
An end-2-end empirical sharing of multi-step quantile forecasting with Tensorflow, NeuralForecast, and Zero-shot LLMs.
Content
- Short Introduction
- Data
- Build a Toy Version of Quantile Recurrent Forecaster
- Quantile Forecasting with the State-of-Art Models
- Zero-shot Quantile Forecast with LLMs
- Conclusion
Short Introduction
Quantile forecasting is a statistical technique used to predict different quantiles (e.g., the median or the 90th percentile) of a response variable’s distribution, providing a more comprehensive view of potential future outcomes. Unlike traditional mean forecasting, which only estimates the average, quantile forecasting allows us to understand the range and likelihood of various possible results.
Quantile forecasting is essential for decision-making in contexts with asymmetric loss functions or varying risk preferences. In supply chain management, for example, predicting the 90th percentile of demand ensures sufficient stock levels to avoid shortages, while predicting the 10th percentile helps minimize overstock and associated costs. This methodology is particularly advantageous in sectors such as finance, meteorology, and energy, where understanding distribution extremes is as critical as the mean.
Both quantile forecasting and conformal prediction address uncertainty, yet their methodologies differ significantly. Quantile forecasting directly models specific quantiles of the response variable, providing detailed insights into its distribution. Conversely, conformal prediction is a model-agnostic technique that constructs prediction intervals around forecasts, guaranteeing that the true value falls within the interval with a specified probability. Quantile forecasting yields precise quantile estimates, whereas conformal prediction offers broader interval assurances.
The implementation of quantile forecasting can markedly enhance decision-making by providing a sophisticated understanding of future uncertainties. This approach allows organizations to tailor strategies to different risk levels, optimize resource allocation, and improve operational efficiency. By capturing a comprehensive range of potential outcomes, quantile forecasting enables organizations to make informed, data-driven decisions, thereby mitigating risks and enhancing overall performance.
Data
To demonstrate the work, I chose to use the data from the M4 competition as an example. The data is under CC0: Public Domain license which can be accessed here. The data can also be loaded through datasetsforecast package:
# Install the package
pip install datasetsforecast
# Load Data
df, *_ = M4.load('./data', group='Weekly')
# Randomly select three items
df = df[df['unique_id'].isin(['W96', 'W100', 'W99'])]
# Define the start date (for example, "1970-01-04")
start_date = pd.to_datetime("1970-01-04")
# Convert 'ds' to actual week dates
df['ds'] = start_date + pd.to_timedelta(df['ds'] - 1, unit='W')
# Display the DataFrame
df.head()

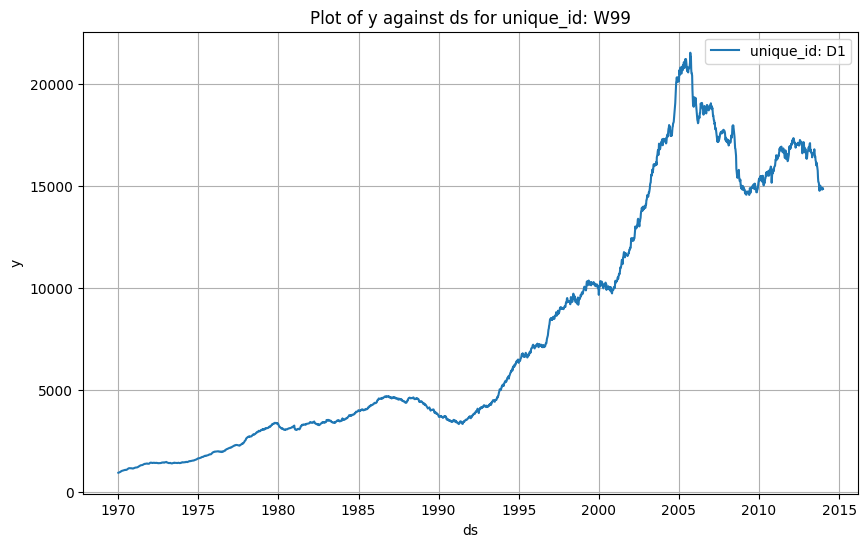
The original data contains over 300 unique time series. To demonstrate, I randomly selected three time series: W96, W99, and W100, as they all have the same history length. The original timestamp is masked as integer numbers (i.e., 1–2296), I manually converted it back to normal date format with the first date to be January 4th, 1970. The following figure is a preview of W99:
Build a Toy Version of Quantile Recurrent Forecaster
First, let’s build a quantile forecaster from scratch to understand how the target data flows through the pipeline and how the forecasts are generated. I picked the idea from the paper A Multi-Horizon Quantile Recurrent Forecaster by Wen et al. The authors proposed a Multi-Horizon Quantile Recurrent Neural Network (MQ-RNN) framework that combines Sequence-to-Sequence Neural Networks, Quantile Regression, and Direct Multi-Horizon Forecasting for accurate and robust multi-step time series forecasting. By leveraging the expressiveness of neural networks, the nonparametric nature of quantile regression, and a novel training scheme called forking-sequences, the model can effectively handle shifting seasonality, known future events, and cold-start situations in large-scale forecasting applications.
We cannot reproduce everything in this short blog, but we can try to replicate part of it using the TensorFlow package as a demo. If you are interested in the implementation of the paper, there is an ongoing project that you can leverage: MQRNN.
Let’s first load the necessary package and define some global parameters. We will use the LSTM model as the core, and we need to do some preprocessing on the data to obtain the rolling windows before fitting. The input_shape is set to (104, 1) meaning we are using two years of data for each training window. In this walkthrough, we will only look into an 80% confidence interval with the median as the point forecast, which means the quantiles = [0.1, 0.5, 0.9]. We will use the last 12 weeks as a test dataset, so the output_steps or horizon is equal to 12 and the cut_off_date will be ‘2013–10–13’.
# Install the package
pip install tensorflow
# Load the package
from sklearn.preprocessing import StandardScaler
from datetime import datetime
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense, concatenate, Layer
# Define Global Parameters
input_shape = (104, 1)
quantiles = [0.1, 0.9]
output_steps = 12
cut_off_date = '2013-10-13'
tf.random.set_seed(20240710)
Next, let’s convert the data to rolling windows which is the desired input shape for RNN-based models:
# Preprocess The Data
def preprocess_data(df, window_size = 104, forecast_horizon = 12):
# Ensure the dataframe is sorted by item and date
df = df.sort_values(by=['unique_id', 'ds'])
# List to hold processed data for each item
X, y, unique_id, ds = [], [], [], []
# Normalizer
scaler = StandardScaler()
# Iterate through each item
for key, group in df.groupby('unique_id'):
demand = group['y'].values.reshape(-1, 1)
scaled_demand = scaler.fit_transform(demand)
dates = group['ds'].values
# Create sequences (sliding window approach)
for i in range(len(scaled_demand) - window_size - forecast_horizon + 1):
X.append(scaled_demand[i:i+window_size])
y.append(scaled_demand[i+window_size:i+window_size+forecast_horizon].flatten())
unique_id.append(key)
ds.append(dates[i+window_size:i+window_size+forecast_horizon])
X = np.array(X)
y = np.array(y)
return X, y, unique_id, ds, scaler
Then we split the data into train, val, and test:
# Split Data
def split_data(X, y, unique_id, ds, cut_off_date):
cut_off_date = pd.to_datetime(cut_off_date)
val_start_date = cut_off_date - pd.Timedelta(weeks=12)
train_idx = [i for i, date in enumerate(ds) if date[0] < val_start_date]
val_idx = [i for i, date in enumerate(ds) if val_start_date <= date[0] < cut_off_date]
test_idx = [i for i, date in enumerate(ds) if date[0] >= cut_off_date]
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
X_test, y_test = X[test_idx], y[test_idx]
train_unique_id = [unique_id[i] for i in train_idx]
train_ds = [ds[i] for i in train_idx]
val_unique_id = [unique_id[i] for i in val_idx]
val_ds = [ds[i] for i in val_idx]
test_unique_id = [unique_id[i] for i in test_idx]
test_ds = [ds[i] for i in test_idx]
return X_train, y_train, X_val, y_val, X_test, y_test, train_unique_id, train_ds, val_unique_id, val_ds, test_unique_id, test_ds
The authors of the MQRNN utilized both horizon-specific local context, essential for temporal awareness and seasonality mapping, and horizon-agnostic global context to capture non-time-sensitive information, enhancing the stability of learning and the smoothness of generated forecasts. To build a model that sort of reproduces what the MQRNN is doing, we need to write a quantile loss function and add layers that capture local context and global context. I added an attention layer to it to show you how the attention mechanism can be included in such a process:
# Attention Layer
class Attention(Layer):
def __init__(self, units):
super(Attention, self).__init__()
self.W1 = Dense(units)
self.W2 = Dense(units)
self.V = Dense(1)
def call(self, query, values):
hidden_with_time_axis = tf.expand_dims(query, 1)
score = self.V(tf.nn.tanh(self.W1(values) + self.W2(hidden_with_time_axis)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
# Quantile Loss Function
def quantile_loss(q, y_true, y_pred):
e = y_true - y_pred
return tf.reduce_mean(tf.maximum(q*e, (q-1)*e))
def combined_quantile_loss(quantiles, y_true, y_pred, output_steps):
losses = [quantile_loss(q, y_true, y_pred[:, i*output_steps:(i+1)*output_steps]) for i, q in enumerate(quantiles)]
return tf.reduce_mean(losses)
# Model architecture
def create_model(input_shape, quantiles, output_steps):
inputs = Input(shape=input_shape)
lstm1 = LSTM(256, return_sequences=True)(inputs)
lstm_out, state_h, state_c = LSTM(256, return_sequences=True, return_state=True)(lstm1)
context_vector, attention_weights = Attention(256)(state_h, lstm_out)
global_context = Dense(100, activation = 'relu')(context_vector)
forecasts = []
for q in quantiles:
local_context = concatenate([global_context, context_vector])
forecast = Dense(output_steps, activation = 'linear')(local_context)
forecasts.append(forecast)
outputs = concatenate(forecasts, axis=1)
model = Model(inputs, outputs)
model.compile(optimizer='adam', loss=lambda y, f: combined_quantile_loss(quantiles, y, f, output_steps))
return model
Here are the plotted forecasting results:


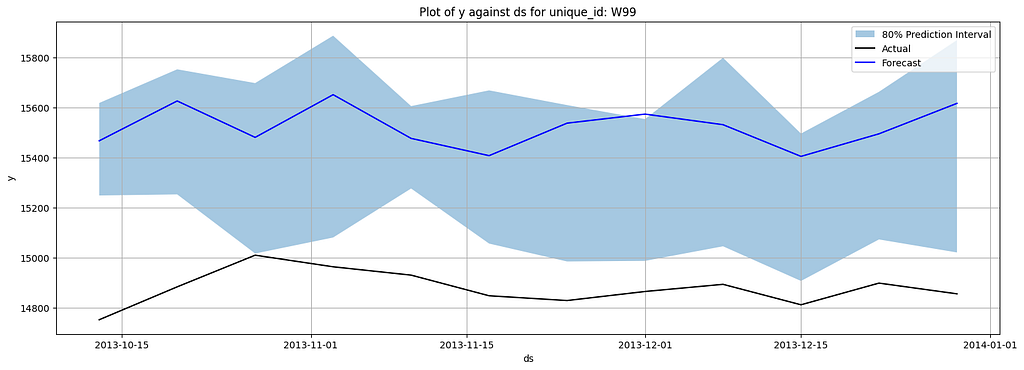
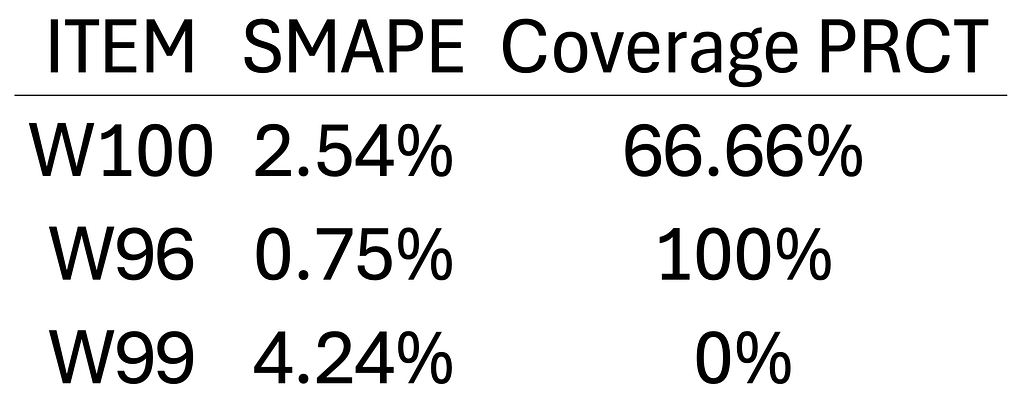
We also evaluated the SMAPE for each item, as well as the percentage coverage of the interval (how much actual was covered by the interval). The results are as follows:
This toy version can serve as a good baseline to start with quantile forecasting. The distributed training is not configured for this setup nor the model architecture is optimized for large-scale forecasting, thus it might suffer from speed issues. In the next section, we will look into a package that allows you to do quantile forecasts with the most advanced deep-learning models.
Quantile Forecasting with the SOTA Models
The neuralforecast package is an outstanding Python library that allows you to use most of the SOTA deep neural network models for time series forecasting, such as PatchTST, NBEATs, NHITS, TimeMixer, etc. with easy implementation. In this section, I will use PatchTST as an example to show you how to perform quantile forecasting.
First, load the necessary modules and define the parameters for PatchTST. Tuning the model will require some empirical experience and will be project-dependent. If you are interested in getting the potential-optimal parameters for your data, you may look into the auto modules from the neuralforecast. They will allow you to use Ray to perform hyperparameter tuning. And it is quite efficient! The neuralforecast package carries a great set of models that are based on different sampling approaches. The ones with the base_window approach will allow you to use MQLoss or HuberMQLoss, where you can specify the quantile levels you are looking for. In this work, I picked HuberMQLoss as it is more robust to outliers.
# Install the package
pip install neuralforecast
# Load the package
from neuralforecast.core import NeuralForecast
from neuralforecast.models import PatchTST
from neuralforecast.losses.pytorch import HuberMQLoss, MQLoss
# Define Parameters for PatchTST
PARAMS = {'input_size': 104,
'h': output_steps,
'max_steps': 6000,
'encoder_layers': 4,
'start_padding_enabled': False,
'learning_rate': 1e-4,
'patch_len': 52, # Length of each patch
'hidden_size': 256, # Size of the hidden layers
'n_heads': 4, # Number of attention heads
'res_attention': True,
'dropout': 0.1, # Dropout rate
'activation': 'gelu', # Activation function
'dropout': 0.1,
'attn_dropout': 0.1,
'fc_dropout': 0.1,
'random_seed': 20240710,
'loss': HuberMQLoss(quantiles=[0.1, 0.5, 0.9]),
'scaler_type': 'standard',
'early_stop_patience_steps': 10}
# Get Training Data
train_df = df[df.ds<cut_off_date]
# Fit and predict with PatchTST
models = [PatchTST(**PARAMS)]
nf = NeuralForecast(models=models, freq='W')
nf.fit(df=train_df, val_size=12)
Y_hat_df = nf.predict().reset_index()
Here are plotted forecasts:
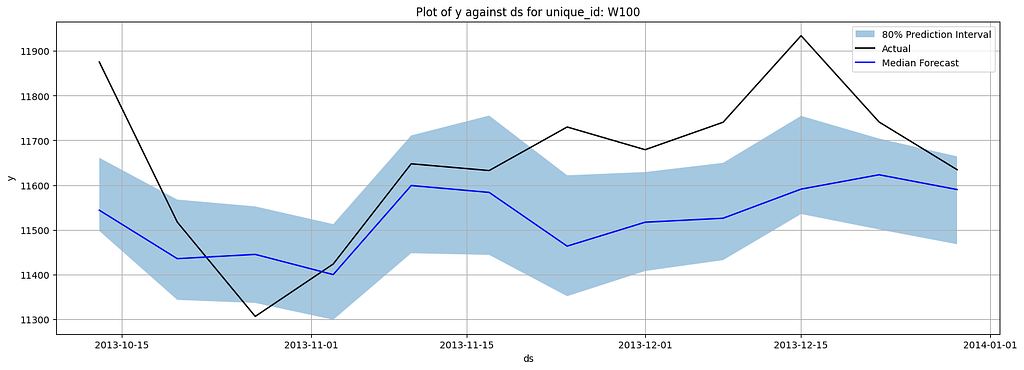
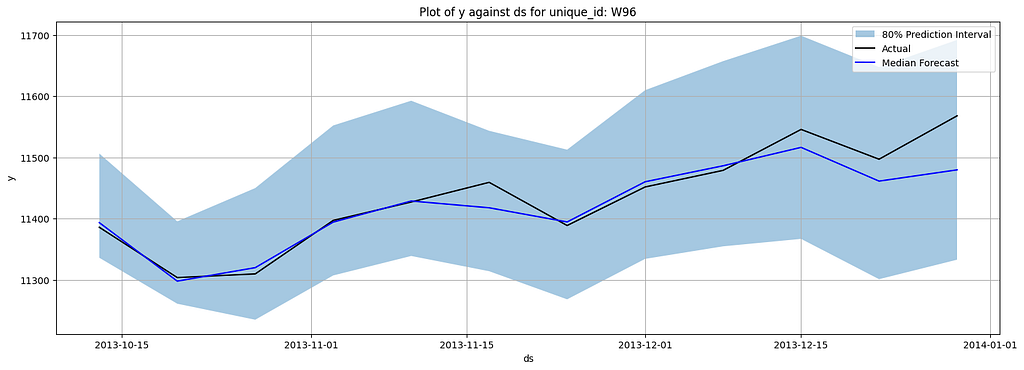

Here are the metrics:

Through the demo, you can see how easy to implement the model and how the performance of the model has been lifted. However, if you wonder if there are any easier approaches to do this task, the answer is YES. In the next section, we will look into a T5-based model that allows you to conduct zero-shot quantile forecasting.
Zero-shot Quantile Forecast with LLMs
We have been witnessing a trend where the advancement in NLP will also further push the boundaries for time series forecasting as predicting the next word is a synthetic process for predicting the next period’s value. Given the fast development of large language models (LLMs) for generative tasks, researchers have also started to look into pre-training a large model on millions of time series, allowing users to do zero-shot forecasts.
However, before we draw an equal sign between the LLMs and Zero-shot Time Series tasks, we have to answer one question: what is the difference between training a language model and training a time series model? It would be “tokens from a finite dictionary versus values from an unbounded.” Amazon recently released a project called Chronos which well handled the challenge and made the large time series model happen. As the authors stated: “Chronos tokenizes time series into discrete bins through simple scaling and quantization of real values. In this way, we can train off-the-shelf language models on this ‘language of time series,’ with no changes to the model architecture”. The original paper can be found here.
Currently, Chronos is available in multiple versions. It can be loaded and used through the autogluon API with only a few lines of code.
# Get Training Data and Transform
train_df = df[df.ds<cut_off_date]
train_df_chronos = TimeSeriesDataFrame(train_df.rename(columns={'ds': 'timestamp', 'unique_id': 'item_id', 'y': 'target'}))
# Zero-shot forecast with Chronos
predictor = TimeSeriesPredictor(prediction_length=output_steps, freq='W', quantile_levels = [0.1, 0.9]).fit(
train_df_chronos, presets="chronos_base",
random_seed = 20240710
)
Y_hat_df_chronos = predictor.predict(train_df_chronos).reset_index().rename(columns={'mean': 'Chronos',
'0.1': 'P10',
'0.9': 'P90',
'timestamp': 'ds',
'item_id': 'unique_id'})
Here are the plotted forecasts:
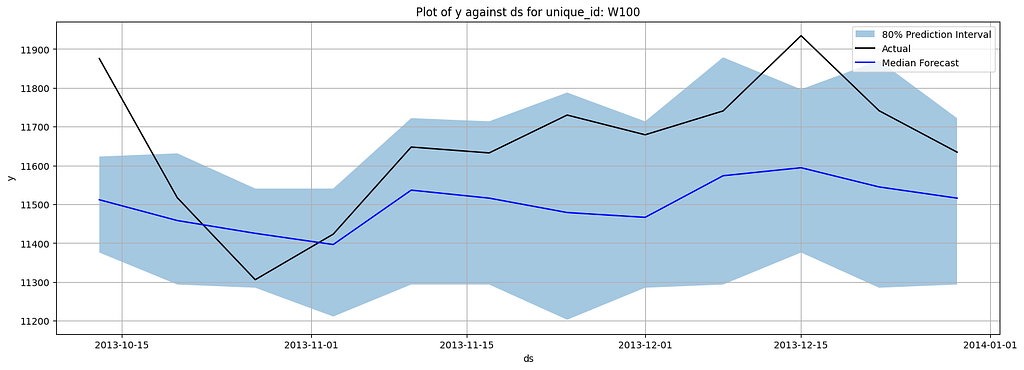
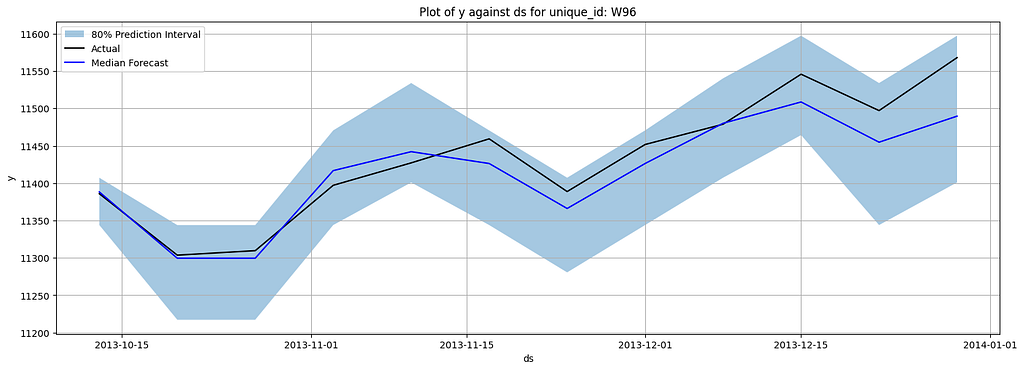
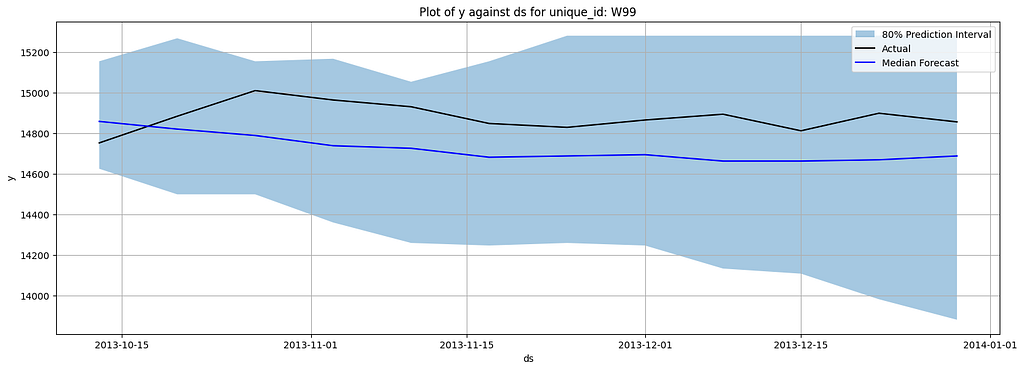
Here are the metrics:
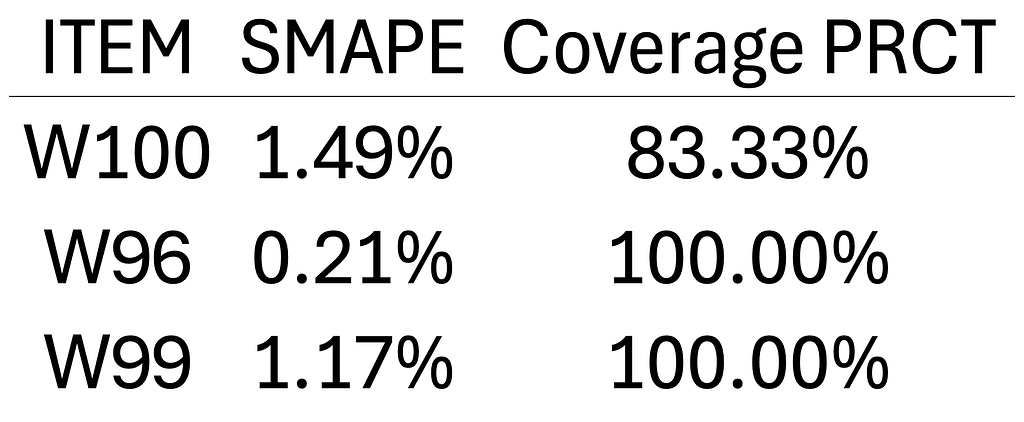
As you can see, Chronos showed a very decent performance compared to PatchTST. However, it does not mean it has surpassed PatchTST, since it is very likely that Chronos has been trained on M4 data. In their original paper, the authors also evaluated their model on the datasets that the model has not been trained on, and Chronos still yielded very comparable results to the SOTA models.
There are many more large time series models being developed right now. One of them is called TimeGPT which was developed by NIXTLA. The invention of this kind of model not only made the forecasting task easier, more reliable, and consistent, but it is also a good starting point to make reasonable guesses for time series with limited historical data.
Conclusion
From building a toy version of a quantile recurrent forecaster to leveraging state-of-the-art models and zero-shot large language models, this blog has demonstrated the power and versatility of quantile forecasting. By incorporating models like TensorFlow’s LSTM, NeuralForecast’s PatchTST, and Amazon’s Chronos, we can achieve accurate, robust, and computationally efficient multi-step time series forecasts. Quantile forecasting not only enhances decision-making by providing a nuanced understanding of future uncertainties but also allows organizations to optimize strategies and resource allocation. The advancements in neural networks and zero-shot learning models further push the boundaries, making quantile forecasting a pivotal tool in modern data-driven industries.
Note: All the images, numbers and tables are generated by the author. The complete code can be found here: Quantile Forecasting.
From Scratch to Deep Quantile Forecasting was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Scratch to Deep Quantile Forecasting
Go Here to Read this Fast! From Scratch to Deep Quantile Forecasting