

Running Qwen2 on SageMaker
In this post I will explain how to run a state-of-the-art 7B parameter LLM based embedding model on just a single 24GB GPU. I will cover some theory and then show how to run it with the HuggingFace Transformers library in Python in just a few lines of code!
The model that we will run in the Qwen2 open source model (Alibaba-NLP/gte-Qwen2–7B-instruct) which was released in June 2024, and at the time of finishing this article is in 4th place on the Massive Text Embeddings Benchmark on HuggingFace.
Theoretical Memory Requirements
Loading a Model
The amount of memory required to load a machine learning model (e.g. LLM or Embedding model) can be calculated from the number of its parameters.
For example, a 7B parameter model in fp32 (float32 precision), means that we need to store 7B numbers in 32-bit precision in order to initialise the model in memory and be able to use it. Therefore, recalling that there are 8 bits in one byte, the memory needed to load the model is
Memory of a 7B param model in fp32 = 7B * 32 bits = 7B * 32 / 8 bytes = 28B bytes = 28GB.
So in order to run this model we need at least 28GB of GPU memory. In fact there is also some additional overhead as described in this post. As a result to run this model in full precision we cannot use smaller and cheaper GPU’s which have 16GB or 24GB of memory.
So without a more powerful GPU such as NVIDIA’s A100, what alternatives do we have? It turns out there a few different techniques to reduce the memory requirement. The simplest one is to reduce the precision of the parameters. Most models can now be used in half precision without any significant loss in accuracy. The memory required to load a model in fp16 or bf16 is
Memory of a 7B param model in fp16 = 7B * 16 bits = 7B * 16 / 8 bytes = 14B bytes = 14GB.
Whilst this is already good enough to load the model on a 24GB GPU, we would still struggle to run it on a 16GB GPU, due to the additional overheads and extra requirements during inference.
Reducing the precision anymore than this naively would already start impacting performance but there is a technique called quantisation which is able to reduce the precision even further (such as into 8bits or 4bits) without a significant drop in accuracy. Recent research in LLMs has even shown the possibility of using 1 bit precision (actually, log_2(3) = 1.58 bits) known as 1-bit LLMs. The parameters of these models can only take the values of 1, -1 or 0!
To read up more on these topics I would recommend:
- Understanding floating point representations from the following tutorial.
- Quantisation Fundamentals with Huggingface free course from DeepLearning.AI.
Inference
The above calculations only tell us how much memory we need to simply load the model! On top of this we need additional memory to actually run some input through the model. For the Qwen2 embedding model and LLMs in general the extra memory required depends on the size of the context window (ie. the length of the text passed into the model).
Older Models with Original Self-Attention Mechanism
Before the release of Flash Attention which is now widely adopted, a lot of older Language Models were using the original self-attention from the Transformer architecture. This mechanism requires an additional memory which scales quadratically with the input sequence length. To illustrate why that’s the case below is a great visual reminder of self-attention.
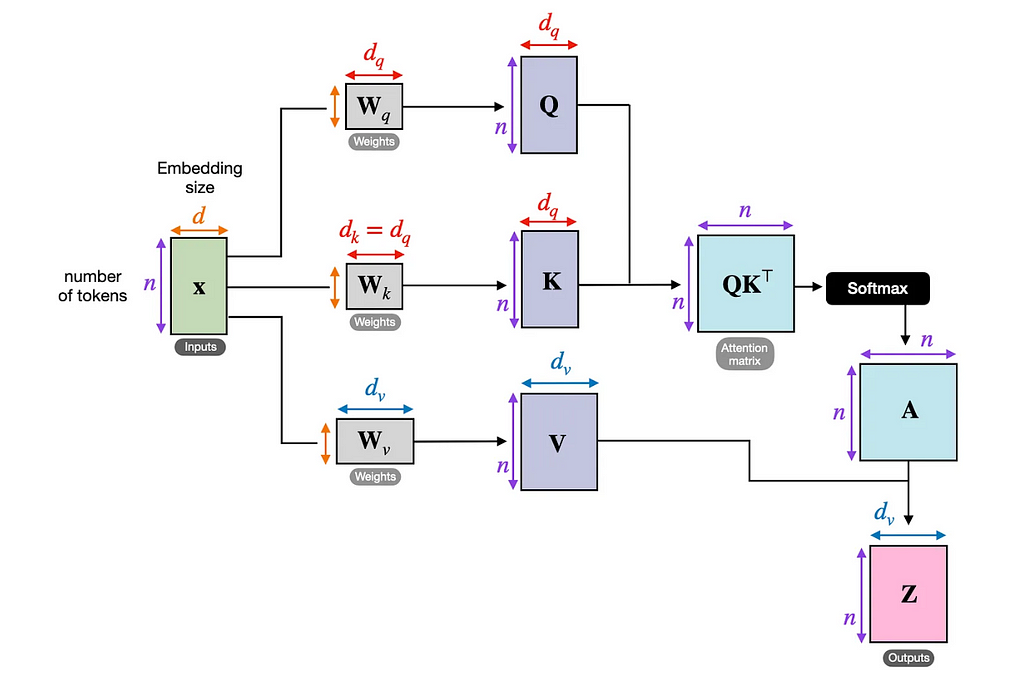
From the diagram we can see that apart from model weights (the Wq, Wk, Wv matrices) which we accounted for when calculating the memory required to load the model, there are many additional calculations and their outputs which need to be stored. These include for example, the inputs X, the Q, K, V matrices, and the attention matrix QK^T. It turns out that as the size of the input sequence length, n, grows the attention matrix becomes the dominant factor in the extra memory required.
To understand this we can perform a few simple calculations. For example, in the original transformer the embedding dimension size, d, was 512. So for an input sequence of 512 tokens both the inputs X and the attention matrix would require an additional 1MB of memory each in fp32.
512² floats = 512² * 32 bits = 512² * 4 bytes = 1MB
If we increase the input sequence length to 8000 tokens, the extra memory requirements would be
Inputs X = 512 * 8000 * 4 bytes = 16MB; Attention Matrix = 8000² * 4 bytes = 256MB.
and if we increase the input sequence length to 32k tokens the extra memory requirements would be
Inputs X = 512 * 32000 * 4 bytes = 65MB; Attention Matrix = 32000² * 4 bytes = 4GB!
As you can see the extra memory required grows very quickly with the size of the context window, and is quickly dominated by the n² number of floats in the attention matrix!
The above calculations are still very much a simplification as there a lot more details which contribute to even more memory usage. For instance, in the original transformer there is also multi-head attention — where the attention computation is computed in parallel with many different heads (8 in the original implementation). So we need to multiply the required memory by the number of heads. Similarly, the above calculations were for a batch size of 1, if we want to embed many different texts at once we can increase the batch size, but at the cost of additional memory. For a detailed breakdown of the different memory requirements see the following article.
More Recent Models like Qwen2
Since the release of the Transformer in 2017, there has been a lot of research into alternative attention mechanisms to avoid the n² bottleneck. However, they came with the tradeoff of decreased accuracy. In 2022, an exact attention mechanism came out with specific GPU optimisations called Flash Attention and has been widely adopted in LLMs. Since then theres been further iterations including the recent Flash Attention 3 released in July 2024. The most important takeaway for us is that Flash Attention scales linearly with the input sequence length!
Below is a theoretical derivation which compares the memory requirements of a 20B parameter model with different sequence lengths of different attention mechanisms. The Padding-Free Transformer is yet another optimisation which removes the need of padding — very useful if you have one long sequence and many short sequences in a batch.
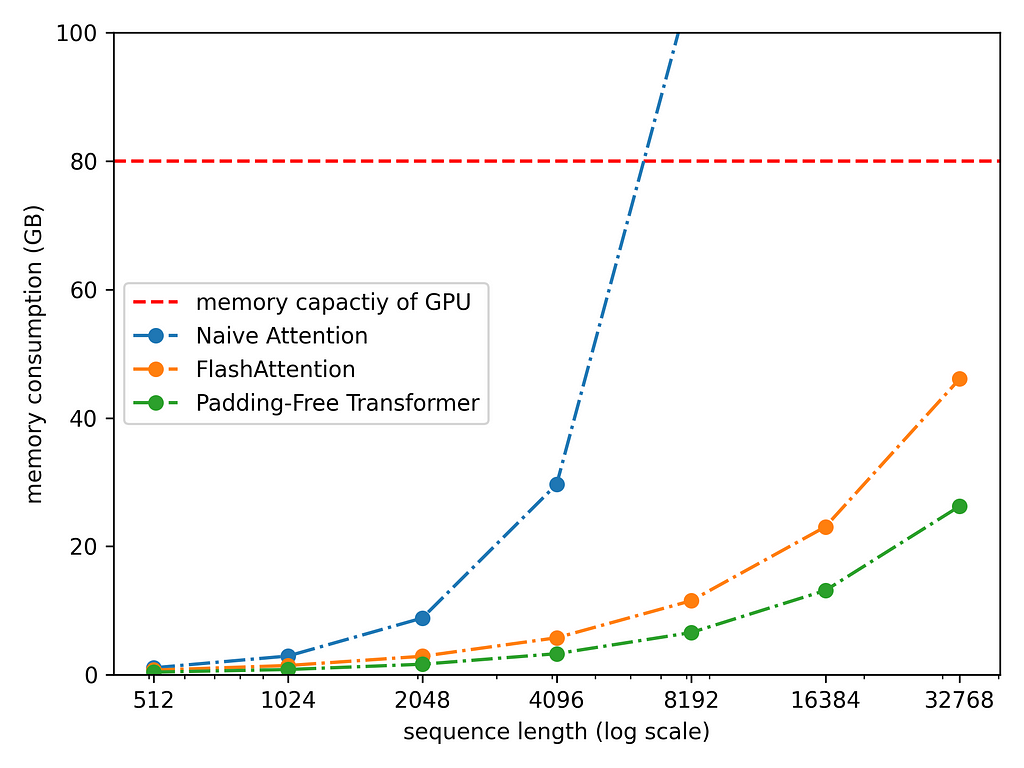
The Qwen2 model uses both the Flash Attention and padding optimisations. Now with the theory covered let’s see how to actually run the Qwen2 model!
Running a 7B Qwen2 Model with HuggingFace Transformers
Set Up
The model that we will experiment with is the Alibaba-NLP/gte-Qwen2-7B-instruct from Transformers. The model card is here.
To perform this experiment, I have used Python 3.10.8 and installed the following packages:
torch==2.3.0
transformers==4.41.2
xformers==0.0.26.post1
flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu122torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
accelerate==0.31.0
I ran into some difficulty in installing flash-attn required to run this model and so had to install the specific version listed above. If anyone has a better workaround please let me know!
The Amazon SageMaker instance I used for this experiment is the ml.g5.2xlarge. It has a 24GB NVIDIA A10G GPU and 32GB of CPU memory and it costs $1.69/hour. The below screenshot from AWS shows all the details of the instance
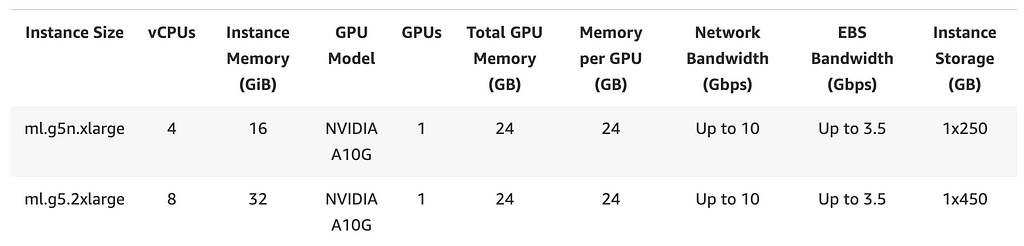
Actually to be precise if you run nvidia-smi you will see that the instance only has 23GB of GPU memory which is slightly less than advertised. The CUDA version on this GPU is 12.2.
How to Run — In Detail
If you look at the model card, one of the suggested ways to use this model is via the sentence-transformers library as show below
from sentence_transformers import SentenceTransformer
# This will not run on our 24GB GPU!
model = SentenceTransformer("Alibaba-NLP/gte-Qwen2-7B-instruct", trust_remote_code=True)
embeddings = model.encode(list_of_examples)
Sentence-transformers is an extension of the Transformers package for computing embeddings and is very useful as you can get things working with two lines of code. The downside is that you have less control on how to load the model as it hides away tokenisation and pooling details. The above code will not run on our GPU instance because it attempts to load the model in full float32 precision which would take 28GB of memory. When the sentence transformer model is initialised it checks for available devices (cuda for GPU) and automatically shifts the Pytorch model onto the device. As a result it gets stuck after loading 5/7ths of the model and crashes.
Instead we need to be able to load the model in float16 precision before we move it onto the GPU. As such we need to use the lower level Transformers library. (I am not sure of a way to do it with sentence-transformers but let me know if one exists!) We do this as follows
import transformers
import torch
model_path = "Alibaba-NLP/gte-Qwen2-7B-instruct"
model = transformers.AutoModel.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.float16).to("cuda")
With the torch_dtype parameter we specify that the model should be loaded in float16 precision straight away, thus only requiring 14GB of memory. We then need to move the model onto the GPU device which is achieved with the to method. Using the above code, the model takes almost 2min to load!
Since we are using transformers we need to separately load the tokeniser to tokenise the input texts as follows:
tokenizer = transformers.AutoTokenizer.from_pretrained(model_path)
The next step is to tokenise the input texts which is done as follows:
texts = ["example text 1", "example text 2 of different length"]
max_length = 32768
batch_dict = tokenizer(texts, max_length=max_length, padding=True, truncation=True, return_tensors="pt").to(DEVICE)
The maximum length of the Qwen2 model is 32678, however as we will see later we are unable to run it with such a long sequence on our 24GB GPU due to the additional memory requirements. I would recommend reducing this to no more than 24,000 to avoid out of memory errors. Padding ensures that all the inputs in the batch have the same length whilst truncation ensures that any inputs longer than the maximum length will be truncated. For more information please see the docs. Finally, we ensure that we return PyTorch tensors (default would be lists instead) and move these tensors onto the GPU to be available to pass to the model.
The next step is to pass the inputs through our model and perform pooling. This is done as follows
with torch.no_grad():
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict["attention_mask"])
with the last_token_pool which looks as follows:
def last_token_pool(last_hidden_states: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
# checks whether there is any padding (where attention mask = 0 for a given text)
no_padding = attention_mask[:, -1].sum() == attention_mask.shape[0]
# if no padding - only would happen if batch size of 1 or all sequnces have the same length, then take the last tokens as the embeddings
if no_padding:
return last_hidden_states[:, -1]
# otherwise use the last non padding token for each text in the batch
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengthsLet’s break down what happened in the above code snippets!
- The torch.no_grad() context manager is used to disable gradient calculation, since we are not training the model and hence to speed up the inference.
- We then pass the tokenised inputs into the transformer model.
- We retrieve the outputs from the last layer of the model with the last_hidden_state attribute. This is a tensor of shape (batch_size, max_sequence_length, embedding dimension). Essentially for each example in the batch the transformer outputs embeddings for all the tokens in the sequence.
- We now need some way of combining all the token embeddings into a single embedding to represent the input text. This is called pooling and it is done in the same way as during training of the model.
- In older BERT based models the first token was typically used (which represented the special classification [CLS] token). However, the Qwen2 model is LLM-based, i.e. transformer decoder based. In the decoder, the tokens are generated auto regressively (one after another) and so the last token contains all the information encoded about the sentence.
- The goal of the last_token_pool function is to therefore select the embedding of the last generated token (which was not the padding token) for each example in the batch.
- It uses the attention_mask which tells the model which of the tokens are padding tokens for each example in the batch (see the docs).
Annotated Example
Let’s look at an example to understand it in a bit more detail. Let’s say we want to embed two examples in a single batch:
texts = ["example text 1", "example text 2 of different length"]
The outputs of the tokeniser (the batch_dict ) will look as follows:
>>> batch_dict
{'input_ids': tensor([[ 8687, 1467, 220, 16, 151643, 151643, 151643],
[ 8687, 1467, 220, 17, 315, 2155, 3084]],
device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
From this you can see that the first sentence gets split into four tokens (8687, 1467, 220, 16), while the second sentence get split into seven tokens. As a result, the first sentence is padded (with three padding tokens with id 151643) up to length seven — the maximum in the batch. The attention mask reflects this — it has three zeros for the first example corresponding to the location of the padding tokens. Both the tensors have the same size
>>> batch_dict.input_ids.shape
torch.Size([2, 7])
>>> batch_dict.attention_mask.shape
torch.Size([2, 7])
Now passing the batch_dict through the model we can retrieve the models last hidden state of shape:
>>> outputs.last_hidden_state.shape
torch.Size([2, 7, 3584])
We can see that this is of shape (batch_size, max_sequence_length, embedding dimension). Qwen2 has an embedding dimension of 3584!
Now we are in the last_token_pool function. The first line checks if padding exists, it does it by summing the last “column” of the attention_mask and comparing it to the batch_size (given by attention_mask.shape[0]. This will only result in true if there exists a 1 in all of the attention mask, i.e. if all the examples are the same length or if we only have one example.
>>> attention_mask.shape[0]
2
>>> attention_mask[:, -1]
tensor([0, 1], device='cuda:0')
If there was indeed no padding we would simply select the last token embedding for each of the examples with last_hidden_states[:, -1]. However, since we have padding we need to select the last non-padding token embedding from each example in the batch. In order to pick this embedding we need to get its index for each example. This is achieved via
>>> sequence_lengths = attention_mask.sum(dim=1) - 1
>>> sequence_lengths
tensor([3, 6], device='cuda:0')
So now we need to simply index into the tensor, with the correct indices in the first two dimensions. To get the indices for all the examples in the batch we can use torch.arange as follows:
>>> torch.arange(batch_size, device=last_hidden_states.device)
tensor([0, 1], device='cuda:0')
Then we can pluck out the correct token embeddings for each example using this and the indices of the last non padding token:
>>> embeddings = last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
>>> embeddings.shape
torch.Size([2, 3584])
And we get two embeddings for the two examples passed in!
How to Run — TLDR
The full code separated out into functions looks like
import numpy as np
import numpy.typing as npt
import torch
import transformers
DEVICE = torch.device("cuda")
def last_token_pool(last_hidden_states: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
# checks whether there is any padding (where attention mask = 0 for a given text)
no_padding = attention_mask[:, -1].sum() == attention_mask.shape[0]
# if no padding - only would happen if batch size of 1 or all sequnces have the same length, then take the last tokens as the embeddings
if no_padding:
return last_hidden_states[:, -1]
# otherwise use the last non padding token for each text in the batch
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths
def encode_with_qwen_model(
model: transformers.PreTrainedModel,
tokenizer: transformers.tokenization_utils.PreTrainedTokenizer | transformers.tokenization_utils_fast.PreTrainedTokenizerFast,
texts: list[str],
max_length: int = 32768,
) -> npt.NDArray[np.float16]:
batch_dict = tokenizer(texts, max_length=max_length, padding=True, truncation=True, return_tensors="pt").to(DEVICE)
with torch.no_grad():
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict["attention_mask"])
return embeddings.cpu().numpy()
def main() -> None:
model_path = "Alibaba-NLP/gte-Qwen2-7B-instruct"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_path)
model = transformers.AutoModel.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.float16).to(DEVICE)
print("Loaded tokeniser and model")
texts_to_encode = ["example text 1", "example text 2 of different length"]
embeddings = encode_with_qwen_model(model, tokenizer, texts_to_encode)
print(embeddings.shape)
if __name__ == "__main__":
main()
The encode_with_qwen_model returns a numpy array. In order to convert a PyTorch tensor to a numpy array we first have to move it off the GPU back onto the CPU which is achieved with the cpu() method. Please note that if you are planning to run long texts you should reduce the batch size to 1 and only embed one example at a time (thus reducing the list texts_to_encode to length 1).
Empirical Memory Usage Tests with Context Length
Before we saw how the memory usage varies with the input text size from a theoretical standpoint. We can also measure how much memory the GPU actually uses when embedding texts of different length and verify the scaling empirically! I got the idea from this great HuggingFace tutorial: Getting the most out of LLMs.
To do this we will make use of some extra functions
import gc
def flush() -> None:
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
def bytes_to_giga_bytes(bytes_: float) -> float:
return bytes_ / 1024 / 1024 / 1024
as well the
torch.cuda.max_memory_allocated()
function to measure the peak GPU usage. The flush function will clear and reset the memory after each pass through the model. We will run texts of different lengths through the model and print out the peak and effective GPU usage. The effective GPU usage is the model size usage subtracted from the total usage which gives us an idea of how much extra memory we need to run the text through the model.
The full code I used is below:
import gc
import numpy as np
import numpy.typing as npt
import torch
import transformers
DEVICE = torch.device("cuda")
def last_token_pool(last_hidden_states: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
# checks whether there is any padding (where attention mask = 0 for a given text)
left_padding = attention_mask[:, -1].sum() == attention_mask.shape[0]
# if no padding - only would happen if batch size of 1 or all sequences have the same length, then take the last tokens as the embeddings
if left_padding:
return last_hidden_states[:, -1]
# otherwise use the last non padding token for each text in the batch
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def encode_with_qwen_model(
model: transformers.PreTrainedModel,
tokenizer: transformers.tokenization_utils.PreTrainedTokenizer | transformers.tokenization_utils_fast.PreTrainedTokenizerFast,
texts: list[str] | str,
max_length: int = 32768,
) -> npt.NDArray[np.float16]:
batch_dict = tokenizer(texts, max_length=max_length, padding=True, truncation=True, return_tensors="pt").to(DEVICE)
with torch.no_grad():
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict["attention_mask"])
return embeddings.cpu().numpy()
def flush() -> None:
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
def bytes_to_giga_bytes(bytes_: float) -> float:
return bytes_ / 1024 / 1024 / 1024
def memory_usage_experiments(
model: transformers.PreTrainedModel,
tokenizer: transformers.tokenization_utils.PreTrainedTokenizer | transformers.tokenization_utils_fast.PreTrainedTokenizerFast,
) -> None:
model_size = bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
print(f"Most gpu usage on model loaded: {model_size} GBn")
sentence = "This sentence should have minimum eight tokens. "
all_texts = [sentence, sentence * 100, sentence * 1000, sentence * 2000, sentence * 3000, sentence * 4000]
for texts in all_texts:
batch_dict = tokenizer(texts, max_length=32768, padding=True, truncation=True, return_tensors="pt")
encode_with_qwen_model(model, tokenizer, texts)
max_mem = bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
print(f"Sequence length: {batch_dict.input_ids.shape[-1]}. Most gpu usage: {max_mem} GB. Effective usage: {max_mem - model_size} GBn")
flush()
def main() -> None:
model_path = "Alibaba-NLP/gte-Qwen2-7B-instruct"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_path)
model = transformers.AutoModel.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.float16).to(DEVICE)
print("Loaded tokeniser and model")
memory_usage_experiments(model, tokenizer)
if __name__ == "__main__":
main()
and the traceback is
Most gpu usage on model loaded: 14.958292961120605 GB
Sequence length: 9. Most gpu usage: 14.967926502227783 GB. Effective usage: 0.009633541107177734 GB
Sequence length: 801. Most gpu usage: 15.11520528793335 GB. Effective usage: 0.15691232681274414 GB
Sequence length: 8001. Most gpu usage: 16.45930576324463 GB. Effective usage: 1.5010128021240234 GB
Sequence length: 16001. Most gpu usage: 17.944651126861572 GB. Effective usage: 2.986358165740967 GB
Sequence length: 24001. Most gpu usage: 19.432421684265137 GB. Effective usage: 4.474128723144531 GB
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.13 GiB. GPU
We can see from this that the Qwen2 model indeed scales linearly with the size of the input text. For example, as we double the number of tokens from 8000 to 16000, the effective memory usage roughly doubles as well. Unfortunately, trying to run a sequence of length 32000 through the model resulted in a CUDA OOM error so even with a 24GB GPU in float 16 precision we are still unable to utilise the full context window of the model.
Other Aspects
Running Qwen2 in fp32
To run the Qwen2 model in full precision we have two options. Firstly we can get access to a bigger GPU — for example 40GB would be enough. However, this could be costly. Amazon SageMaker for instance does not have an instance with a single 40GB GPU, instead it has an instance with 8 of them! But that wouldn’t be useful as we do not need the other 7 sitting idly. Of course we may also look at other providers as well — there are quite a few now and offering competitive prices.
The other option is to run the model on an instance with multiple smaller GPUs. The model can be sharded across different GPUs — i.e. different layers of the model are put on different GPUs and the data gets moved across the devices during inference. To do this with HuggingFace you can do
model_path = "Alibaba-NLP/gte-Qwen2-7B-instruct"
model = transformers.AutoModel.from_pretrained(model_path, trust_remote_code=True, device_map="auto").to("cuda")
For more information on how this works see the following docs and the conceptual guide. The caveat is that this way of doing it is a lot slower — due to the overhead of inter-GPU communication, moving data across the different devices to perform inference. This implementation is also not optimised, meaning execution on each GPU happens sequentially whilst others are sitting idle. If you were embedding thousands of texts or training the model you would ideally have all the GPUs constantly doing some work.
Running Qwen2 on smaller GPUs
To run this model on even smaller GPUs you would need to quantise the model. Two popular options would be
Conclusion
In conclusion in this article we saw how to run a 7B LLM based Qwen2 Embedding model on a single 24GB GPU. We saw how the size of the model is calculated from the number of its parameters and that we need to load the model in float16 precision to fit it onto the 24GB GPU. We then saw that extra memory is required to actually run an example through the model which depends on the size of the context window and varies depending on the underlining attention mechanism used. Finally we saw how to do all of this in just a few lines of code with the Transformers library.
Running a SOTA 7B Parameter Embedding Model on a Single GPU was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Running a SOTA 7B Parameter Embedding Model on a Single GPU
Go Here to Read this Fast! Running a SOTA 7B Parameter Embedding Model on a Single GPU