Using LLMs to generate synthetic data and code

Intro
I’ve been working on weekend LLM projects. When contemplating what to work on, two ideas struck me:
- There are few resources for practicing data analytics interviews in contrast to other roles like software engineering and product management. I relied on friends in the industry to make up SQL and Python interview questions when I practiced interviewing for my first data analyst job.
- LLMs are really good at generating synthetic datasets and writing code.
As a result, I’ve built the AI Data Analysis Interviewer which automatically creates a unique dataset and generates Python interview questions for you to solve!
This article provides an overview of how it works and its technical implementation. You can check out the repo here.
Demo
When I launch the web app I’m prompted to provide details on the type of interview I want to practice for, specifically the company and a dataset description. Let’s say I’m interviewing for a data analyst role at Uber which focuses on analyzing ride data:
After clicking Submit and waiting for GPT to do its magic, I receive the AI generated questions, answers, and an input field where I can execute code on the AI generated dataset:
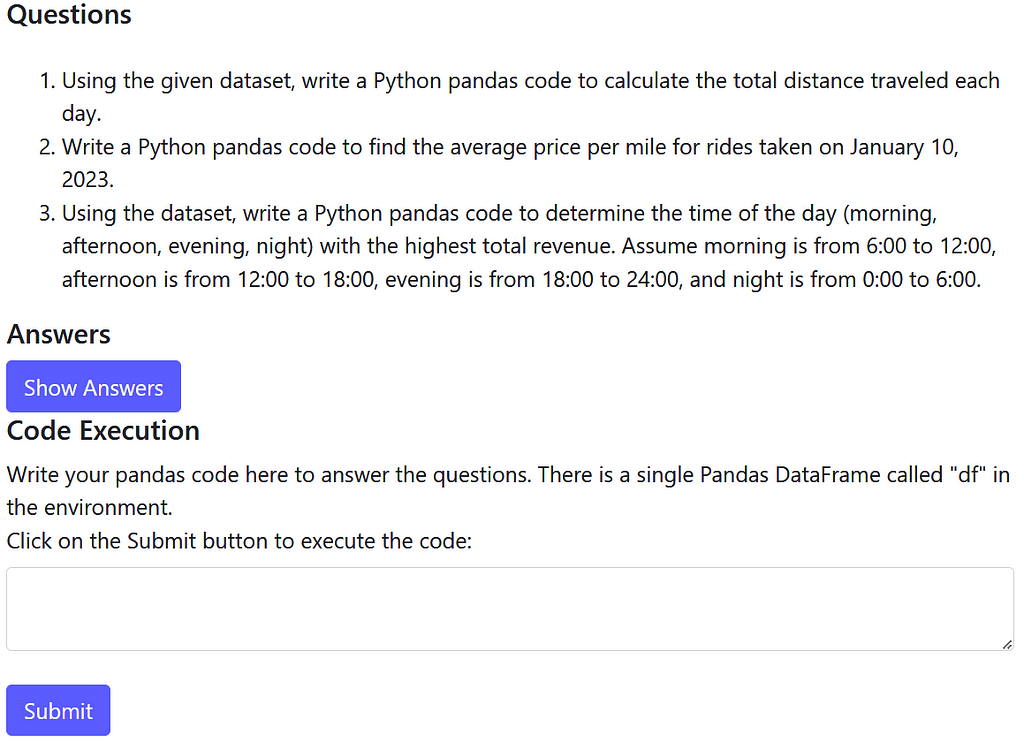
Awesome! Let’s try to solve the first question: calculate the total distance traveled each day. As is good analytics practice, let’s start with data exploration:
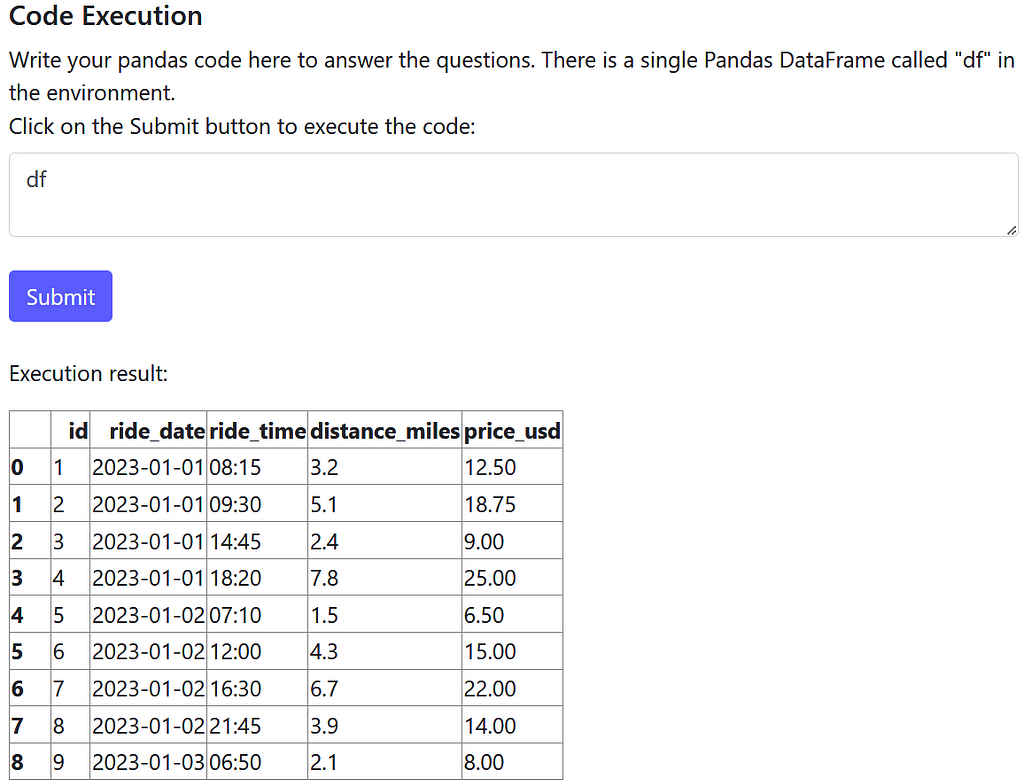
It looks like we need to group by the ride_date field and sum the distance_miles field. Let’s write and submit that Pandas code:
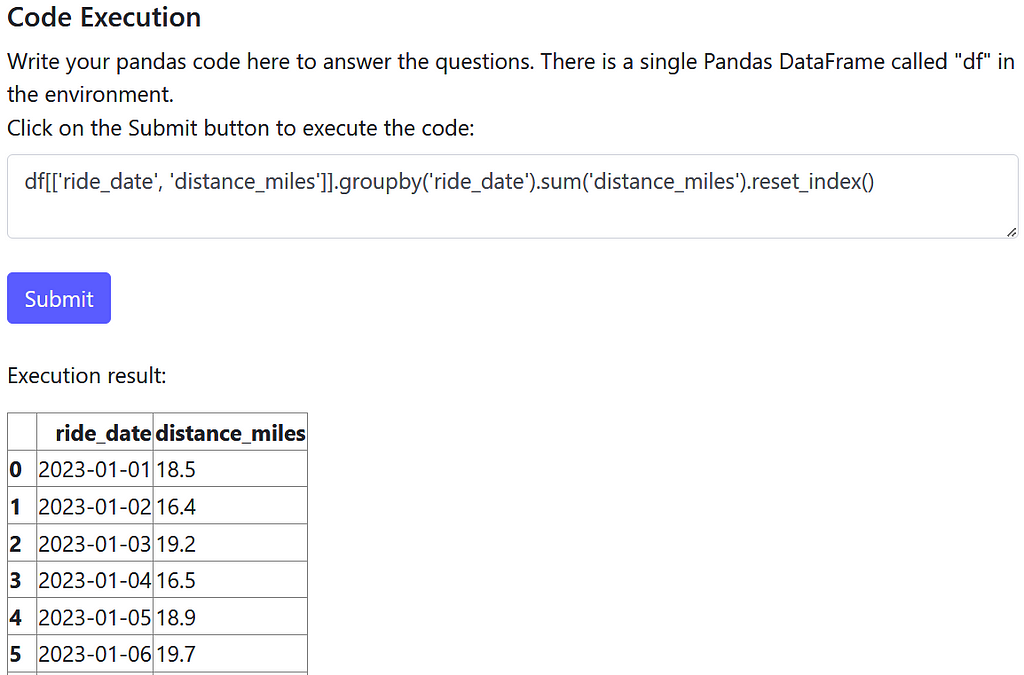
Looks good to me! Does the AI answer agree with our approach?
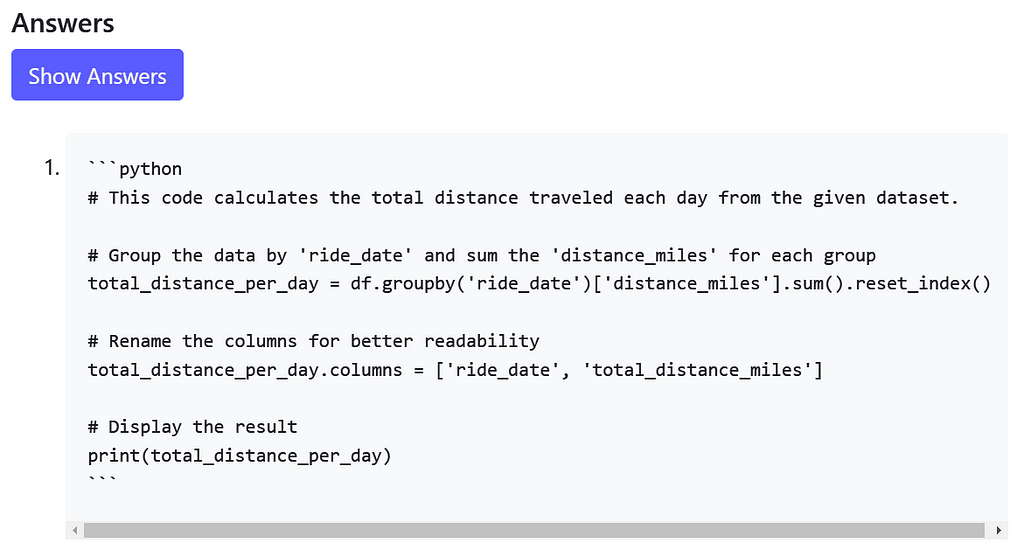
The AI answer uses a slightly different methodology but solves the problem essentially in the same way.
I can rinse and repeat as much as needed to feel great before heading into an interview. Interviewing for Airbnb? This tool has you covered. It generates the questions:
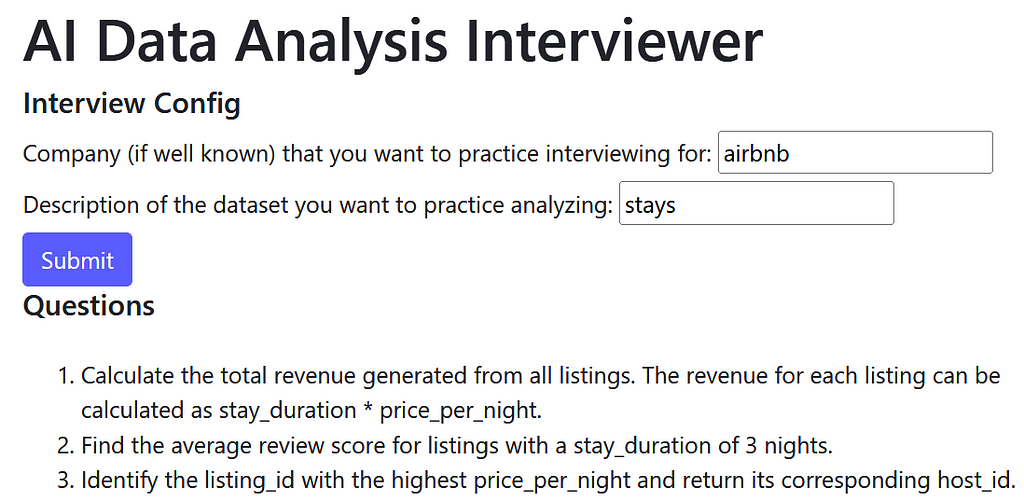
Along with a dataset you can execute code on:
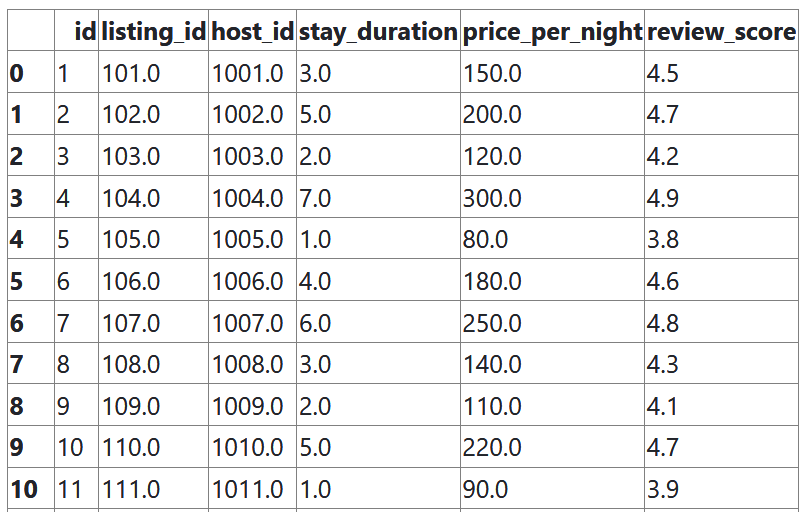
How to use the app
Check out the readme of the repo here to run the app locally. Unfortunately I didn’t host it but I might in the future!
High-level design
The rest of this article will cover the technical details on how I created the AI Data Analysis Interviewer.
LLM architecture
I used OpenAI’s gpt-4o as it’s currently my go-to LLM model (it’s pretty easy to swap this out with another model though.)
There are 3 types of LLM calls made:
- Dataset generation: we ask a LLM to generate a dataset suitable for an analytics interview.
- Question generation: we ask a LLM to generate a couple of analytics interview questions from that dataset.
- Answer generation: we ask a LLM to generate the answer code for each interview question.
Front-end
I built the front-end using Flask. It’s simple and not very interesting so I’ll focus on the LLM details below. Feel free to check out the code in the repo however!
Design details
LLM manager
LLMManager is a simple class which handles making LLM API calls. It gets our OpenAI API key from a local secrets file and makes an OpenAI API call to pass a prompt to a LLM model. You’ll see some form of this in every LLM project.
class LLMManager():
def __init__(self, model: str = 'gpt-4o'):
self.model = model
load_dotenv("secrets.env")
openai_api_key = os.getenv("OPENAI_API_KEY")
self.client = OpenAI(api_key=openai_api_key)
def call_llm(self, system_prompt: str, user_prompt: str, temperature: float) -> str:
print(f"Calling LLM with system prompt: {system_prompt}nnUser prompt: {user_prompt}")
response: ChatCompletion = self.client.chat.completions.create(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
model=self.model,
temperature=temperature
)
message = response.choices[0].message.content
print(response)
return message
Dataset generation
Here is where the fun starts!
We first prompt a LLM to generate a dataset with the following prompt:
SYSTEM_TEMPLATE = """You are a senior staff data analyst at a world class tech company.
You are designing a data analysis interview for hiring candidates."""
DATA_GENERATION_USER_TEMPLATE = """Create a dataset for a data analysis interview that contains interesting insights.
Specifically, generate comma delimited csv output with the following characteristics:
- Relevant to company: {company}
- Dataset description: {description}
- Number of rows: 100
- Number of columns: 5
Only include csv data in your response. Do not include any other information.
Start your output with the first header of the csv: "id,".
Output: """
Let’s break it down:
- Many LLM models follow a prompt structure where the LLM accepts a system and user message. The system message is intended to define general behavior and the user message is intended to provide specific instructions. Here we prompt the LLM to be a world class interviewer in the system message. It feels silly but hyping up a LLM is a proven prompt hack to get better performance.
- We pass the user inputs about the company and dataset they want to practice interviewing with into the user template through the string variables {company} and {description}.
- We prompt the LLM to output data in csv format. This seems like the simplest tabular data format for a LLM to produce which we can later convert to a Pandas DataFrame for code analysis. JSON would also probably work but may be less reliable given the more complex and verbose syntax.
- We want the LLM output to be parseable csv, but gpt-4o tends to generate extra text likely because it was trained to be very helpful. The end of the user template strongly instructs the LLM to just output parseable csv data, but even so we need to post-process it.
The class DataGenerator handles all things data generation and contains the generate_interview_dataset method which makes the LLM call to generate the dataset:
def generate_interview_dataset(self, company: str, description: str, mock_data: bool) -> str:
if not mock_data:
data_generation_user_prompt = DATA_GENERATION_USER_TEMPLATE.format(company=company, description=description)
dataset = self.llm_manager.call_llm(
system_prompt=SYSTEM_TEMPLATE,
user_prompt=data_generation_user_prompt,
temperature=0
)
dataset = self.clean_llm_dataset_output(dataset)
return dataset
return MOCK_DATASET
def clean_llm_dataset_output(self, dataset: str) -> str:
cleaned_dataset = dataset[dataset.index("id,"):]
return cleaned_dataset
Note that the clean_llm_dataset_output method does the light post-processing mentioned above. It removes any extraneous text before “id,” which denotes the start of the csv data.
LLMs only can output strings so we need to transform the string output into an analyzable Pandas DataFrame. The convert_str_to_df method takes care of that:
def convert_str_to_df(self, dataset: str) -> pd.DataFrame:
csv_data = StringIO(dataset)
try:
df = pd.read_csv(csv_data)
except Exception as e:
raise ValueError(f"Error in converting LLM csv output to DataFrame: {e}")
return df
Question generation
We can prompt a LLM to generate interview questions off of the generated dataset with the following prompt:
QUESTION_GENERATION_USER_TEMPLATE = """Generate 3 data analysis interview questions that can be solved with Python pandas code based on the dataset below:
Dataset:
{dataset}
Output the questions in a Python list where each element is a question. Start your output with [".
Do not include question indexes like "1." in your output.
Output: """
To break it down once again:
- The same system prompt is used here as we still want the LLM to embody a world-class interviewer when writing the interview questions.
- The string output from the dataset generation call is passed into the {dataset} string variable. Note that we have to maintain 2 representations of the dataset: 1. a string representation that a LLM can understand to generate questions and answers and 2. a structured representation (i.e. DataFrame) that we can execute code over.
- We prompt the LLM to return a list. We need the output to be structured so we can iterate over the questions in the answer generation step to generate an answer for every question.
The LLM call is made with the generate_interview_questions method of DataGenerator:
def generate_interview_questions(self, dataset: str) -> InterviewQuestions:
question_generation_user_prompt = QUESTION_GENERATION_USER_TEMPLATE.format(dataset=dataset)
questions = self.llm_manager.call_llm(
system_prompt=SYSTEM_TEMPLATE,
user_prompt=question_generation_user_prompt,
temperature=0
)
try:
questions_list = literal_eval(questions)
except Exception as e:
raise ValueError(f"Error in converting LLM questions output to list: {e}")
questions_structured = InterviewQuestions(
question_1=questions_list[0],
question_2=questions_list[1],
question_3=questions_list[2]
)
return questions_structured
Answer generation
With both the dataset and the questions available, we finally generate the answers with the following prompt:
ANSWER_GENERATION_USER_TEMPLATE = """Generate an answer to the following data analysis interview Question based on the Dataset.
Dataset:
{dataset}
Question: {question}
The answer should be executable Pandas Python code where df refers to the Dataset above.
Always start your answer with a comment explaining what the following code does.
DO NOT DEFINE df IN YOUR RESPONSE.
Answer: """
- We make as many answer generation LLM calls as there are questions, so 3 since we hard coded the question generation prompt to ask for 3 questions. Technically you could ask a LLM to generate all 3 answers for all 3 questions in 1 call but I suspect that performance would worsen. We want the maximize the ability of the LLM to generate accurate answers. A (perhaps obvious) rule of thumb is that the harder the task given to a LLM, the less likely the LLM will perform it well.
- The prompt instructs the LLM to refer to the dataset as “df” because our interview dataset in DataFrame form is called “df” when the user code is executed by the CodeExecutor class below.
class CodeExecutor():
def execute_code(self, df: pd.DataFrame, input_code: str):
local_vars = {'df': df}
code_prefix = """import pandas as pdnresult = """
try:
exec(code_prefix + input_code, {}, local_vars)
except Exception as e:
return f"Error in code execution: {e}nCompiled code: {code_prefix + input_code}"
execution_result = local_vars.get('result', None)
if isinstance(execution_result, pd.DataFrame):
return execution_result.to_html()
return execution_result
Conclusion
I hope this article sheds light on how to build a simple and useful LLM project which utilizes LLMs in a variety of ways!
If I continued to develop this project, I would focus on:
- Adding more validation on structured output from LLMs (i.e. parseable csv or lists). I already covered a couple of edge cases but LLMs are very unpredictable so this needs hardening.
2. Adding more features like
- Generating multiple relational tables and questions requiring joins
- SQL interviews in addition to Python
- Custom dataset upload
- Difficulty setting
How to practice data analyst interviews with AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to practice data analyst interviews with AI
Go Here to Read this Fast! How to practice data analyst interviews with AI