

Predictive vs. causal inference: a critical distinction
“If all you have is a hammer, everything looks like a nail.”
In the era of AI/ML, Machine Learning is often used as a hammer to solve every problem. While ML is profoundly useful and important, ML is not always the solution.
Most importantly, Machine Learning is made essentially for predictive inference, which is inherently different from causal inference. Predictive models are incredibly powerful tools, allowing us to detect patterns and associations, but they fall short in explaining why events occur. This is where causal inference steps in, allowing for more informed decision-making, that can effectively influence outcomes and go beyond mere association.
Predictive inference exploits correlations. So if you know that “Correlation does not imply causation”, you should understand that Machine Learning should not be used blindly to measure causal effects.
Mistaking predictive inference for causal inference can lead to costly mistakes as we are going to see together! To avoid making such mistakes, we will examine the main differences between these two approaches, discuss the limitations of using machine learning for causal estimation, explore how to choose the appropriate method correctly, how often they work together to solve different parts of a question, and explore how both can be effectively integrated within the framework of Causal Machine Learning.
This article will answer the following questions:
- What is causal inference and what is predictive inference?
- What are the main differences between them, and why does correlation not imply causation?
- Why is it problematic to use Machine Learning for inferring causal effects?
- When should each type of inference be used?
- How can causal and predictive inference be used together?
- What is Causal Machine Learning and how does it fit into this context?
What is predictive inference?
Machine Learning is about prediction.
Predictive inference involves estimating the value of something (an outcome) based on the values of other variables (as they are). If you look outside and people are wearing gloves and hats, it is most certainly cold.
Examples:
- Spam filter: ML algorithms are used to filter incoming emails between safe and spam using the content, the sender, and other various information attached to an email.
- Tumor detection: Machine Learning (Deep Learning) can be used to detect brain tumors from MRI images.
- Fraud detection: In banking, ML is used to detect potential fraud based on credit card activity.
Bias-variance: In predictive inference, you want a model able to predict the outcome well, most of the time out-of-sample (with new unseen data). You might accept a bit of bias if it results in lower variance in the predictions.
What is causal inference?
Causal inference is the study of cause and effect. It is about impact evaluation.
Causal inference aims to measure the value of the outcome when you change the value of something else. In causal inference, you want to know what would happen if you change the value of a variable (feature), everything else equal. This is completely different from predictive inference where you try to predict the value of the outcome for a different observed value of a feature.
Examples:
- Marketing campaign ROI: Causal inference helps to measure the impact (consequence) of a marketing campaign (cause).
- Political Economy: Causal inference is often used to measure the effect (consequence) of a policy (cause).
- Medical research: Causal inference is key to measuring the effect of drugs or behavior (causes) on health outcomes (consequence).
Bias-variance: In causal inference, you do not focus on the quality of the prediction with measures like R-square. Causal inference aims to measure an unbiased coefficient. It is possible to have a valid causal inference model with a relatively low predictive power as the causal effect might explain just a small part of the variance of the outcome.
Key conceptual difference: The complexity of causal inference lies in the fact that we want to measure something that we will never actually observe. To measure a causal effect, you need a reference point: the counterfactual. The counterfactual is the world without your treatment or intervention. The causal effect is measured by comparing the observed situation with this reference (the counterfactual).
Imagine that you have a headache. You take a pill and after a while, your headache is gone. But was it thanks to the pill? Was it because you drank tea or plenty of water? Or just because time went by? It is impossible to know which factor or combination of factors helped as all those effects are confounded. The only way to answer this question perfectly would be to have two parallel worlds. In one of the two worlds, you take the pill and in the other, you don’t. As the pill is the only difference between the two situations, it would allow you to claim that it was the cause. But obviously, we do not have parallel worlds to play with. In causal inference, we call this: The fundamental problem of causal inference.

So the whole idea of causal inference is to approach this impossible ideal parallel world situation by finding a good counterfactual. This is why the gold standard is randomized experiments. If you randomize the treatment allocation (pill vs. placebo) within a representative group, the only systematic difference (assuming that everything has been done correctly) is the treatment, and hence a statistically significant difference in outcome can be attributed to the treatment.

Note that randomized experiments have weaknesses and that it is also possible to measure causal effects with observational data. If you want to know more, I explain those concepts and causal inference more in-depth here:
The Science and Art of Causality (part 1)
Why does correlation not imply causation?
We all know that “Correlation does not imply causation”. But why?
There are two main scenarios. First, as illustrated below in Case 1, the positive relationship between drowning accidents and ice cream sales is arguably just due to a common cause: the weather. When it is sunny, both take place, but there is no direct causal link between drowning accidents and ice cream sales. This is what we call a spurious correlation. The second scenario is depicted in Case 2. There is a direct effect of education on performance, but cognitive capacity affects both. So, in this situation, the positive correlation between education and job performance is confounded with the effect of cognitive capacity.
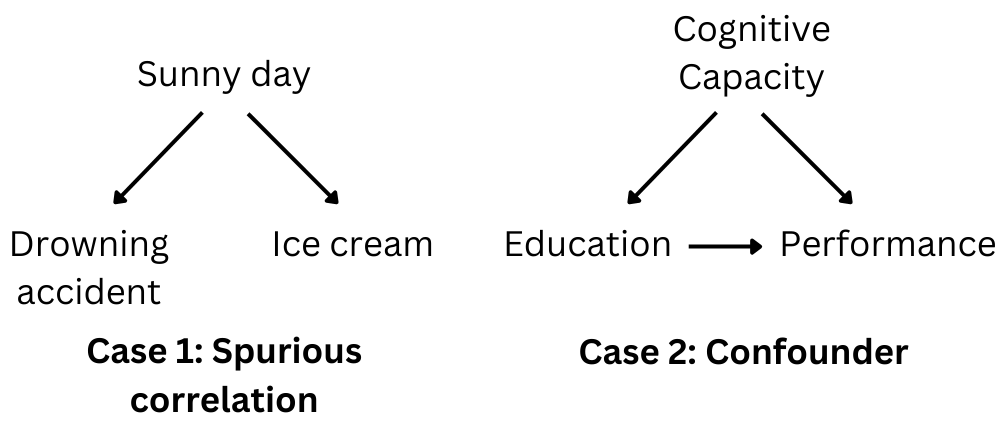
As I mentioned in the introduction, predictive inference exploits correlations. So anyone who knows that ‘Correlation does not imply causation’ should understand that Machine Learning is not inherently suited for causal inference. Ice cream sales might be a good predictor of the risk of drowning accidents the same day even if there is no causal link. This relationship is just correlational and driven by a common cause: the weather.
However, if you want to study the potential causal effect of ice cream sales on drowning accidents, you must take this third variable (weather) into account. Otherwise, your estimation of the causal link would be biased due to the famous Omitted Variable Bias. Once you include this third variable in your analysis you would most certainly find that the ice cream sales is not affecting drowning accidents anymore. Often, a simple way to address this is to include this variable in the model so that it is not ‘omitted’ anymore. However, confounders are often unobserved, and hence it is not possible to simply include them in the model. Causal inference has numerous ways to address this issue of unobserved confounders, but discussing these is beyond the scope of this article. If you want to learn more about causal inference, you can follow my guide, here:
How to Learn Causal Inference on Your Own for Free
Hence, a central difference between causal and predictive inference is the way you select the “features”.
In Machine Learning, you usually include features that might improve the prediction quality, and your algorithm can help to select the best features based on predictive power. However, in causal inference, some features should be included at all costs (confounders/common causes) even if the predictive power is low and the effect is not statistically significant. It is not the predictive power of the confounder that is the primary interest but rather how it affects the coefficient of the cause we are studying. Moreover, there are features that should not be included in the causal inference model, for example, mediators. A mediator represents an indirect causal pathway and controlling for such variables would prevent measuring the total causal effect of interest (see illustration below). Hence, the major difference lies in the fact that the inclusion or not of the feature in causal inference depends on the assumed causal relationship between variables.
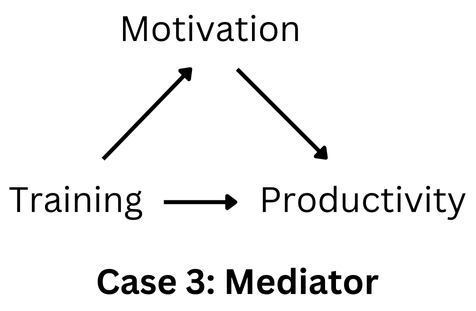
This is a subtle topic. Please refer to “A Crash Course in Good and Bad Controls” Cinelli et al. (2002) for more details.
Why is it problematic to use Machine Learning for inferring causal effects?
Imagine that you interpret the positive association between ice cream sales and drowning accidents as causal. You might want to ban ice cream at all costs. But of course, that would have potentially little to no effect on the outcome.
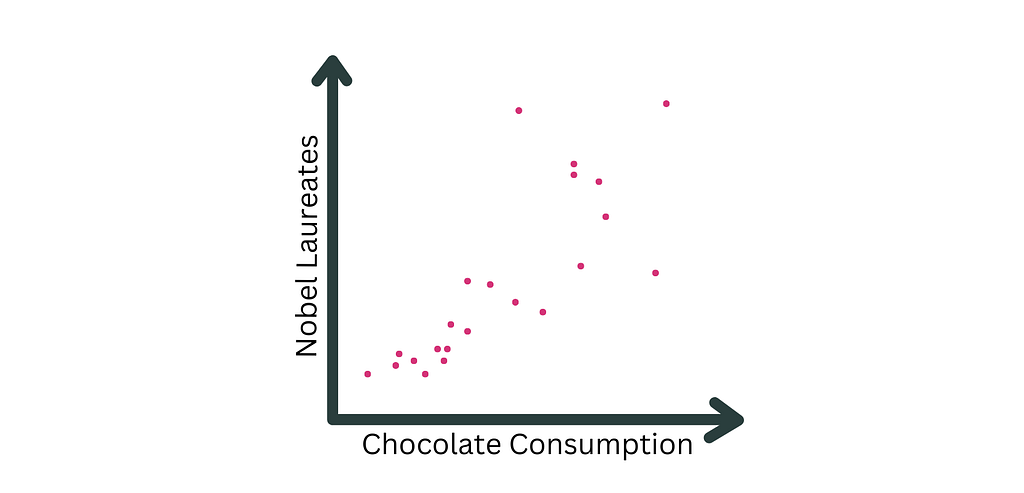
A famous correlation is the one between chocolate consumption and Nobel prize laureates (Messerli (2012)). The author found a 0.8 linear correlation coefficient between the two variables at the country level. While this sounds like a great argument to eat more chocolate, it should not be interpreted causally. (Note that the arguments of a potential causal relationship presented in Messerli (2012) have been disproved later (e.g., P Maurage et al. (2013)).
Now let me share a more serious example. Imagine trying to optimize the posts of a content creator. To do so, you build an ML model including numerous features. The analysis revealed that posts published late afternoon or in the evening have the best performance. Hence, you recommend a precise schedule where you post exclusively between 5 pm and 9 pm. Once implemented, the impressions per post crashed. What happened? The ML algorithm predicts based on current patterns, interpreting the data as it appears: posts made late in the day correlate with higher impressions. Eventually, the posts published in the evening were the ones more spontaneous, less planned, and where the author didn’t aim to please the audience in particular but just shared something valuable. So the timing was not the cause; it was the nature of the post. This spontaneous nature might be harder to capture with the ML model (even if you code some features as length, tone, etc., it might not be trivial to capture this).
In marketing, predictive models are often used to measure the ROI of a marketing campaign.
Often, models such as simple Marketing Mix Modeling (MMM) suffer from omitted variable bias and the measure of ROI will be misleading.
Typically, the behavior of the competitors might correlate with our campaign and also affect our sales. If this is not taken into account properly, the ROI might be under or over-evaluated, leading to sub-optimal business decisions and ad spending.
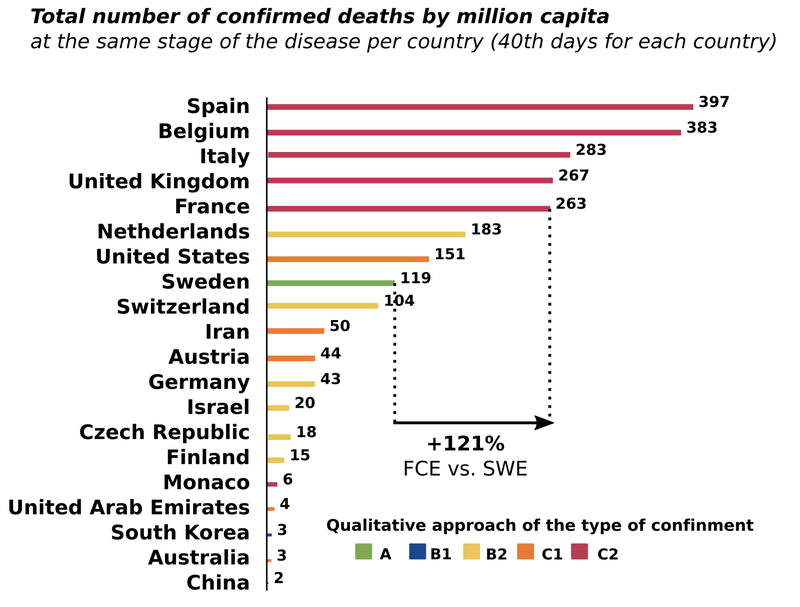
This concept is also important for policy and decision-making. At the beginning of the Covid-19 pandemic, a French “expert” used a graph to argue that lockdowns were counterproductive (see figure below). The graph revealed a positive correlation between the stringency of the lockdown and the number of Covid-related deaths (more severe lockdowns were associated with more deaths). However, this relationship was most likely driven by the opposite causal relationship: when the situation was bad (lots of deaths), countries would impose strict measures. This is called reverse causation. Indeed, when you study properly the trajectory of the number of cases and deaths within a country around the lockdowns controlling for potential confounders, you find a strong negative effect (c.f. Bonardi et al. (2023)).
When should each type of inference be used?
Machine learning and causal inference are both profoundly useful; they just serve different purposes.
As usual with numbers and with statistics, most of the time the problem is not the metrics but their interpretation. Hence, a correlation is informative, it becomes problematic only if you interpret it blindly as a causal effect.
When to use Causal Inference: When you want to understand the cause-and-effect relationship and do impact evaluation.
- Policy Evaluation: To determine the impact of a new policy, such as the effect of a new educational program on student performance.
- Medical Studies: To assess the effectiveness of a new drug or treatment on health outcomes.
- Economics: To understand the effect of interest rate changes on economic indicators like inflation or employment.
- Marketing: To evaluate the impact of a marketing campaign on sales.
Key Questions in Causal Inference:
- What is the effect of X on Y?
- Does changing X cause a change in Y?
- What would happen to Y if we intervene on X?
When to use Predictive Inference: When you want to do accurate prediction (association between features and outcome) and learn patterns from the data.
- Risk Assessment: To predict the likelihood of credit default or insurance claims.
- Recommendation Systems: To suggest products or content to users based on their past behavior.
- Diagnostics: To classify medical images for disease detection.
Key Questions for Predictive Inference:
- What is the expected value of Y given X?
- Can we predict Y based on new data about X?
- How accurately can we forecast Y using current and historical data on X?
How can causal and predictive inference be used together?
While causal and predictive inference serve different purposes, they sometimes work together. Dima Goldenberg, Senior Machine Learning Manager at Booking.com, illustrated this perfectly in a podcast with Aleksander Molak (author of ‘Causal Inference and Discovery in Python’).
Booking.com is obviously working hard on recommendation systems. “Recommendation” is a prediction problem: “What type of product would client X prefer to see?” Hence, this first step is typically solved with Machine Learning. However, there is another connected question: “What is the effect of this new recommendation system on sales/conversion, etc.?” Here, the keyword “effect … on” should directly make you realize that you must use causal inference for this second step. This step will require causal inference and more precisely randomized experiments (A/B testing).
This is a typical workflow including complementary roles of Machine Learning and Causal Inference. You develop a predictive model with Machine Learning and you evaluate its impact with Causal Inference.
So, what is Causal Machine Learning and how does it fit into this context?
Recently, a new field emerged: Causal Machine Learning. While this is an important breakthrough, I think that it added to the confusion.
Many people see the term “Causal ML” and just think that they can use Machine Learning carelessly for causal inference.
Causal ML is an elegant combination of both worlds. However, Causal ML is not Machine Learning used blindly for Causal Inference. It is rather Causal Inference with ML sprinkled on top of it to improve the results. The key differentiating concept of causal inference is still valid with Causal ML. The feature selection relies on the assumed causal relationships.
Let me present the two main methods in Causal ML to illustrate this interesting combination.
A. Dealing with High-Dimensional Data and Complex Functional Forms
In some situations, you have numerous control variables in your causal inference models. To reduce the risk of omitted variable bias, you included many potential confounders. How should you deal with this high number of controls? Maybe you have multicollinearity between sets of controls, or maybe you should control for non-linear effects or interactions. This can quickly become very complex and quite arbitrary to solve with traditional causal inference methods.
As Machine Learning is particularly efficient in dealing with high-dimensional data, it can be used to address these challenges. Machine Learning will be used to find the best set of controls and the right functional form in such a way that your model will not suffer from multicollinearity while still satisfying the conditions to measure a causal effect (see: Double Machine Learning Method).
B. Heterogenous Treatment Effects
Causal Inference historically focused on measuring the Average Treatment Effect (ATE), which is a measure of the average effect of a treatment. However, as you are certainly aware, the average is useful, but it can also be misleading. The effect of the treatment could lead to different effects depending on the subject. Imagine that a new drug reduces the risk of cancer significantly on average, but actually, the whole effect is driven by the results on men, while the effect on women is null. Or imagine a marketing campaign leading to a higher conversion rate on average while it actually has a negative impact in a specific region.
Causal ML allows us to go beyond Average Treatment Effect and uncover this heterogeneity by identifying the Conditional Average Treatment Effect (CATE). In other words, it helps to identify the treatment effect conditionally on different characteristics of the subjects.
The main method to uncover the Conditional Average Treatment Effect is called Causal Forest. However, it is important to note that while this methodology will allow us to find sub-groups with different reactions to a treatment, the characteristics defining such groups uncovered with Machine Learning are not necessarily causal. Imagine that the model reveals that the effect of an Ad is completely different for smartphone users vs. tablet users. The ‘device’ should not be interpreted as the cause for this difference. It could be that the real cause is not measured but correlates with this feature, for example, age.
Conclusion
Distinguishing predictive from causal inference is central today to avoid costly mistakes in various domains like marketing, policy-making, and medical research. We examined why machine learning, despite its remarkable predictive capabilities, is not intrinsically suited to causal inference due to its reliance on correlations/associations rather than causal relationships. Hopefully, you will be able to understand this distinction and pick the right model for the right type of questions.

If you want to learn more about causal machine learning here are a few valuable and reliable resources:
Causal Machine Learning:
- Causal Machine Learning in Marketing
- The Value Added of Machine Learning to Causal Inference: Evidence from Revisited Studies
- Causal machine learning for predicting treatment outcomes
Double Machine Learning:
Heterogenous Treatment Effect:
Why Machine Learning Is Not Made for Causal Estimation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Why Machine Learning Is Not Made for Causal Estimation
Go Here to Read this Fast! Why Machine Learning Is Not Made for Causal Estimation