user really stayed or left.
Following this rationale, we easily understand how we can outperform random targeting by only targeting a small share of our whole population.
From here, we’re able to plot our gain curve and compute our AAUC. Easy right? The code below does exactly that, still leveraging causalML.
#AAUC score
aauc_normalized = auuc_score(df_t_learner_plot_multi, outcome_col='retention', treatment_col='treatment_col', normalize=True, tmle=False)
aauc_non_normalize = auuc_score(df_t_learner_plot_multi, outcome_col='retention', treatment_col='treatment_col', normalize=False, tmle=False)
print(f"AAUC Score Normalized: {aauc_normalized}")
print(f"AAUC Score: {aauc_non_normalize}")
# Plot Gain Curve
plot_gain(df_t_learner_plot_multi, outcome_col='retention', treatment_col='treatment_col')
plt.title('Gain Curve - T-Learner')
plt.show()
Results interpretation
- T-Learner: ~1.45 (best performer)
- S-Learner: ~1.42 (very close second)
- Random Forest: ~1.20 (good, but not as good as the others)
- Random targeting: ~0.52 (baseline)
What this means:
- Once again, all our models outperform random targeting, and once again the T-Learner is the best performer
- However we note that the difference is lower than in our first case. Different reasons could explain that, one being the actual set-up. We’re considering a bigger population here, which we did not consider in our first experiment. It also could mean that our models do not perform as well when it comes to multi-treatment and we would need to iterate and try to improve their performance.
But let’s look at our gain curve to understand better our performance.
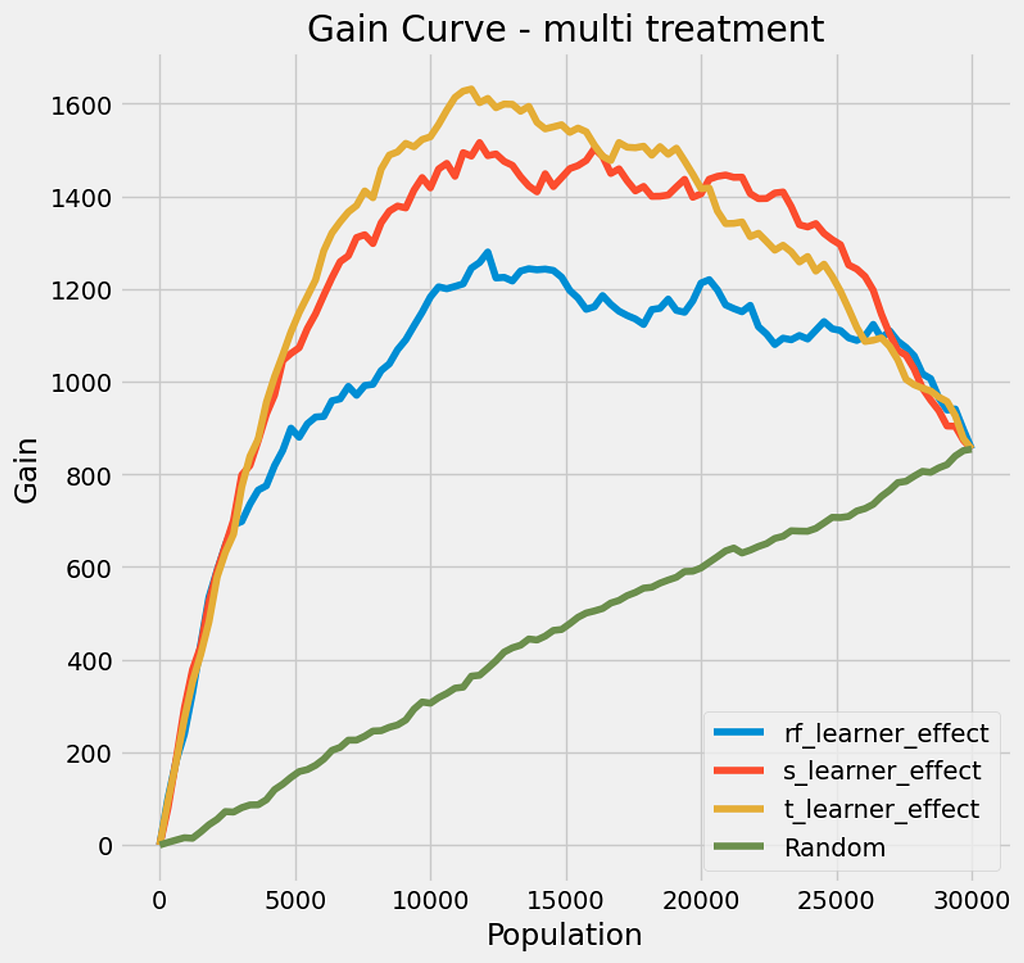
Interpretation of the Multi-Treatment Gain Curve
- As we can see, if we were to target 100% of our population — 30,000 users — we would retain an additional 850 users (approximately)
- however, using our models, we are able to retain 1,600 users while only contacting 33% of the total population
- Finally, we notice that past 40% of the population all curves start to decrease indicating that there is no value contacting those customers.
We made it. We successfully built a model that enables us to personalize effectively our retention actions to maximize our ROI. Based on this model, our company decided to put this model to production and saved millions not wasting resources reaching out to everyone, but also focusing the right type of effort on the right customer!
Putting such a model to production is another challenge in itself because we need to ensure its performance in the long term, and keep retraining it when possible. The framework to do that would be to:
- Generate inference with your model on 80% of your target population
- Keep 10% of your target population intact : Control
- Keep an additional 10% of your population to keep experimenting to train your model for the next time period (month/quarter/year depending on your capabilities)
We might look into this later on!
Conclusion
If you made it this far, thank you! I hope this was interesting and that you learned how to create an uplift model and how to evaluate its performance.
If I did a good job, you may now know that uplift models are an incredible tool to understand and that it can lead to great, direct and measurable impact. You also may have understood that uplift models enable us to target the right population with the right treatment, but require a strong and exploitable experimental data to be trained on. Getting this data up to date is often the big challenge of such projects. It is applicable on historical/observational data, one would need to add specific cleaning and treating steps to ensure that the data is unbiased.
So what’s next? While we’re deep-diving in the world of causal machine learning, I want to make sure you are heard. So if you want to look into specific topics that you think you could apply in your own company and would like to learn more about it, let me know, I’ll do my best. Let’s keep all learning from each other! Until next time, happy modeling!
Source
Unless otherwise noted, all images are by the author
[1] https://en.wikipedia.org/wiki/Uplift_modelling
[2] https://causalml.readthedocs.io/en/latest/index.html
[3] https://matheusfacure.github.io/python-causality-handbook/landing-page.html
Causal Machine Learning for Customer Retention: a Practical Guide with Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Causal Machine Learning for Customer Retention: a Practical Guide with Python