A walkthrough on how to create a RAG chatbot using Langflow’s intuitive interface, integrating LLMs with vector databases for context-driven responses.

A Retrieval-Augmented Generation, or RAG, is a natural language process that involves combining traditional retrieval techniques with LLMs to generate a more accurate and relevant text by integrating the generation properties with the context provided by the retrievals. It has been used widely recently in the context of chatbots, providing the ability for companies to improve their automated communications with clients by using cutting-edge LLM models customized with their data.
Langflow is the graphical user interface of Langchain, a centralized development environment for LLMs. Back in October 2022, Langchain was released and by June 2023 it had become one of the most used open-source projects on GitHub. It took the AI community by storm, specifically for the framework developed to create and customize multiple LLMs with functionalities like integrations with the most relevant text generation and embedding models, the possibility of chaining LLM calls, the ability to manage prompts, the option of equipping vector databases to speed up calculations, and delivering smoothly the outcomes to external APIs and task flows.
In this article, an end-to-end RAG Chatbot created with Langflow is going to be presented using the famous Titanic dataset. First, the sign-up needs to be made in the Langflow platform, here. To begin a new project some useful pre-built flows can be quickly customizable based on the user needs. To create a RAG Chatbot the best option is to select the Vector Store RAG template. Image 1 exhibits the original flow:
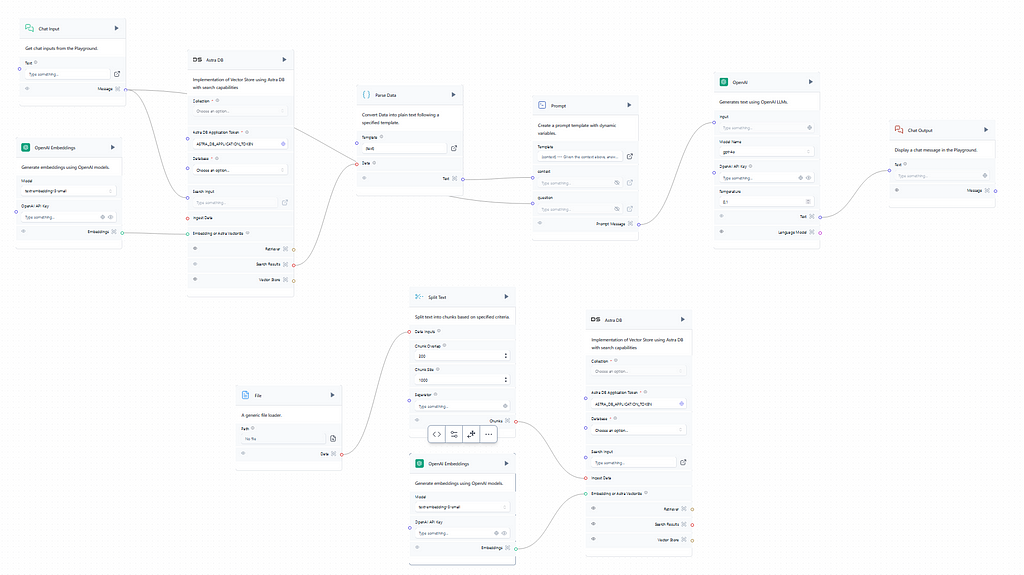
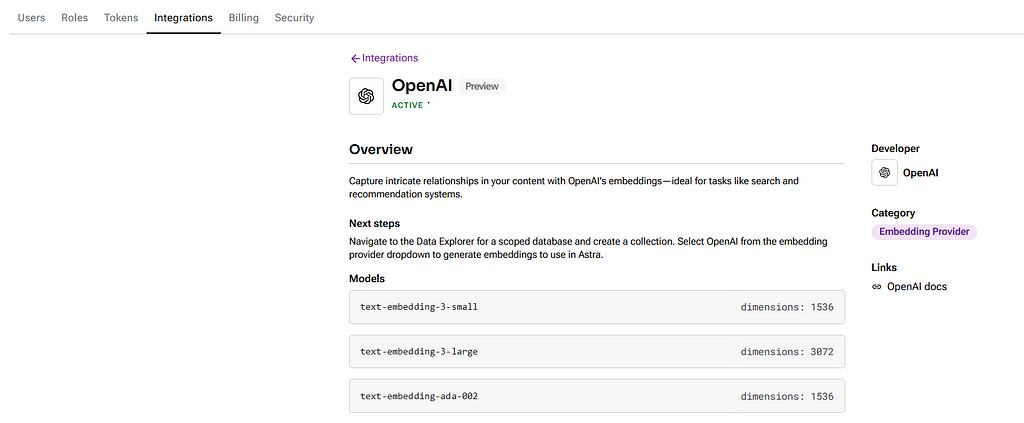
The template has OpenAI preselected for the embeddings and text generations, and those are the ones used in this article, but other options like Ollama, NVIDIA, and Amazon Bedrock are available and easily integrable by just setting up the API key. Before using the integration with an LLM provider is important to check if the chosen integration is active on the configurations, just like in Image 2 below. Also, global variables like API keys and model names can be defined to facilitate the input on the flow objects.
There are two different flows on the Vector Store Rag template, the one below displays the retrieval part of the RAG where the context is provided by uploading a document, splitting, embedding, and then saving it into a Vector Database on Astra DB that can be created easily on the flow interface. Currently, by default, the Astra DB object retrieves the Astra DB application token so it is not even necessary to gather it. Finally, the collection that will store the embedded values in the vector DB needs to be created. The collection dimension needs to match the one from the embedding model, which is available in the documentation, for proper storing of the embedding results. So if the chosen embedding model is OpenAI’s text-embedding-3-small therefore the created collection dimension has to be 1536. Image 3 below presents the complete retrieval flow.
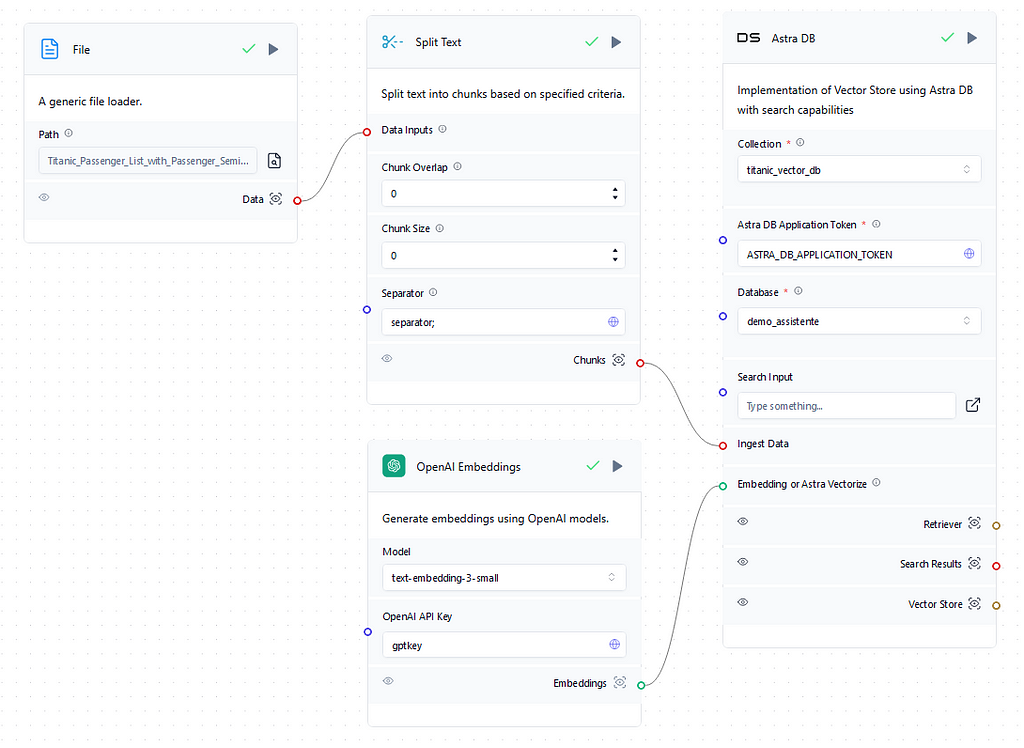
The dataset used to enhance the chatbot context was the Titanic dataset (CC0 License). By the end of the RAG process, the chatbot should be able to provide specific details and answer complex questions about the passengers. But first, we update the file on a generic file loader object and then split it using the global variable “separator;” since the original format was CSV. Also, the chunk overlap and chunk size were set to 0 since each chunk will be a passenger by using the separator. If the input file is in straight text format it is necessary to apply the chunk overlap and size setups to properly create the embeddings. To finish the flow the vectors are stored in the titanic_vector_db on the demo_assistente database.
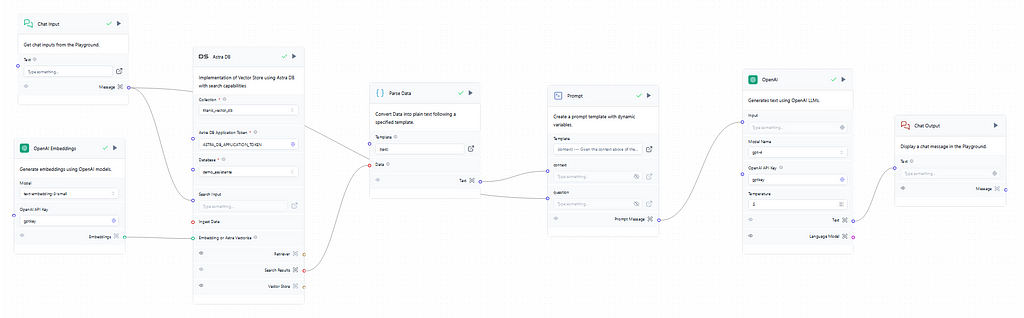
Moving to the generation flow of the RAG, displayed in Image 4, it is triggered with the user input on the chat which is then searched into the database to provide context for the prompt later on. So if the user asks something related to the name “Owen” on the input the search will run through the vector DB’s collection looking for “Owen” related vectors, retrieve and run them through the parser to convert them to text, and finally, the context necessary for the prompt later on is obtained. Image 5 shows the results of the search.

Back to the beginning, it is also critical to connect again the embedding model to the vector DB using the same model in the retrieval flow to run a valid search, otherwise, it would always come empty since the embedding models used in the retrieval and generation flows then would be different. Furthermore, this step evidences the massive performance benefits of using vector DBs in a RAG, where the context needs to be retrieved and passed to the prompt quickly before forging any type of response to the user.
In the prompt, shown in Image 6, the context comes from the parser already converted to text and the question comes from the original user input. The image below shows how the prompt can be structured to integrate the context with the question.

With the prompt written it is time for the text generation model. In this flow, the GPT4 model was chosen with a temperature of 0.5, a recommended standard for chatbots. The temperature controls the randomness of predictions made by a LLM. A lower temperature will generate more deterministic and straightforward answers, leading to a more predictable text. A higher one will generate more creative outputs even though if it is too high the model can easily hallucinate and produce incoherent text. Finally, just set the API key using the global variable with OpenAI’s API key and it’s as easy as that. Then, it’s time to run the flows and check the results on the playground.
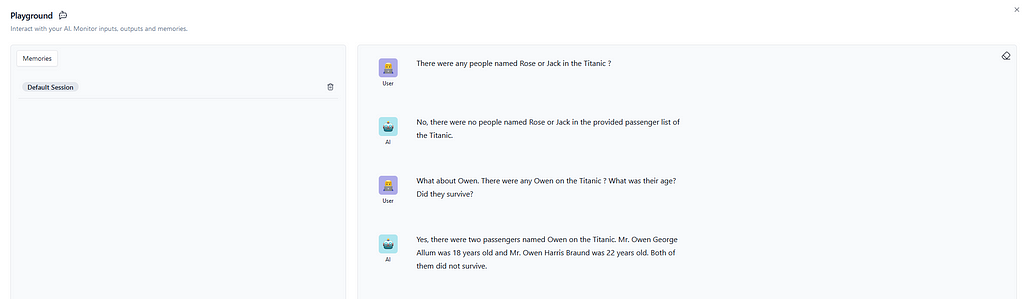
The conversation in Image 7 clearly shows that the chatbot has correctly obtained the context and rightfully answered detailed questions about the passengers. And even though it might be disappointing to find out that there were not any Rose or Jack on the Titanic, unfortunately, that is true. And that’s it. The RAG chatbot is created, and of course, it can be enhanced to increase conversational performance and cover some possible misinterpretations, but this article demonstrates how easy Langflow makes it to adapt and customize LLMs.
Finally, to deploy the flow there are multiple possibilities. HuggingFace Spaces is an easy way to deploy the RAG chatbot with scalable hardware infrastructure and native Langflow that wouldn’t require any installations. Langflow can also be installed and used through a Kubernetes cluster, a Docker container, or directly in GCP by using a VM and Google Cloud Shell. For more information about deployment look at the documentation.
New times are coming and low-code solutions are starting to set the tone of how AI is going to be developed in the real world in the short future. This article presented how Langflow revolutionizes AI by centralizing multiple integrations with an intuitive UI and templates. Nowadays anyone with basic knowledge of AI can build a complex application that at the beginning of the decade would take a huge amount of code and deep learning frameworks expertise.
Creating a RAG Chatbot with Langflow and Astra DB was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Creating a RAG Chatbot with Langflow and Astra DB
Go Here to Read this Fast! Creating a RAG Chatbot with Langflow and Astra DB