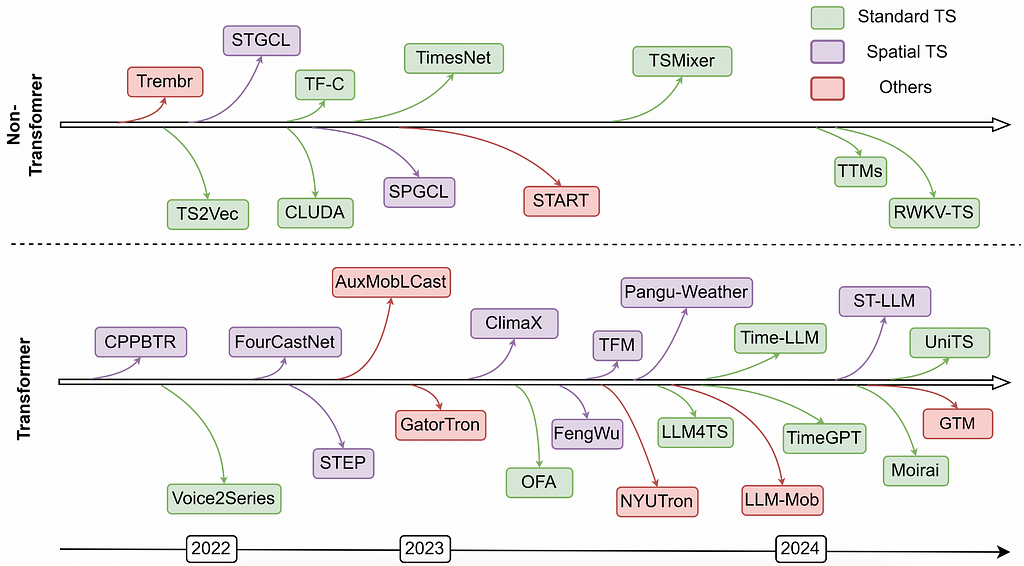
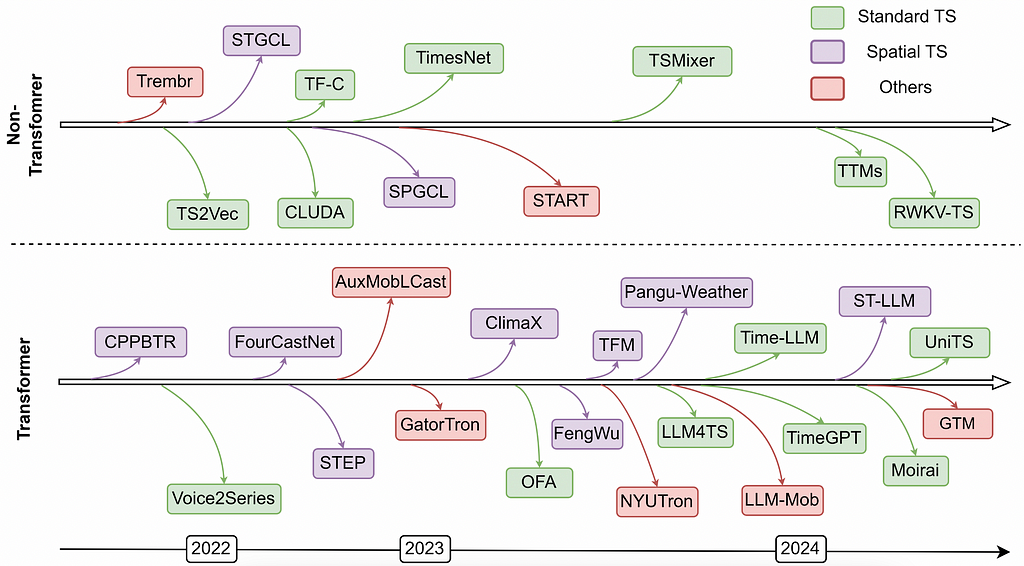
Harnessing the power of LLMs for time series modeling
Foundation models drive the recent advancements of computational linguistic and computer vision domains and achieve great success in Artificial Intelligence (AI). The key ideas toward a successful foundation model include:
- Gigantic-scale of data: The vast and diverse training data covers a comprehensive distribution, allowing the model to approximate any potential testing distribution.
- Transferability: The mechanisms of memorizing and recalling learned information, such as prompting [1] and self-supervised pre-training [2], enable the model to adapt to new tasks effectively.
Large Time Series Foundation Model (LTSM)
Following the success of foundation models in the computational linguistic domain, increasing research efforts are aiming to replicate this success in another type of sequential data: time series.
Similar to Large Language Models (LLMs), a large time series foundation model (LTSM) aims to learn from a vast and diverse set of time series data to make forecasts. The trained foundation model can then be fine-tuned for various tasks, such as outlier detection or time series classification.
Although the concept of a time series foundation model has been around for some time and various neural architectures (MLP, RNN, CNN) have been explored, none have achieved zero-shot prediction due to issues with data quantity and quality. More extensive efforts began after the success of LLMs, aiming to leverage the sequential information learned from natural language data for time series modeling.
Why can LLMs be used for time series data?
The major connection between language model and time series model is that the input data are all sequential data, where the main differences are the way that the data are encoded for the model for types of patterns and structures they aim to capture.
For large language models, words in an input sentence are encoded into a integer sequence through tokenization then transformed into a numerical vector through embedding lookup process.
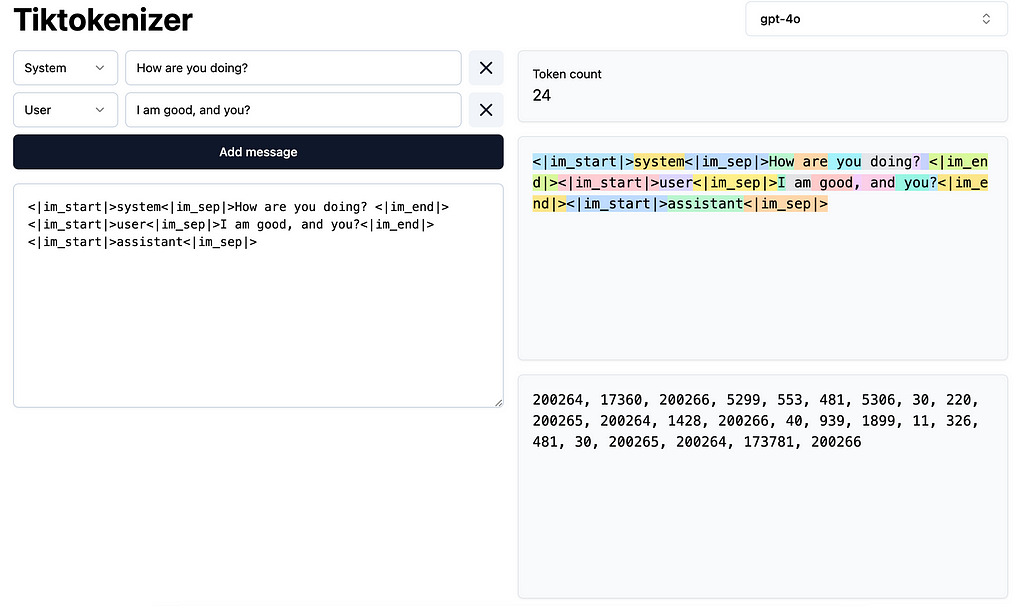
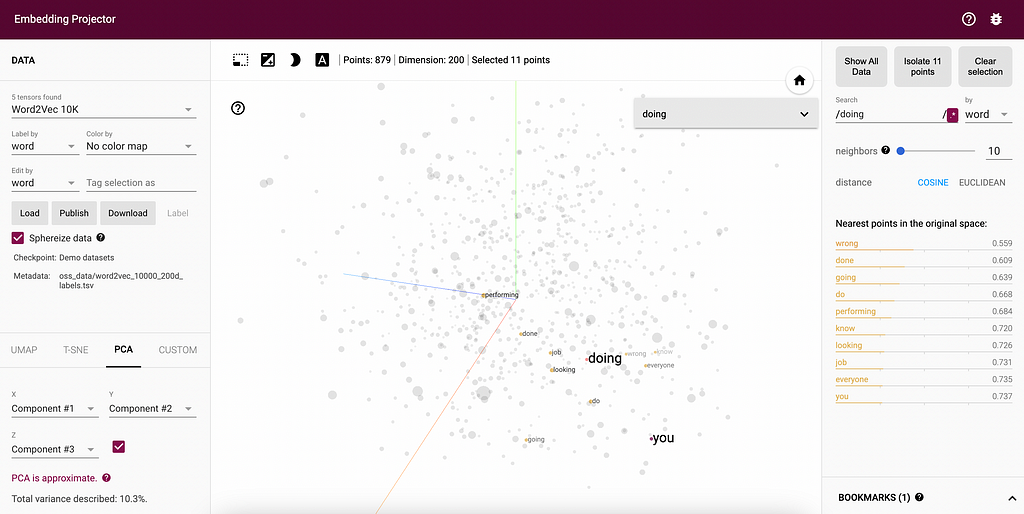
Similarly, a time series data can also be tokenized into a series of symbolic representations. The figure below illustrates an example of transforming a time series with 100 timestamps into a series with a length of 5, where each step in the series is represented by a 4-dimensional feature vector. The time series can be segmented with a sliding window and perform discretized for extracting statistical values (e.g., mean, std, min, max) to represent each window.
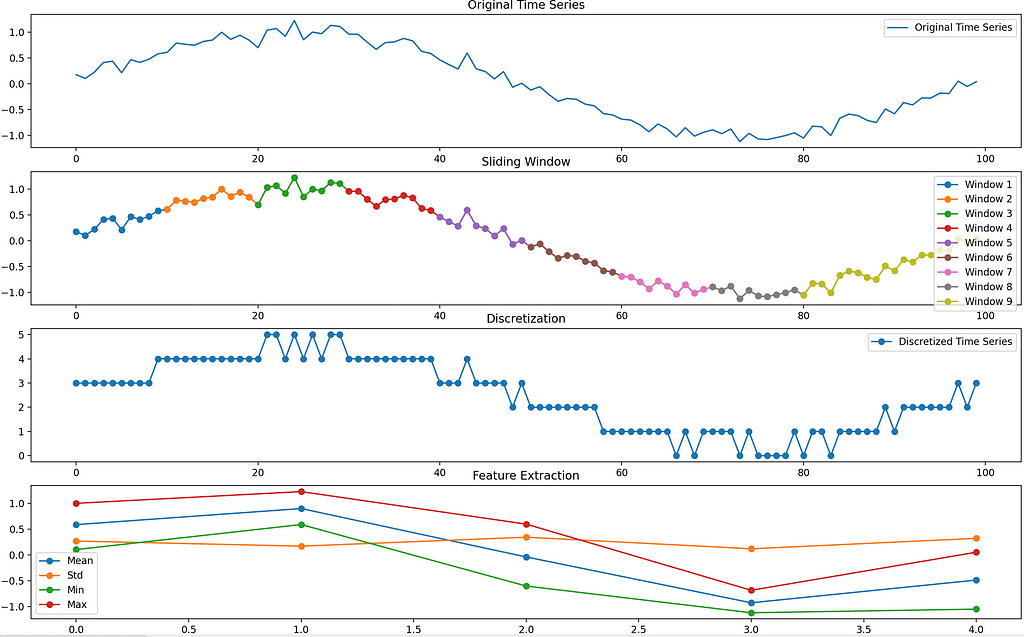
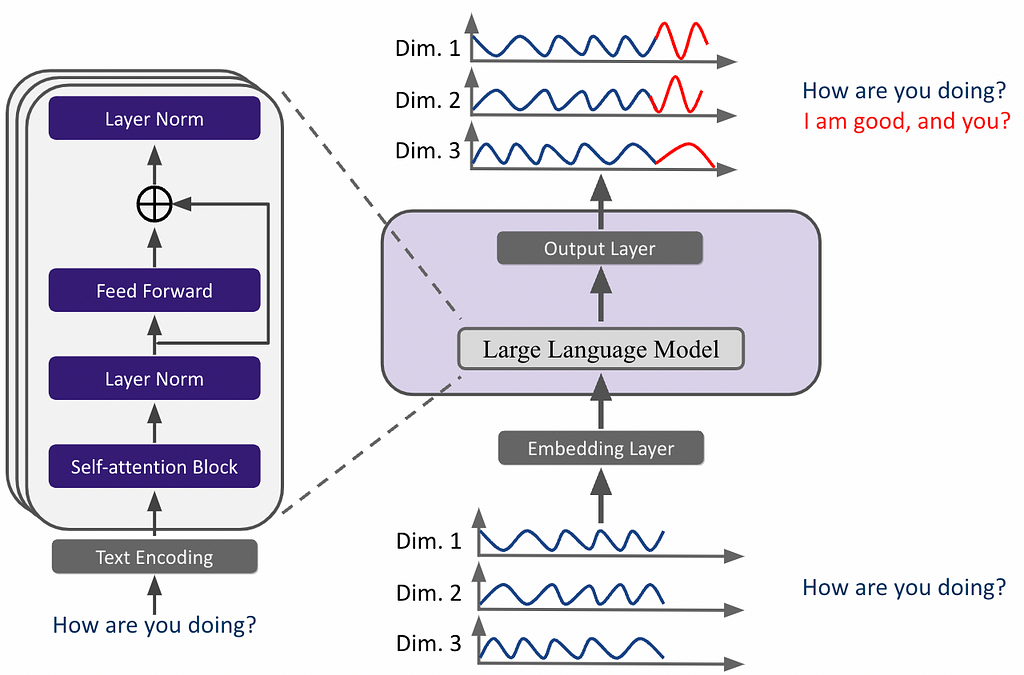
This way, a large language model trained on a comprehensive corpus can be viewed as analogous to a large time series model (LTSM) that has learned from extensive numerical patterns found in real-world data. Thus, a time series forecasting problem can be framed as a next-word prediction problem. The key challenge in achieving optimal performance and zero/few-shot forecasting lies in aligning the semantic information between time series tokens and natural language tokens.
How to re-program LLM for time series modeling
To tackle the challenge, researchers are investigating methodologies to align the information gap between time series and natural language from every perspective of training a large language model. The table below shows the component comparison for the two data types and representative works for each components.
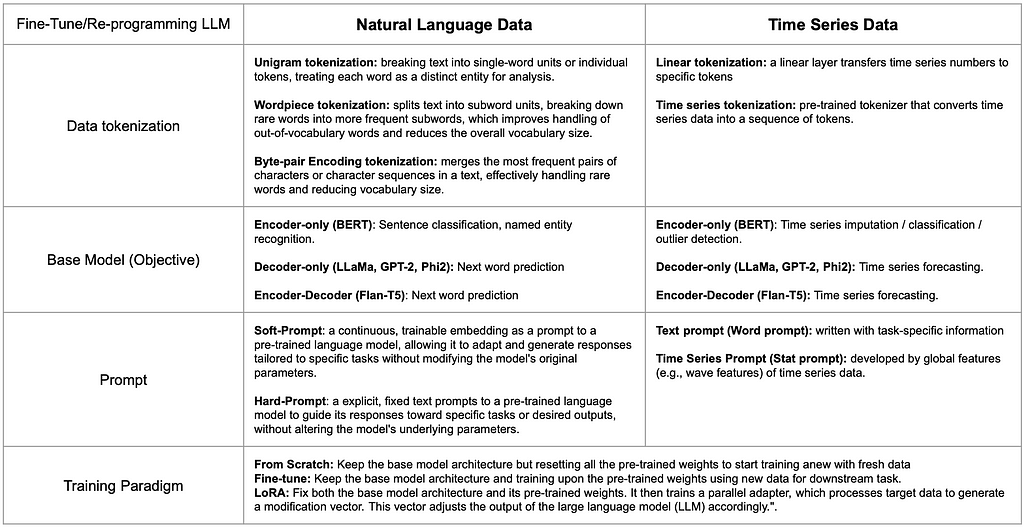
In general, re-programming a large language model (LLM) for time series modeling is similar to fine-tuning it for a specific domain. The process involves several key steps: tokenization, base model selection, prompt engineering, and defining the training paradigm.
Tokenizing time series data for an LLM can be achieved through symbolic representation. Instead of relying on manual discretization and heuristic feature extraction, one can use either a simple linear layer or a pre-trained tokenizer [3] to map segments of the time series data into tokens within a latent embedding space, allowing the tokenized time series to better adapt to the LLM.
The base model can be selected by drawing analogies between the target objectives of different architectures. For example, sentence classification can correspond to time series classification or outlier detection, while next word prediction can correspond to time series forecasting.
Prompting time series data can either rely on textual information about the data (e.g., dataset or task descriptions) or on extracting global statistical features from each time series to highlight the overall differences between different datasets.
The training paradigm for time series data generally follows similar approaches used in natural language processing. These include training from scratch using the same model architecture without pre-trained weights, fine-tuning on pre-trained weights, or training a parallel adapter (e.g., LoRA) to adapt the LLM to time series data. Each approach has different computational costs, which are not necessarily positively correlated with performance outcomes.
So, given the diverse choices at each step, how can we determine the best options to create a more generalizable model with optimal performance?
Understanding Different Design Choices in Training Large Time Series Models
To understanding the pros and cons of choices at each step, our recent paper LTSM-bundle studies the combinations of different choices on open-sourced benchmark datasets and provided an open sourced benchmark framework to enable the public to re-program and benchmark different choices LLMs on their own time series data.
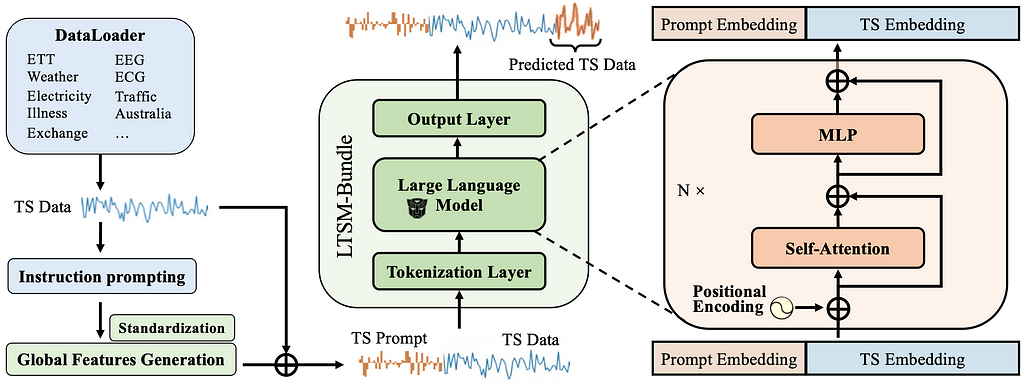
Specifically, we dived into how to train LTSM models by looking at various factors, like different ways to prompt the model, how to break down the data, training methods, choosing the right base model, the amount of data we have, and how diverse the datasets are. On top of examining current methods, we’ve come up with a new idea called “time series prompt”. This new approach creates prompts by pulling out key features from the training data, giving a solid statistical overview of each dataset.
We evaluate different choices based on the prediction errors (Mean Squared/Absolute Error), the lower the numbers, the better the model. Some key takeaway from the studies including:
- Simple statistical prompts (TS Prompt) outperform text prompts in enhancing the training of LTSM models and the use of statistical prompts results in superior performance compared to scenarios where no prompts are employed.

2. Tokenizing time series with a learnable linear layer works better for training LTSM models, especially when dealing with data from different domains together, compared to other tokenization methods.

3. Training from scratch can perform well initially but risks overfitting due to a large number of parameters. Full fine-tuning generally achieves the best performance and converges twice as fast as training from scratch, ensuring efficient and effective forecasting.

4. Smaller models demonstrate up to 2% better performance in long-term forecasting (336 and 720 steps), while medium-sized models outperform larger ones in short-term forecasting (96 and 192 steps), due to potential overfitting issues in larger models
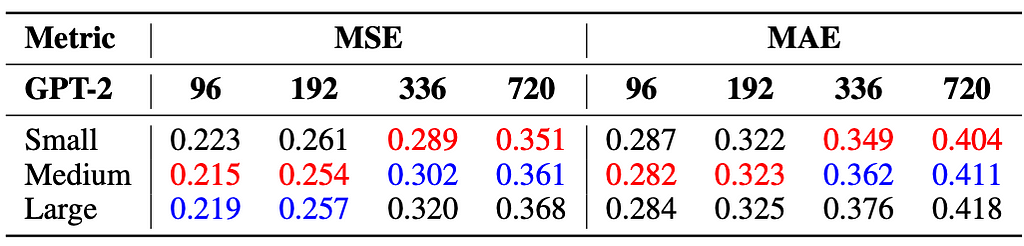
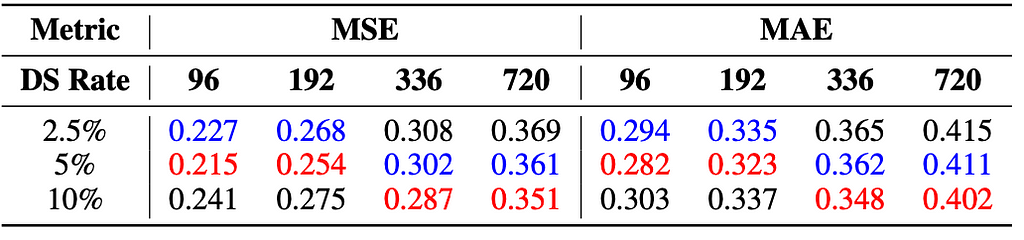
5. Increasing the data quantity does not positively correlate with improved model performance since more data for each dataset increases the granularity of training time series, which may reduce the model’s generalization ability. But augmenting dataset diversity generally leads to improved performances.

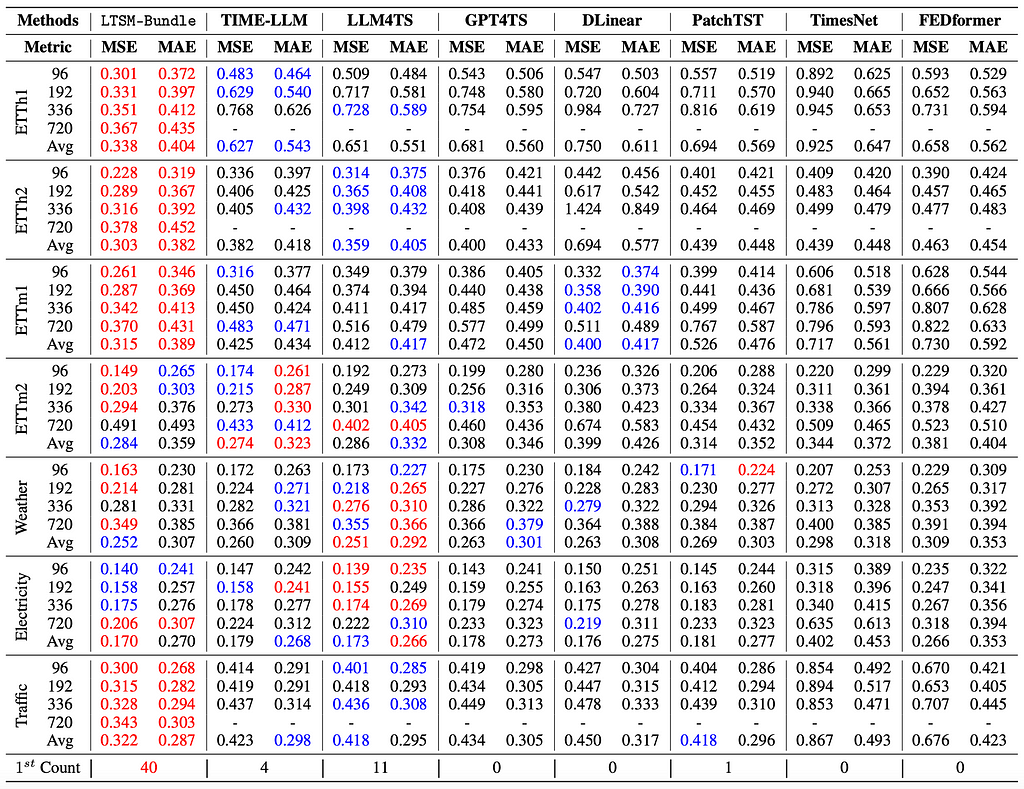
6. Bundling all these takeaways create a LTSM model (LTSM-Bundle) that outperforms all existing methods that re-programming LLM for time series and transformer based time series forecasting models.
Re-program a LTSM yourself!
Wanna try to re-program your own LTSM? Here is the tutorial for the LTSM-bundle: https://github.com/daochenzha/ltsm/blob/main/tutorial/README.md
Step 1: Create a virtual environment. Clone and install the requirements and the repository.
conda create -n ltsm python=3.8.0
conda activate ltsm
git clone [email protected]:daochenzha/ltsm.git
cd ltsm
pip3 install -e .
pip3 install -r requirements.txt
Step 2: Prepare your dataset. Make sure your local data folder like following:
- ltsm/
- datasets/
DATA_1.csv/
DATA_2.csv/
DATA_3.csv/
...
Step 3: Generating the time series prompts from training, validating, and testing datasets
python3 prompt_generate_split.py
Step 4: Find the generated time series prompts in the ‘./prompt_data_split’ folder. Then run the following command for finalizing the prompts:
# normalizing the prompts
python3 prompt_normalization_split.py --mode fit
#export the prompts to the "./prompt_data_normalize_split" folder
python3 prompt_normalization_split.py --mode transform
Final Step: Train your own LTSM with Time Series Prompt and Linear Tokenization on gpt2-medium.
python3 main_ltsm.py
--model LTSM
--model_name_or_path gpt2-medium
--train_epochs 500
--batch_size 10
--pred_len 96
--data_path "DATA_1.csv DATA_2.csv"
--test_data_path_list "DATA_3.csv"
--prompt_data_path "prompt_bank/prompt_data_normalize_split"
--freeze 0
--learning_rate 1e-3
--downsample_rate 20
--output_dir [Your_Output_Path]
Checkout more details in our paper and GitHub Repo:
Paper: https://arxiv.org/pdf/2406.14045
Code: https://github.com/daochenzha/ltsm/
Reference:
[1] Liu, Pengfei, et al. “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.” ACM Computing Surveys 55.9 (2023): 1–35.
[2] Liu, Xiao, et al. “Self-supervised learning: Generative or contrastive.” IEEE transactions on knowledge and data engineering 35.1 (2021): 857–876.
[3] Ansari, Abdul Fatir, et al. “Chronos: Learning the language of time series.” arXiv preprint arXiv:2403.07815 (2024).
Time Series Are Not That Different for LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Time Series Are Not That Different for LLMs
Go Here to Read this Fast! Time Series Are Not That Different for LLMs