

Agentic Workflow Writing Structured Documents, A Line-by-Line Tutorial
Not only the Mona Lisa and the Vitruvian Man but also the Curriculum Vitae (CV), are cultural artifacts by Leonardo Da Vinci’s hand that resonate and reproduce in the present time. The CV is not the exclusive way to present oneself to the job market. Yet the CV persists despite the many innovations in information and graphics technology since Leonardo enumerated on paper his skills and abilities to the Duke of Milan.
In high-level terms, the creation of a CV:
- summarizes past accomplishments and experiences of a person in a document form,
- in a manner relevant to a specific audience, who in a short time assesses the person’s relative and absolute utility to some end,
- where the style and layout of the document form are chosen to be conducive to a favourable assessment by said audience.
These are semantic operations in service of an objective under vaguely stated constraints.
Large language models (LLMs) are the premier means to execute semantic operations with computers, especially if the operations are ambiguous in the way human communication often is. The most common way to date to interact with LLMs is a chat app — ChatGPT, Claude, Le Chat etc. We, the human users of said chat apps, define somewhat loosely the semantic operations by way of our chat messages.
Certain applications, however, are better served by a different interface and a different way to create semantic operations. Chat is not the be-all and end-all of LLMs.
I will use the APIs for the LLM models of Anthropic (especially Sonnet and Haiku) to create a basic application for CV assembly. It relies on a workflow of agents working in concert (an agentic workflow), each agent performing some semantic operation in the chain of actions it takes to go from a blob of personal data and history to a structured CV document worthy of its august progenitor…
This is a tutorial on building a small yet complete LLM-powered non-chat application. In what follows I describe both the code, my reasons for a particular design, and where in the bigger picture each piece of Python code fits.
The CV creation app is a useful illustration of AIs working on the general task of structured style-content generation.
Before Code & How — Show What & Wow
Imagine a collection of personal data and lengthy career descriptions, mostly text, organized into a few files where information is scattered. In that collection is the raw material of a CV. Only it would take effort to separate the relevant from the irrelevant, distill and refine it, and give it a good and pleasant form.
Next imagine running a script make_cv and pointing it to a job ad, a CV template, a person and a few specification parameters:
make_cv --job-ad-company "epic resolution index"
--job-ad-title "luxury retail lighting specialist"
--cv-template two_columns_abt_0
--person-name "gregor samsa"
--output-file ../generated_output/cv_nice_two_columns.html
--n-words-employment 50 --n-skills 8 --n-words-about-me 40
Then wait a few seconds while the data is shuffled, transformed and rendered, after which the script outputs a neatly styled and populated one-pager two-column CV.

Nice! Minimal layout and style in green hues, good contrast between text and background, not just bland default fonts, and the content consists of brief and to-the-point descriptions.
But wait… are these documents not supposed to make us stand out?
Again with the aid of the Anthropic LLMs, a different template is created (keywords: wild and wacky world of early 1990s web design), and the same content is given a new glorious form:

If you ignore the flashy animations and peculiar colour choices, you’ll find that the content and layout are almost identical to the previous CV. This isn’t by chance. The agentic workflow’s generative tasks deal separately with content, form, and style, not resorting to an all-in-one solution. The workflow process rather mirrors the modular structure of the standard CV.
That is, the generative process of the agentic workflow is made to operate within meaningful constraints. That can enhance the practical utility of generative AI applications — design, after all, has been said to depend largely on constraints. For example, branding, style guides, and information hierarchy are useful, principled constraints we should want in the non-chat outputs of the generative AI — be they CVs, reports, UX, product packaging etc.
The agentic workflow that accomplishes all that is illustrated below.
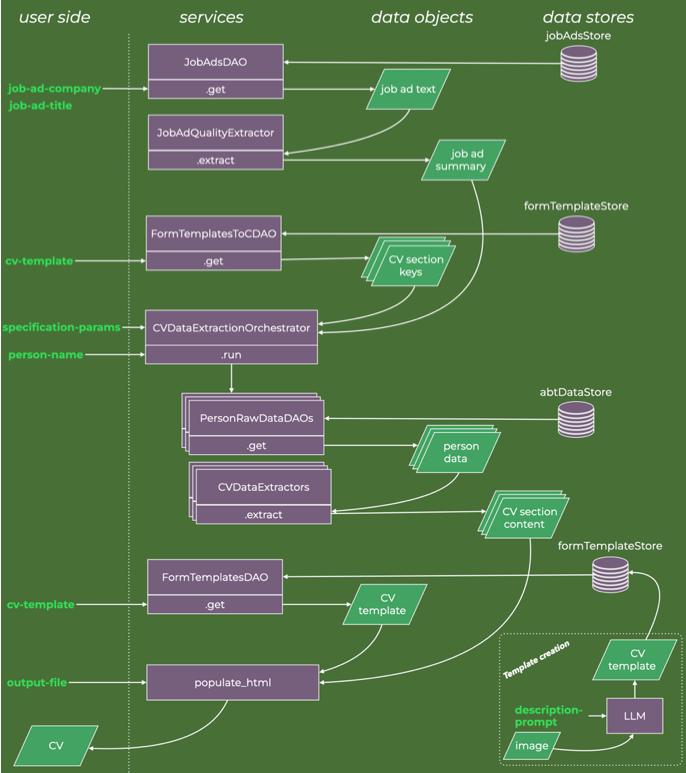
If you wish to skip past the descriptions of code and software design, Gregor Samsa is your lodestar. When I return to discussing applications and outputs, I will do so for synthetic data for the fictional character Gregor Samsa, so keyword-search your way forward.
The complete code is available in this GitHub repo, free and without any guarantees.
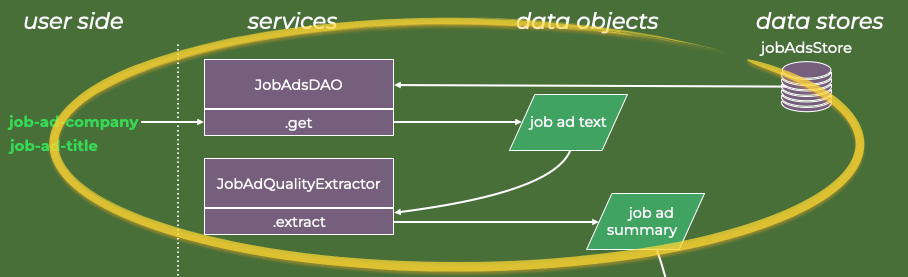
Job Ad Pre-Processing, DAO and Prompt Assembly
It is often said that one should tailor a CV’s content to the job ad. Since job ads are frequently verbose, sometimes containing legal boilerplate and contact information, I wish to extract and summarize only the relevant features and use that text in subsequent tasks.
To have shared interfaces when retrieving data, I make a basic data-access object (DAO), which defines a common interface to the data, which in the tutorial example is stored in text and JSON files locally (stored in registry_job_ads), but generally can be any other job ad database or API.
To summarize or abstract text is a semantic operation LLMs are well-suited for. To that end,
- an instruction prompt is required to make the LLM process the text appropriately for the task;
- and the LLM model from Anthropic has to be selected along with its parameters (e.g. temperature);
- and the instructed LLM is invoked via a third-party API with its specific requirements on syntax, error checking etc.
To keep these three distinct concerns separate, I introduce some abstraction.
The class diagram below illustrates key methods and relationships of the agent that extract key qualities of the job ad.
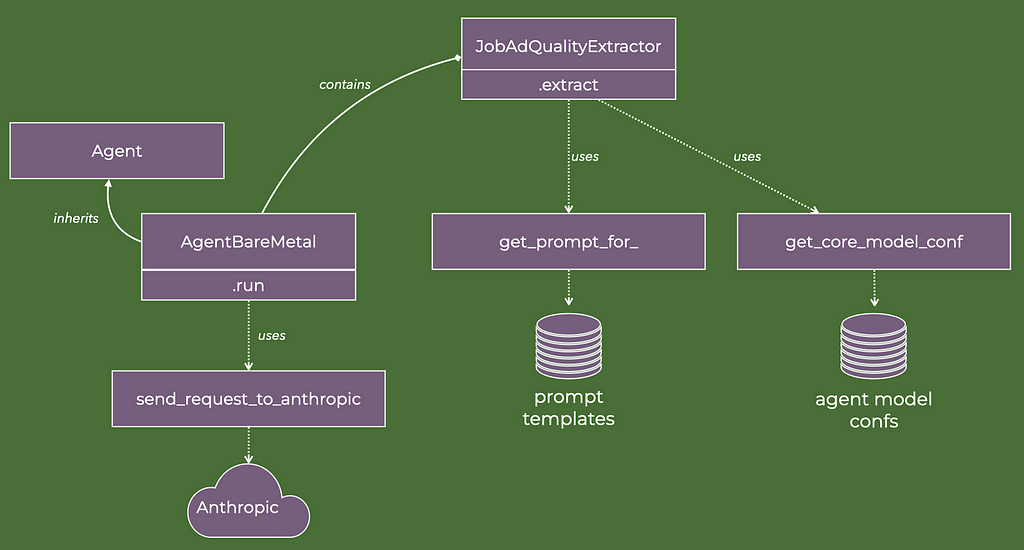
In code, that looks like this:
The configuration file agent_model_extractor_confs is a JSON file that in part looks like this:
Additional configurations are added to this file as further agents are implemented.
The prompt is what focuses the general LLM onto a specific capability. I use Jinja templates to assemble the prompt. This is a flexible and established method to create text files with programmatic content. For the fairly straightforward job ad extractor agent, the logic is simple — read text from a file and return it — but when I get to the more advanced agents, Jinja templating will prove more helpful.
And the prompt template for agent_type=’JobAdQualityExtractor is:
Your task is to analyze a job ad and from it extract,
on the one hand, the qualities and attributes that the
company is looking for in a candidate, and on the other
hand, the qualities and aspirations the company
communicates about itself.
Any boilerplate text or contact information should be
ignored. And where possible, reduce the overall amount
of text. We are looking for the essence of the job ad.
Invoking the Agent, Without Tools
A model name (e.g. claude-3–5-sonnet-20240620), a prompt and an Anthropic client are the least we need to send a request to the Anthropic APIs to execute an LLM. The job ad quality extractor agent has it all. It can therefore instantiate and execute the “bare metal” agent type.
Without any memory of prior use or any other functionality, the bare metal agent invokes the LLM once. Its scope of concern is how Anthropic formats its inputs and outputs.
I create an abstract base class as well, Agent. It is not strictly required and for a task as basic as CV creation of limited use. However, if we were to keep building on this foundation to deal with more complex and diverse tasks, abstract base classes are good practice.
The send_request_to_anthropic_message_creation is a simple wrapper around the call to the Anthropic API.
This is all that is needed to obtain the job ad summary. In short, the steps are:
- Instantiate a job ad quality extractor agent, which entails gathering the associated prompt and Anthropic model parameters.
- Invoke the job ad data access object with a company name and position to get the complete job ad text.
- Apply the extraction on the complete job ad text, which entails a one-time request to the APIs of the Anthropic LLMs; a text string is returned with the generated summary.
In terms of code in the make_cv script, these steps read:
# Step 0: Get Anthropic client
anthropic_client = get_anthropic_client(api_key_env)
# Step 1: Extract key qualities and attributes from job ad
ad_qualities = JobAdQualityExtractor(
client=anthropic_client,
).extract_qualities(
text=JobAdsDAO().get(job_ad_company, job_ad_title),
)
The top part of the data flow diagram has thus been described.
How To Build Agents That Use Tools
All other types of agents in the agentic workflow use tools. Most LLMs nowadays are equipped with this useful capacity. Since I described the bare metal agent above, I will describe the tool-using agent next, since it is the foundation for much to follow.
LLMs generate string data through a sequence-to-sequence map. In chat applications as well as in the job ad quality extractor, the string data is (mostly) text.
But the string data can also be an array of function arguments. For example, if I have an executable function, add, that adds two integer variables, a and b, and returns their sum, then the string data to run add could be:
{
"name": "add",
"input": {
"a": "2",
"b": "2"
}
}
So if the LLM outputs this string of function arguments, it can in code lead to the function call add(a=2, b=2).
The question is: how should the LLM be instructed such that it knows when and how to generate string data of this kind and specific syntax?
Alongside the AgentBareMetal agent, I define another agent type, which also inherits the Agent base class:
This differs from the bare metal agent in two regards:
- self.tools is a list created during instantiation.
- tool_return is created during execution by invoking a function obtained from a registry, registry_tool_name_2_func.
The former object contains the data instructing the Anthropic LLMs on the format of the string data it can generate as input arguments to different tools. The latter object comes about through the execution of the tool, given the LLM-generated string data.
The tools_cv_data file contains a JSON string formatted to define a function interface (but not the function itself). The string has to conform to a very specific schema for the Anthropic LLM to understand it. A snippet of this JSON string is:
From the specification above we can tell that if, for example, the initialization of AgentToolInvokeReturn includes the string biography in the tools argument, then the Anthropic LLM will be instructed that it can generate a function argument string to a function called create_biography. What kind of data to include in each argument is left to the LLM to figure out from the description fields in the JSON string. These descriptions are therefore mini-prompts, which guide the LLM in its sense-making.
The function that is associated with this specification I implement through the following two definitions.
In short, the tool name create_biography is associated with the class builder function Biography.build, which creates and returns an instance of the data class Biography.
Note that the attributes of the data class are perfectly mirrored in the JSON string that is added to the self.tools variable of the agent. That implies that the strings returned from the Anthropic LLM will fit perfectly into the class builder function for the data class.
To put it all together, take a closer look at the inner loop of the run method of AgentToolInvokeRetur shown again below:
for response_message in response.content:
assert isinstance(response_message, ToolUseBlock)
tool_name = response_message.name
func_kwargs = response_message.input
tool_id = response_message.id
tool = registry_tool_name_2_func.get(tool_name)
try:
tool_return = tool(**func_kwargs)
except Exception:
...
The steps are:
- The response from the Anthropic LLM is checked to be a string of function arguments, not ordinary text.
- The name of the tool (e.g. create_biography), the string of function arguments and a unique tool use id are gathered.
- The executable tool is retrieved from the registry (e.g. Biography.build).
- The function is executed with the string function arguments (checking for errors)
Once we have the output from the tool, we should decide what to do with it. Some applications integrate the tool outputs into the messages and execute another request to the LLM API. However, in the current application, I build agents that generate data objects, specifically subclasses of CVData. Hence, I design the agent to invoke the tool, and then simply return its output — hence the class name AgentToolInvokeReturn.
It is on this foundation I build agents which create the constrained data structures I want to be part of the CV.
Structured CV Data Extractor Agents
The class diagram for the agent that generates structured biography data is shown below. It has much in common with the previous class diagram for the agent that extracted the qualities from job ads.
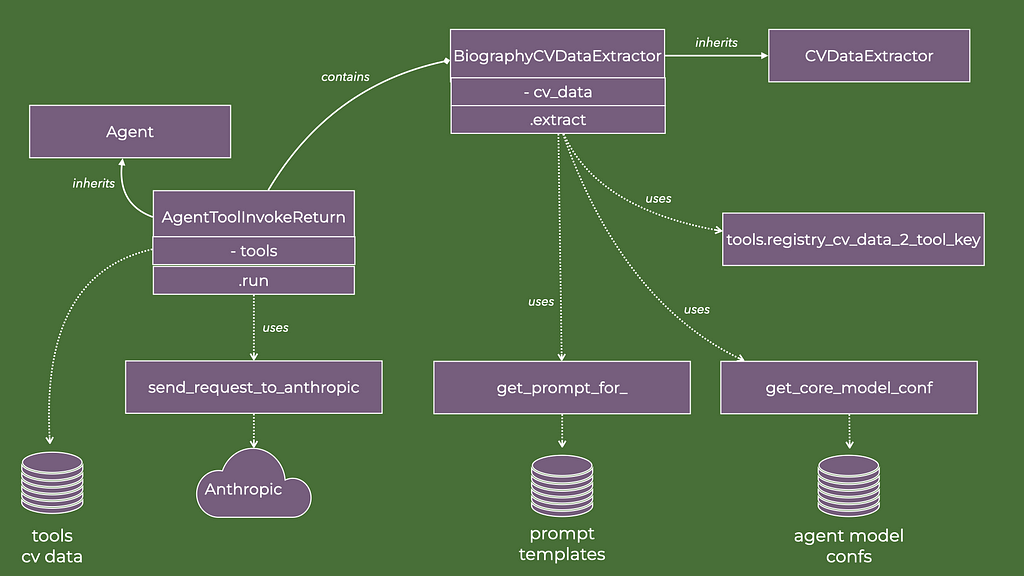
In code:
Two distinctions to the previous agent JobAdQualityExtractor:
- The tool names are retrieved as a function of the class attribute cv_data (line 47 in the snippet above). So when the agent with tools is instantiated, the sequence of tool names is given by a registry that associates a type of CV data (e.g. Biography) with the key used in the tools_cv_data JSON string described above, e.g. biography.
- The prompt for the agent is rendered with variables (lines 48–52). Recall the use of Jinja templates above. This enables the injection of the relevant qualities of the job ad and a target number of words to be used in the “about me” section. The specific template for the biography agent is:

That means as it is instantiated, the agent is made aware of the job ad it should tailor its text output to.
So when it receives the raw text data, it performs the instruction and returns an instance of the data class Biography. With identical reasons and similar software design, I generate additional extractor agents and CV data classes and tools definitions:
class EducationCVDataExtractor(CVDataExtractor):
cv_data = Educations
def __init__(self):
# <truncated>
class EmploymentCVDataExtractor(CVDataExtractor):
cv_data = Employments
def __init__(self):
# <truncated>
class SkillsCVDataExtractor(CVDataExtractor):
cv_data = Skills
def __init__(self):
# <truncated>
We can now go up a level in the abstractions. With extractor agents in place, they should be joined to the raw data from which to extract, summarize, rewrite and distill the CV data content.
Orchestration of Data Retrieval and Extraction
The part of the data diagram to explain next is the highlighted part.
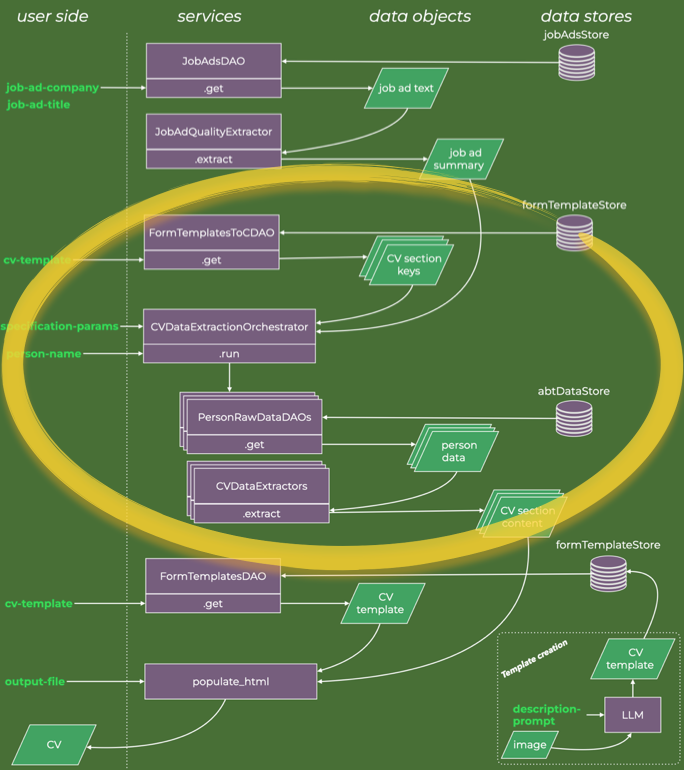
In principle, we can give the extractor agents access to all possible text we have for the person we are making the CV for. But that means the agent has to process a great deal of data irrelevant to the specific section it is focused on, e.g. formal educational details are hardly found in personal stream-of-consciousness blogging.
This is where important questions of retrieval and search usually enter the design considerations of LLM-powered applications.
Do we try to find the relevant raw data to apply our agents to, or do we throw all we have into the large context window and let the LLM sort out the retrieval question? Many have had their say on the matter. It is a worthwhile debate because there is a lot of truth in the below statement:
For my application, I will keep it simple — retrieval and search are saved for another day.
Therefore, I will work with semi-structured raw data. While we have a general understanding of the content of the respective documents, internally they consist mostly of unstructured text. This scenario is common in many real-world cases where useful information can be extracted from the metadata on a file system or data lake.
The first piece in the retrieval puzzle is the data access object (DAO) for the template table of contents. At its core, that is a JSON string like this:
It associates the name of a CV template, e.g. single_column_0, with a list of required data sections — the CVData data classes described in an earlier section.
Next, I encode which raw data access object should go with which CV data section. In my example, I have a modest collection of raw data sources, each accessible through a DAO, e.g. PersonsEmploymentDAO.
_map_extractor_daos: Dict[str, Tuple[Type[DAO]]] = {
f'{EducationCVDataExtractor.cv_data.__name__}': (PersonsEducationDAO,),
f'{EmploymentCVDataExtractor.cv_data.__name__}': (PersonsEmploymentDAO,),
f'{BiographyCVDataExtractor.cv_data.__name__}': (PersonsEducationDAO, PersonsEmploymentDAO, PersonsMusingsDAO),
f'{SkillsCVDataExtractor.cv_data.__name__}': (PersonsEducationDAO, PersonsEmploymentDAO, PersonsSkillsDAO),
}
"""Map CV data types to DAOs that provide raw data for the CV data extractor agents
This allows for a pre-filtering of raw data that are passed to the extractors. For example,
if the extractor is tailored to extract education data, then only the education DAO is used.
This is strictly not needed since the Extractor LLM should be able to do the filtering itself,
though at a higher token cost.
"""
Note in this code that the Biography and Skills CV data are created from several raw data sources. These associations are easily modified if additional raw data sources become available — append the new DAO to the tuple — or made configurable at runtime.
It is then a matter of matching the raw data and the CV data extractor agents for each required CV section. That is the data flow that the orchestrator implements. The image below is a zoomed-in data flow diagram for the CVDataExtractionOrchestrator execution.
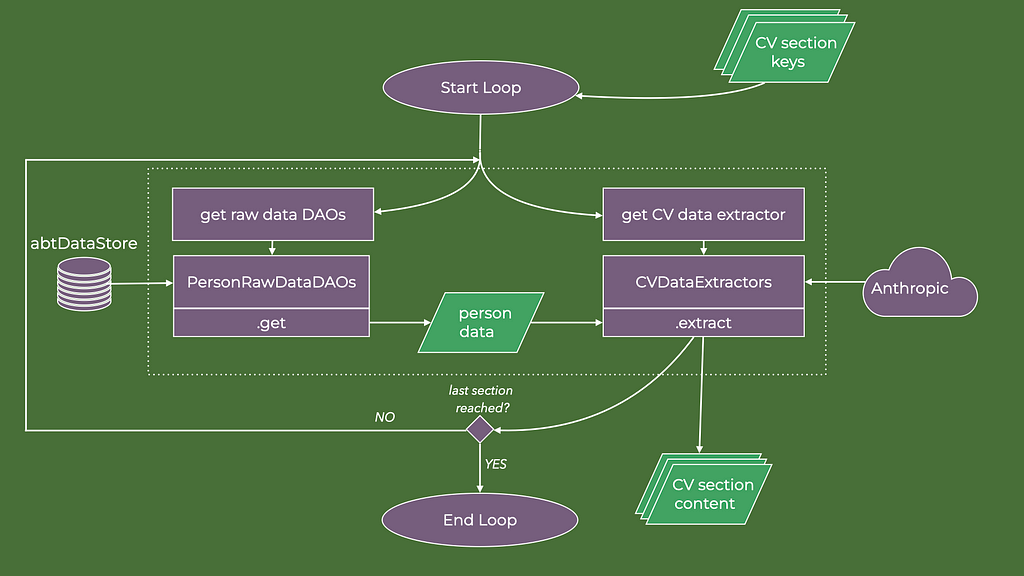
In code, the orchestrator is as follows:
And putting it all together in the script make_cv we have:
# Step 2: Ascertain the data sections required by the CV template and collect the data
cv_data_orchestrator = CVDataExtractionOrchestrator(
client=anthropic_client,
relevant_qualities=ad_qualities,
n_words_employment=n_words_employment,
n_words_education=n_words_education,
n_skills=n_skills,
n_words_about_me=n_words_about_me,
)
template_required_cv_data = FormTemplatesToCDAO().get(cv_template, 'required_cv_data_types')
cv_data = {}
for required_cv_data in template_required_cv_data:
cv_data.update(cv_data_orchestrator.run(
cv_data_type=required_cv_data,
data_key=person_name
))
It is within the orchestrator therefore that the calls to the Anthropic LLMs take place. Each call is done with a programmatically created instruction prompt, typically including the job ad summary, some parameters of how wordy the CV sections should be, plus the raw data, keyed on the name of the person.
The loop yields a collection of structured CV data class instances once all the agents that use tools have concluded their tasks.
Interlude: None, <UNKNOWN>, “missing”
The Anthropic LLMs are remarkably good at matching their generated content to the output schema required to build the data classes. For example, I do not sporadically get a phone number in the email field, nor are invalid keys dreamt up, which would break the build functions of the data classes.
But when I ran tests, I encountered an imperfection.
Look again at how the Biography CV data is defined:
If for example, the LLM does not find a GitHub URL in a person’s raw data, then it is permissible to return None for that field, since that attribute in the data class is optional. That is how I want it to be since it makes the rendering of the final CV simpler (see below).
But the LLMs regularly return a string value instead, typically ‘<UNKNOWN>’. To a human observer, there is no ambiguity about what this means. It is not a hallucination in that it is a fabrication that looks real yet is without basis in the raw data.
However, it is an issue for a rendering algorithm that uses simple conditional logic, such as the following in a Jinja template:
<div class="contact-info">
{{ biography.email }}
{% if biography.linkedin_url %} — <a href="{{ biography.linkedin_url }}">LinkedIn</a>{% endif %}
{% if biography.phone %} — {{ biography.phone }}{% endif %}
{% if biography.github_url %} — <a href="{{ biography.github_url }}">GitHub</a>{% endif %}
{% if biography.blog_url %} — <a href="{{ biography.blog_url }}">Blog</a>{% endif %}
</div>
A problem that is semantically obvious to a human, but syntactically messy, is perfect for LLMs to deal with. Inconsistent labelling in the pre-LLM days caused many headaches and lengthy lists of creative string-matching commands (anyone who has done data migrations of databases with many free-text fields can attest to that).
So to deal with the imperfection, I create another agent that operates on the output of one of the other CV data extractor agents.
This agent uses objects described in previous sections. The difference is that it takes a collection of CV data classes as input, and is instructed to empty any field “where the value is somehow labelled as unknown, undefined, not found or similar” (part of the full prompt).
A joint agent is created. It first executes the creation of biography CV data, as described earlier. Second, it executes the clear undefined agent on the output of the former agent to fix issues with any <UNKNOWN> strings.
This agent solves the problem, and therefore I use it in the orchestration.
Could this imperfection be solved with a different instruction prompt? Or would a simple string-matching fix be adequate? Maybe.
However, I use the simplest and cheapest LLM of Anthropic (haiku), and because of the modular design of the agents, it is an easy fix to implement and append to the data pipeline. The ability to construct joint agents that comprise multiple other agents is one of the design patterns advanced agentic workflows use.
Render With CV Data Objects Collection
The final step in the workflow is comparatively simple thanks to that we spent the effort to create structured and well-defined data objects. The contents of said objects are specifically placed within a Jinja HTML template through syntax matching.
For example, if biography is an instance of the Biography CV data class and env a Jinja environment, then the following code
template = env.get_template('test_template.html')
template.render(biography=biography)
would for test_template.html like
<body>
<h1>{{ biography.name }}</h1>
<div class="contact-info">
{{ biography.email }}
</div>
</body>
match the name and email attributes of the Biography data class and return something like:
<body>
<h1>My N. Ame</h1>
<div class="contact-info">
[email protected]
</div>
</body>
The function populate_html takes all the generated CV Data objects and returns an HTML file using Jinja functionality.
In the script make_cv the third and final step is therefore:
# Step 3: Render the CV with data and template and save output
html = populate_html(
template_name=cv_template,
cv_data=list(cv_data.values()),
)
with open(output_file, 'w') as f:
f.write(html)
This completes the agentic workflow. The raw data has been distilled, the content put inside structured data objects that mirror the information design of standard CVs, and the content rendered in an HTML template that encodes the style choices.
What About the CV Templates — How to Make Them?
The CV templates are Jinja templates of HTML files. Any tool that can create and edit HTML files can therefore be used to create a template. As long as the variable naming conforms to the names of the CV data classes, it will be compatible with the workflow.
So for example, the following part of a Jinja template would retrieve data attributes from an instance of the Employments CV data class, and create a list of employments with descriptions (generated by the LLMs) and data on duration (if available):
<h2>Employment History</h2>
{% for employment in employments.employment_entries %}
<div class="entry">
<div class="entry-title">
{{ employment.title }} at {{ employment.company }} ({{ employment.start_year }}{% if employment.end_year %} - {{ employment.end_year }}{% endif %}):
</div>
{% if employment.description %}
<div class="entry-description">
{{ employment.description }}
</div>
{% endif %}
</div>
{% endfor %}
I know very little about front-end development — even HTML and CSS are rare in the code I’ve written over the years.
I decided therefore to use LLMs to create the CV templates. After all, this is a task in which I seek to map an appearance and design sensible and intuitive to a human observer to a string of specific HTML/Jinja syntax — a kind of task LLMs have proven quite apt at.
I chose not to integrate this with the agentic workflow but appended it in the corner of the data flow diagram as a useful appendix to the application.
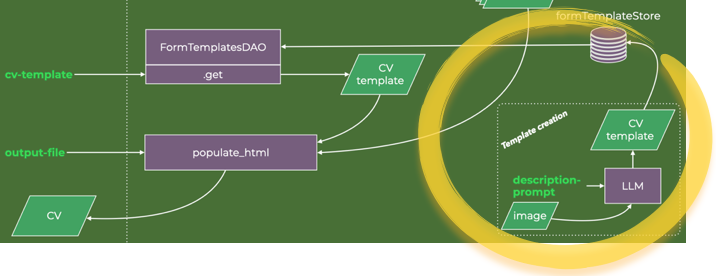
I used Claude, the chat interface to Anthropic’s Sonnet LLM. I provided Claude with two things: an image and a prompt.
The image is a crude outline of a single-column CV I cook up quickly using a word processor and then screen-dump.

The prompt I give is fairly lengthy. It consists of three parts.
First, a statement of what I wish to accomplish and what information I will provide Claude as Claude executes the task.
Part of the prompt of this section reads:
I wish to create a Jinja2 template for a static HTML page. The HTML page is going to present a CV for a person. The template is meant to be rendered with Python with Python data structures as input.
Second, a verbal description of the layout. In essence, a description of the image above, top to bottom, with remarks about relative font sizes, the order of the sections etc.
Third, a description of the data structures that I will use to render the Jinja template. In part, this prompt reads as shown in the image below:

The prompt continues listing all the CV data classes.
To a human interpreter, who is knowledgeable in Jinja templating, HTML and Python data classes, this information is sufficient to enable matching the semantic description of where to place the email in the layout to the syntax {{ biography.email }} in the HTML Jinja template, and the description of where to place the LinkedIn profile URL (if available) in the layout to the syntax {% if biography.linkedin_url %} <a href=”{{ biography.linkedin_url }}”>LinkedIn</a>{% endif } and so on.
Claude executes the task perfectly — no need for me to manually edit the template.
I ran the agent workflow with the single-column template and synthetic data for the persona Gregor Samsa (see more about him later).
make_cv --job-ad-company "epic resolution index"
--job-ad-title "luxury retail lighting specialist"
--cv-template single_column_0
--person-name "gregor samsa"
--output-file ../generated_output/cv_single_column_0.html
--n-words-employment 50 --n-skills 8
The output document:

A decent CV. But I wanted to create variations and see what Claude and I could cook up.
So I created another prompt and screen dump. This time for a two-column CV. The crude outline I drew up:
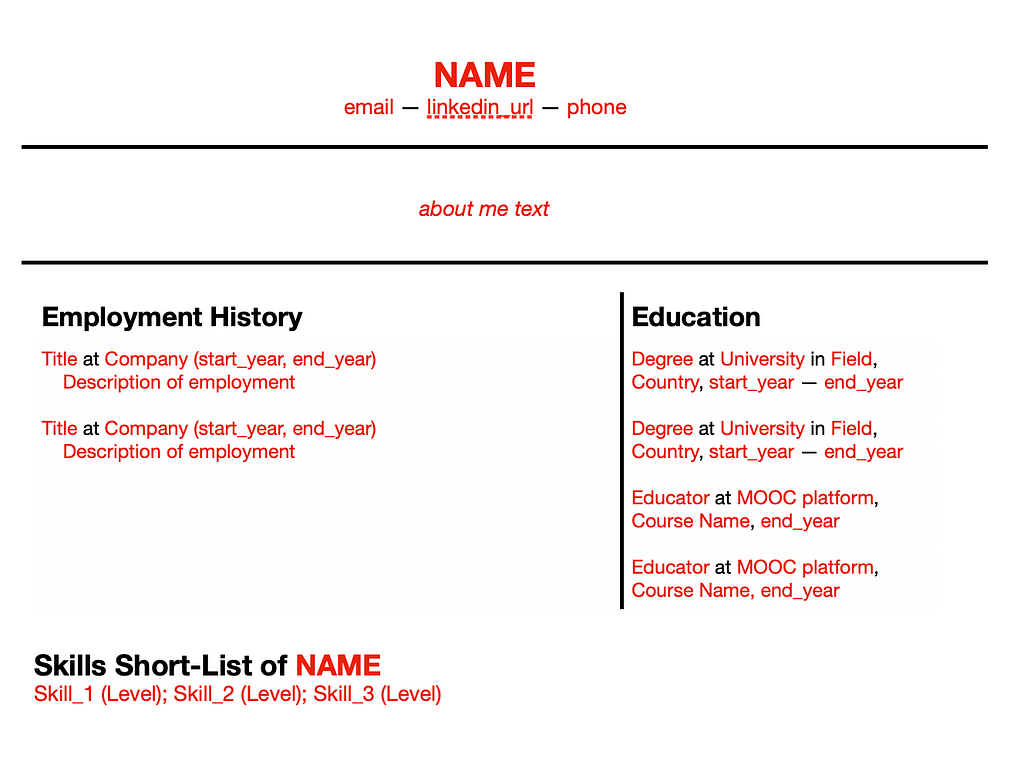
I reused the prompt for the single column, only changing the second part where I in words describe the layout.
It worked perfectly again.
The styling, though, was a bit too bland for my taste. So as a follow-up prompt to Claude, I wrote:
Love it! Can you redo the previous task but with one modification: add some spark and colour to it. Arial font, black and white is all a bit boring. I like a bit of green and nicer looking fonts. Wow me! Of course, it should be professional-looking still.
Had Claude responded with an annoyed comment that I must be a bit more specific, I would have empathized (in some sense of that word). Rather, Claude’s generative juices flowed and a template was created that when rendered looked like this:
Nice!
Notably, the fundamental layout in the crude outline is preserved in this version: the placement of sections, the relative width of the two columns, and the lack of descriptions in the education entries etc. Only the style changed and was consistent with the vague specifications given. Claude’s generative capacities filled in the gaps quite well in my judgment.
I next explored if Claude could keep the template layout and content specifications clear and consistent even when I dialled up the styling to eleven. So I wrote next to Claude:
Amazing. But now I want you to go all out! We are talking early 1990s web page aesthetic, blinking stuff, comic sans in the oddest places, weird and crazy colour contrasts. Full speed ahead, Claude, have some fun.
The result was glorious.

Who is this Gregor Samsa, what a free-thinker and not a trace of anxiety — hire the guy!
Even with this extreme styling, the specified layout is mostly preserved, and the text content as well. With a detailed enough prompt, Claude can seemingly create functional and nicely styled templates that can be part of the agentic workflow.
What About the Text Output?
Eye-catching style and useful layout aside, a CV must contain abbreviated text that succinctly and truthfully shows the fit between person and position.
To explore this I created synthetic data for a person Gregor Samsa — educated in Central Europe, working in lighting sales, with a general interest in entomology. I generated raw data on Gregor’s past and present, some from my imagination, and some from LLMs. The details are not important. The key point is that the text is too muddled and unwieldy to be copy-pasted into a CV. The data has to be found (e.g. the email address appears within one of Gregor’s general musings), summarized (e.g. the description of Gregor’s PhD work is very detailed), distilled and tailored to the relevant position (e.g. which skills are worth bringing to the fore), and all reduced to one or two friendly sentences in an about me section.
The text outputs were very well made. I had Anthropic’s most advanced and eloquent model, Sonnet, write the About Me sections. The tone rang true.
In my tests, I found no outright hallucinations. However, the LLMs had taken certain liberties in the Skills section.
Gregor is described in the raw data as working and studying in Prague and Vienna mostly with some online classes from English-language educators. In one generated CV, language skills in Czech, German and English were listed despite that the raw data does not explicitly declare such knowledge. The LLM had made a reasonable inference of skills. Still, these were not skills abstracted from the raw data alone.
All code and synthetic data are available in my GitHub repo. I used Python 3.11 to run it, and as long as you have an API key to Anthropic (assumed by the script to be stored in the environment variable ANTHROPIC_API_KEY), you can run and explore the application — and of course, to the best of my understanding, there are no errors, but I make no guarantees.
This tutorial has shown one way to use generative AI, made a case for useful constraints in generative applications, and shown how it all can be implemented working directly with the Anthropic APIs. Though CV creation is not an advanced task, the principles and designs I covered can be a foundation for other non-chat applications with greater value and complexity.
Happy building!
All images, graphs and code created by the Author.
AI, Write and Style My CV was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
AI, Write and Style My CV