

LLM-Powered Parsing and Analysis of Semi-Structured & Unstructured Documents
How to extract required information from your documents
Document parsing is the process of analyzing a document’s content (unstructured or semi-structured) to extract specific information or to transform the content into a more structured format. The goal of document parsing is to break down the document into its constituent parts and interpret these parts. Document parsing is very useful for organizations that deal with large volumes of data in various formats which requires automated data extraction. There could be several use cases where document parsing is useful in business, e.g., invoice processing, analysis of legal contracts, customer feedback analysis from multiple sources, and financial statement analysis, to name a few.
Before the advent of Large Language Models (LLMs), document parsing was done using predefined rules such as Regular Expressions (Regex). However, these rules lack flexibility and are limited to pre-defined structures. Real-world documents often have inconsistencies and do not follow a fixed structure or format. This is where LLMs could be of immense potential to extract specific information from semi-structured or unstructured documents for further analysis.
In this article, I will explain, with a practical example, how to automatically extract required information from semi-structured and unstructured documents using an LLM and subsequently analyze this information. The documents used in this experiment comprise the AI advisory feedback to companies in our FAIR (Finnish AI Region) project. These documents contain data about a company’s AI maturity, current solution, need for AI integration, future plans regarding AI integration, technical expertise, services sought from AI advisory, and detailed recommendations from the AI experts. Extraction of key information from these documents and their subsequent analysis can provide useful insights about recent trends in AI adoption across various industries, the specific needs and challenges companies are facing in implementing AI solutions, and the types of AI technologies that are currently in demand.
The following figure shows the entire workflow of document parsing with LLM and subsequent analysis.
The code to implement this entire workflow is available on GitHub.
Let’s go through these steps one by one.
1. Text Extraction
The documents used in this example include the AI advisory feedback that we provide to companies after an advisory session. These companies include startups and established companies who want to integrate AI into their business or want to advance their existing AI solutions. The feedback document is a semi-structured document whose format is shown below. The names and other information in this document have been changed due to privacy constraints.

The AI experts provide their analysis for each field. However, with hundreds of such documents, extracting insights from the data becomes a challenging task. To gain insights into this data, it needs to be converted into a concise, structured format that can be analyzed using existing statistical or machine learning methods. Performing this conversion manually is not only labor-intensive and time-consuming but also prone to errors.
In addition to the readily visible information in the document, such as the company name, consultation date, and expert(s) involved, I aimed to extract specific details for further analysis. These included the major industry or domain each company operates in, a concise description of the current solutions offered, the AI topic(s), company type, AI maturity level, aim, and a brief summary of the recommendations. This extraction needed to be performed on the detailed text associated with each field. Additionally, the feedback template has evolved over time, which has resulted in documents with inconsistent formats.
Before we discuss the text extraction from the documents, please note that following libraries need to be installed for running the complete code used in this article.
# Install the required libraries
!pip install tqdm # For displaying a progress bar for document processing
!pip install requests # For making HTTP requests
!pip install pandas # For data manipulation and analysis
!pip install python-docx # For processing Word documents
!pip install plotly # For creating interactive visualizations
!pip install numpy # For numerical computations
!pip install scikit-learn # For machine learning algorithms and tools
!pip install matplotlib # For creating static, animated, and interactive plots
!pip install openai # For interacting with the OpenAI API
!pip install seaborn # For statistical data visualization
The following code extracts text from a document (.docx format) using python-docx library. It is important to extract text from all the formats, including paragraphs, tables, headers, and footers.
def extract_text_from_docx(docx_path: str):
"""
Extract text content from a Word (.docx) file.
"""
doc = docx.Document(docx_path)
full_text = []
# Extract text from paragraphs
for para in doc.paragraphs:
full_text.append(para.text)
# Extract text from tables
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
full_text.append(cell.text)
# Extract text from headers and footers
for section in doc.sections:
header = section.header
footer = section.footer
for para in header.paragraphs:
full_text.append(para.text)
for para in footer.paragraphs:
full_text.append(para.text)
return 'n'.join(full_text).strip()
2. Set LLM Prompts
We need to instruct the LLM on how to extract the required information from the documents. Also, we need to explain the meaning of each field of interest to be extracted so that it can extract the semantically matching information from the documents. This is particularly important because a required field comprising one or more words can be interpreted in several ways. For instance, we need to explain what we mean by “aim”, which basically refers to the company’s plans for AI integration or how it wants to advance its current solution. Therefore, crafting the right prompt for this purpose is very important.
I set the instructions in system prompt to guide the LLM’s behavior. The input prompt comprises the data to be processed by the LLM. The system prompt is shown below.
# System prompt with extraction instructions
system_message = """
You are an expert in analyzing and extracting information from the feedback forms written by AI experts after AI advisory sessions with companies.
Please carefully read the provided feedback form and extract the following 15 key information. Make sure that the key names are exactly the same as
given below. Do not create any additional key names other than these 15.
Key names and their descriptions:
1. Company name: name of the company seeking AI advisory
2. Country: Company's country [output 'N/A' if not available]
3. Consultation Date [output 'N/A' if not available]
4. Experts: persons providing AI consultancy [output 'N/A' if not available]
5. Consultation type: Regular or pop-up [output 'N/A' if not available]
6. Area/domain: Field of the company’s operations. Some examples: healthcare, industrial manufacturing, business development, education, etc.
7. Current Solution: description of the current solution offered by the company. The company could be currently in ideation phase. Some examples of ‘Current Solution’ field include i) Recommendation system for cars, houses, and other items, ii) Professional guidance system, iii) AI-based matchmaking service for educational peer-to-peer support. [Be very specific and concise]
8. AI field: AI's sub-field in use or required. Some examples: image processing, large language models, computer vision, natural language processing, predictive modeling, speech recognition, etc. [This field is not explicitly available in the document. Extract it by the semantic understanding of the overall document.]
9. AI maturity level: low, moderate, high [output 'N/A' if not available].
10. Company type: ‘startup’ or ‘established company’
11. Aim: The AI tasks the company is looking for. Some examples: i) Enhance AI-driven systems for diagnosing heart diseases, ii) to automate identification of key variable combinations in customer surveys, iii) to develop AI-based system for automatic quotation generation from engineering drawings, iv) to building and managing enterprise-grade LLM applications. [Be very specific and concise]
12. Identified target market: The targeted customers. Some examples: healthcare professionals, construction firms, hospitality, educational institutions, etc.
13. Data Requirement Assessment: The type of data required for the intended AI integration? Some examples: Transcripts of therapy sessions, patient data, textual data, image data, videos, etc.
14. FAIR Services Sought: The services expected from FAIR. For instance, technical advice, proof of concept.
15. Recommendations: A brief summary of the recommendations in the form of key words or phrase list. Some examples: i) Focus on data balance, monitor for bias, prioritize transparency, ii) Explore machine learning algorithms, implement decision trees, gradient boosting. [Be very specific and concise]
Guidelines:
- Very important: do not make up anything. If the information of a required field is not available, output ‘N/A’ for it.
- Output in JSON format. The JSON should contain the above 15 keys.
"""
It is important to emphasize what the LLM should focus on. For instance, the number of key elements to be extracted, using exactly the same field names as specified, and not inventing any information if not available. An explanation of each field and some examples of the required information (if possible) are also important. It is worth mentioning that an optimal prompt may not be crafted in the first attempt.
3. Process Documents
Processing the documents refers to sending the data to an LLM for parsing. I used OpenAI’s gpt-4o-mini model for document parsing which is an affordable and intelligent small model for fast, lightweight tasks. GPT-4o mini is cheaper and more capable than GPT-3.5 Turbo. However, the lightweight versions of open LLMs such as Llama, Mistral, or Phi-3 can also be tested for this purpose.
The following code walks through a directory and its sub-directories to find the AI advisory documents (.docx format), extract text from each document, and send the document to gpt-4o-mini via an API call.
def process_files(directory_path: str, api_key: str, system_message: str):
"""
Process all .docx files in the given directory and its subdirectories,
send their content to the LLM, and store the JSON responses.
"""
json_outputs = []
docx_files = []
# Walk through the directory and its subdirectories to find .docx files
for root, dirs, files in os.walk(directory_path):
for file in files:
if file.endswith(".docx"):
docx_files.append(os.path.join(root, file))
if not docx_files:
print("No .docx files found in the specified directory or sub-directories.")
return json_outputs
# Iterate through all .docx files in the directory with a progress bar
for file_path in tqdm(docx_files, desc="Processing files...", unit="file"):
filename = os.path.basename(file_path)
extracted_text = extract_text_from_docx(file_path)
# Prepare the user message with the extracted text
input_message = extracted_text
# Prepare the API request payload
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": system_message},
{"role": "user", "content": input_message}
],
"max_tokens": 2000,
"temperature": 0.2
}
# Send the request to the LLM API
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
# Extract the JSON response
json_response = response.json()
content = json_response['choices'][0]['message']['content'].strip("```jsonn").strip("```")
parsed_json = json.loads(content)
# Normalize the parsed JSON output
normalized_json = normalize_json_output(parsed_json)
# Append the normalized JSON output to the list
json_outputs.append(normalized_json)
return json_outputs
In the call’s payload, I set the maximum number of tokens (max_tokens) to 2000 to accommodate the input/output tokens. I set a relatively low temperature (0.2) so that the LLM does not have a high creativity which is not required for this task. A high temperature may lead to hallucinations where the LLM may invent new information.
The LLM’s response is received in a JSON object and is further parsed and normalized as discussed in the next section.
4. Parse LLM Output
As shown in the above code, the response from the API is received in a JSON object (parsed_json) which is further normalized using the following function.
def normalize_json_output(json_output):
"""
Normalize the keys and convert list values to comma-separated strings.
"""
normalized_output = {}
for key, value in json_output.items():
normalized_key = key.lower().replace(" ", "_")
if isinstance(value, list):
normalized_output[normalized_key] = ', '.join(value)
else:
normalized_output[normalized_key] = value
return normalized_output
This function standardizes the keys of the JSON object by converting them to lowercase and replacing spaces with underscores. Additionally, it converts any list values into comma-separated strings to make the data easier to work with and analyze.
The normalized JSON object (json_outputs), containing the extracted key information from all the documents, is finally saved to an Excel file.
def save_json_to_excel(json_outputs, output_file_path: str):
"""
Save the list of JSON objects to an Excel file with a SNO. column.
"""
# Convert the list of JSON objects to a DataFrame
df = pd.DataFrame(json_outputs)
# Add a Serial Number (SNO.) column
df.insert(0, 'SNO.', range(1, len(df) + 1))
# Ensure all columns are consistent and save the DataFrame to an Excel file
df.to_excel(output_file_path, index=False)
A snapshot of the Excel file is shown below. LLM-powered parsing produced precise information pertaining to the required fields. The “N/A” in the snapshot represents the data unavailable in the documents (old feedback templates missing this information).

Finally, the code to call all the above-mentioned functions is given below. Note that OpenAI’s API key is required to run this code.
# Directory containing files
directory_path = 'Documents'
# API key for GPT-4-mini
api_key = 'YOUR_OPENAI_API_KEY'
# Process files and get the JSON outputs
json_outputs = process_files(directory_path, api_key, system_message)
if json_outputs:
# Save the JSON outputs to an Excel file
output_file_path = 'processed-gpt-o-mini.xlsx'
save_json_to_excel(json_outputs, output_file_path)
print(f"Processed data has been saved to {output_file_path}")
else:
print("No .docx file found.")
I also parsed some unstructured versions of the same documents. Here is a snapshot of the unstructured version of the same AI feedback. The names and important details in this version have been changed due to privacy constraints.

The parsing delivered the same precise and accurate information. A snapshot of the parsing results is shown below.

5. Perform Data Analysis
Now that we have a structured document, we can perform several analysis of this data. Even the LLM can be further used to suggest several analyses and even perform analysis with the given data and/or help writing the analysis code. For example, I quickly did the following two analyses to find the AI maturity level distribution of the companies, and the company type distribution. The following code generates visual insights into these distributions.
import pandas as pd
import plotly.express as px
# Load the dataset
file_path = 'processed-gpt-o-mini.xlsx' # Update this to match your file path
data = pd.read_excel(file_path)
# Convert fields to lowercase
data['ai_maturity_level'] = data['ai_maturity_level'].str.lower()
data['company_type'] = data['company_type'].str.lower()
# Plot for AI Maturity Level
fig_ai_maturity = px.bar(data,
x='ai_maturity_level',
title="AI Maturity Level Distribution",
labels={'ai_maturity_level': 'AI Maturity Level', 'count': 'Number of Companies'})
# Update layout for AI Maturity Level plot
fig_ai_maturity.update_layout(
xaxis_title="AI Maturity Level",
yaxis_title="Number of Companies",
xaxis={'categoryorder':'total descending'}, # Order bars by descending number of companies
yaxis=dict(type='linear'),
showlegend=False
)
# Display the AI Maturity Level figure
fig_ai_maturity.show()
# Plot for Company Type
fig_company_type = px.bar(data,
x='company_type',
title="Company Type Distribution",
labels={'company_type': 'Company Type', 'count': 'Number of Companies'})
# Update layout for Company Type plot
fig_company_type.update_layout(
xaxis_title="Company Type",
yaxis_title="Number of Companies",
xaxis={'categoryorder':'total descending'}, # Order bars by descending number of companies
yaxis=dict(type='linear'),
showlegend=False
)
# Display the Company Type figure
fig_company_type.show()
Here are the graphs generated by this code.
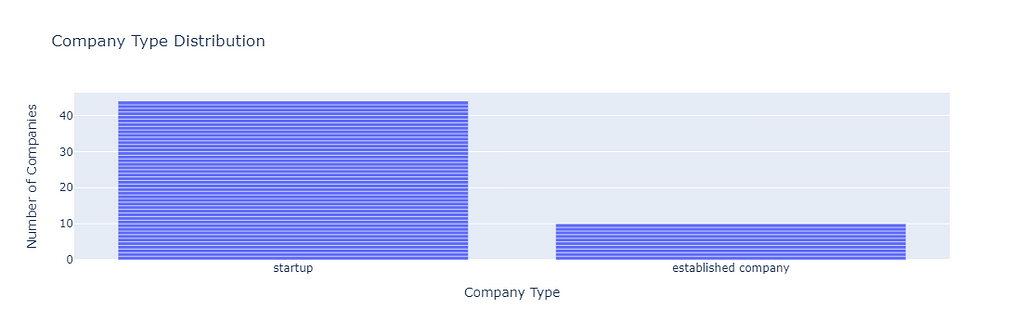
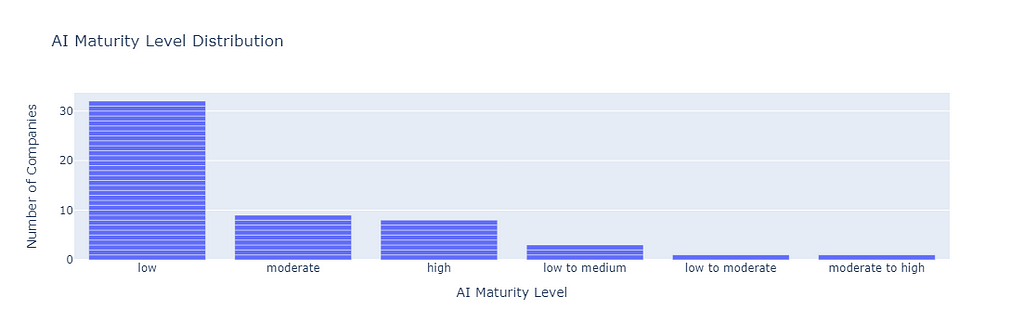
Further analyses can be done on the fields of area/domain, current solution, AI field, target market, and the experts’ recommendations to find the main themes or clusters of these fields. For the purpose of demonstration, I only performed clustering of area/domain field to find the main sectors these companies operate in.
For this purpose, I performed the following steps.
- Computed the embeddings of the text in the `area/domain` field using OpenAI’s text-embedding-3-small embedding model. Alternatively, an open embedding model such as all-MiniLM-L12-v2 can also be used.
- Applied the K-means clustering algorithm to the embeddings and experimented with different numbers of clusters to find the optimal one. This was done by computing the Silhouette score for each clustering result to evaluate the quality of the clustering. The cluster number with the highest Silhouette score was selected as the optimal number.
- Clustered the data using the optimal number of clusters.
- Sent the clusters to the gpt-4o-mini model for assigning a label to each cluster based on the semantic similarity of all data points within the cluster.
- Used the labeled clusters to represent the major sectors the companies seeking AI advisory belong to.
To know more about embeddings, please refer to the following article of mine.
The Power of Embeddings for Semantic Search
The following code computes embeddings with OpenAI’s text-embedding-3-smalle mbedding model.
def fetch_embeddings(texts, filename):
# Check if the embeddings file already exists
if os.path.exists(filename):
print(f"Loading embeddings from {filename}...")
with open(filename, 'rb') as f:
embeddings = pickle.load(f)
else:
print("Computing embeddings...")
embeddings = []
for text in texts:
embedding = client.embeddings.create(input=[text], model="text-embedding-3-small").data[0].embedding
embeddings.append(embedding)
embeddings = np.array(embeddings)
# Save the embeddings to a file for future use
print(f"Saving embeddings to {filename}...")
with open(filename, 'wb') as f:
pickle.dump(embeddings, f)
return embeddings
After computing the embeddings, the following code snippet finds the optimal number of clusters using k-means clustering with the computed embeddings. Before computing embeddings, unique names in area/domain field are computed; however, it is also important to keep track of the original indices for later analysis. The unique names in area/domain field are contained in deduplicated_domains list.
# Load the dataset
file_path = 'C:/Users/h02317/Downloads/processed-gpt-o-mini.xlsx'
data = pd.read_excel(file_path)
# Extract the "area/domain" field and process the data
area_domain_data = data['area/domain'].dropna().tolist()
# Deduplicate the data while keeping track of the original indices
deduplicated_domains = []
original_to_dedup = []
for item in area_domain_data:
item_lower = item.strip().lower()
if item_lower not in deduplicated_domains:
deduplicated_domains.append(item_lower)
original_to_dedup.append(deduplicated_domains.index(item_lower))
# Fetch embeddings for all deduplicated domain data points
embeddings = fetch_embeddings(deduplicated_domains, filename="all_domains_embeddings_2.pkl")
# Determine the optimal number of clusters using the silhouette score
silhouette_scores = []
K_range = list(range(2, len(deduplicated_domains))) # Testing between 2 and the total number of unique domains
print('Finding optimal number of clusters')
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(embeddings)
score = silhouette_score(embeddings, kmeans.labels_)
silhouette_scores.append(score)
# Find the optimal number of clusters
optimal_k = K_range[np.argmax(silhouette_scores)]
print(f'Optimal number of clusters: {optimal_k}')
# Plot the silhouette scores
plot_silhouette_scores(K_range, silhouette_scores, optimal_k)
The following graph shows the Silhouette scores of all clusters and the optimal number of clusters.
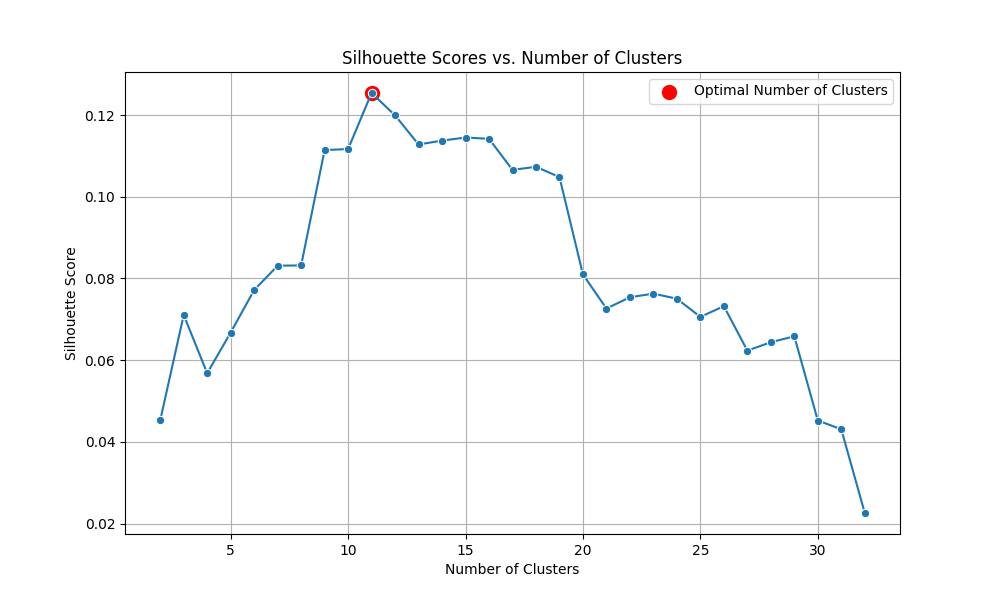
Clustering is done with the optimal number of clusters (optimal_k) with the following code snippet. The clusters with the unique data points are stored in dedup_clusters. These clusters are also mapped to the original data points and are stored in original_clusters for later use.
# Perform k-means clustering with the optimal number of clusters
kmeans = KMeans(n_clusters=optimal_k, random_state=42)
kmeans.fit(embeddings)
dedup_clusters = kmeans.labels_
# Map clusters back to the original data points
original_clusters = [dedup_clusters[idx] for idx in original_to_dedup]
The original_clusters are sent to gpt-4o-mini model to assign labels. The following code snippet shows the system and input prompts sent with the payload. The output is received in JSON format. For this task, a higher temperature (0.7) is selected so that the model can utilize some creativity for assigning suitable labels.
# Function to label clusters using GPT-4-o-mini
def label_clusters_with_gpt(clusters, api_key):
# Prepare the input for GPT-4
cluster_descriptions = []
for cluster_id, data_points in clusters.items():
cluster_descriptions.append(f"Cluster {cluster_id}: {', '.join(data_points)}")
# Prepare the system and input messages
system_message = "You are a helpful assistant"
input_message = (
"Please label each of the following clusters with a concise, specific label based on the semantic similarity "
"of the data points within each cluster."
"Output in a JSON format where the keys are cluster numbers and the values are cluster labels."
"nn" + "n".join(cluster_descriptions)
)
# Set up the request payload
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o-mini", # Model name
"messages": [
{"role": "system", "content": system_message},
{"role": "user", "content": input_message}
],
"max_tokens": 2000,
"temperature": 0.7
}
# Send the request to the API
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
# Extract and parse the response
if response.status_code == 200:
response_data = response.json()
response_text = response_data['choices'][0]['message']['content'].strip()
try:
# Ensure that the JSON is correctly formatted
response_text = response_text.replace("```json", "").replace("```", "").strip()
cluster_labels = json.loads(response_text)
except json.JSONDecodeError as e:
print("Failed to parse JSON:", e)
cluster_labels = {}
return cluster_labels
else:
print(f"Request failed with status code {response.status_code}")
print("Response Body:", response.text)
return None
The following function, clusters_to_dataframe, transforms the JSON output from gpt-4o-mini into a structured pandas DataFrame. It organizes labeled clusters by converting each cluster’s label, associated data points, and the count of original data points into a tabular format. The function ensures that each cluster is clearly identified by its number, label, and content, making it easier to analyze and visualize the clustering results. The resulting data frame is sorted by cluster number, providing a clean and organized view of the data.
# Function to convert the JSON labeled clusters into a DataFrame
def clusters_to_dataframe(cluster_labels, clusters, original_clustered_data):
data = {"Cluster Number": [], "Label": [], "Data Points": [], "Original Data Points": []}
# Iterate through the cluster labels
for cluster_num, label in cluster_labels.items():
cluster_num = int(cluster_num) # Convert cluster number to integer
data["Cluster Number"].append(cluster_num)
data["Label"].append(label)
data["Data Points"].append(repr(clusters[cluster_num])) # Use repr to retain the original list format
data["Original Data Points"].append(len(original_clustered_data[cluster_num])) # Count original data points
# Convert to DataFrame and sort by "Cluster Number"
df = pd.DataFrame(data)
df = df.sort_values(by='Cluster Number').reset_index(drop=True)
return df
The final data frame returned by this function is shown below.
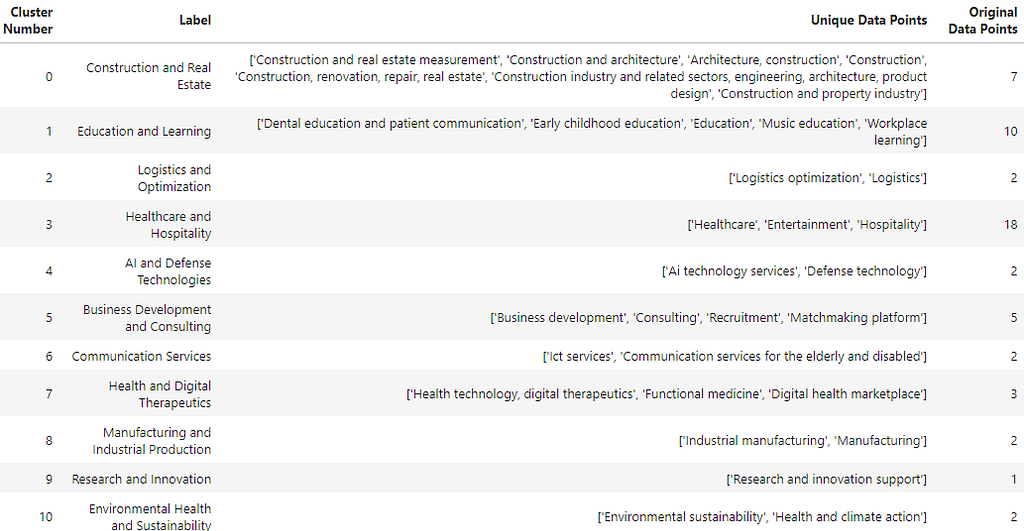
The following code snippet plots a visualization of the number of companies in each sector.
'''draw visualization'''
import plotly.express as px
# Use the "Original Data Points" column for the number of companies
df_labeled_clusters['No. of companies'] = df_labeled_clusters['Original Data Points']
# Create the Plotly bar chart
fig = px.bar(df_labeled_clusters,
x='Label',
y='No. of companies',
title="Number of Companies per Sector",
labels={'Label': 'Sectors', 'No. of companies': 'No. of Companies'})
# Update layout for better visibility
fig.update_layout(
xaxis_title="Sectors",
yaxis_title="No. of Companies",
xaxis={'categoryorder':'total descending'}, # Order bars by descending number of companies
yaxis=dict(type='linear'),
showlegend=False
)
# Display the figure
fig.show()
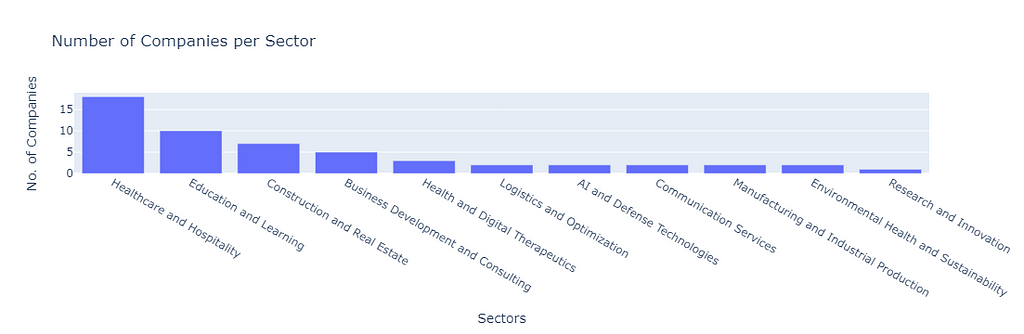
Conclusion
In this article, I demonstrated how an LLM can be used to transform data from semi-structured and unstructured documents into structured formats. Subsequently, the structured data can be further analyzed using traditional machine learning and statistical methods.
For illustration purposes, I focused only on clustering the “area/domain” field to identify the major sectors companies operate in. However, this approach can be extended to various other data fields, such as identifying the types of current solutions offered by companies, analyzing AI technologies in use or under consideration, clustering the “aim” field to uncover major AI trends in business, examining the “data_requirement_assessment” field to understand existing data needs, and clustering the “fair_services_sought” field to find key advisory interests from companies. Additionally, the “recommendation” field, which contains rich advisory data across different domains, can also be analyzed using this technique.
Due to privacy constraints, I cannot share the original dataset. However, I have provided sample documents on GitHub that can be used to run and test the entire code.
This approach and code are not limited to the specific documents used in this demonstration. The code and LLM parameters, especially the prompts, can be adapted to other types of documents. The code can also be modified to parse data from images (e.g., scanned invoices, financial and healthcare documents, etc.) and subsequent analysis.
If you like the article, please clap the article and follow me on Medium and/or LinkedIn
GitHub
For the full code reference, please take a look at my repo:
References and Other Related Posts You May Like
Magyar, Dávid, and Sándor Szénási. “Parsing via Regular Expressions.” 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). IEEE, 2021.
https://platform.openai.com/docs/models/gpt-4o-mini
- Recommending Reviewers/Experts Using Semantic Matching
- Ranking and Selecting Data from Large Structured Documents using Large Language Models
- Text clustering with LLM embeddings
LLM-Powered Parsing and Analysis of Semi-Structured & Structured Documents was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.