

An intro to an especially sneaky bias that invades many regression models
From 2000 to 2013, a flood of research showed a striking correlation between the rate of risky behavior among adolescents, and how often they ate meals with their family.
Study after study seemed to reach the same conclusion:
The greater the number of meals per week that adolescents had with their family, the lower their odds of indulging in substance abuse, violence, delinquency, vandalism, and many other problem behaviors.
A higher frequency of family meals also correlated with reduced stress, reduced incidence of childhood depression, and reduced frequency of suicidal thoughts. Eating together correlated with increased self-esteem, and a generally increased emotional well-being among adolescents.
Soon, the media got wind of these results, and they were packaged and distributed as easy-to-consume sound bites, such as this one:
“Studies show that the more often families eat together, the less likely kids are to smoke, drink, do drugs, get depressed, develop eating disorders and consider suicide, and the more likely they are to do well in school, delay having sex, eat their vegetables, learn big words and know which fork to use.” — TIME Magazine, “The magic of the family meal”, June 4, 2006
One of the largest studies on the topic was conducted in 2012 by the National Center on Addiction and Substance Abuse (CASA) at Columbia University. CASA surveyed 1003 American teenagers aged 12 to 17 about various aspects of their lives.
CASA discovered the same, and in some cases, startlingly clear correlations between the number of meals adolescents had with their family and a broad range of behavioral and emotional parameters.
There was no escaping the conclusion.
Family meals make well-adjusted teens.
Until you read what is literally the last sentence in CASA’s 2012 white paper:
“Because this is a cross-sectional survey, the data cannot be used to establish causality or measure the direction of the relationships that are observed between pairs of variables in the White Paper.”
And so here we come to a few salient points.
Frequency of family meals may not be the only driver of the reduction in risky behaviors among adolescents. It may not even be the primary driver.
Families who eat together more frequently may do so simply because they already share a comfortable relationship and have good communication with one another.
Eating together may even be the effect of a healthy, well-functioning family.
And children from such families may simply be less likely to indulge in risky behaviors and more likely to enjoy better mental health.
Several other factors are also at play. Factors such as demography, the child’s personality, and the presence of the right role models at home, school, or elsewhere might make children less susceptible to risky behaviors and poor mental health.
Clearly, the truth, as is often the case, is murky and multivariate.
Although, make no mistake, ‘Eat together’ is not bad advice, as advice goes. The trouble with it is the following:
Most of the studies on this topic, including the CASA study, as well as a particularly thorough meta-analysis published by Goldfarb et al in 2013 of 14 other studies, did in fact carefully measure and tease out the partial effects of exactly all of these factors on adolescent risky behavior.
So what did the researchers find?
They found that the partial effect of the frequency of family meals on the observed rate of risky behaviors in adolescents was considerably diluted when other factors such as demography, personality, and nature of relationship with the family were included in the regression models. The researchers also found that in some cases, the partial effect of frequency of family meals, completely disappeared.
Here, for example, is a finding from Goldfarb et al (2013) (FFM=Frequency of Family Meals):
“The associations between FFM and the outcome in question were most likely to be statistically significant with unadjusted models or univariate analyses. Associations were less likely to be significant in models that controlled for demographic and family characteristics or family/parental connectedness. When methods like propensity score matching were used, no significant associations were found between FFM and alcohol or tobacco use. When methods to control for time-invariant individual characteristics were used, the associations were significant about half the time for substance use, five of 16 times for violence/delinquency, and two of two times for depression/suicide ideation.”
Wait, but what does all this have to do with bias?
The connection to omitted variable bias
The relevance to bias comes from two unfortunately co-existing properties of the frequency of family meals variable:
- On one hand, most studies on the topic found that the frequency of family meals does have an intrinsic partial effect on the susceptibility to risky behavior. But, the effect is weak when you factor in other variables.
- At the same time, the frequency of family meals is also heavily correlated with several other variables, such as the nature of inter-personal relationships with other family members, the nature of communication within the family, the presence of role models, the personality of the child, and demographics such as household income. All of these variables, it was found, have a strong joint correlation with the rate of indulgence in risky behaviors.
The way the math works is that if you unwittingly omit even a single one of these other variables from your regression model, the coefficient of the frequency of family meals gets biased in the negative direction. In the next two sections, I’ll show exactly why that happens.
This negative bias on the coefficient of frequency of family meals will make it appear that simply increasing the number of times families sit together to eat ought to, by itself, considerably reduce the incidence of — oh, say — alcohol abuse among adolescents.
The above phenomenon is called Omitted Variable Bias. It’s one of the most frequently occurring, and easily missed, biases in regression studies. If not spotted and accounted for, it can lead to unfortunate real-world consequences.
For example, any social policy that disproportionately stresses the need for increasing the number of times families eat together as a major means to reduce childhood substance abuse will inevitably miss its design goal.
Now, you might ask, isn’t much of this problem caused by selecting explanatory variables that correlate with each other so strongly? Isn’t it just an example of a sloppily conducted variable-selection exercise? Why not select variables that are correlated only with the response variable?
After all, shouldn’t a skilled statistician be able to employ their ample training and imagination to identify a set of factors that have no more than a passing correlation with one another and that are likely to be strong determinants of the response variable?
Sadly, in any real-world setting, finding a set of explanatory variables that are only slightly (or not at all) correlated is the stuff of dreams, if even that.
But to paraphrase G. B. Shaw, if your imagination is full of ‘fairy princesses and noble natures and fearless cavalry charges’, you might just come across a complete set of perfectly orthogonal explanatory variables, as statisticians like to so evocatively call them. But again, I will bet you the Brooklyn Bridge that even in your sweetest statistical dreamscapes, you will not find them. You are more likely to stumble into the non-conforming Loukas and the reality-embracing Captain Bluntschlis instead of greeting the quixotic Rainas and the Major Saranoffs.

{kind=link}
And so, we must learn to live in a world where explanatory variables freely correlate with one another, while at the same time influencing the response of the model to varying degrees.
In our world, omitting one of these variable s— either by accident, or by the innocent ignorance of its existence, or by the lack of means to measure it, or through sheer carelessness — causes the model to be biased. We might as well develop a better appreciation of this bias.
In the rest of this article, I’ll explore Omitted Variable Bias in great detail. Specifically, I’ll cover the following:
- Definition and properties of omitted variable bias.
- Formula for estimating the omitted variable bias.
- An analysis of the omitted variable bias in a model of adolescent risky behavior.
- A demo and calculation of omitted variable bias in a regression model trained on a real-world dataset.
Definition and properties of omitted variable bias
From a statistical perspective, omitted variable bias is defined as follows:
When an important explanatory variable is omitted from a regression model and the truncated model is fitted on a dataset, the expected values of the estimated coefficients of the non-omitted variables in the fitted model shift away from their true population values. This shift is called omitted variable bias.
Even when a single important variable is omitted, the expected values of the coefficients of all the non-omitted explanatory variables in the model become biased. No variable is spared from the bias.
Magnitude of the bias
In linear models, the magnitude of the bias depends on the following three quantities:
- Covariance of the non-omitted variable with the omitted variable: The bias on a non-omitted variable’s estimated coefficient is directly proportional to the covariance of the non-omitted variable with the omitted variable, conditioned upon the rest of the variables in the model. In other words, the more tightly correlated the omitted variable is with the variables that are left behind, the heavier the price you pay for omitting it.
- Coefficient of the omitted variable: The bias on a non-omitted variable’s estimated coefficient is directly proportional to the population value of the coefficient of the omitted variable in the full model. The greater the influence of the omitted variable on the model’s response, the bigger the hole you dig for yourself by omitting it.
- Variance of the non-omitted variable: The bias on a non-omitted variable’s estimated coefficient is inversely proportional to the variance of the non-omitted variable, conditioned upon the rest of the variables in the model. The more scattered the non-omitted variable’s values are around its mean, the less affected it is by the bias. This is yet another place in which the well-known effect of bias-variance tradeoff makes its presence felt.
Direction of the bias
In most cases, the direction of omitted variable bias on the estimated coefficient of a non-omitted variable, is unfortunately hard to judge. Whether the bias will boost or attenuate the estimate is hard to tell without actually knowing the omitted variable’s coefficient in the full model, and working out the conditional covariance and conditional variance of non-omitted variable.
Formula for omitted variable bias
In this section, I’ll present the formula for Omitted Variable Bias that is applicable to coefficients of only linear models. But the general concepts and principles of how the bias works, and the factors it depends on carry over smoothly to various other kinds of models.
Consider the following linear model which regresses y on x_1 through x_m and a constant:
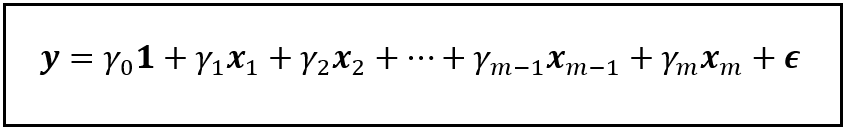
In this model, γ_1 through γ_m are the population values of the coefficients of x_1 through x_m respectively, and γ_0 is the intercept (a.k.a. the regression constant). ϵ is the regression error. It captures the variance in y that x_1 through x_m and γ_0 are jointly unable to explain.
As a side note, y, x_1 through x_m, 1, and ϵ are all column vectors of size n x 1, meaning they each contain n rows and 1 column, with ‘n’ being the number of samples in the dataset on which the model operates.
Lest you get ready to take flight and flee, let me assure you that beyond mentioning the above fact, I will not go any further into matrix algebra in this article. But you have to let me say the following: if it helps, I find it useful to imagine an n x 1 column vector as a vertical cabinet with (n — 1) internal shelves and a number sitting on each shelf.
Anyway.
Now, let’s omit the variable x_m from this model. After omitting x_m, the truncated model looks like this:
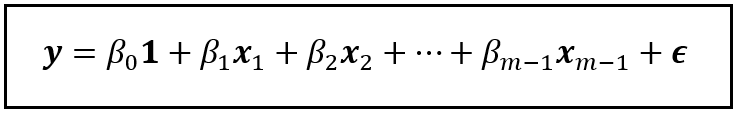
In the above truncated model, I’ve replaced all the gammas with betas to remind us that after dropping x_m, the coefficients of the truncated model will be decidedly different than in the full model.
The question is, how different are the betas from the gammas? Let’s find out.
If you fit (train) the truncated model on the training data, you will get a fitted model. Let’s represent the fitted model as follows:
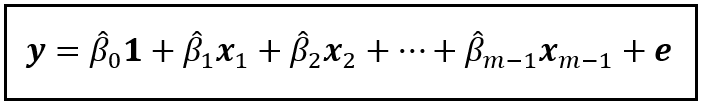
In the fitted model, the β_0_cap through β_(m — 1)_cap are the fitted (estimated) values of the coefficients β_0 through β_(m — 1). ‘e’ is the residual error, which captures the variance in the observed values of y that the fitted model is unable to explain.
The theory says that the omission of x_m has biased the expected value of every single coefficient from β_0_cap through β_(m — 1)_cap away from their true population values γ_1 through γ_(m — 1).
Let’s examine the bias on the estimated coefficient β_k_cap of the kth regression variable, x_k.
The amount by which the expected value of β_k_cap in the truncated fitted model is biased is given by the following equation:
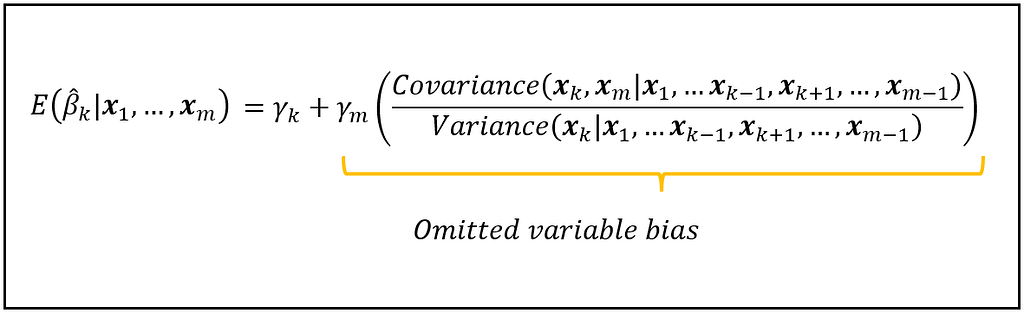
Let’s note all of the following things about the above equation:
- β_k_cap is the estimated coefficient of the non-omitted variable x_k in the truncated model. You get this estimate of β_k from fitting the truncated model on the data.
- E( β_k_cap | x_1 through x_m) is the expected value of the above mentioned estimate, conditioned on all the observed values of x_1 through x_m. Note that x_m is actually not observed. We’ve omitted it, remember? Anyway, the expectation operator E() has the following meaning: if you train the truncated model on thousands of randomly drawn datasets, you will get thousands of different estimates of β_k_cap. E(β_k_cap) is the mean of all these estimates.
- γ_k is the true population value of the coefficient of x_k in the full model.
- γ_m is the true population value of the coefficient of the variable x_m that was omitted from the full model.
- The covariance term in the above equation represents the covariance of x_k with x_m, conditioned on the rest of the variables in the full model.
- Similarly, the variance term represents the variance of x_k conditioned on all the other variables in the full model.
The above equation tells us the following:
- First and foremost, had x_m not been omitted, the expected value of β_k_cap in the fitted truncated model would have been γ_k. This is a property of all linear models fitted using the OLS technique: the expected value of each estimated coefficient in the fitted model is the unbiased population value of the respective coefficient.
- However, due to the missing x_m in the truncated model, the expected value β_k_cap has become biased away from its population value, γ_k.
- The amount of bias is the ratio of, the conditional covariance of x_k with x_m, and the conditional variance of x_k, scaled by γ_m.
The above formula for the omitted variable bias should give you a first glimpse of the appalling carnage wreaked on your regression model, should you unwittingly omit even a single explanatory variable that happens to be not only highly influential but also heavily correlated with one or more non-omitted variables in the model.
As we’ll see in the following section, that is, regrettably, just what happens in a specific kind of flawed model for estimating the rate of risky behaviour in adolescents.
An analysis of the omitted variable bias in a model of adolescent risky behavior
Let’s apply the formula for the omitted variable bias to a model that tries to explain the rate of risky behavior in adolescents. We’ll examine a scenario in which one of the regression variables is omitted.
But first, we’ll look at the full (non-omitted) version of the model. Specifically, let’s consider a linear model in which the rate of risky behavior is regressed on the suitably quantified versions of the following four factors:
- frequency of family meals
- how well-informed a child thinks their parents are about what’s going on in their life,
- the quality of the relationship between parent and child, and
- the child’s intrinsic personality.
For simplicity, we’ll use the variables x_1, x_2, x_3 and x_4 to represent the above four regression variables.
Let y represent the response variable, namely, the rate of risky behaviors.
The linear model is as follows:
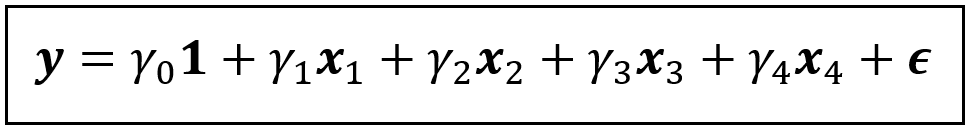
We’ll study the biasing effect of omitting x_2(=how well-informed a child thinks their parents are about what’s going on in their life) on the coefficient of x_1(=frequency of family meals).
If x_2 is omitted from the above linear model, and the truncated model is fitted, the fitted model looks like this:
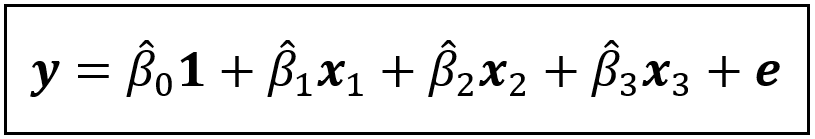
In the fitted model, β_1_cap is the estimated coefficient of the frequency of family meals. Thus, β_1_cap quantifies the partial effect of frequency of family meals on the rate of risky behavior in adolescents.
Using the formula for the omitted variable bias, we can state the expected value of the partial effect of x_1 as follows:

Studies have shown that frequency of family meals (x_1) happens to be heavily correlated with how well-informed a child thinks their parents are about what’s going on in their life (x_2). Now look at the covariance in the numerator of the bias term. Since x_1 is highly correlated with x_2, the large covariance makes the numerator large.
If that weren’t enough, the same studies have shown that x_2 (=how well-informed a child thinks their parents are about what’s going on in their life) is itself heavily correlated (inversely) with the rate of risky behavior that the child indulges in (y). Therefore, we’d expect the coefficient γ_2 in the full model to be large and negative.
The large covariance and the large negative γ_2 join forces to make the bias term large and negative. It’s easy to see how such a large negative bias will drive down the expected value of β_1_cap deep into negative territory.
It is this large negative bias that will make it seem like the frequency of family meals has an outsized partial effect on explaining the rate of risky behavior in adolescents.
All of this bias occurs by the inadvertent omission of a single highly influential variable.
A real-world demo of omitted variable bias
Until now, I’ve relied on equations and formulae to provide a descriptive demonstration of how omitting an important variable biases a regression model.
In this section, I’ll show you the bias in action on real world data.
For illustration, I’ll use the following dataset of automobiles published by UC Irvine.

Each row in the dataset contains 26 different features of a unique vehicle. The characteristics include make, number of doors, engine features such as fuel type, number of cylinders, and engine aspiration, physical dimensions of the vehicle such as length, breath, height, and wheel base, and the vehicle’s fuel efficiency on city and highway roads.
There are 205 unique vehicles in this dataset.
Our goal is to build a linear model for estimating the fuel efficiency of a vehicle in the city.
Out of the 26 variables covered by the data, only two variables — curb weight and horsepower — happen to be the most potent determiners of fuel efficiency. Why these two in particular? Because, out of the 25 potential regression variables in the dataset, only curb weight and horsepower have statistically significant partial correlations with fuel efficiency. If you are curious how I went about the process of identifying these variables, take a look at my article on the partial correlation coefficient.
A linear model of fuel efficiency (in the city) regressed on curb weight and horsepower is as follows:
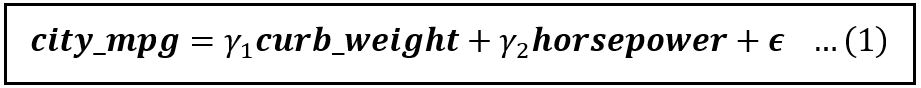
Notice that the above model has no intercept. That is so because when either one of curb weight and horsepower is zero, the other one has to be zero. And you will agree that it will be quite unusual to come across a vehicle with zero weight and horsepower but somehow sporting a positive mileage.
So next, we’ll filter out the rows in the dataset containing missing data. And from the remaining data, we’ll carve out two randomly selected datasets for training and testing the model in a 80:20 ratio. After doing this, the training data happens to contain 127 vehicles.
If you were to train the model in equation (1) on the training data using Ordinary Least Squares, you’ll get the estimates γ_1_cap and γ_2_cap for the coefficients γ_1 and γ_2.
At the end of this article, you’ll find the link to the Python code for doing this training plus all other code used in this article.
Meanwhile, following is the equation of the trained model:

Now suppose you were to omit the variable horsepower from the model. The truncated model looks like this:
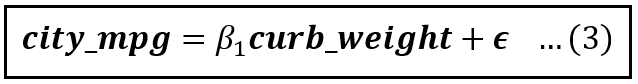
If you were to train the model in equation (3) on the training data using OLS, you will get the following estimate for β_1:
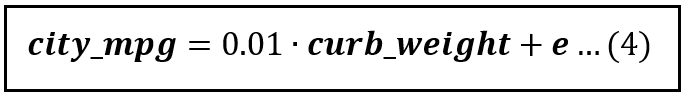
Thus, β_1_cap is 0.01. This is different than the 0.0193 in the full model.
Because of the omitted variable, the expected value of β_1_cap has gotten biased as follows:
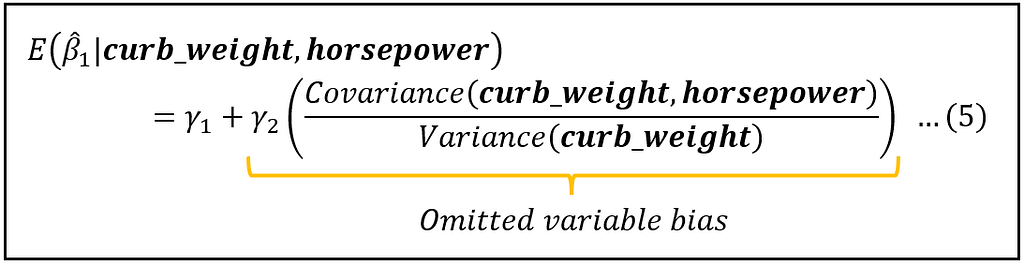
As mentioned earlier, in a non-biased linear model fitted using OLS, the expected value of β_1_cap will be the population value of β_1_cap which is γ_1. Thus, in a non-biased model:
E(β_1_cap) = γ_1
But the omission of horsepower has biased this expectation as shown in equation (5).
To calculate the bias, you need to know three quantities:
- γ_2: This is the population value of the coefficient of horsepower in the full model shown in equation (1).
- Covariance(curb_weight, horsepower): This is the population value of the covariance.
- Variance(curb_weight): This is the population value of the variance.
Unfortunately, none of the three values are computable because the overall population of all vehicles is inaccessible to you. All you have is a sample of 127 vehicles.
In practice though, you can estimate this bias by substituting sample values for the population values.
Thus, in place of γ_2, you can use γ_2_cap= — 0.2398 from equation (2).
Similarly, using the training data of 127 vehicles as the data sample, you can calculate the sample covariance of curb_weight and horsepower, and the sample variance of curb_weight.
The sample covariance comes out to be 11392.85. The sample variance of curb_weight comes out to be 232638.78.
With these values, the bias term in equation (5) can be estimated as follows:

Getting a feel for the impact of the omitted variable bias
To get a sense of how strong this bias is, let’s return to the fitted full model:
In the above model, γ_1_cap = 0.0193. Our calculation shows that the bias on the estimated value of γ_1 is 0.01174 in the negative direction. The magnitude of this bias (0.01174) is 0.01174/0.0193*100 = 60.93 , in other words an alarming 60.83% of the estimated value of γ_1.
There is no gentle way to say this: Omitting the highly influential variable horsepower has wreaked havoc on your simple linear regression model.
Omitting horsepower has precipitously attenuated the expected value of the estimated coefficient of the non-omitted variable curb_weight. Using equation (5), you will be able to approximate the attenuated value of this coefficient as follows:
E(β_1_cap | curb_weight, horsepower)
= γ_1_cap + bias = 0.0193—0.01174 = 0.00756
Remember once again that you are working with estimates instead of the actual values of γ_1 and bias.
Nevertheless, the estimated attenuated value of γ_1_cap (0.00756) matches closely with the estimate of 0.01 returned by fitting the truncated model of city_mpg (equation 4) on the training data. I’ve reproduced it below.
Python Code
Here are the links to the Python code and the data used for building and training the full and the truncated models and for calculating the Omitted Variable Bias on E(β_1_cap).
Link to the automobile dataset.
By the way, each time you run the code, it will pull a randomly selected set of training data from the overall autos dataset. Training the full and truncated models on this training data will lead to slightly different estimated coefficient values. Therefore, each time you run the code, the bias on E(β_1_cap) will also be slightly different. In fact, this illustrates rather nicely why the estimated coefficients are themselves random variables and why they have their own estimated values.
Summary
Let’s summarize what we learned.
- Omitted variable bias is caused when one or more important variables are omitted from a regression model.
- The bias affects the expected values of the estimated coefficients of all non-omitted variables. The bias causes the expected values to become either bigger or smaller from their true population values.
- Omitted variable bias will make the non-omitted variables look either more important or less important than what they actually are in terms of their influence on the response variable of the regression model.
- The magnitude of the bias on each non-omitted variable is directly proportional to how correlated is the non-omitted variable with the omitted variable(s), and also how influential is/are the omitted variables on the the response variable of the model. The bias is inversely proportional to how dispersed is the non-omitted variable.
- In most real-world cases, the direction of the bias is hard to judge without computing it.
References and Copyrights
Articles and Papers
Eisenberg, M., E., Olson, R. E., Neumark-Sztainer, D., Story. M., Bearinger L. H.: “Correlations Between Family Meals and Psychosocial Well-being Among Adolescents”, Archives of pediatrics & adolescent medicine, Vol. 158, No. 8, pp 792–796 (2004), doi:10.1001/archpedi.158.8.792, Full Text
Fulkerson, J., A., Story, M., Mellin, A., Leffert, N., Neumark-Sztainer D., French, S., A.: “Family dinner meal frequency and adolescent development: relationships with developmental assets and high-risk behaviors”, Journal of Adolescent Health, Vol. 39, No. 3, pp 337–345, (2006), doi:10.1016/j.jadohealth.2005.12.026, PDF
Sen, B.: “The relationship between frequency of family dinner and adolescent problem behaviors after adjusting for other family characteristics”, Journal of Adolescent Health, Vol. 33, No. 1, pp 187–196, (2010), PDF
Musick, K., Meier, A.: “Assessing causality and persistence in associations between family dinners and adolescent well-being”, Wiley Journal of Marriage and Family, Vol. 74, No. 3, pp 476–493 (2012), doi:10.1111/j.1741–3737.2012.00973.x, PMID: 23794750; PMCID: PMC3686529, PDF
Hoffmann, J., P., Warnick, E.: “Do family dinners reduce the risk for early adolescent substance use? A propensity score analysis”, Journal of Health and Social Behavior, Vol. 54, No. 3, pp 335–352, (2013), doi:10.1177/0022146513497035
Goldfarb, S., Tarver, W., Sen, B.: “Family structure and risk behaviors: the role of the family meal in assessing likelihood of adolescent risk behaviors”, Psychology Research and Behavior Management, Vol. 7, pp 53–66, (2014), doi:10.2147/PRBM.S40461, Full Text
Gibbs, N.: “The Magic of the Family Meal”, TIME, (June 4, 2006), Full Text
National Center on Addiction and Substance Abuse (CASA): “The Importance of Family Dinners VIII”, CASA at Columbia University White Paper, (September 2012), Archived, Original (not available) Website
Miech, R. A., Johnston, L. D., Patrick, M. E., O’Malley, P. M., Bachman, J. G. “Monitoring the Future national survey results on drug use, 1975–2023: Secondary school students”, Monitoring the Future Monograph Series, Ann Arbor, MI: Institute for Social Research, University of Michigan, (2023), Available at https://monitoringthefuture.org/results/annual-reports/
Dataset
Schlimmer, J.: “Automobile”, UCI Machine Learning Repository, (1987), doi:10.24432/C5B01C, Download
Images
All images in this article are copyright Sachin Date under CC-BY-NC-SA, unless a different source and copyright are mentioned underneath the image.
Thanks for reading! If you liked this article, follow me to receive content on statistics and statistical modeling.
Omitted Variable Bias was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Omitted Variable Bias