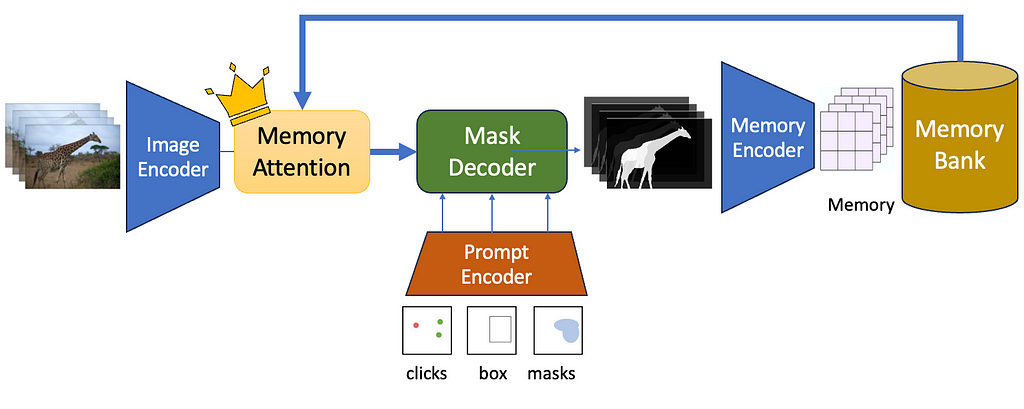
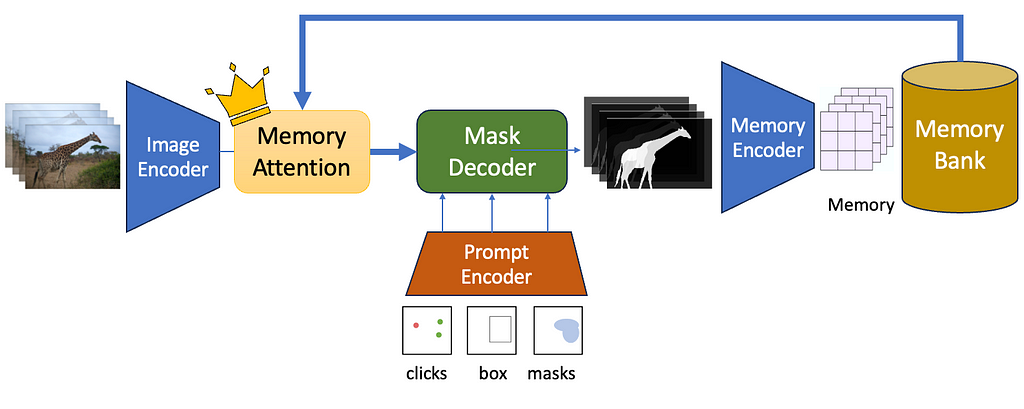
Foundation + Promptable + Interactive + Video. How?
Meta just released the Segment Anything 2 model or SAM 2 — a neural network that can segment not just images, but entire videos as well. SAM 2 is a promptable interactive foundation segmentation model. Being promptable means you can click or drag bounding boxes on one or more objects you want to segment, and SAM2 will be able to predict a mask singling out the object and track it across the input clip. Being interactive means you can edit the prompts on the fly, like adding new prompts in different frames — and the segments will adjust accordingly! Lastly, being a foundation segmentation model means that it is trained on a massive corpus of data and can be applied for a large variety of use-cases.
Note that this article is a “Deep Learning Guide”, so we will primarily be focusing on the network architecture behind SAM-2. If you are a visual learner, you might want to check out the YouTube video that this article is based on.
Promptable Visual Segmentation (PVS)
SAM-2 focuses on the PVS or Prompt-able Visual Segmentation task. Given an input video and a user prompt — like point clicks, boxes, or masks — the network must predict a masklet, which is another term for a spatio-temporal mask. Once a masklet is predicted, it can be iteratively refined by providing more prompts in additional frames — through positive or negative clicks — to interactively update the segmented mask.
The Original Segment Anything Model
SAM-2 builds up on the original SAM architecture which was an image segmentation model. Let’s do a quick recap about the basic architecture of the original SAM model.
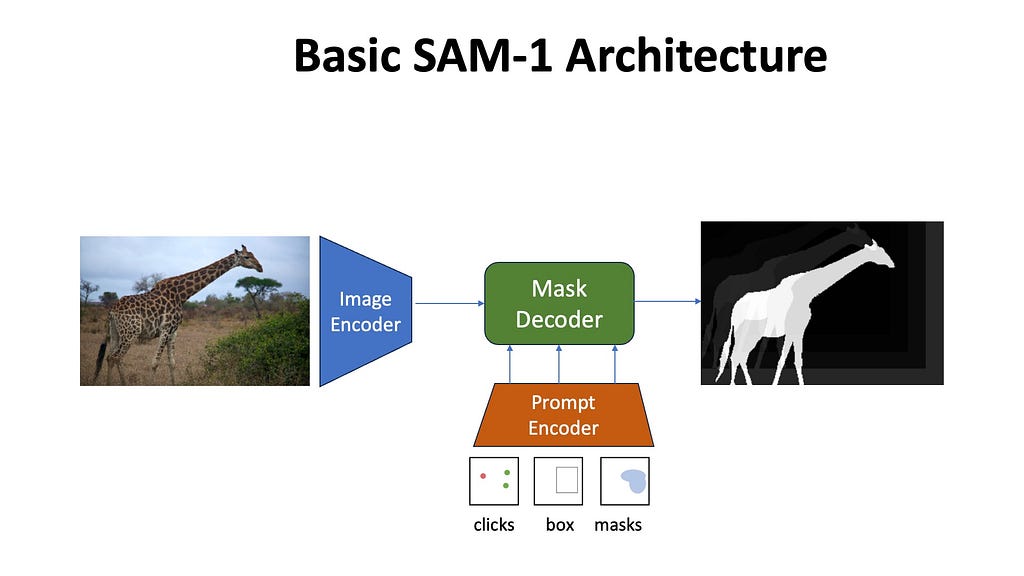
- The Image Encoder processes the input image to create general image embeddings. These embeddings are unconditional on the prompts.
- The Prompt Encoder processes the user input prompts to create prompt embeddings. Prompt embeddings are unconditional on the input image.
- The Mask Decoder inputs the unconditional image and prompt embeddings and applies cross-attention and self-attention blocks to contextualize them with each other. From the resulting contextual embeddings, multiple segmentation masks are generated
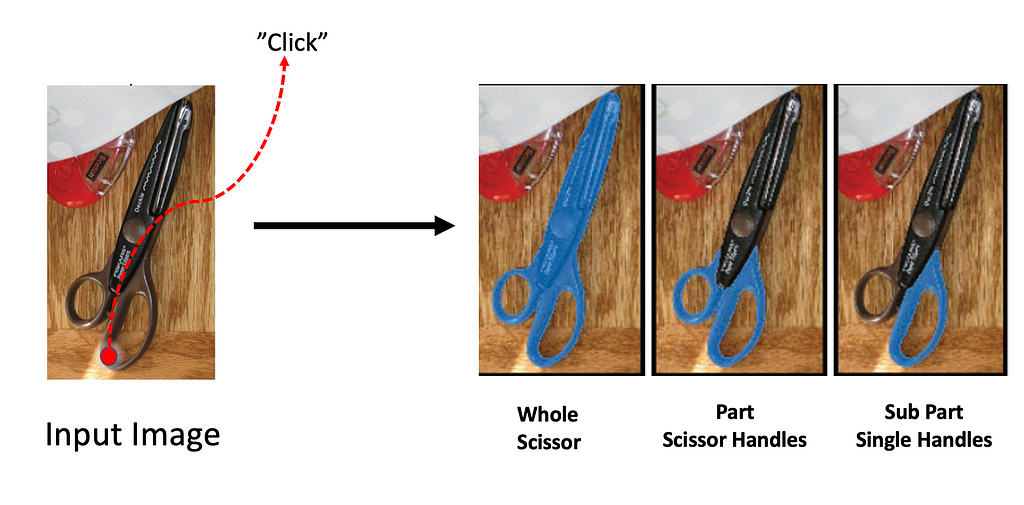
- Multiple Output Segmentation Masks are predicted by the Mask Decoder. These masks often represent the whole, part, or subpart of the queried object and help resolve ambiguity that might arise due to user prompts (image below).
- Intersection-Over-Union scores are predicted for each output segmentation mask. These IoU scores denote the confidence score SAM has for each predicted mask to be “correct”. Meaning if SAM predicts a high IoU score for Mask 1, then Mask 1 is probably the right mask.
So what does SAM-2 does differently to adopt the above architecture for videos? Let’s discuss.
Frame Encoder
The input video is first divided into multiple frames, and each of the frames is independently encoded using a Vision Transformer-based Masked Auto-encoder computer vision model, called the Heira architecture. We will worry about the exact architecture of this transformer later, for now just imagine it as a black box that inputs a single frame as an image and outputs a multi-channel feature map of shape 256x64x64. All the frames of the video are similarly processed using the encoder.
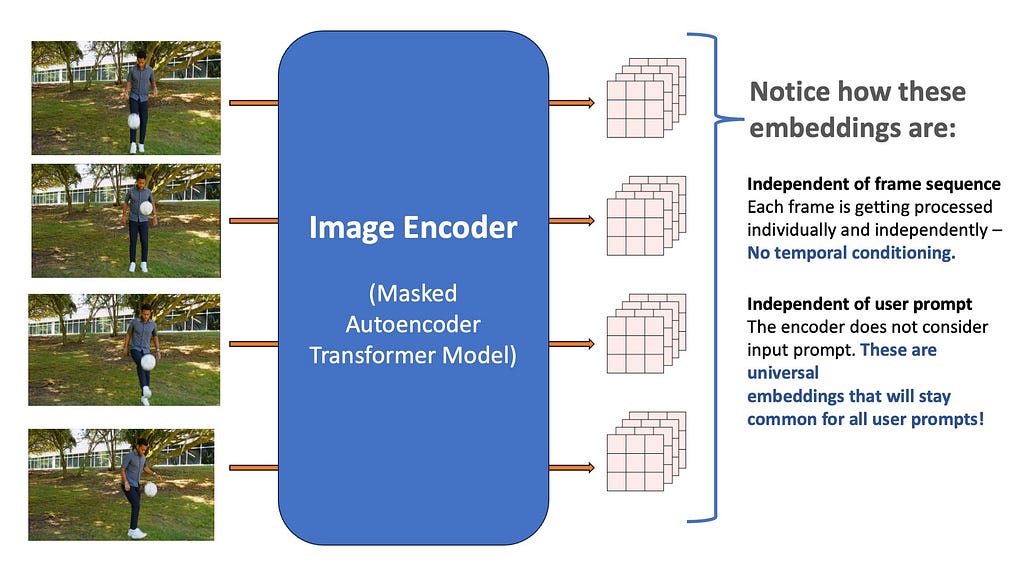
Notice that these embeddings do not consider the video sequence — they are just independent frame embeddings, meaning they don’t have access to other frames in the video. Secondly, just like SAM-1 they do not consider the input prompt at all — meaning that the resultant output is treated as a universal representation of the input frame and completely unconditional on the input prompts.
The advantage of this is that if the user adds new prompts in future frames, we do not need to run the frames through the image encoder again. The image encoder runs just once for each frame, and the results are cached and reused for all types of input prompts. This design decision makes SAM-2 run at interactive speeds — because the heavy work of encoding images only needs to happen once per video input.
Quick notes about the Heira Architecture
The exact nature of the Image encoder is an implementation detail — as long as the encoder is good enough and trained on a huge corpus of images it is fine. The Heira architecture is a hierarchical vision transformer, meaning that spatial resolution is reduced and the feature dimensions are increased as the network deepens. These models are trained on the task of Mask Autoencoding where the image inputted into the network is divided into multiple patches and some patches are randomly grayed out — and then the Heira model learns to reconstruct the original image back from the remaining patches that it can see.
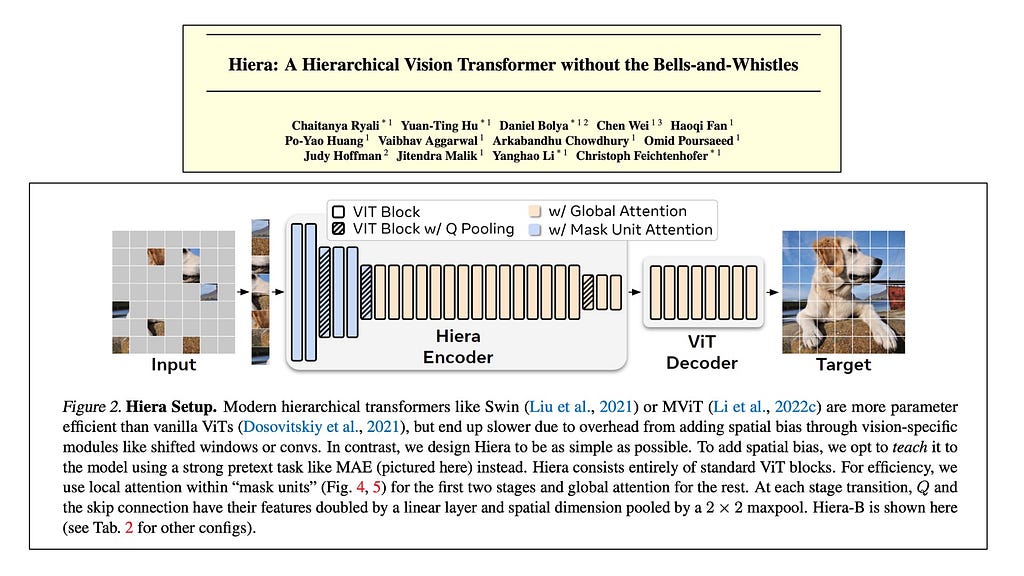
Because mask auto-encoding is self-supervised, meaning all the labels are generated from the source image itself, we can easily train these large encoders on massive image datasets without needing to manually label them. Mask Autoencoders tend to learn general embeddings about images that can be used for a bunch of downstream tasks. It’s general-purpose embedding capabilities make it the choice architecture for SAM’s frame encoder.
Prompt Encoder
Just like the original SAM model, input prompts can come from point clicks, boxes, and segmentation masks. The prompt encoder’s job is to encode these prompts by converting them into a representative vector representation. Here’s a video of the original SAM architecture that goes into the details about how prompt encoders work.
The Prompt Encoder takes converts it into a shape of N_tokens x 256. For example,
- To encode a click — The positional encoding of the x and y coordinate of the click is used as one of the tokens in the prompt sequence. The “type” of click (foreground/positive or background/negative) is also included in the representation.
- To encode a bounding box — The positional encoding for the top-left and bottom-right points is used.

A note on Dense Prompt Encodings
Point clicks and Bounding boxes are sparse prompt encodings, but we can also input entire segmentation masks as well, which is a form of dense prompt encodings. The dense prompt encodings are rarely used during inference — but during training, they are used to iteratively train the SAM model. The training methods of SAM are beyond the scope of this article, but for those curious here is my attempt to explain an entire article in one paragraph.
SAM is trained using iterative segmentation. During training, when SAM outputs a segmentation mask, we input it back into SAM as a dense prompt along with refinement clicks (sparse prompts) simulated from the ground-truth and prediction. The mask decoder uses the sparse and dense prompts and learns to output a new refined segmentation mask. During inference, only sparse prompts are used, and segmentation masks are predicted in one-pass (without feeding back the dense mask.
Maybe one day I’ll write an article about iterative segmentation training, but for now, let’s move on with our exploration of SAM’s network architecture.
Prompt encodings have largely remained the same in SAM-2. The only difference is that they must run separately for all frames that the user prompts.
Mask Decoder (Teaser)
Umm… before we get into mask decoders, let’s talk about the concept of Memory in SAM-2. For now, let’s just assume that the Mask Decoder inputs a bunch of things (trust me we will talk about what these things are in a minute) and outputs segmentation masks.
Memory Encoder and Memory Bank
After the mask decoder generates output masks the output mask is passed through a memory encoder to obtain a memory embedding. A new memory is created after each frame is processed. These memory embeddings are appended to a Memory Bank which is a first-in-first-out (FIFO) queue of the latest memories generated during video decoding.
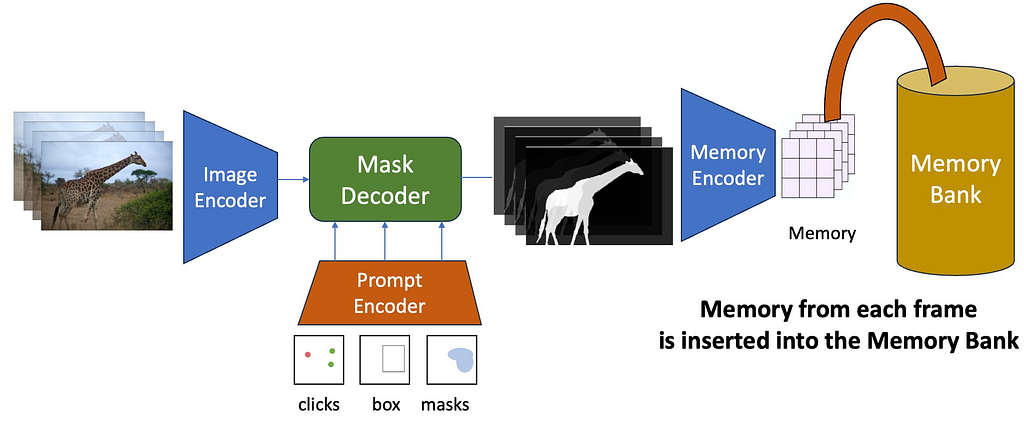
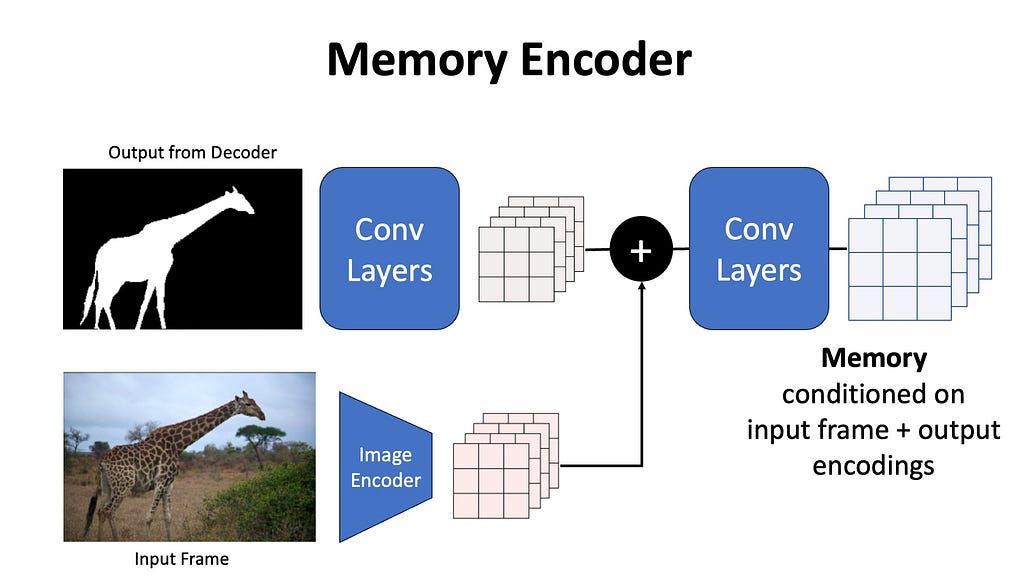
Memory Encoder
The output masks are first downsampled using a convolutional layer, and the unconditional image encoding is added to this output, passed through light-weight convolution layers to fuse the information, and the resulting spatial feature map is called the memory. You can imagine the memory to be a representation of the original input frame and the generated mask from a given time frame in the video.
Memory Bank
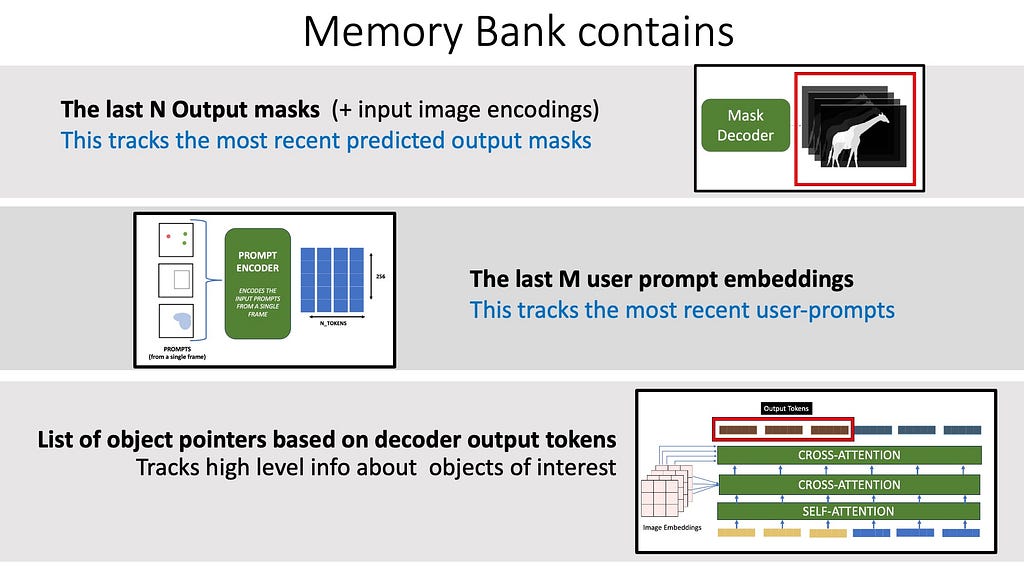
The memory bank contains the following:
- The most recent N memories are stored in a queue
- The last M prompts inputed by the user to keep track of multiple previous prompts.
- The mask decoder output tokens for each frame are also stored — which are like object pointers that capture high-level semantic information about the object to segment.
Memory Attention
We now have a way to save historical information in a Memory Bank. Now we need to use this information while generating segmentation masks for future frames. This is achieved using Memory Attention. The role of memory attention is to condition the current frame features on the Memory Bank features before it is inputted into the Mask Decoder.
The Memory attention block first performs self-attention with the frame embeddings and then performs cross-attention between the image embeddings and the contents of the memory bank. The unconditional image embeddings therefore get contextualized with the previous output masks, previous input prompts, and object pointers.
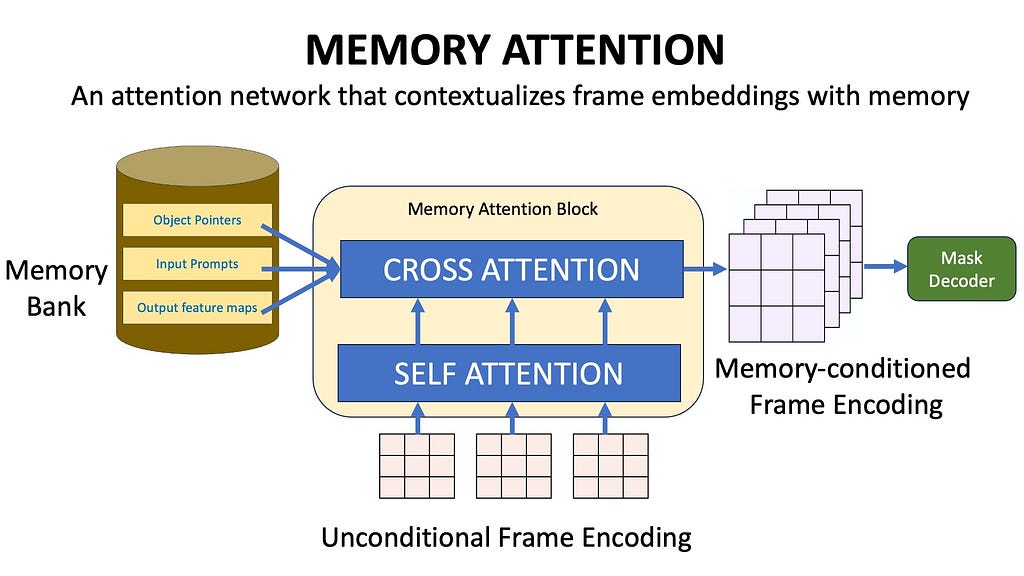
During the self-attention and cross-attention layers, in addition to the usual sinusoidal position embeddings, 2D rotary positional embeddings are also used. Without getting into extra details — rotary positional embeddings allow to capture of relative relationships between the frames, and 2D rotary positional embeddings work well for images because they help to model the spatial relationship between the frames both horizontally and vertically.
Mask Decoder (For real this time)
The Mask Decoder inputs the memory-contextualized image encodings output by the Memory Attention block, plus the prompt encodings and outputs the segmentation masks, IOU scores, and (the brand new) occlusion scores.
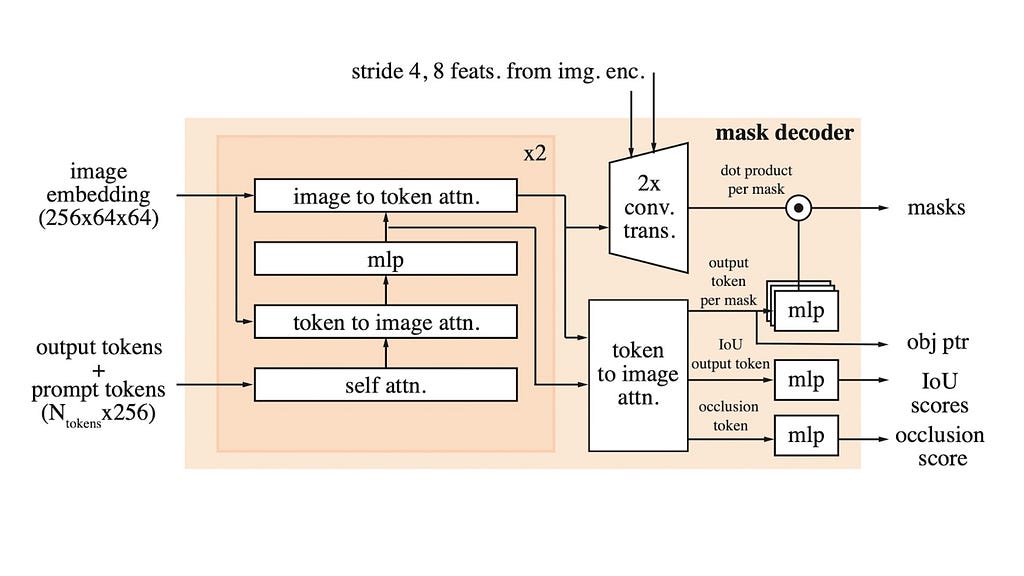
The Mask-Decoder uses self-attention and cross attention mechanisms to contextualize the prompt tokens with the (memory-conditioned) image embeddings. This allows the image and prompts to be “married” together into one context-aware sequence. These embeddings are then used to produce segmentation masks, IOU scores, and the occlusion score. Basically, during the video, the queried object can get occluded because it got blocked by another object in the scene — the occlusion score predicts if the queried object is present in the current frame. The occlusion scores are a new addition to SAM-2 which predicts if the queried object is at-all present in the current scene or not.
To recap, just like the IOU scores, SAM generates an occlusion score for each of the three predicted masks. The three IOU scores tell us how confident SAM is for each of the three predicted masks — and the three occlusion scores tell us how likely SAM thinks that the corresponding object is present in the scene.

Final Thoughts
So… that was an outline of the network architecture behind SAM-2. For the extracted frames from a video (often at 6 FPS), the frames are encoded using the Frame/Image encoder, memory attention contextualizes the image encodings, prompts are encoded if present, the Mask Decoder then combines the image and prompt embeddings, produces output masks, IOU scores, and occlusion scores, Memory is generated using memory encoder, appended into the memory bank, and the whole process repeats.

There are still many things to discuss about SAM-2 like how it trains interactively to be a promptable model, and how their data engine works to create training data. I hope to cover these topics in a separate article! You can watch the SAM-2 video on my YouTube channel above for more information and a visual tour of the systems that empower SAM-2.
Thanks for reading! Throw a clap and a follow!
References / Where to go next
- Author’s Youtube Channel
- My video explanation of SAM
- My video explanation of SAM-2
- You can play with the Segment Anything 2 Model on Meta’s website.
- OG SAM Paper
- SAM-2 Paper
Segment Anything 2: What Is the Secret Sauce? (A Deep Learner’s Guide) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Segment Anything 2: What Is the Secret Sauce? (A Deep Learner’s Guide)
Go Here to Read this Fast! Segment Anything 2: What Is the Secret Sauce? (A Deep Learner’s Guide)