A Bird’s-Eye View on the Evolution of Language Models for Text Generation
In this article I would like to share my notes on how language models (LMs) have been developing during the last decades. This text may serve a a gentle introduction and help to understand the conceptual points of LMs throughout their history. It’s worth mentioning that I don’t dive very deep into the implementation details and math behind it, however, the level of description is enough to understand LMs’ evolution properly.
What is Language Modeling?
Generally speaking, Language Modeling is a process of formalizing a language, in particular — natural language, in order to make it machine-readable and process it in various ways. Hence, it is not only about generating language, but also about language representation.
The most popular association with “language modeling”, thanks to GenAI, is tightly connected with the text generation process. This is why my article considers the evolution of the language models from the text generation point of view.
N-gram Language Models
Although the foundation of n-gram LMs was created in the middle of 20th century, the widespread of such models has started in 1980s and 1990s.
The n-gram LMs make use of the Markov assumption, which claims, in the context of LMs, that in the probability of a next word in a sequence depends only on the previous word(s). Therefore, the probability approximation of a word given its context with an n-gram LM can be formalized as follows:
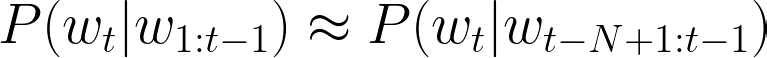
where t is the number of words in the whole sequence and N is the size of the context (uni-gram (1), bi-gram (2), etc.). Now, the question is how to estimate those n-gram probabilities? The simplest approach is to use n-gram counts (to be calculated on a large text corpora in an “unsupervised” way):
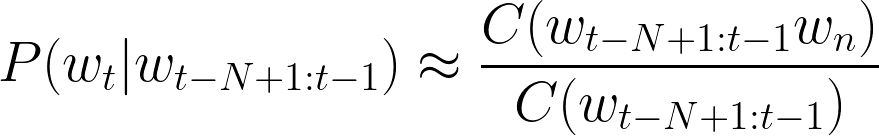
Obviously, the probability estimation from the equation above may appear to be naive. What if the numerator or even denominator values will be zero? This is why more advanced probability estimations include smoothing or backoff (e.g., add-k smoothing, stupid backoff, Kneser-Ney smoothing). We won’t explore those methods here, however, conceptually the probability estimation approach doesn’t change with any smoothing or backoff method. The high-level representation of an n-gram LM is shown below:
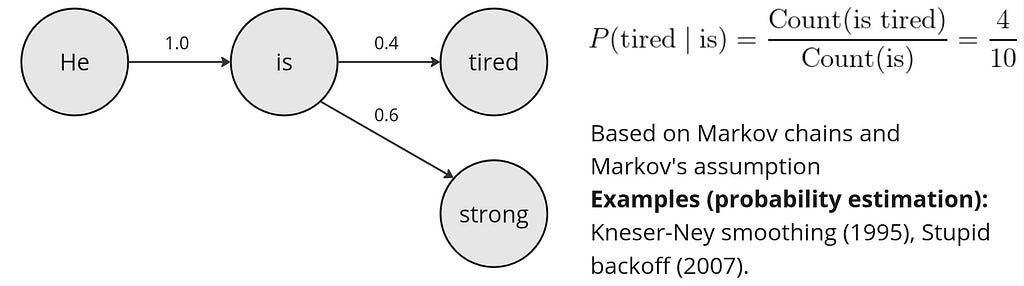
Having the counts calculated, how do we generate text from such LM? Essentially, the answer to this question applies to all LMs to be considered below. The process of selecting the next word given the probability distribution fron an LM is called sampling. Here are couple sampling strategies applicable to the n-gram LMs:
- greedy sampling — select the word with the highest probability;
- random sampling— select the random word following the probability
distribution.
Feedforward Neural Network Language Models
Despite smoothing and backoff, the probability estimation of the n-gram LMs is still intuitively too simple to model natural language. A game-changing approach of Yoshua Bengio et al. (2000) was very simple yet innovative: what if instead of n-gram counts we will use neural networks to estimate word probabilities? Although the paper claims that recurrent neural networks (RNNs) can be also used for this task, main content focuses on a feedforward neural network (FFNN) architecture.
The FFNN architecture proposed by Bengio is a simple multi-class classifier (the number of classes is the size of vocabulary V). The training process is based on the task of predicting a missing word w in the sequence of the context words c: P (w|c), where |c| is the context window size. The FFNN architecture proposed by Bengio et al. is shown below:
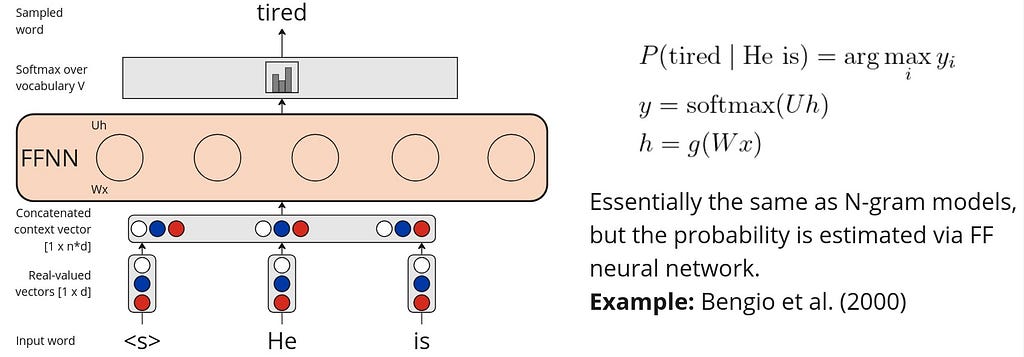
Such FFNN-based LMs can be trained on a large text corpora in an self-supervised manner (i.e., no explicitly labeled dataset is required).
What about sampling? In addition to the greedy and random strategies, there are two more that can be applied to NN-based LMs:
- top-k sampling — the same as greedy, but made within a renormalized set of top-k
words (softmax is recalculated on top-k words), - nucleus sampling— the same as top-k, but instead of k as a number use percentage.
Recurrent Neural Network Language Models
To this point we were working with the assumption that the probability of the next word depends only on the previous one(s). We also considered a fixed context or n-gram size to estimate the probability. What if the connections between words are also important to consider? What if we want to consider the whole sequence of preceding words to predict the next one? This can be perfectly modeled by RNNs!
Naturally, RNNs’ advantage is that they are able to capture dependencies of the whole word sequence while adding the hidden layer output from the previous step (t-1) to the input from the current step (t):
where h — hidden layer output, g(x) — activation function, U and W — weight matrices.
The RNNs are also trained following the self-supervised setting on a large text corpora to predict the next word given a sequence. The text generation is then performed via so-called autoregressive generation process, which is also called causal language modeling generation. The autoregressive generation with an RNN is demonstrated below:
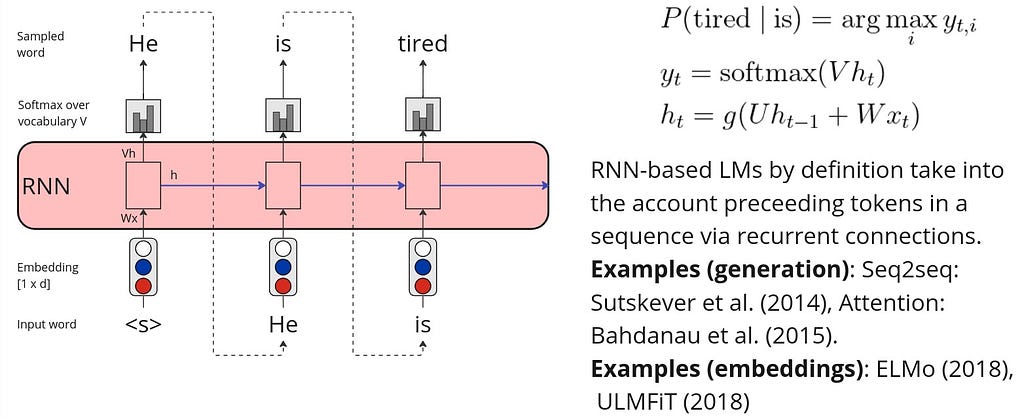
In practice, canonical RNNs are rarely used for the LM tasks. Instead, there are improved RNN architectures such as stacked and bidirectional, long short-term memory (LSTM) and its variations.
One of the most remarkable RNN architectures was proposed by Sutskever et al. (2014) — the encoder-decoder (or seq2seq) LSTM-based architecture. Instead of simple autoregressive generation, seq2seq model encodes an input sequence to an intermediate representation — context vector — and then uses autoregressive generation to decode it.
However, the initial seq2seq architecture had a major bottleneck — the encoder narrows down the whole input sequence to the only one representation — context vector. To remove this bottleneck, Bahdanau et al. (2014) introduces the attention mechanism, that (1) produces an individual context vector for every decoder hidden state (2) based on weighted encoder hidden states. Hence, the intuition behind the attention mechanism is that every input word impacts every output word and the intensity of this impact varies.
It is worth mentioning that RNN-based models are used for learning language representations. In particular, the most well known models are ELMo (2018) and ULMFiT (2018).
Evaluation: Perplexity
While considering LMs without applying them to a particular task (e.g. machine translation) there is one universal measure that may give us insights on how good is our LM is. This measure is called Perplexity.

where p — probability distribution of the words, N — is the total number of words in the sequence, wi — represents the i-th word. Since Perplexity uses the concept of entropy, the intuition behind it is how unsure a particular model about the predicted sequence. The lower the perplexity, the less uncertain the model is, and thus, the better it is at predicting the sample.
Transformer Language Models
The modern state-of-the-art LMs make use of the attention mechanism, introduced in the previous paragraph, and, in particular, self-attention, which is an integral part of the transformer architecture.
The transformer LMs have a significant advantage over the RNN LMs in terms of computation efficiency due to their ability to parallelize computations. In RNNs, sequences are processed one step at a time, this makes RNNs slower, especially for long sequences. In contrast, transformer models use a self-attention mechanism that allows them to process all positions in the sequence simultaneously. Below is a high-level representation of a transformer model with an LM head.

To represent the input token, transformers add token and position embeddings together. The last hidden state of the last transformer layer is typically used to produce the next word probabilities via the LM head. The transformer LMs are pre-trained following the self-supervised paradigm. When considering the decoder or encoder-decoder models, the pre-training task is to predict the next word in a sequence, similarly to the previous LMs.
It is worth mentioning that the most advances in the language modeling since the inception of transformers (2017) are lying in the two major directions: (1) model size scaling and (2) instruction fine-tuning including reinforcement learning with human feedback.
Evaluation: Instruction Benchmarks
The instruction-tuned LMs are considered as general problem-solvers. Therefore, Perplexity might not be the best quality measure since it calculates the quality of such models implicitly. The explicit way of evaluating intruction-tuned LMs is based on on instruction benchmarks,
such as Massive Multitask Language Understanding (MMLU), HumanEval for code, Mathematical Problem Solving (MATH), and others.
Summary
We considered here the evolution of language models in the context of text generation that covers at least last three decades. Despite not diving deeply into the details, it is clear how language models have been developing since the 1990s.
The n-gram language models approximated the next word probability using the n-gram counts and smoothing methods applied to it. To improve this approach, feedforward neural network architectures were proposed to approximate the word probability. While both n-gram and FFNN models considered only a fixed number of context and ignored the connections between the words in an input sentence, RNN LMs filled this gap by naturally considering connections between the words and the whole sequence of input tokens. Finally, the transformer LMs demonstrated better computation efficiency over RNNs as well as utilized self-attention mechanism for producing more contextualized representations.
Since the invention of the transformer architecture in 2017, the biggest advances in language modeling are considered to be the model size scaling and instruction fine-tuning including RLHF.
References
I would like to acknowledge Dan Jurafsky and James H. Martin for their Speech and Language Processing book that was the main source of inspiration for this article.
The other references are included as hyperlinks in the text.
Postscriptum
Text me [contact (at) perevalov (dot) com] or visit my website if you want to get more knowledge on applying LLMs in real-world industrial use cases (e.g. AI Assistants, agent-based systems and many more).
A bird’s-eye view on the evolution of language models for text generation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A bird’s-eye view on the evolution of language models for text generation
Go Here to Read this Fast! A bird’s-eye view on the evolution of language models for text generation