Exploring continual learning strategies for CLIP

There is currently a growing interest in the study and application of Large Language Models. However, these models can only process textual data, which limits their usefulness for some applications. Humans are capable of processing information across multiple modalities, such as written and spoken language, and visual understanding of the reality around us. We would expect models to be capable of similar processing.
Vision-Language models can address both textual and visual data, which has a wide range of use cases such as image analysis (e.g. medical images), object recognition and better scene understanding (e.g. for self-driving cars), generating captions for the images, responding to the visual questions, chatting about images, and more…
Unfortunately, multi-modal models face the same challenges as unimodal ones. Once trained, they can become outdated over time as new data samples arrive or the data distribution changes.
In my last article I introduced the Continual Learning (CL) approach to AI models in general. Continual Learning tries to find ways to continually train models, which may be a more sustainable solution for the future. In this article, I want to explore the possibilities of applying CL to Vision-Language models (VLMs) — specifically the Contrastive Language-Image Pretraining (CLIP) model.
But what is CLIP?
Contrastive Language-Image Pretraining (CLIP) was introduced by the OpenAI in 2021 in the Learning Transferable Visual Models From Natural Language Supervision paper [1].
The goal of the CLIP model is to understand the relation between text and an image. If you input it a piece of text it should return the most relevant image in a given set of images for it. Likewise if you put in the model an image it should give you the most fitting text from a set of available texts.
CLIP was trained on a large dataset of text-image pairs. Contrastive learning was used to bring matching text-image pairs closer together in the embedding space and to move non-matching pairs away from each other. This learned shared embedding space is then used during inference to understand the relationship between text and images. If you want to know more about CLIP, I recommend the following article, which describes it in detail.
Why do we need Continual Learning for Vision-Language models?
Large foundation models can become obsolete over time due to shifts in distribution or the arrival of new data samples. Re-training such models is expensive and time consuming. The authors of the TiC-CLIP paper [7] show that current evaluation practices often fail to capture the difference in performance when considering time-evolving data.
In Figure 1 you can see that if we compare OpenAI models trained before 2020 and OpenCLIP models trained before 2022, although there is not much difference between their robustness on Imagenet (left image), there is a performance gap when compared on retrieval tasks from 2014–2016 and 2021–2022 (right image), indicating that OpenAI models have less zero-shot robustness with time-evolving data [7].
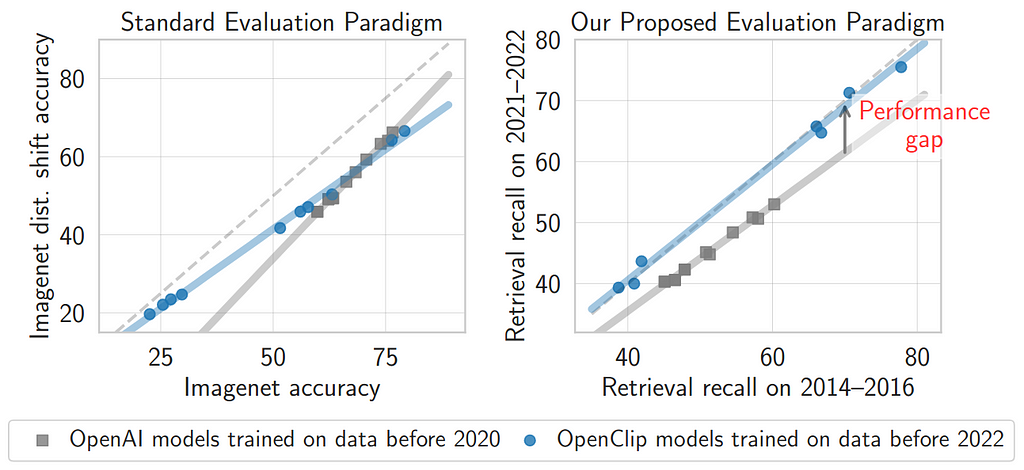
In addition, Continual Learning may be a natural choice for some use cases such as Online Lifelong Learning (OLL) [8] where data comes from continuous and non-stationary data streams and evolves with time.
Finally, as pointed out in [4], CLIP shows remarkable zero-shot capabilities, but for some domains it may struggle to achieve good performance due to insufficient data for some categories during pre-training.
Challenges
As some of the current state-of-the-art Vision-Language models require more and more computational time and resources, finding a way to continually adapt them without re-training seems to be crucial. However, there are some challenges in continually adapting such models:
- catastrophic forgetting — learning new tasks can damage the performance on the old tasks.
- losing zero-shot capability — pre-trained models can display zero-shot behaviour meaning that they can perform a task for which they have not received training data, i.e. classify a class of images without seeing them during training. This ability can be lost when training continually.
- misalignment between text and image representations — as noted by the authors of [12], during Continual Learning for CLIP, there may be a deterioration in the alignment of the multimodal representation space, which can lead to performance degradation in the long run.
Continual Learning Methods for CLIP
There is an ongoing research on improving the continual aspect of multi-modal models. Below are some of the existing strategies and use cases:
- Mixture of Experts (MoE)
- To continually train the CLIP, the authors of [2] propose MoE approach using task-specific adapters. They build a dynamic extension architecture on top of a frozen CLIP model.
- The idea here is to add new adapters as new tasks are trained. At the same time, the Distribution Discriminative Auto-Selector is trained so that later, during the inference phase, the model can automatically choose whether the test data should go to the MoE adapters or to the pre-trained CLIP for zero-shot detection.
2. CoLeCLIP
- The authors of [4] focus on the problem of Continual Learning for Vision-Language models in open domains — where we may have datasets from diverse seen and unseen domains with novel classes.
- Addressing open domain challenges is particularly important for use cases such as AI assistants, autonomous driving systems and robotics, as these models operate in complex and changing environments [4].
- CoLeCLIP is based on CLIP but adjusted for open-domain problems.
- In CoLeCLIP an external laernable Parameter-Efficient Fine-Tuning (PEFT) module per task is attached to the frozen text encoder of CLIP to learn the text embeddings of the classes [4].
3. Continual Language Learning (CLL)
- The authors of [3] noted that current pre-trained Vision-Language models often only support English. At the same time popular methods for creating multilingual models are expensive and require large amounts of data.
- In their paper, they propose to extend language capability by using CLL, where linguistic knowledge is updated incrementally.
- CLL-CLIP uses an expandable embedding layer to store linguistic differences. It trains only token embeddings and is optimised for learning alignment between images and multilingual text [3].
- The authors also propose a novel approach to ensure that the distribution of all token embeddings is identical during initialisation and later regularised during training. You can see a visualisation of this process in Figure 2 from their paper.
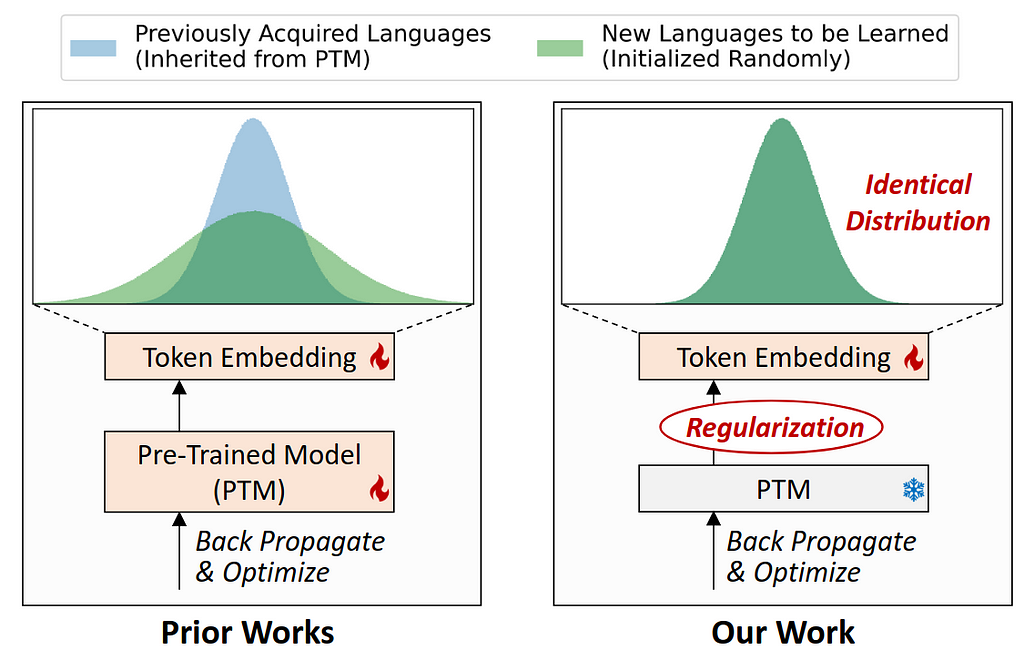
4. Symmetric Image-Text tuning strategy (SIT)
- In [8] the authors observe that there occurs asymetry between text and image during Parameter-Efficient Tuning (PET) for their Online Lifelong Learning scenario which may lead to catastrophic forgetting.
- They propose to use the SIT strategy to mitigate this problem. This approach matches images and class labels within the current batch only during online learning.
- The goal is to preserve the generalisation ability of CLIP while improving its performance on a specific downstream task or dataset, without introducing asymmetry between the encoders.
Evaluation of the Continual Learning models
The evaluation standards for CL appear to be still a work in progress. Many of the existing benchmarks for evaluating the effectiveness of CL models do not take the time factor into account when constructing data sets. As mentioned by [7], the performance gap may sometimes only become visible when we recreate the time-evolving setup for the test data.
In addition, many of the existing benchmarks for Vision-Language models focus only on the single-image input, without measuring multi-image understanding, which may be critical in some applications. The authors of [5] develop a benchmark for multi-image evaluation that allows a more fine-grained assessment of the limitations and capabilities of current state-of-the-art models.
Continual Learning does not solve all the problems…
Visual-Language models like CLIP have their shortcomings. In [6], the authors explored the gap between CLIP’s visual embedding space and purely visual self-supervised learning. They investigated false matches in the embedding space, where images have similar encoding when they should not.
From their results it can be concluded that if a pre-trained model has a weakness, it can be propagated when the model is adapted. Learning visual representations remains an open challenge, and vision models may become a bottleneck in multimodal systems, as scaling alone does not solve the built-in limitations of models such as CLIP. [6]
Conclusion
This article explores the opportunities and challenges of applying Continual Learning to Vision-Language models, focusing on the CLIP model. Hopefully this article has given you a first impression of what is possible, and that while Continual Learning seems to be a good direction for the future of AI models, there is still a lot of work to be done to make it fully usable.
If you have any questions or comments, please feel free to share them in the comments section.
Until next time!

References
[1] Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning (pp. 8748–8763). PMLR.
[2] Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, & You He. (2024). Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters.
[3] Bang Yang, Yong Dai, Xuxin Cheng, Yaowei Li, Asif Raza, & Yuexian Zou. (2024). Embracing Language Inclusivity and Diversity in CLIP through Continual Language Learning.
[4] Yukun Li, Guansong Pang, Wei Suo, Chenchen Jing, Yuling Xi, Lingqiao Liu, Hao Chen, Guoqiang Liang, & Peng Wang. (2024). CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning.
[5] Bingchen Zhao, Yongshuo Zong, Letian Zhang, & Timothy Hospedales. (2024). Benchmarking Multi-Image Understanding in Vision and Language Models: Perception, Knowledge, Reasoning, and Multi-Hop Reasoning.
[6] Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, & Saining Xie. (2024). Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs.
[7] Saurabh Garg, Hadi Pour Ansari, Mehrdad Farajtabar, Sachin Mehta, Raviteja Vemulapalli, Oncel Tuzel, Vaishaal Shankar, & Fartash Faghri (2023). TiC-CLIP: Continual Training of CLIP Models. In NeurIPS Workshop.
[8] Leyuan Wang, Liuyu Xiang, Yujie Wei, Yunlong Wang, & Zhaofeng He. (2024). CLIP model is an Efficient Online Lifelong Learner.
[9] Vishal Thengane, Salman Khan, Munawar Hayat, & Fahad Khan. (2023). CLIP model is an Efficient Continual Learner.
[10] Yuxuan Ding, Lingqiao Liu, Chunna Tian, Jingyuan Yang, & Haoxuan Ding. (2022). Don’t Stop Learning: Towards Continual Learning for the CLIP Model.
[11] Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, & Aman Chadha. (2024). Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions.
[12] Ni, Z., Wei, L., Tang, S., Zhuang, Y., & Tian, Q. (2023). Continual vision-language representation learning with off-diagonal information. In Proceedings of the 40th International Conference on Machine Learning. JMLR.org.
How Can We Continually Adapt Vision-Language Models? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How Can We Continually Adapt Vision-Language Models?
Go Here to Read this Fast! How Can We Continually Adapt Vision-Language Models?