

This blog post shares recent papers on out-of-distribution generalization on graph-structured data
This blog post introduces recent advances in out-of-distribution generalization on graphs, an important yet under-explored problem in machine learning. We will first introduce the problem formulation and typical scenarios involving distribution shifts on graphs. Then we present an overview of three recently published papers (where I am the author):
Handling Distribution Shifts on Graphs: An Invariance Perspective, ICLR2022.
Graph Out-of-Distribution Generalization via Causal Intervention, WWW2024.
Learning Divergence Fields for Shift-Robust Graph Representations, ICML2024.
These works focus on generalization on graphs through the lens of invariance principle and causal intervention. Moreover, we will compare these methods and discuss potential future directions in this area.
Graph machine learning remains a popular research direction, especially with the wave of AI4Science driving increasingly diverse applications of graph data. Unlike general image and text data, graphs stand as a mathematical abstraction that describes the attributes of entities and their interactions within a system. In this regard, graphs can not only represent real-world physical systems of different scales (such as molecules, protein interactions, social networks, etc.), but also describe certain abstract topological relationships (such as scene graphs, industrial processes, chains of thought, etc.).
How to build universal foundation models for graph data is a research question that has recently garnered significant attention. Despite the powerful representation capabilities demonstrated by existing methods such as Graph Neural Networks (GNNs) and Graph Transformers, the generalization of machine learning models on graph-structured data remains an underexplored open problem [1, 2, 3]. On the one hand, the non-Euclidean space and geometric structures involved in graph data significantly increase the difficulty of modeling, making it challenging for existing methods aimed at enhancing model generalization to succeed [4, 5, 6]. On the other hand, the distribution shift in graph data, i.e., the difference in distribution between training and testing data, arises from more complex guiding factors (such as topological structures) and external context, making this problem even more challenging to study [7, 8].
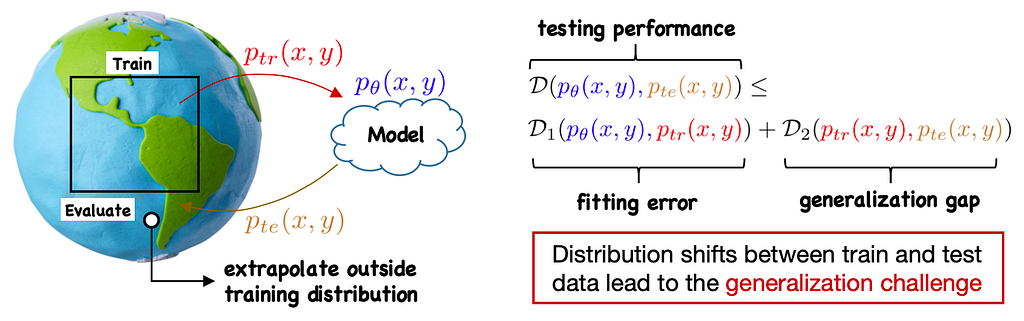
Problem and Motivation
Distribution Shifts in An Open World
The issue of generalization is crucial because models in real-world scenarios often need to interact with an open, dynamic, and complex environment. In practical situations, due to limited observation and resources, training data cannot encompass all possible environments, and the model cannot foresee all potential future circumstances during the training process. At the testing stage, however, the model is likely to encounter samples that are not aligned with the training distribution. The key focus of the out-of-distribution generalization (OOD) problem targets how machine learning models perform on test data outside the training distribution.

In this setting, since the test data/distribution is strictly unseen/unknown during the training process, structural assumptions about the data generation are necessarily required as a premise. Conversely, without any data assumptions, out-of-distribution generalization is impossible (no-free lunch theorem). Therefore, it is important to clarify upfront that the research goal of the OOD problem is not to eliminate all assumptions but to 1) maximize the model’s generalization ability under reasonable assumptions, and 2) properly add/reduce assumptions to ensure the model’s capability to handle certain distribution shifts.
Out-of-Distribution Generalization on Graphs
The general out-of-distribution (OOD) problem can be simply described as:
How to design effective machine learning methods when p(x,y|train)≠p(x,y|test)?
Here, we follow the commonly used setting in the literature, assuming that the data distribution is controlled by an underlying environment. Thus, under a given environment e, the data generation can be written as (x,y)∼p(x,y|e). Then for the OOD problem, training and test data can be assumed to be generated from different environments. Consequently, the problem can be further elaborated as
How to learn a predictor model f such that it performs (equally) well across all environments e∈E?
Specifically, for graph-structured data, the input data also contains structural information. In this regard, depending on the form in which graph structures exist, the problem can be further categorized into two types: node-level tasks and graph-level tasks. The following figure presents the formulation of the OOD problem under the two types of tasks.

As previously mentioned, the OOD problem requires certain assumptions about data generation which pave the way for building generalizable machine learning methods. Below, we will specifically introduce two classes of methods that utilize the invariance principle and causal intervention, respectively, to achieve out-of-distribution generalization on graphs.
Generalization by Invariance Principle
Learning methods based on the invariance principle, often referred to as invariant learning [9, 10, 11], aim to design new learning algorithms that guide machine learning models to leverage the invariant relations in data. Invariant relations particularly refer to the predictive relations from input x and label y that universally hold across all environments. Therefore, when a predictor model f (e.g., a neural network) successfully learns such invariant relations, it can generalize across data from different environments. On the contrary, if the model learns spurious correlations, which particularly refer to the predictive relations from x and y that hold only in some environments, then excessively improving training accuracy would mislead the predictor to overfit the data.
In light of the above illustration, we notice that invariant learning relies on the invariant assumption in data generation, i.e., there exists a predictive relation between x and y that remains invariant across different environments. Mathematically, this can be formulated as:
There exists a mapping c such that z=c(x) satisfies p(y|z,e)=p(y|z), ∀e∈E.
In this regard, we naturally have two follow-up questions: i) how can the invariant assumption be defined on graphs? and ii) is this a reasonable assumption for common graph data?
We next introduce the recent paper [5], Wu et al., “Handling Distribution Shifts on Graphs: An Invariance Perspective” (ICLR2022). This paper proposes applying the invariance principle to out-of-distribution generalization on graphs and poses the invariance assumption for graph data.
Invariant Assumption on Graphs
Inspired by the Weisfeiler-Lehman algorithm for graph isomorphism testing, [5] considers ego-graphs centered on each node and characterizes the contributions of all the nodes’ features within the ego-graph to the label of the central node. The latter is specifically decomposed into invariant features and spurious features. This definition accommodates the topological structures and also allows enough flexibility. The following figure illustrates the invariant assumption as defined in [5] and provides an example of a citation network.
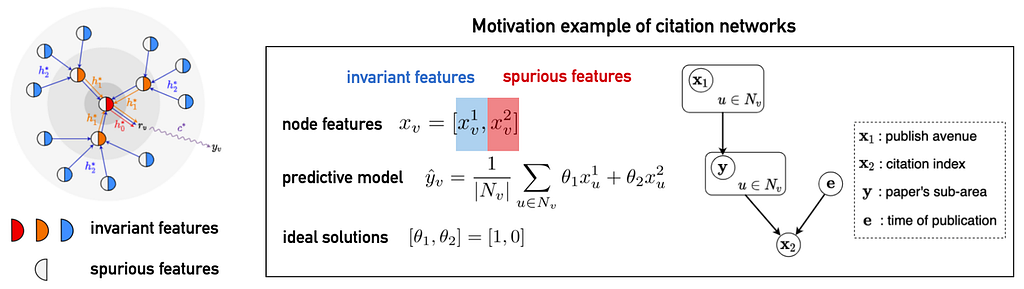
Proposed Method: Explore-to-Extrapolate Risk Minimization
Under the invariance assumption, a natural approach is to regularize the loss difference across environments to facilitate learning invariant relations. However, real-world data typically lack environment labels, i.e., the correspondence between each instance and its environment is unknown, making it impossible to directly compute differences in loss across different environments. To address this challenge, [5] proposes Exploration-Extrapolation Risk Minimization (EERM), which involves introducing K context generators to augment and diversify the input data, thereby simulating input data from different environments. Through theoretical analysis, [5] proves that the new learning objective can guarantee an optimal solution for the formulated out-of-distribution generalization problem.

Apart from generating (virtual) environments, another recent study [12] proposes inferring latent environments from observed data and introduces an additional model for environment inference, iteratively optimizing it alongside the predictor during training. Meanwhile, [13] approaches OOD generalization with data augmentation, using the invariance principle to guide the data augmentation process that preserves invariant features.
Generalization by Causal Intervention
Invariant learning requires assuming the existence of invariant relations in data that can be learned. This to some extent limits the applicability of such methods, as the model can only generalize reliably on test data that shares certain invariance with training data. For out-of-distribution test data that violates this condition, the model’s generalization performance remains unknown.
Next, we introduce another approach proposed by recent work [14], Wu et al., “Graph Out-of-Distribution Generalization via Causal Intervention” (WWW2024). This paper aims to tackle out-of-distribution generalization through the lens of causal intervention. Unlike invariant learning, this approach does not rely on the invariant assumption in data generation. Instead, it guides the model to learn causality from x to y through the learning algorithm.
A Causal Perspective for Graph Learning
Firstly, let us consider the causal dependency among variables typically induced by machine learning models such as graph neural networks. We have the input G (e.g., ego-graphs centered on each node in a graph), the label Y, and the environment E influencing the data distribution. After training with the standard supervised learning objective (e.g., empirical risk minimization or equivalently, maximum likelihood estimation), their dependencies are illustrated in the diagram below.

The causal graph above reveals the limitation of traditional training methods, specifically their inability to achieve out-of-distribution generalization. Here, both the input G and the label Y are outcomes of the environment E, suggesting that they are correlated due to this confounder. During training, the model continuously fits the training data, causing the predictor f to learn the spurious correlation between inputs and labels specific to a particular environment.
[14] introduces an example of a social network to illustrate this learning process. Suppose we need to predict the interests of users (nodes) in a social network, where notice that user interests are significantly influenced by factors such as age and social circles. Therefore, if a predictor is trained on data from a university social network, it might easily predict a user’s interest in “basketball” because within a university environment, there is a higher proportion of users interested in basketball due to the environment itself. However, this predictive relation may not hold when the model is transferred to LinkedIn’s social network, where user ages and interests are more diverse. This example highlights that an ideal model needs to learn the causal relations between inputs and labels to generalize across different environments.
To this end, a common approach is causal intervention, which involves cutting off the dependence path between E and G in the causal graph. This is achieved by disrupting how the environment influences the inputs and labels, thereby guiding the model to learn causality. The diagram below illustrates this approach. In causal inference terminology [15], such interventions, aimed at removing dependence paths to a specific variable, can be represented using the do-operator. Therefore, if we aim to enforce cutting off the dependence path between E and G during training, it effectively means replacing the traditional optimization objective p(Y|G) (the likelihood of observed data) with p(Y|do(G)).

However, computing this learning objective requires observed environment information in data, specifically the correspondence between each sample G and its environment E. In practice, however, environments are often unobservable.
Proposed Method: Variational Context Adjustment
To make the above approach feasible, [14] derives a variational lower bound for the causal intervention objective, using a data-driven approach that infers the latent environments from data to address the issue of unobservable environments. Particularly, [14] introduces a variational distribution q(E|G), resulting in a surrogate learning objective depicted in the following figure.

The new learning objective is comprised of three components. [14] instantiates them as an environment inference model, a GNN predictor, and a (non-parametric) prior distribution of the environment. The first two models contain trainable parameters and are jointly optimized during training.
To validate the effectiveness of the proposed method, [14] applies the model to various real-world graph datasets with distribution shifts. Specifically, because the proposed method CaNet does not depend on specific backbone models, [14] uses GCN and GAT as the backbone, respectively, and compares the model with state-of-the-art OOD methods (including the previously-introduced approach EERM). The table below shows some of the experimental results.

Implicit Assumptions in Causal Intervention
So far, we have introduced the method of causal intervention that shows competitiveness for out-of-distribution generalization on graphs. As mentioned earlier in this blog, achieving guaranteed generalization requires necessary assumptions about how the data is generated. This triggers a natural inquiry: What assumptions does causal intervention require for generalization? Unlike invariant learning, causal intervention does not start from explicit assumptions but instead relies on implicit assumptions during modeling and analysis:
There exists only one confounding factor (the environment) between the inputs and the labels.
This assumption simplifies the analysis of the real system to some extent but introduces approximation errors. For more complex scenarios, there remains significant exploration space in the future.
Generalization with Implicit Graph Structures
In the previous discussion, we assumed that the structural information of input data is observed and complete. For more general graph data, structural information may be partially observed or even completely unknown. Such data is referred to as implicit graph structures. Moreover, distribution shifts on graphs may involve underlying structures that impact data distribution, posing unresolved challenges in characterizing the influence of geometry on data distribution.
To address this, recent work [16], Wu et al., “Learning Divergence Fields for Shift-Robust Graph Representations” (ICML2024), leverages the inherent connection between continuous diffusion equations and message passing mechanisms, integrating the causal intervention approach introduced earlier. This design aims to develop a learning method that is applicable for both explicit and implicit graph structures where distribution shifts pose the generalization challenge.
From Message Passing to Diffusion Equations
Message Passing mechanism serves as a foundational design in modern graph neural networks and graph Transformers, propagating information from other nodes in each layer to update the representation of the central node. Essentially, if we view the layers of a neural network as discretized approximations of continuous time, then message passing can be seen as a discrete form of diffusion process on graphs [17, 18]. The following diagram illustrates their analogy. (We refer the readers interested in more details along this line to recent blogs by Prof. Michael Bronstein et al.).

Particularly, the diffusivity (denoted by d_u) in the diffusion equation controls the interactions between nodes during the diffusion process. When adopting local or global diffusion forms, the discrete iterations of the diffusion equation respectively lead to the layer-wise update formulas of Graph Neural Networks [18] and Transformers [19].
However, the deterministic diffusivity cannot model the multi-faceted effects and uncertainties in interactions between instances. Therefore, [16] proposes defining the diffusivity as a random sample from a probability distribution. The corresponding diffusion equation will yield a stochastic trajectory (as shown in the figure below).

Even so, if the traditional supervised learning objective is directly applied for training, the model described above can not generalize well with distribution shifts. This issue is echoed by the causal perspective of graph learning discussed earlier. Specifically, in the diffusion models considered here, the input x (such as a graph) and the output y (such as node labels in the graph) are associated by diffusivity. The diffusivity can be seen as an embodiment of the environment specific to the dataset, determining the interdependencies among instances. Therefore, the model trained on limited training data tends to learn specific interdependent patterns specific to the training set, making it unable to generalize to new test data.
Causality-guided Divergence Field Learning
To address this challenge, we once again employ causal intervention to eliminate the dependency between the diffusivity d and the input x during training. Unlike previous work [14] where the mapping from input to output was given by a predictor, here the dependence path from x to y involves a multi-step diffusion process (corresponding to multiple layers of updates in GNNs/Transformers). Therefore, causal intervention is needed at each step of the diffusion process. However, since the diffusivity is an abstract notion for modeling and cannot be directly observed (similar to the environment discussed earlier), [16] extends the variational approach used in [14] to derive a variational lower bound for the learning objective pertaining to the diffusion process. This serves as an approximate objective for causal intervention at each step of the diffusion process.
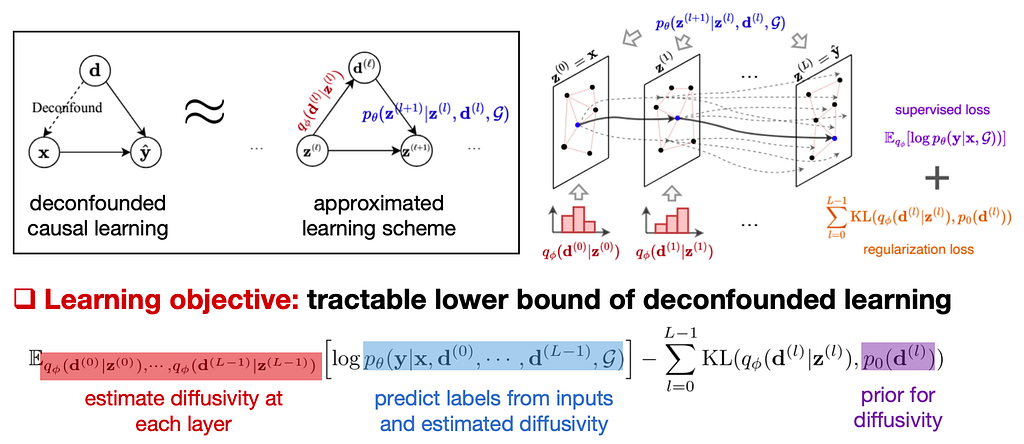
As an implementation of the aforementioned method, [16] introduces three specific model designs:
- GLIND-GCN: Considers the diffusivity as a constant matrix instantiated by the normalized graph adjacency matrix;
- GLIND-GAT: Considers the diffusivity as a time-dependent matrix implemented by graph attention networks;
- GLIND-Trans: Considers the diffusivity as a time-dependent matrix implemented by global all-pair attention networks.
Particularly, for GLIND-Trans, to address the quadratic complexity issue in global attention computations, [16] further adopts the linear attention function design from DIFFormer [19]. (We also refer the readers interested in how to achieve linear complexity for all-pair attentions to this Blog).
The table below presents partial experimental results in scenarios involving implicit structures.

Summary and Discussion
This blog briefly introduces recent advances in out-of-distribution (OOD) generalization, focusing primarily on three published papers [5, 14, 16]. These works approach the problem from the perspectives of invariant learning and causal intervention, proposing methods applicable to both explicit and implicit graph structures. As mentioned earlier, we note that OOD problems require assumptions about the data generation as a prerequisite for effective solutions. Based on this, future research could focus on refining existing methods or analyzing the limits of generalization under the well-established assumptions. It could also explore how to achieve generalization under other assumption conditions.
Another challenge closely related to OOD generalization is Out-of-Distribution Detection [20, 21, 22]. Unlike OOD generalization, OOD detection aims to investigate how to equip models during training to recognize out-of-distribution samples appearing during the testing phase. Future research could also focus on extending the methods in this blog to OOD detection or exploring the intersection of these two problems.
References
[1] Garg et al., Generalization and Representational Limits of Graph Neural Networks, ICLR 2020.
[2] Koh et al., WILDS: A Benchmark of in-the-Wild Distribution Shifts, ICML 2021
[3] Morris et al., Position: Future Directions in the Theory of Graph Machine Learning, ICML 2024.
[4] Zhu et al., Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data, NeurIPS 2021.
[5] Wu et al., Handling Distribution Shifts on Graphs: An Invariance Perspective, ICLR 2022.
[6] Li et al., OOD-GNN: Out-of-Distribution Generalized Graph Neural Network, TKDE 2022.
[7] Yehudai et al., From Local Structures to Size Generalization in Graph Neural Networks, ICML 2021.
[8] Li et al., Size Generalization of Graph Neural Networks on Biological Data:
Insights and Practices from the Spectral Perspective, Arxiv 2024.
[9] Arjovsky, et al., Invariant Risk Minimization, Arxiv 2019.
[10] Rojas-Carulla, et al., Invariant Models for Causal Transfer Learning, JMLR 2018.
[11] Krueger et al., Out-of-Distribution Generalization via Risk Extrapolation, ICML 2021.
[12] Yang et al., Learning Substructure Invariance for Out-of-Distribution Molecular Representations, NeurIPS 2022.
[13] Sui et al., Unleashing the Power of Graph Data Augmentation on Covariate Distribution Shift, NeurIPS 2023.
[14] Wu et al., Graph Out-of-Distribution Generalization via Causal Intervention, WWW 2024.
[15] Pearl et al., Causal Inference in Statistics: A Primer, 2016.
[16] Wu et al., Learning Divergence Fields for Shift-Robust Graph Representations, ICML 2024.
[17] Freidlin et al., Diffusion Processes on Graphs and the Averaging Principle, The Annals of probability 1993.
[18] Chamberlain et al., GRAND: Graph Neural Diffusion, ICML 2021.
[19] Wu et al., DIFFormer: Scalable (Graph) Transformers Induced by
Energy Constrained Diffusion, ICLR 2023.
[20] Wu et al., Energy-based Out-of-Distribution Detection for Graph Neural Networks, ICLR 2023.
[21] Liu et al., GOOD-D: On Unsupervised Graph Out-Of-Distribution Detection, WSDM 2023.
[22] Bao et al., Graph Out-of-Distribution Detection Goes Neighborhood Shaping, ICML 2024.
Towards Generalization on Graphs: From Invariance to Causality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Towards Generalization on Graphs: From Invariance to Causality
Go Here to Read this Fast! Towards Generalization on Graphs: From Invariance to Causality