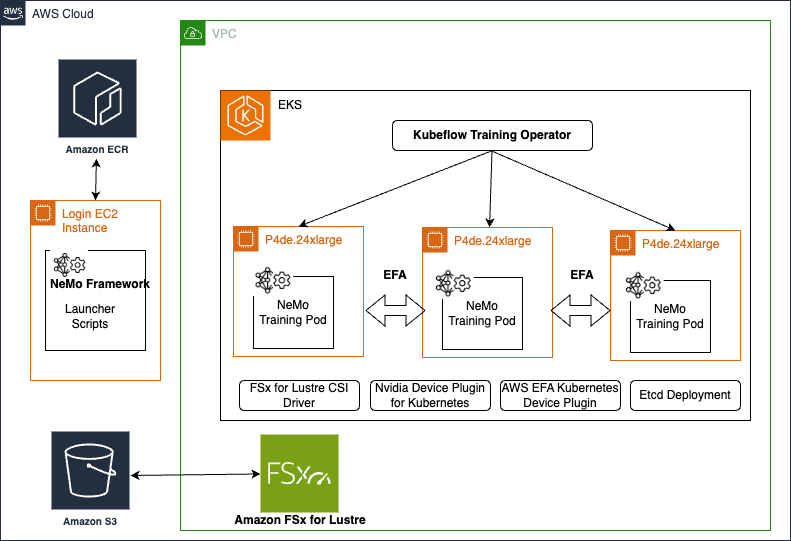
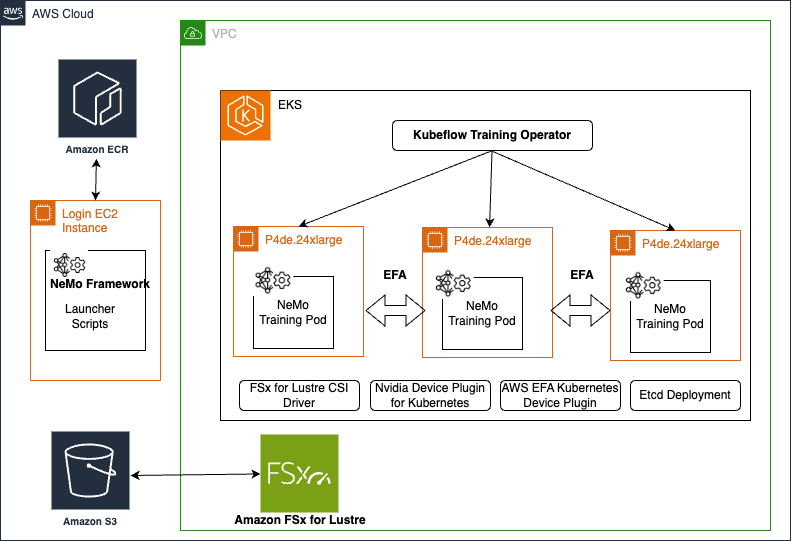
In today’s rapidly evolving landscape of artificial intelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Without a structured framework, the process can become prohibitively time-consuming, costly, and complex. Enterprises struggle with managing […]
Originally appeared here:
Accelerate your generative AI distributed training workloads with the NVIDIA NeMo Framework on Amazon EKS