A simple tutorial to get you started on asynchronous ML inference

Most machine learning serving tutorials focus on real-time synchronous serving, which allows for immediate responses to prediction requests. However, this approach can struggle with surges in traffic and is not ideal for long-running tasks. It also requires more powerful machines to respond quickly, and if the client or server fails, the prediction result is usually lost.
In this blog post, we will demonstrate how to run a machine learning model as an asynchronous worker using Celery and Redis. We will be using the Florence 2 base model, a Vision language model known for its impressive performance. This tutorial will provide a minimal yet functional example that you can adapt and extend for your own use cases.
The core of our solution is based on Celery, a Python library that implements this client/worker logic for us. It allows us to distribute the compute work across many workers, improving the scalability of your ML inference use case to high and unpredictable loads.
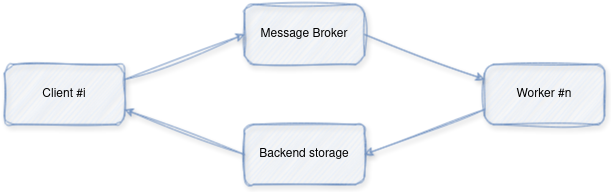
The process works as follows:
- The client submits a task with some parameters to a queue managed by the broker (Redis in our example).
- A worker (or multiple ones) continuously monitors the queue and picks up tasks as they come. It then executes them and saves the result in the backend storage.
- The client is able to fetch the result of the task using its id either by polling the backend or by subscribing to the task’s channel.
Let’s start with a simplified example:
First, run Redis:
docker run -p 6379:6379 redis
Here is the worker code:
from celery import Celery
# Configure Celery to use Redis as the broker and backend
app = Celery(
"tasks", broker="redis://localhost:6379/0", backend="redis://localhost:6379/0"
)
# Define a simple task
@app.task
def add(x, y):
return x + y
if __name__ == "__main__":
app.worker_main(["worker", "--loglevel=info"])
And the client code:
from celery import Celery
app = Celery("tasks", broker="redis://localhost:6379/0", backend="redis://localhost:6379/0")
print(f"{app.control.inspect().active()=}")
task_name = "tasks.add"
add = app.signature(task_name)
print("Gotten Task")
# Send a task to the worker
result = add.delay(4, 6)
print("Waiting for Task")
result.wait()
# Get the result
print(f"Result: {result.result}")
This gives the result that we expect: “Result: 10”
Now, let’s move on to the real use case: Serving Florence 2.
We will build a multi-container image captioning application that uses Redis for task queuing, Celery for task distribution, and a local volume or Google Cloud Storage for potential image storage. The application is designed with few core components: model inference, task distribution, client interaction and file storage.
Architecture Overview:
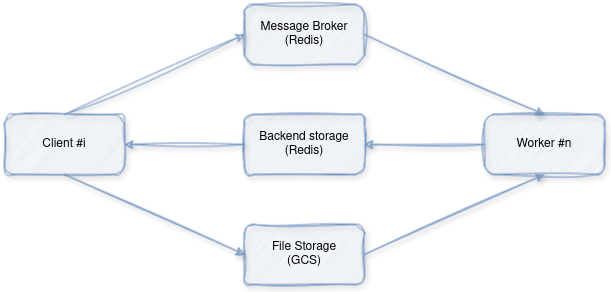
- Client: Initiates image captioning requests by sending them to the worker (through the broker).
- Worker: Receives requests, downloads images, performs inference using the pre-trained model, and returns results.
- Redis: Acts as a message broker facilitating communication between the client and worker.
- File Storage: Temporary storage for image files
Component Breakdown:
1. Model Inference (model.py):
- Dependencies & Initialization:
import os
from io import BytesIO
import requests
from google.cloud import storage
from loguru import logger
from modeling_florence2 import Florence2ForConditionalGeneration
from PIL import Image
from processing_florence2 import Florence2Processor
model = Florence2ForConditionalGeneration.from_pretrained(
"microsoft/Florence-2-base-ft"
)
processor = Florence2Processor.from_pretrained("microsoft/Florence-2-base-ft")
- Imports necessary libraries for image processing, web requests, Google Cloud Storage interaction, and logging.
- Initializes the pre-trained Florence-2 model and processor for image caption generation.
- Image Download (download_image):
def download_image(url):
if url.startswith("http://") or url.startswith("https://"):
# Handle HTTP/HTTPS URLs
# ... (code to download image from URL) ...
elif url.startswith("gs://"):
# Handle Google Cloud Storage paths
# ... (code to download image from GCS) ...
else:
# Handle local file paths
# ... (code to open image from local path) ...
- Downloads the image from the provided URL.
- Supports HTTP/HTTPS URLs, Google Cloud Storage paths (gs://), and local file paths.
- Inference Execution (run_inference):
def run_inference(url, task_prompt):
# ... (code to download image using download_image function) ...
try:
# ... (code to open and process the image) ...
inputs = processor(text=task_prompt, images=image, return_tensors="pt")
except ValueError:
# ... (error handling) ...
# ... (code to generate captions using the model) ...
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
# ... (model generation parameters) ...
)
# ... (code to decode generated captions) ...
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
# ... (code to post-process generated captions) ...
parsed_answer = processor.post_process_generation(
generated_text, task=task_prompt, image_size=(image.width, image.height)
)
return parsed_answer
Orchestrates the image captioning process:
- Downloads the image using download_image.
- Prepares the image and task prompt for the model.
- Generates captions using the loaded Florence-2 model.
- Decodes and post-processes the generated captions.
- Returns the final caption.
2. Task Distribution (worker.py):
- Celery Setup:
import os
from celery import Celery
# ... other imports ...
# Get Redis URL from environment variable or use default
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
# Configure Celery to use Redis as the broker and backend
app = Celery("tasks", broker=REDIS_URL, backend=REDIS_URL)
# ... (Celery configurations) ...
- Sets up Celery to use Redis as the message broker for task distribution.
- Task Definition (inference_task):
@app.task(bind=True, max_retries=3)
def inference_task(self, url, task_prompt):
# ... (logging and error handling) ...
return run_inference(url, task_prompt)
- Defines the inference_task that will be executed by Celery workers.
- This task calls the run_inference function from model.py.
- Worker Execution:
if __name__ == "__main__":
app.worker_main(["worker", "--loglevel=info", "--pool=solo"])
- Starts a Celery worker that listens for and executes tasks.
3. Client Interaction (client.py):
- Celery Connection:
import os
from celery import Celery
# Get Redis URL from environment variable or use default
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
# Configure Celery to use Redis as the broker and backend
app = Celery("tasks", broker=REDIS_URL, backend=REDIS_URL)
- Establishes a connection to Celery using Redis as the message broker.
- Task Submission (send_inference_task):
def send_inference_task(url, task_prompt):
task = inference_task.delay(url, task_prompt)
print(f"Task sent with ID: {task.id}")
# Wait for the result
result = task.get(timeout=120)
return result
- Sends an image captioning task (inference_task) to the Celery worker.
- Waits for the worker to complete the task and retrieves the result.
Docker Integration (docker-compose.yml):
- Defines a multi-container setup using Docker Compose:
- redis: Runs the Redis server for message brokering.
- model: Builds and deploys the model inference worker.
- app: Builds and deploys the client application.

- flower: Runs a web-based Celery task monitoring tool.
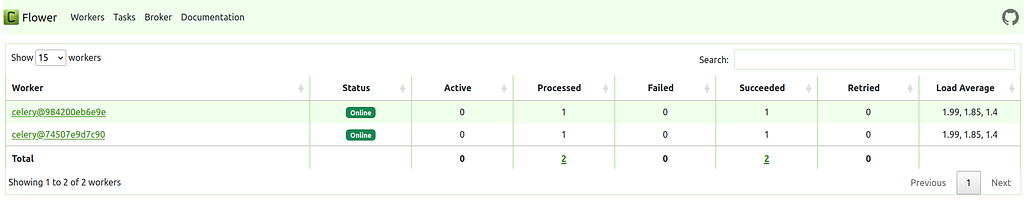
You can run the full stack using:
docker-compose up
And there you have it! We’ve just explored a comprehensive guide to building an asynchronous machine learning inference system using Celery, Redis, and Florence 2. This tutorial demonstrated how to effectively use Celery for task distribution, Redis for message brokering, and Florence 2 for image captioning. By embracing asynchronous workflows, you can handle high volumes of requests, improve performance, and enhance the overall resilience of your ML inference applications. The provided Docker Compose setup allows you to run the entire system on your own with a single command.
Ready for the next step? Deploying this architecture to the cloud can have its own set of challenges. Let me know in the comments if you’d like to see a follow-up post on cloud deployment!
Code: https://github.com/CVxTz/celery_ml_deploy
Asynchronous Machine Learning Inference with Celery, Redis, and Florence 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Asynchronous Machine Learning Inference with Celery, Redis, and Florence 2