

t-Test : From Application to Theory
To bridge the gap between mathematical computations and programmatic implementation of a two-sample t-Test, this article provides a step-by-step guide using a practical use case. It includes an overview of the statistical tools, the motivation behind using these tools, and an explanation of the results and their interpretation.
Have you ever been stuck in a loop where you repeatedly go over the concepts of statistical tools, memorize them, and revisit them, but the concepts still don’t stick? You know how to use formulas but feel like that just gives surface-level knowledge of the concept. I was in the same boat until I TA’d for a physics lab course 105M at UT Austin and applied statistical tools relevant to the problems we were solving. It was then that I finally understood the theory and application of the Student’s t-Test, and now it truly sticks.
Let’s start with a question.
Does Color Affect the Sliding Time of 2 Similar Balls Rolled Over a Ramp?
Intuitively, the answer to this question might be NO! But let’s validate this hypothesis using prevalent statistical tests. In hypothesis testing terms :
- Null Hypothesis would be that color doesn’t affect the rolling time (no effect)
- Alternative Hypothesis would suggest that color does affect the rolling time (there is an effect).

Data
We start by measuring the time taken by two similar balls of different colors (for instance, one black and one red) as we roll them down the ramp one by one, in multiple trials (let’s say 10 trials each).
The difference in the rolling times obtained in different trials highlights the significance of conducting multiple trials instead of one, therefore helping in providing a more reliable estimate.
It is also important to note that there can be many possible values (population) for the estimated rolling time, but we are capturing only a sample of these values with limited trials.
Best Estimate
Next, we calculate the expected value or the best estimate of the rolling time for each ball. We assume that the time recordings from different trials form a random distribution, and the expected value is best represented by the mean or the average value of the distribution.

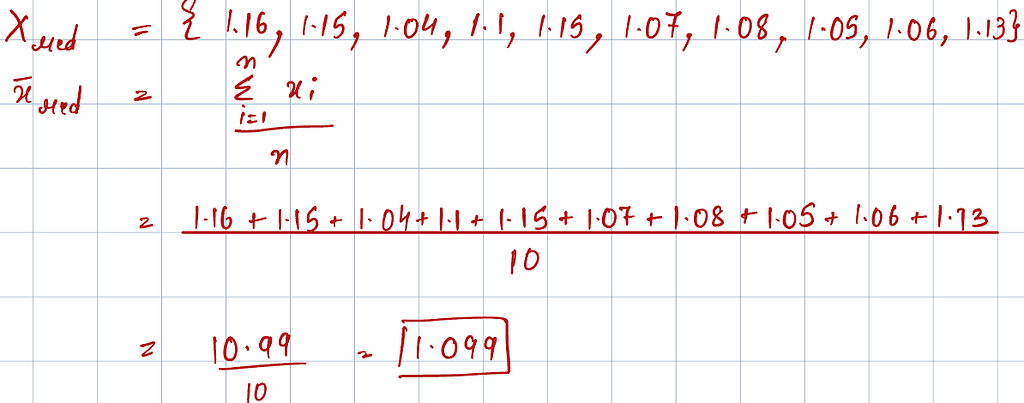
Standard Error
As mentioned earlier, we gathered limited data (sample) using just 10 trials out of all the possible values (population). Note that the calculated best estimate is from the sample distribution. However, to get a better estimate of the population mean, we calculate the standard error of the sample distribution. The standard error helps us determine the range within which our best estimate for the population is likely to fall. It is based on the variance of the distribution, which indicates how disperse the distribution is around mean.
To calculate the standard error, first find the standard deviation (square root of variance), then divide it by the square root of the number of data points.


We observe that the best estimates and the standard errors for both balls are comparable (there is an overlap between the calculated ranges), prompting us to consider that distributions are similar and therfore color may not affect the rolling time of the balls. However, how statistically significant and reliable are these findings? In essence, do these values provide sufficient evidence for us to draw conclusions about the hypothesis?
To measure the certainty about our results and present evidence in a more communicable way, we use test statistics. These statistics help us measure the probability of obtaining these results, providing a measure of certainty. For instance, we use statistics like z-statistic if the population standard deviation is known and the t-statistic if only the sample standard deviation is known, as in our experiment.
T-statistic
We compare our two sample distributions (groups) using a Two-Sample t-Test, which relies on the best estimates and variances of the two groups. Depending on the similarity of the variances between the two groups, we decide between using pooled variance, as in Student’s t-Test for equal variances, or Welch’s t-Test, which is for unequal variances.
Using statistical tests such as the F-test or Levene’s test, we can assess the equality of variances.
Since the calculated standard deviations (square root of variance) of both distributions are very similar, we proceed with a Student’s t-Test for equal variances. We conduct a two-tailed test to check for inequality of distributions rather than specifically looking for lesser or greater values.
We use the pooled standard deviation along with the averages obtained from our two distributions to calculate the t-score.

Result Interpretation
As we observed, the t-statistic is based on the difference of the means of the two samples. In our case, the t-statistic is very small (~-0.38), indicating that the difference between the means of the two distributions is also very small. This suggests that the recordings for the two balls are similar, hinting at the overall conclusion that color has no significant effect on the rolling time.
However, interpreting the t-statistic involves more than just observing the small difference in means, especially since we compared only two samples (limited trials) and not the entire populations. To make an informed inference, we need to determine the critical value and then compare out t-statistic with that critical value.
The critical value is determined based on the confidence interval (e.g., 95%) and the sample sizes (degrees of freedom). A 95% confidence interval (CI) means that if the experiment is repeated several times, the true mean difference will fall within 95% of the calculated intervals.
To find the critical value or critical value range in our case (since we are checking for inequality), we use the t-distribution table. For a two-tailed test with a 95% CI, we look at the 0.05 significance level, which splits into 2.5% for each tail. Given our degrees of freedom (df = 18), the critical value range is approximately -2.101 to +2.101.
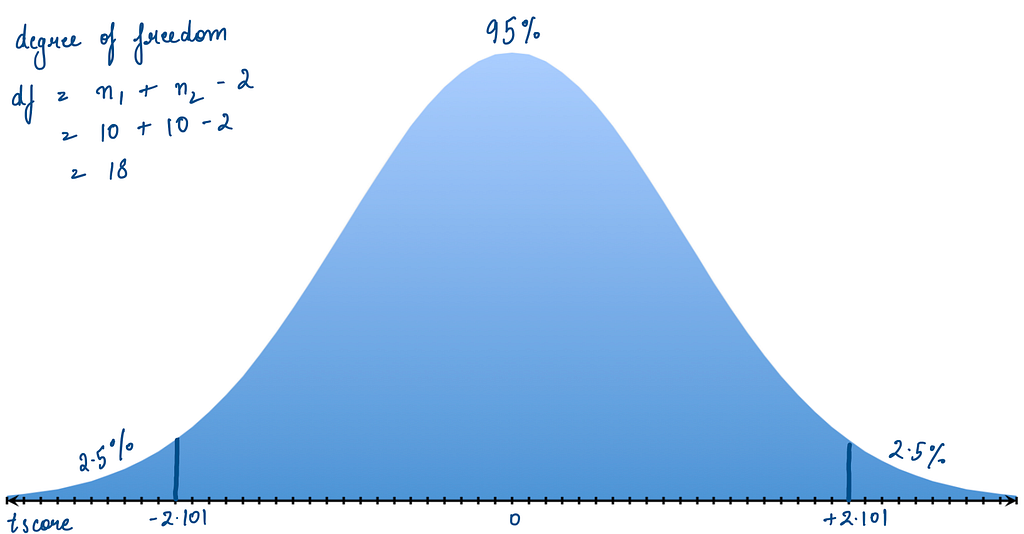
Our t-statistic of -0.38 falls within the critical range for a 95% confidence interval, leading to two key inferences. Firstly, the observed difference in means between the rolling times of the red and black balls is very small, indicating that color has no effect on rolling time. Secondly, with 95% certainty, if we were to repeat this experiment multiple times, the true difference in means between the rolling times of the red and black balls would consistently fall within this range.
Therefore, our results showing a low difference between the means of recording times for the two balls are statistically significant and reliable at the 95% confidence level, suggesting no meaningful difference in rolling times based on ball color.
I am excited to have documented my understanding in the hope of assisting others who may have struggled, like me, with grasping these statistical tools. I look forward to seeing others implement these methods. Please feel free to reach out or refer to the references mentioned below for any unanswered questions.
Unless otherwise noted, all images are by the author.
References:
- Student’s t-test – Wikipedia
- Standard error – Wikipedia
- numpy.std – NumPy v2.0 Manual
- ttest_ind – SciPy v1.14.0 Manual
t-Test : From Application to Theory was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
t-Test : From Application to Theory
Go Here to Read this Fast! t-Test : From Application to Theory