

LLMs won’t replace data scientists, but they will change how we collaborate with decision makers
LLMs are supposed to make data science easier. They generate Python and SQL for every imaginable function, cutting a repetitive task down from minutes to seconds. Yet assembling, maintaining, and vetting data workflows has become more difficult, not less, with LLMs.
LLM code generators create two related problems for data scientists in the private sector. First, LLMs have set the expectation that data scientists should work faster, but privacy considerations may require that they not send confidential data to an LLM. In that case, data scientists must use LLMs to generate code in piecemeal fashion, ensuring the LLM is unaware of the overall dataset
That results in the second issue: a lack of transparency and reproducibility while interpreting results. When data scientists carry out analysis in the “traditional” way, they create deterministic code, written in Python in Jupyter notebooks, for example, and create the final analytic output. An LLM is non-deterministic. Ask it the same question multiple times, and you may get different answers. So while the workflow might yield an insight, the data scientist may not be able to reproduce the process that led to it.
Thus, LLMs can speed up the generation of code for individual steps, but they also have the potential to erode trust between data teams and decision makers. The solution, I believe, is a more conversational approach to analytics where data professionals and decision makers create and discuss insights together.
GenAI’s Mixed Blessings
Executives budget for data science in hopes that it will drive decisions that increase profits and shareholder value — but they don’t necessarily know or care how analytics work. They want more information quicker, and if LLMs speed up data science code production, then data teams better generate code with them. This all goes smoothly if the code is relatively simple, enabling data scientists to build and then interrogate each component before proceeding to the next one. But as the complexity increases, this process gets convoluted, leading to analyses that are more prone to mistakes, more difficult to document and vet, and much harder to explain to business users.
Why? First, data scientists increasingly work in multiple languages along with dialects that are specific to their tools, like Snowflake or Databricks. LLMs may generate SQL and Python, but they don’t absolve data scientists of their responsibility to understand that code and test it. Being the front-line defense against hallucinations — in multiple coding languages — is a significant burden.
Second, LLMs are inconsistent, which can make integrating newly generated code messy. If I run a prompt requesting a table join function in Python, an LLM could give me a different output each time I run the prompt. If I want to modify a workflow slightly, the LLM might generate code incompatible with everything it has given me prior. In that case, do I try to adjust the code I have, or take the new code? And what if the old code is deployed in production somewhere? It’s a bit of a mess.
Third, LLM code generation has the potential to scale a mistake quickly and then hide the root cause. Once code is deeply nested, for example, starting from scratch might be easier than troubleshooting the problem.
If an analysis works brilliantly and decision makers benefit from using it, no one will demand to know the details of the workflow. But if decision makers find out they’ve acted upon misleading analytics — at a cost to their priorities — they’ll grow to distrust data and demand that data scientists explain their work. Convincing business users to trust in an analysis is difficult when that analysis is in a notebook and rendered in nested code, with each component sourced from an LLM.
We Don’t Think in Code
If I were to show fellow data scientists a Python notebook, they’d understand what I intended to do — but they’d struggle to identify the root cause of any problems in that code. The issue is that we’re attempting to reason and think in code. Programming languages are like Morse code in the sense that they don’t mean anything without a vernacular to provide context and meaning. A potential solution then is to spend less time in the land of code and more time in the land of plain English.
If we conduct, document, and discuss analyses in English, we’re more likely to grasp the workflows we’ve developed, and why they make sense or not. Moreover, we’d have an easier time communicating those workflows to the business users who are supposed to act on these analytics but may not fully trust them.
Since 2016, I’ve researched how to abstract code into English and abstract natural language into SQL and Python. That work ultimately led my colleague Rogers Jeffrey Leo John and I to launch a company, DataChat, around the idea of creating analytics using plain English commands and questions. In my work at Carnegie Mellon University, I often use this tool for initial data cleaning and preparation, exploration, and analysis.
What if, instead of merely documenting work in English, enterprise data teams collaborated with decision makers to create their initial analytics in a live setting? Instead of spending hours in isolation working on analyses that may not be reproducible and may not answer the executives’ biggest questions, data scientists would facilitate analytics sessions the way creatives facilitate brainstorming sessions. It’s an approach that could build trust and consensus.
To illustrate why this is a fruitful direction for enterprise data science, I’ll demonstrate what this could look like with an example. I’ll use DataChat, but I want to emphasize that there are other ways to render code in vernacular and document data workflows using LLMs.
With Decision Makers in the Room
To recap, we use coding languages in which LLMs are now fluent — but they can come up with numerous solutions to the same prompt, impairing our ability to maintain the quality of our code and reproduce analyses. This status quo introduces a high risk of analytics that could mislead decision makers and lead to costly actions, degrading trust between analytics creators and users.
Now, though, we’re in a boardroom with C-level executives of an ecommerce company that specializes in electronics. The datasets in this example are generated to look realistic but do not come from an actual company.
A typical, step-by-step guide to analyzing an ecommerce dataset in Python might start like this:
import pandas as pd
# Path to your dataset
file_path = 'path/to/your/dataset.csv'
# Load the dataset
df = pd.read_csv(file_path)
# Display the first few rows of the dataframe
print(df.head())
This is instructive for a data scientist — we know the coder has loaded a dataset. This is exactly what we’re going to avoid. The business user doesn’t care. Abstracted in English, here’s the equivalent step with our datasets:
The C-level team now understands which datasets we’ve included in the analysis, and they want to explore them as one dataset. So, we need to join these datasets. I’ll use plain English commands, as if I were talking to an LLM (which, indirectly, I am):
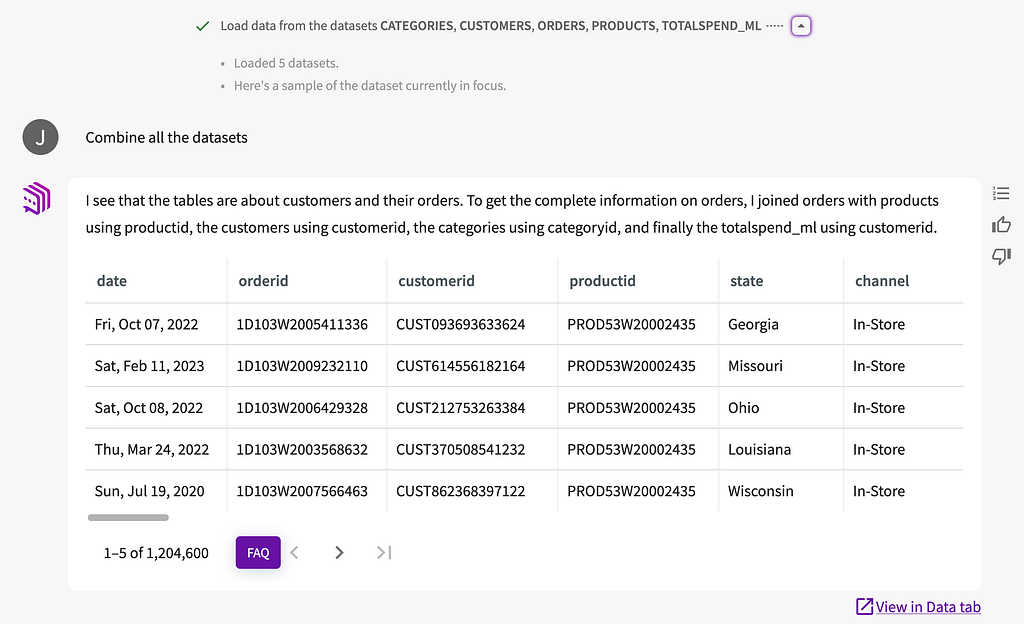
I now have a combined dataset and an AI-generated description of how they were joined. Notice that my prior step, loading the dataset, is visible. If my audience wanted to know more about the actual steps that led to this outcome, I can pull up the workflow. It is a high-level description of the code, written in Guided English Language (GEL), which we originally developed in an academic paper:

Now I can field questions from the C-level team, the domain experts in this business. I’m simultaneously running the analysis and training the team in how to use this tool (because, ultimately, I want them to answer the basic questions for themselves and task me with work that utilizes my full skillset).
The CFO notices that a price is given for each item ordered, but not the total per order. They want to see the value of each order, so we ask:

The CMO asks questions about sales of specific items and how they fluctuate at different points in the year. Then the CEO brings up a more strategic question. We have a membership program like Amazon Prime, which is designed to increase customer lifetime value. How does membership affect sales? The team assumes that members spend more with us, but we ask:
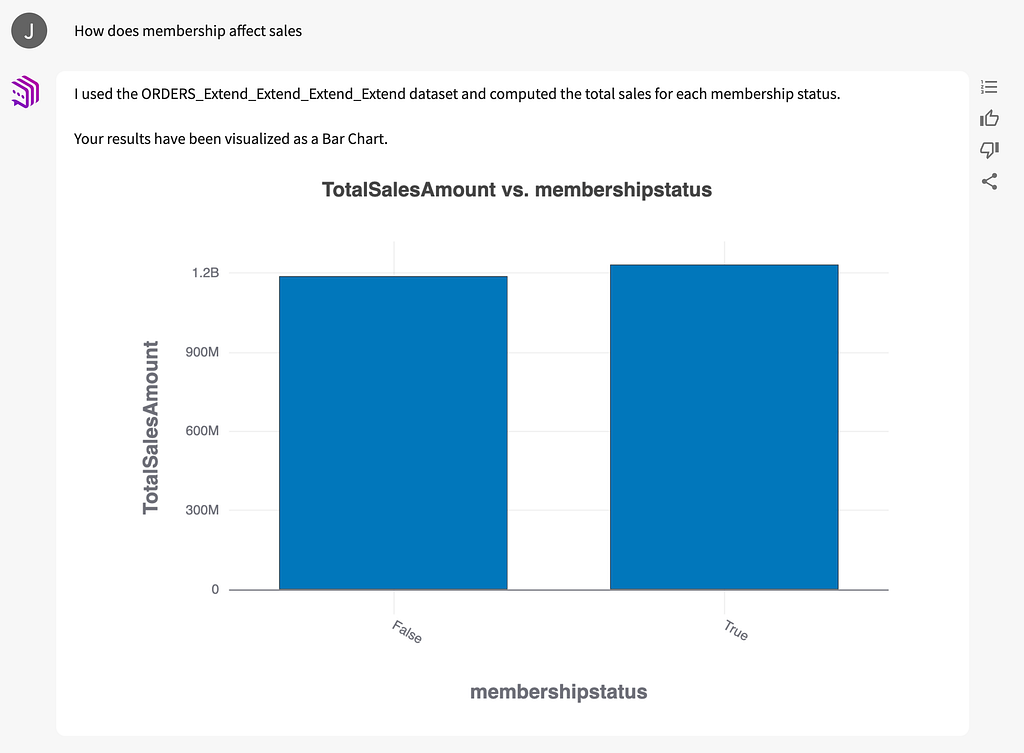
The chart reveals that membership barely increases sales. The executive team is surprised, but they’ve walked through the analysis with me. They know I’m using a robust dataset. They ask to see if this trend holds over a span of several years:
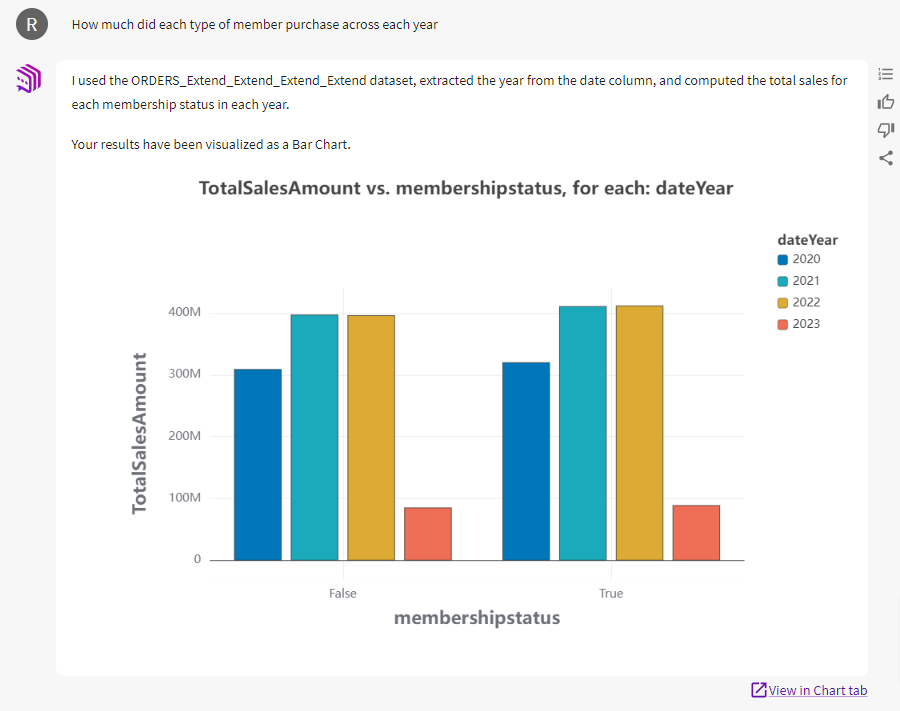
Year to year, membership seems to make almost no difference in purchases. Current investments in boosting membership are arguably wasted. It may be more useful to test member perks or tiers designed to increase purchases. This could be an interesting project for our data team. If, instead, we had emailed a report to the executives claiming that membership has no impact on sales, there’d be far more resistance.
If someone with a stake in the current membership strategy isn’t happy about this conclusion — and wants to see for themselves how we came up with this — we can share the workflow for that chart alone:
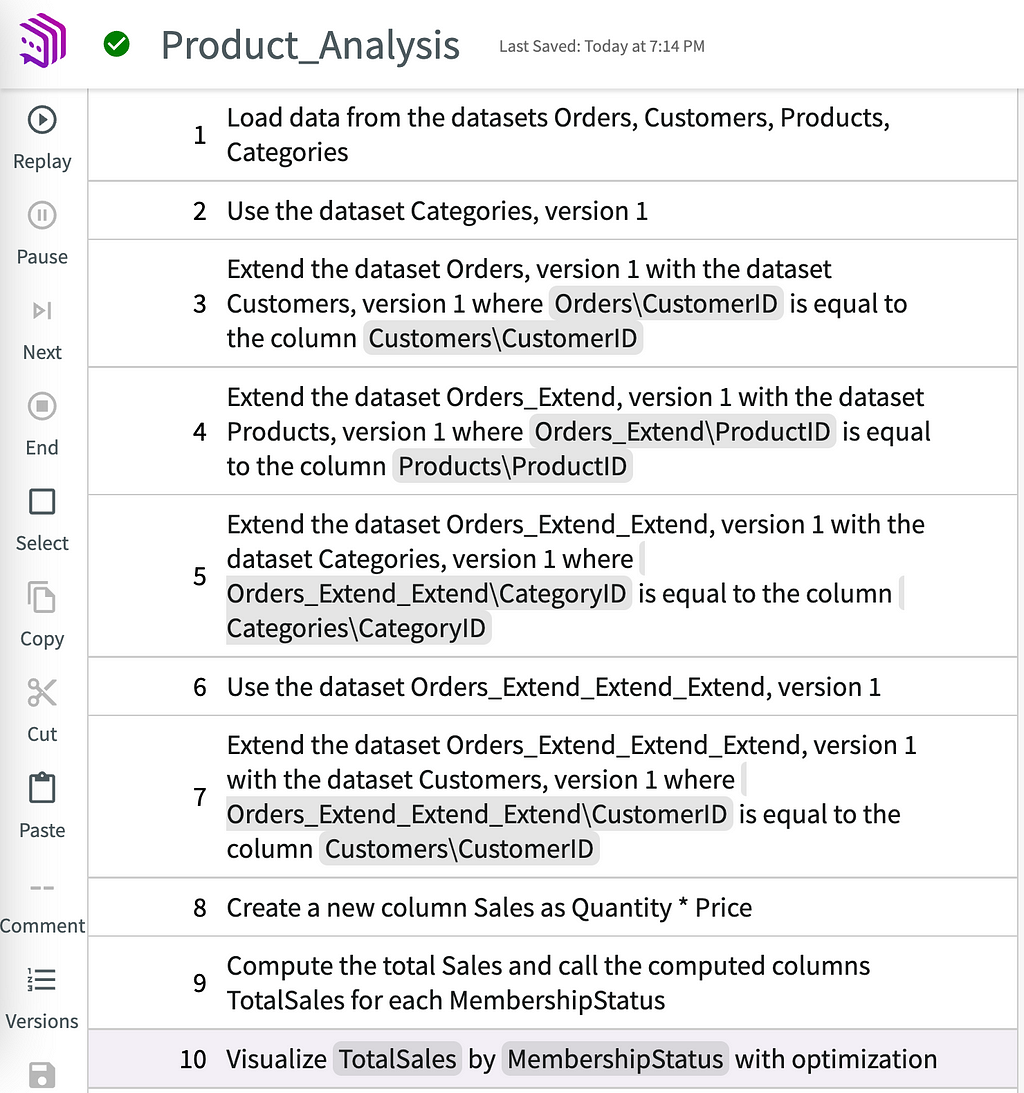
Our analytics session is coming to an end. The workflow is documented, which means anyone can vet and reproduce it (GEL represents exact code). In a few months, after testing and implementing new membership features, we could rerun these steps on the updated datasets to see if the relationship between membership and sales has changed over time.
Conversational Data Science
Normally, data science is made to order. Decision makers request analytics on one thing or another; the data team delivers it; whether the decision makers use this information and how isn’t necessarily known to the analysts and data scientists. Maybe the decision makers have new questions based on the initial analysis, but times up — they need to act now. There’s no time to request more insights.
Leveraging LLMs, we can make data science more conversational and collaborative while eroding the mysteries around where analytics come from and whether they merit trust. Data scientists can run plain-English sessions, like I just illustrated, using widely available tools.
Conversational analytics don’t render the notebook environment irrelevant — they complement it by improving the quality of communication between data scientists and business users. Hopefully, this approach to analytics creates more informed decision makers who learn to ask more interesting and daring questions about data. Maybe these conversations will lead them to care more about the quality of analytics and less about how quickly we can create them with code generation LLMs.
Unless otherwise noted, all images are by the author.
Conversational Analysis Is the Future for Enterprise Data Science was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Conversational Analysis Is the Future for Enterprise Data Science
Go Here to Read this Fast! Conversational Analysis Is the Future for Enterprise Data Science